AWS ECS 使用 EC2 Capacity Provider (EC2 Auto Scaling)
在我 X 中 AWS 上不同应用的部署策略 中提到过在 AWS 部署服务(特别是 Web 服务时), 基于采用过以下演进的方式
- EC2(AutoScaling) + 直接 EC2 中部署本地应用, 靠 userdata 完成应用部署 2 EC2(AutoScaling) + ECS(AutoScaling), 运行容器,Replica 模式,有两个层次的 AutoScaling 要单独控制,比较麻烦
- ECS + EC2(AutoScaling), 运行容器,Daemon 模式。由 EC2 来驱动部署 ECS Task
- ECS(AutoScaling) + Fargate, 运行容器。这是最简单的,但硬件资源受限, 想要强大的 CPU, 没门
- ECS(AutoScaling) + Capacity Provider(EC2) + EC2(Managed AutoScaling), 运行容器。由 ECS Task 发起 EC2 实例需求
- ECS(AutoScaling) + Capacity Provider(Fargate),运行容器,Serverless 就是简单,同样硬件资源受限
- EKS,开启 Auto mode,一切变得简单,像是 Capacity Provider(EC2). 但会涉及到复杂的 EKS 配置管理,集群内网络,如 ELB,
基于服务的 WAF, IAM Role. 但基本是一次的工作,建立了健壮的 EKS, 以后部署任何应用都变得很轻松。
对于 #2 和 #3, 如果选择 Network 模式为 vpc 的话,即每个容器都会有自己的 IP 地址,并且 Target Group 中注册的是 IP 地址,这时候 AutoScaling
在缩减实例时就要靠 AutoScaling 的 Lifecycle Hook 来处理对相应 ECS Task 的通知,因为 EC2 的 AutoScaling 只知在开始关闭实例停止向相应实例
转发请求. 如果 Network 模式为默认的 Bridge 则没问题,因为请求是过通 NAT 方式(如 32768:80) 由 EC2 实例转发到其中的容器。
