四. 使用持久性的 JobStore
在很多方面,JobStore 有用内存来存储的,还有些使用某种能长期持久的方式来共享相拟的特征。这不该有什么惊奇的,因为他们都服务于同一目的。
和 RAMJobStore 一样,特久性的 JobStore 有优点也有其缺点。在你选择持久性的 JobStore 之前应该认真理解其利与弊。这节就来解释它们的区别,以及在什么情况下你会希望使用持久性的 JobStore。
目前,Quartz 提供了两种类型的持久性 JobStore,每一种类型都有其独特的持久化机制。
| 持久性 JobStore = JDBC + 关系型数据库 尽管有几种不同的持久化机制可被 Quartz 用于持久化 Scheduler 信息,Quartz 依赖于一个关系型数据库管理系统(RDMS) 来持久化存储。假如你想用某种别的而不是数据库来持久化存储,那么你必须通过实现 JobStore 接口自己构建它。假定你想用文件系统来持久化存储。你可以创建一个类,这个类要实现 JobStore 接口,在本章中,当我们说 "持久化",我们隐式的是说用 JDBC 来持久化 Scheduler 状态到数据库中 |
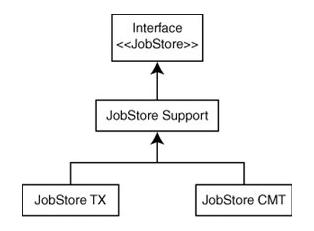
Quartz 所带的所有的持久化的 JobStore 都扩展自 org.quartz.impl.jdbcjobstore.JobStoreSupport 类。
·JobStoreSupport 类
JobStoreSupport 是个抽象类,并实现了 JobStore 接口,在此章前面就讨论过的。它为所有基于 JDBC 的 JobStore 提供了基本的功能。图 6.1 显示了 JobStore 类型的层次关系。
| JobStoreSupport 本该名之为 JDBCJobStoreSupport作为这个类的一个更好的名字本应该是 JDBCJobStoreSupport,因为这个类专门是为基于 JDBC 存储方案而设置的,然而,这个名并没有减损到它为持久性 JobStore 所提供的功能。 |
因为 JobStoreSupport 类是抽象的,因此 Quartz 提供了两种不同类型的具体化的 JobStore,每一个设计为针对特定的数据库环境和配置:
·org.quartz.impl.jdbcjobstore.JobStoreTX
·org.quartz.impl.jdbcjobstore.JobStoreCMT
这两个持久性 JobStore 前面简单讨论过。但现在,我们来讨论两个版本所需要的数据库。
五. 为 Job 存储使用数据库
Quartz 中的持久性 JobStore 有时候就是指 JDBC JobStore,因为他们基本是依赖于一个 JDBC 驱动和一个关系型数据库通信。持久性 JobStore 会用到许多的 JDBC 特性,包括支持事特,锁定和隔离级别,只列了这几个特性罢。
| 要是我的数据库不支持 JDBC 呢?假如你的数据库不支持 JDBC,那你肯定是碰到什么问题了。并不能全归咎于你运气不好,只是在这之前你还有很多工作要做。你最好是切换到某一种支持的数据库平台上来。假如你的数据库不支持 JDBC,你将需要创建一个新的实现(实现了 JobStore 接口)。你也许想检查一下 Quartz 用户论坛里的用户,看谁是否已经做了这样的工作,并是否愿意共享他们的代码或者至少告诉你实现的方法。 |
·持久性 JobStore 所支持的数据库
Quartz 中的持久性 JobStore 被设计能与如下数据库平台一同使用:
·Oracle
·MySQL
·MS SQL Server 2000
·HSQLDB
·PostgreSQL
·DB2
·Cloudscape/Derby
·Pointbase
·Informix
·Firebird
·大多数别的有完全 JDBC 兼容性驱动的 RDBMS
·独立环境中的持久性存储
JobStoreTX 类设计为用于独立环境中。这里的 "独立",我们是指这样一个环境,在其中不存在与应用容器的事物集成。这里并不意味着你不能在一个容器中使用 JobStoreTX,只不过,它不是设计来让它的事特受容器管理。区别就在于 Quartz 的事物是否要参与到容器的事物中去。
