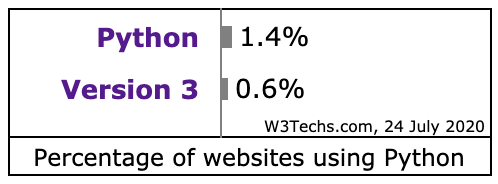
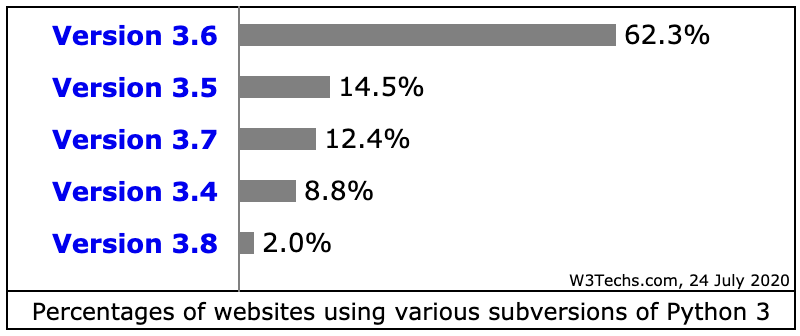
一年半以前写了关于 Python 包管理及虚拟环境系列
其中历数了 virtualenv, python3 -m venv, pipenv, 并提到了 pyenv 和 conda。但对 pyenv 和 conda 未作介绍,其中 conda 似乎不该错过。 Anaconda 着力于为数据分析提供支撑,并与 Jupyter Notebook 有更完美的结合,而且 PyCharm 中对它也有很好支持。因此本文来了解一下 conda 以及 Anaconda。
首先 Anaconda 是什么,它是一个用于科学计算的,跨平台的包管理与 Python 环境的工具,它方便的解决了多版本 Python 并存,切换及第三方包安装的问题。所以 Anaconda 不只是像 venv, pipenv 那样的创建管理 Python 虚拟环境,还承担了系统软件的安装管理,像 Mac 下的 brew 那样的功能。一般来说我们没有必要安装 Anaconda, 只需要安装 Miniconda 获得 conda 这个命令行工具即可。 阅读全文 >>