通常只控制 ECS 上的 AutoScaling 会更可靠性,因为它和 ECS 最近,能够准确的控制 ECS Task 的状态,从而不更易丢失请求。
本文体验 #6 种方式,即 ECS(AutoScaling) + Capacity Provieder(EC2) + EC2(Managed AutoScaling), Scaling type 选择 EC2 Auto Scaling.
另一种 Scaling type 方式为 Managed instances, 应该比 EC2 Auto Scaling 更容易。我们先从难处下手, 会通过各种选项让它成为一个
Managed AutoScaling, 到时时候我们只需要关注 ECS 的 AutoScaling.
最终我们只需控制 ECS AutoScaling 的 Desired Count, 比如我们选择 EC2 实例是 t3.medium(2 vCPU, 4G). 为把事情弄简单一点,我们采用类似于
ECS/EC2 的 Daemon 模式, 让每个 EC2 实例上只能运行一个 ECS Task, 比如这里的 ECS Task 分配 2 vCPU, 3G 内存, 再也没有多余的 CPU。
希望达到的目标
- 初始一个 ECS Task, 会请求 EC2 Managed AutoScaling 启动一个
t3.medium实例, 在其中启动一个 ECS Task - 修改 ECS Task 的 Desired Count 2, 会请求 EC2 Managed AutoScaling 启动一个新的
t3.medium实例, 在其上启动一个 ECS Task - 修改 ECS Task 的 Desired Count 3, 再请求 EC2 Managed AutoScaling 启动一个新的
t3.medium, 在其上启动一个新的 ECS Task, - 现在修改 ECS Task 的 Desired Count 2, 会立即停掉一个 ECS Task, 有一个 EC2 未运行 Task, 闲置中,等 15 分钟后,该闲置 EC2 被关闭
- 继续修改 ECS Task 的 Desired Count 1, 会立即停掉一个 ECS Task, 再等 15 分钟后,EC2 实例只剩下一个