·程序容器中的持久性存储
JobStoreCMT 类设计为当你想要程序容器来为你的 JobStore 管理事物时,并且那些事物要参与到容器管理的事物边界时使用。它的名字明显是来源于容器管理的事物(Container Managed Transactions (CMT))。
六. 创建 Quartz 数据库结构
JobStore 是基于 JDBC 的,它需要一个数据用于 Scheduler 信息的持久化。Quartz 需要创建 12 张数据库表。表的名字和描述在表 6.1 中列出。
| 表名 | 描述 |
| QRTZ_CALENDARS | 以 Blob 类型存储 Quartz 的 Calendar 信息 |
| QRTZ_CRON_TRIGGERS | 存储 Cron Trigger,包括 Cron 表达式和时区信息 |
| QRTZ_FIRED_TRIGGERS | 存储与已触发的 Trigger 相关的状态信息,以及相联 Job 的执行信息 |
| QRTZ_PAUSED_TRIGGER_GRPS | 存储已暂停的 Trigger 组的信息 |
| QRTZ_SCHEDULER_STATE | 存储少量的有关 Scheduler 的状态信息,和别的 Scheduler 实例(假如是用于一个集群中) |
| QRTZ_LOCKS | 存储程序的非观锁的信息(假如使用了悲观锁) |
| QRTZ_JOB_DETAILS | 存储每一个已配置的 Job 的详细信息 |
| QRTZ_JOB_LISTENERS | 存储有关已配置的 JobListener 的信息 |
| QRTZ_SIMPLE_TRIGGERS | 存储简单的 Trigger,包括重复次数,间隔,以及已触的次数 |
| QRTZ_BLOG_TRIGGERS | Trigger 作为 Blob 类型存储(用于 Quartz 用户用 JDBC 创建他们自己定制的 Trigger 类型,JobStore 并不知道如何存储实例的时候) |
| QRTZ_TRIGGER_LISTENERS | 存储已配置的 TriggerListener 的信息 |
| QRTZ_TRIGGERS | 存储已配置的 Trigger 的信息 |
中表 6.1 中,所有的表都是以前缀 QRTZ_ 开始。这是默认的,但是你可以通过在 quartz.properties 文件中提供一个替代的前缀来改变它。如果你对不同的 Scheduler 实例使用了多套的表,那么改变这个前缀则是必须的。这在你需要用到多个非集群的 Scheduler,但只想用一个单独的数据库实例时也是要做的。
·安装 Quartz 数据库表
Quartz 包括了所有被支持的数据库平台的 SQL 脚本。你能在 <quartz_home>/docs/dbTables 目录下找到那些 SQL 脚本,这里的 <quartz_home> 是解压 Quartz 分发包后的目录。
大约有 18 种不同的数据库平台的脚本。这差不多能覆盖到你所能想出来的任何数据库。假如你的不在其列,你可以使用其中一个已存在的脚本,略做修改以适应你的数据库平台。
要安装必须的数据库表,先打开那个专为你的数据库平台制作的 .sql 文件并用你喜爱的查询工具执行其中的命令。比如说是 MS SQL Server,你需要用数据库所带的查询分析器(Quary Analyzer) 运行文件 tables_sqlServer.sql 中的命令。SQL 命令不负责创建数据库。你还要特别留意 SQL 文件最前面的注释。通常,在运行命令之前都必须执行几条指令。例如,还是 MS SQL Server 的 SQL 文件,你需要修改文件顶端的这条命令,填入数据库名称,在你刚创建它的时候还是一个空数据库。
USE [enter_db_name_here]
SQL 文件创建了必须的表结构,还给表加上了基本的约束和索引。在本章后面,我们会讨论如何通过对表结构做些额外的变动来改进性能。
本文链接 https://yanbin.blog/quartz-job-scheduling-framework-6-2/, 来自 隔叶黄莺 Yanbin Blog
[版权声明]  本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。