上面的 ECS Task 的 Desired Count 测试中是手工控制的,实际服中由配置的 ECS AutoScaling 规则来控制,如基于 CPU, 或 Memory 的使用率等。 为什么 Scale in 时候要等候 15 分钟,因为 Capacity Provider 会自动创建一个每分检查一次,总 15 次才会触发的 Cloudwatch Alarm. 后面将会看到。
下面是相应的 Terraform 脚本文件
Terraform 脚本
ecs.tf
1resource "aws_ecs_cluster" "main" {
2 name = "test-cp"
3}
4
5resource "aws_ecs_service" "main" {
6 name = "my-service"
7 cluster = aws_ecs_cluster.main.id
8 task_definition = aws_ecs_task_definition.main.arn
9 desired_count = 1
10 network_configuration {
11 subnets = var.subnet_ids
12 security_groups = var.ec2_security_groups
13 }
14
15 capacity_provider_strategy {
16 capacity_provider = aws_ecs_capacity_provider.ec2.name
17 base = 1
18 weight = 1
19 }
20
21 load_balancer {
22 target_group_arn = aws_lb_target_group.main.arn
23 container_name = "my-container"
24 container_port = 80
25 }
26}
27
28resource "aws_ecs_task_definition" "main" {
29 family = "my-task"
30 requires_compatibilities = ["EC2"]
31 network_mode = "awsvpc"
32
33 container_definitions = jsonencode([
34 {
35 name = "my-container"
36 image = "strm/helloworld-http"
37 cpu = 2048
38 memory = 3072
39 stopTimeout = 5
40 portMappings = [
41 {
42 containerPort = 80
43 hostPort = 80
44 protocol = "tcp"
45 }
46 ]
47 }
48 ])
49}
选择了用 vpc 网络模式,每个 Task 有独立的 IP 地址,省得端口映射来访问,并且需要开放 32768~65536 端口。strm/helloworld-http"
Docker 镜像是一个 Web 服务,访问时返回当前机器的 IP 地址,作负载均衡测试很有用的。
capacity-provider.tf
1resource "aws_ecs_capacity_provider" "ec2" {
2 name = "ec2-capacity-provider"
3
4 auto_scaling_group_provider {
5 auto_scaling_group_arn = aws_autoscaling_group.ecs_asg.arn
6 managed_termination_protection = "ENABLED"
7 managed_scaling {
8 maximum_scaling_step_size = 5
9 minimum_scaling_step_size = 1
10 status = "ENABLED"
11 target_capacity = 100
12 }
13 }
14}
15
16resource "aws_ecs_cluster_capacity_providers" "main" {
17 cluster_name = aws_ecs_cluster.main.name
18 capacity_providers = [aws_ecs_capacity_provider.ec2.name]
19}
给 ECS Cluster 添加 Capacity Provider, 该 Capacity Provider 与自定义的 EC2 AutoScaling 相关联。这就是创建 Capacity Provider
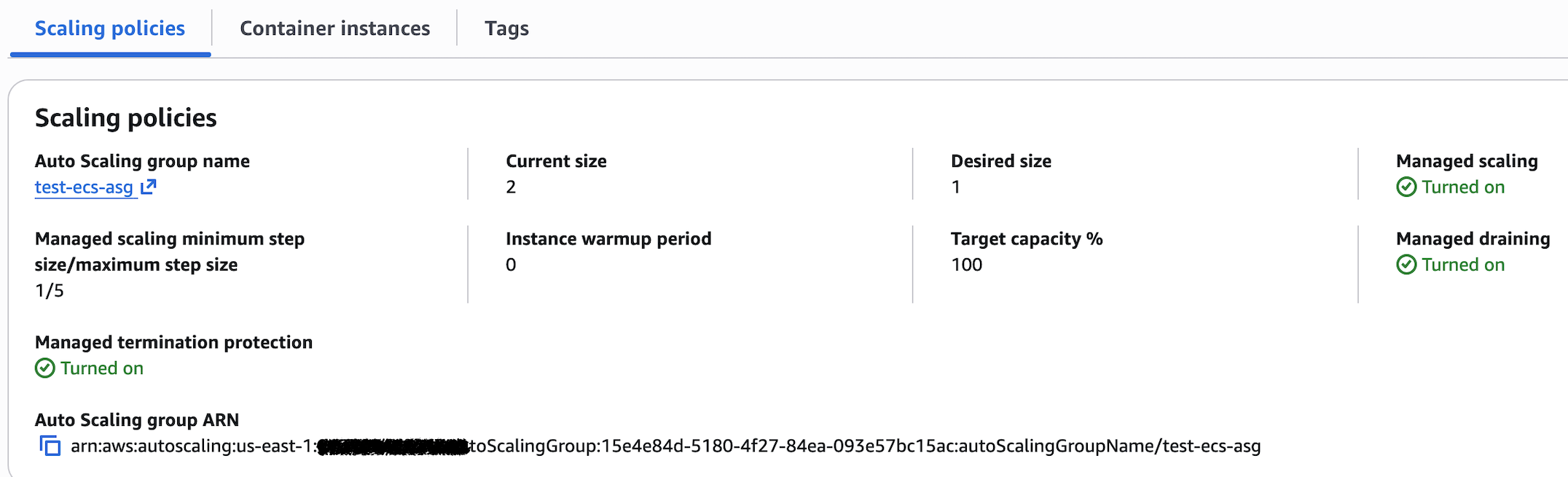
选择 EC2 Auto Scaling 的效果

注意上面几个值:
managed_termination_protection = "ENABLED"ECS 确保任务迁移完再终止实例managed_scaling.status = "ENABLED"打开 Managed scaling: Turned on, ECS 接管扩缩容managed_draining = "ENABLED"默认为ENABLED, 会给相应的 EC2 ASG 创建一个 Lifecycle Hookmanaged_scaling.target_capacity = 100只按需分配,不预备资源
创建好的 Capacity Provider 看起来是下面的样子
asg.tf
1resource "aws_autoscaling_group" "ecs_asg" {
2 name = "test-ecs-asg"
3 vpc_zone_identifier = var.subnet_ids
4 min_size = 0
5 max_size = 12
6 desired_capacity = 0
7 protect_from_scale_in = true
8 termination_policies = [
9 "OldestInstance",
10 ]
11
12 launch_template {
13 id = aws_launch_template.ecs_lt.id
14 version = "$Latest"
15 }
16
17 tag {
18 key = "AmazonECSManaged"
19 value = true
20 propagate_at_launch = true
21 }
22
23 tag {
24 key = "Name"
25 value = "test-cp"
26 propagate_at_launch = true
27 }
28}
29
30resource "aws_launch_template" "ecs_lt" {
31 name = "test-cp-lt"
32
33 image_id = var.ecs_ami_id
34 instance_type = "t3.medium"
35
36 iam_instance_profile {
37 arn = var.ecs_instance_profile_arn
38 }
39
40 vpc_security_group_ids = var.ec2_security_groups
41
42 tag_specifications {
43 resource_type = "instance"
44 tags = {
45 Name = "test-cp"
46 }
47 }
48
49 user_data = base64encode(<<EOF
50#!/bin/sh
51
52cat << SH_EOF > /etc/ecs/ecs.config
53ECS_CLUSTER=test-cp
54ECS_ENABLE_CONTAINER_METADATA=true
55ECS_RESERVE_MEMORY=512
56SH_EOF
57
58EOF
59 )
60}
61
62resource "aws_appautoscaling_target" "ecs_target" {
63 max_capacity = 10
64 min_capacity = 1
65 resource_id = "service/${aws_ecs_cluster.main.name}/${aws_ecs_service.main.name}"
66 scalable_dimension = "ecs:service:DesiredCount"
67 service_namespace = "ecs"
68}
AmazonECSManagedtag 的作用是正式承认该 EC2 ASG 让 ECS 托管protect_from_scale_in = true防止 EC2 ASG 绕过 ECS 自行缩容
elb.tf
1resource "aws_lb" "test-cp" {
2 name = "test-cp-lb"
3 internal = true
4 subnets = var.subnet_ids
5 security_groups = var.elb_security_groups
6}
7
8resource "aws_lb_listener" "main" {
9 port = 80
10 protocol = "HTTP"
11 load_balancer_arn = aws_lb.test-cp.arn
12 default_action {
13 type = "forward"
14 target_group_arn = aws_lb_target_group.main.arn
15 }
16}
17
18resource "aws_lb_target_group" "main" {
19 name = "test-cp-tg"
20 port = 80
21 protocol = "HTTP"
22 vpc_id = var.vpc_id
23 target_type = "ip"
24}
以上脚本,请填入对应环境的以下变量
1 subnet_ids
2 ecs_ami_id
3 ecs_instance_profile_arn
4 elb_security_groups
5 ec2_security_groups
6 vpc_id
准备好 AWS Credentials, 再补上 AWS Provider 后, 运行
1terraform init
2terraform apply-auto-approve
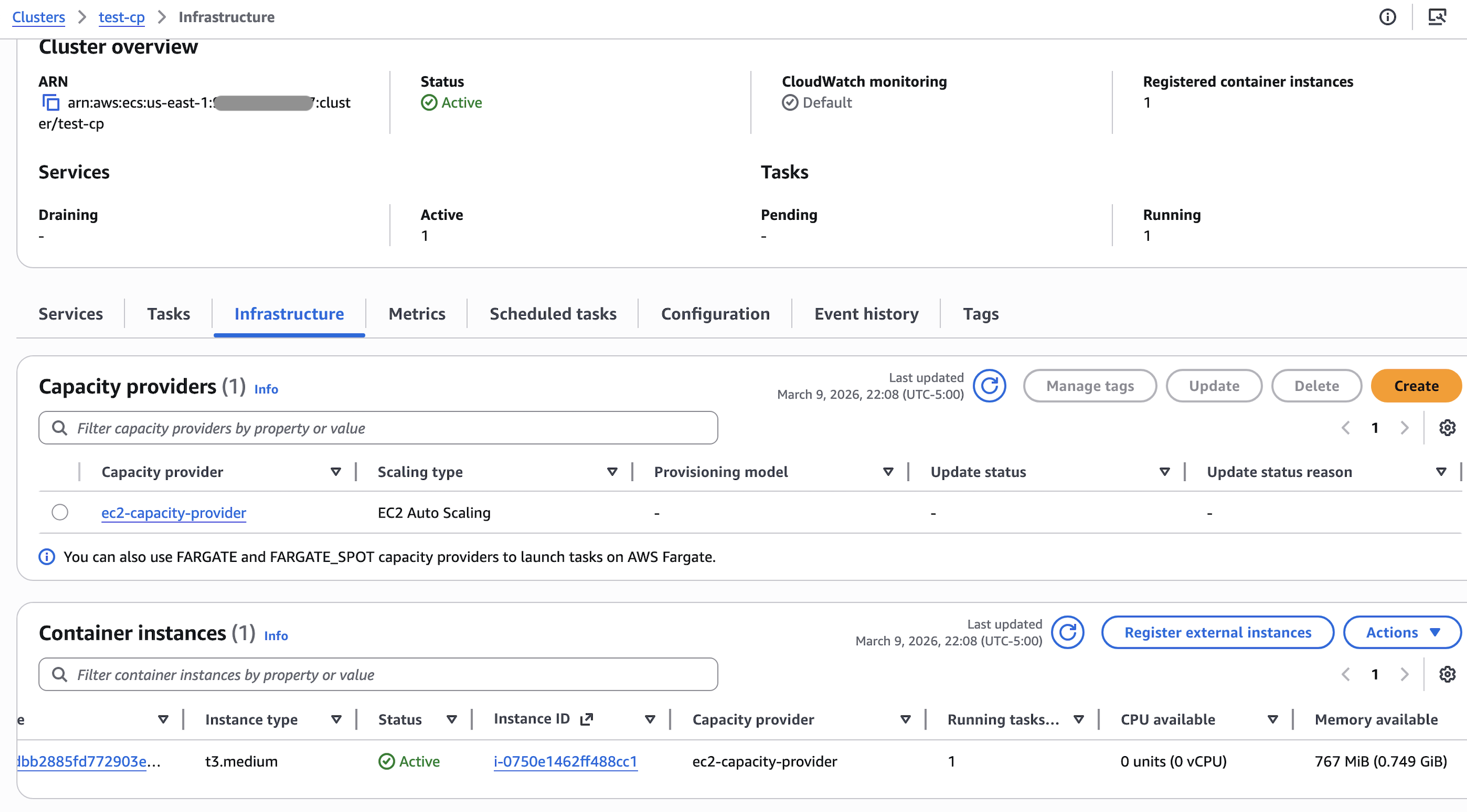
成功后会产生整个架构。在 ECS cluster test-cp 的 Infrastructure 将会看到
实际的测试效
- ECS Desired Count 1,启动了一个 EC2 实例
- ECS Desired Count 2, 启动了两个 EC2 实例
- ECS Desired Count 3, 这时候就有点乱了,突然起了四个新实例,总共有 6 个 EC2 实例,但只使用了其中三个 EC2 实例
- 等候超过 15 分钟后,EC2 ASG 会把多余的 3 个 EC2 实例关掉
- ECS Desired Count 变成 2, 再等 15 分钟也会把空闲的 EC2 实例关闭
EC2 上同时运行多个 ECS Task 的情况也是一样的,就是在 Scale Out 的时候会过度启动多余的实例,对系统性能是不会有影响,对快速扩容还有一些好处, 比如再有 Scale Out 的时候都有现成的 EC2 实例可用,等系统平稳后回到了 ECS AutoScaling 实际的 Desired Count 值,EC2 实例数量与 ECS Task 数目会保持一致。也就是说 ECS Capacity Provider Managed EC2 AutoScaling Scale Out(Up) 时会过度启动多余的 EC2 实例, Scale In(Down) 缩容后 EC2 的数量与 ECS Task 数量会达到预期。
下面是 Scale Out 会出现 EC2 实例出现刚刚满足或有富余的状况
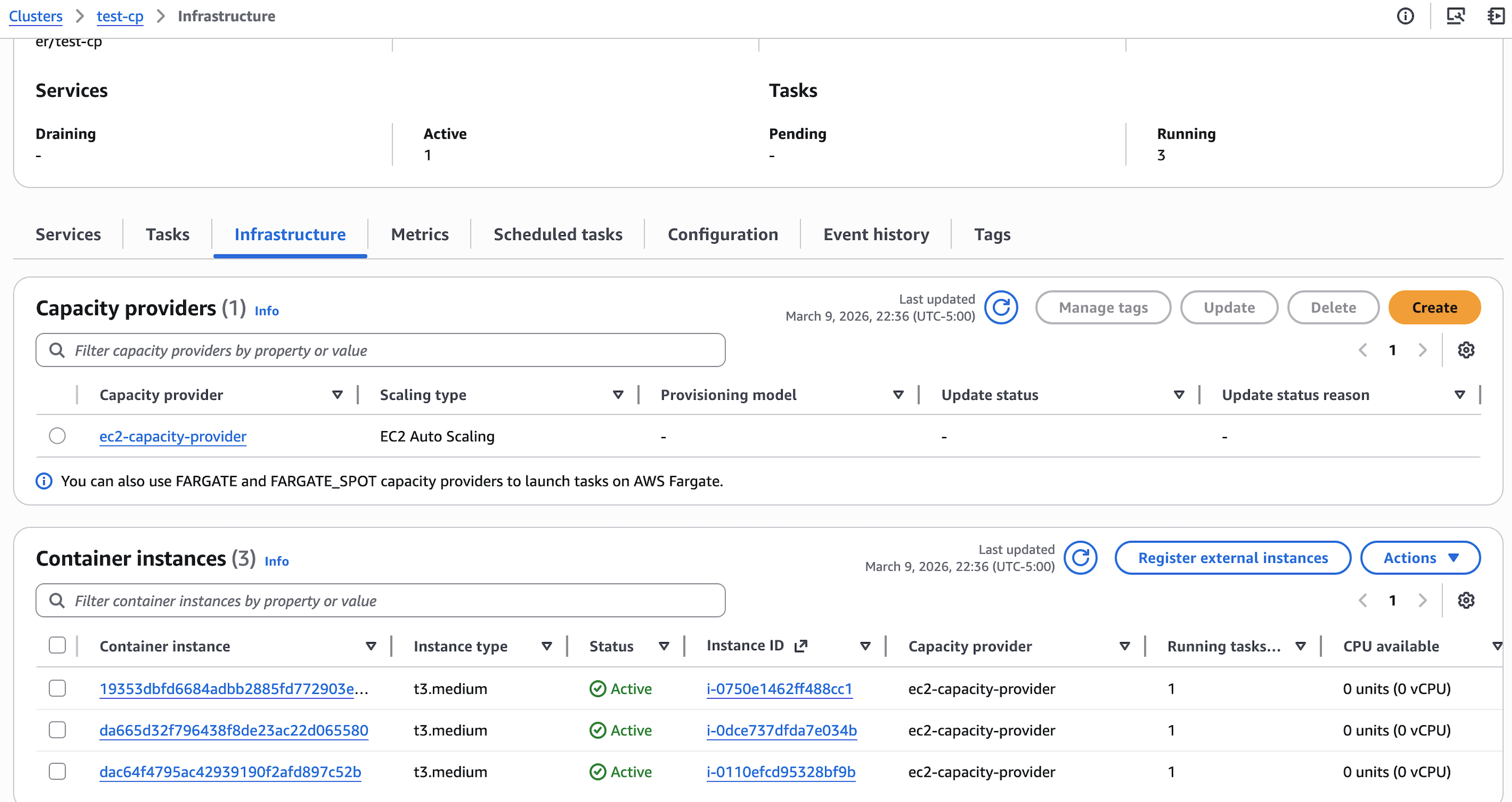 这是刚刚好的情况,每个 EC2 实例上跑了一个容器。
这是刚刚好的情况,每个 EC2 实例上跑了一个容器。
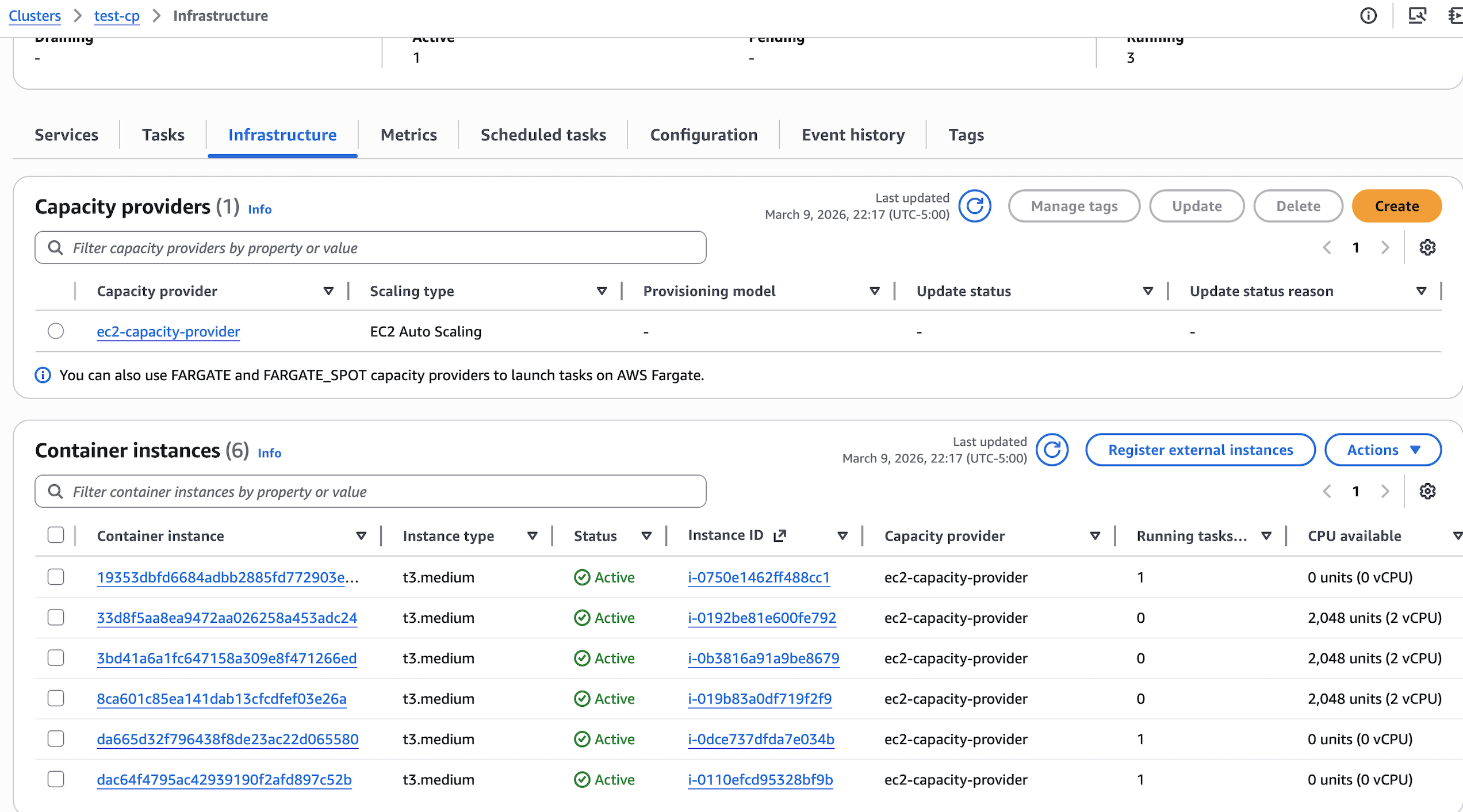 产生了三个多余的 EC2 实例, 如果 Desired Count 再加 1 的话,就不用等待 EC2 的启动时间,直接有现成的 EC2 可用。如果它们被闲置超过 15 分钟后,
会被 EC2 的 ASG 关掉,最终达成平衡。
产生了三个多余的 EC2 实例, 如果 Desired Count 再加 1 的话,就不用等待 EC2 的启动时间,直接有现成的 EC2 可用。如果它们被闲置超过 15 分钟后,
会被 EC2 的 ASG 关掉,最终达成平衡。
Capacity Provider 是如何实现 ECS 来管理 EC2 AutoScaling 的
是因我们在创建 Capacity Provider 时会自动为关联的 EC2 AutoScaling 自动创建的一个 Dynamic scaling policies 和 Lifecycle hooks
基于两个 Cloudwatch Alarm 进行自动扩容和缩容的。
| EC2 AutoScaling Policy | EC2 AutoScaling Lifecycle Hook |
 |  |
这个 EC2 AutoScaling Policy 对应两个 Cloudwatch Alarm, 一个是 Scale Up(Out) 的
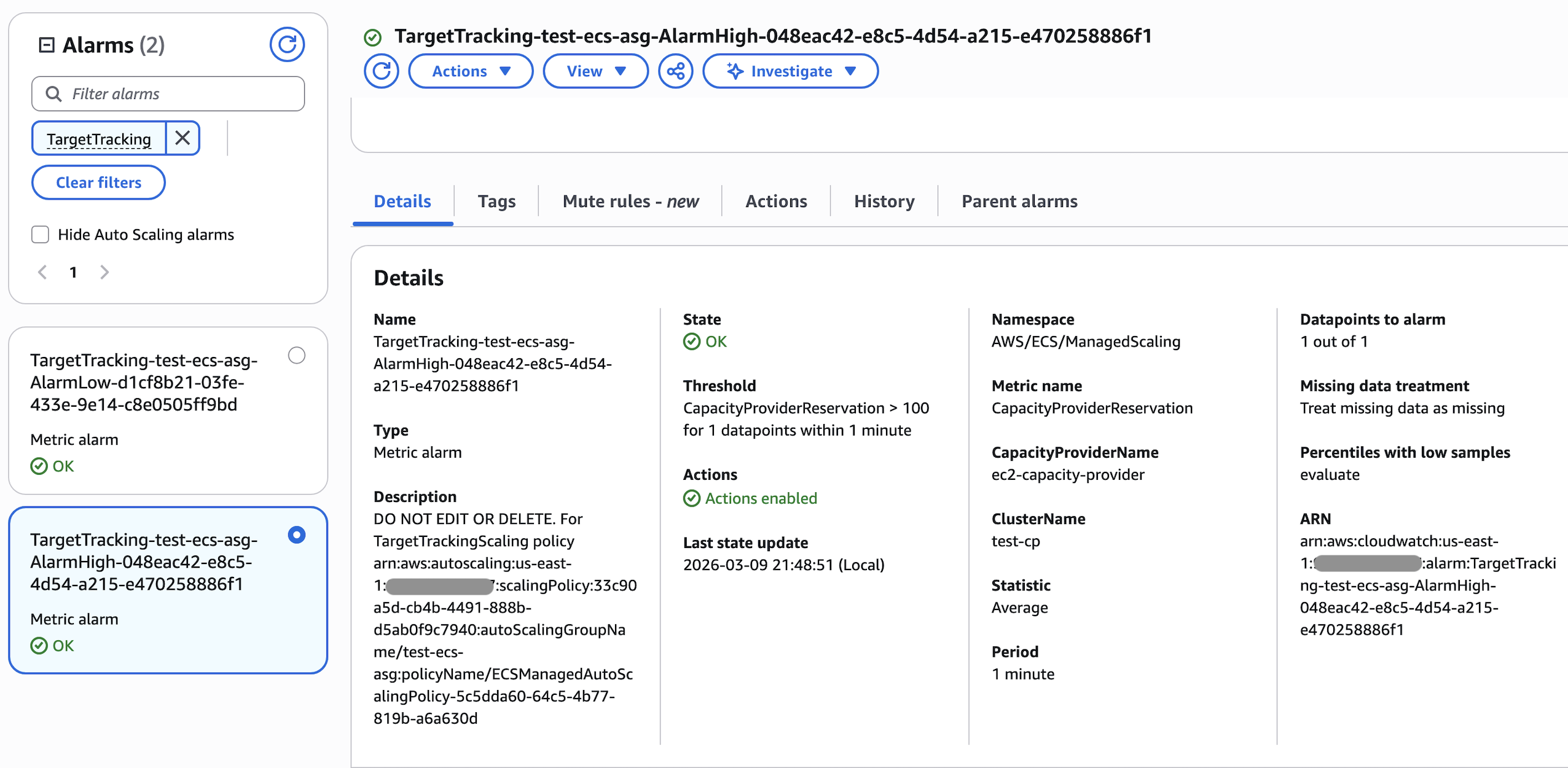
它每分钟检查一次 Cluster test-cp 的 CapacityProviderReservation 指标,如果它大于 100 就立即触发 AutoScaling Policy 的
Scale Out(Up) 操作, 让 EC2 ASG 启动一个新的 EC2 实例来满足 ECS Task 的需求。
另一个是 Scale Down(In) 的
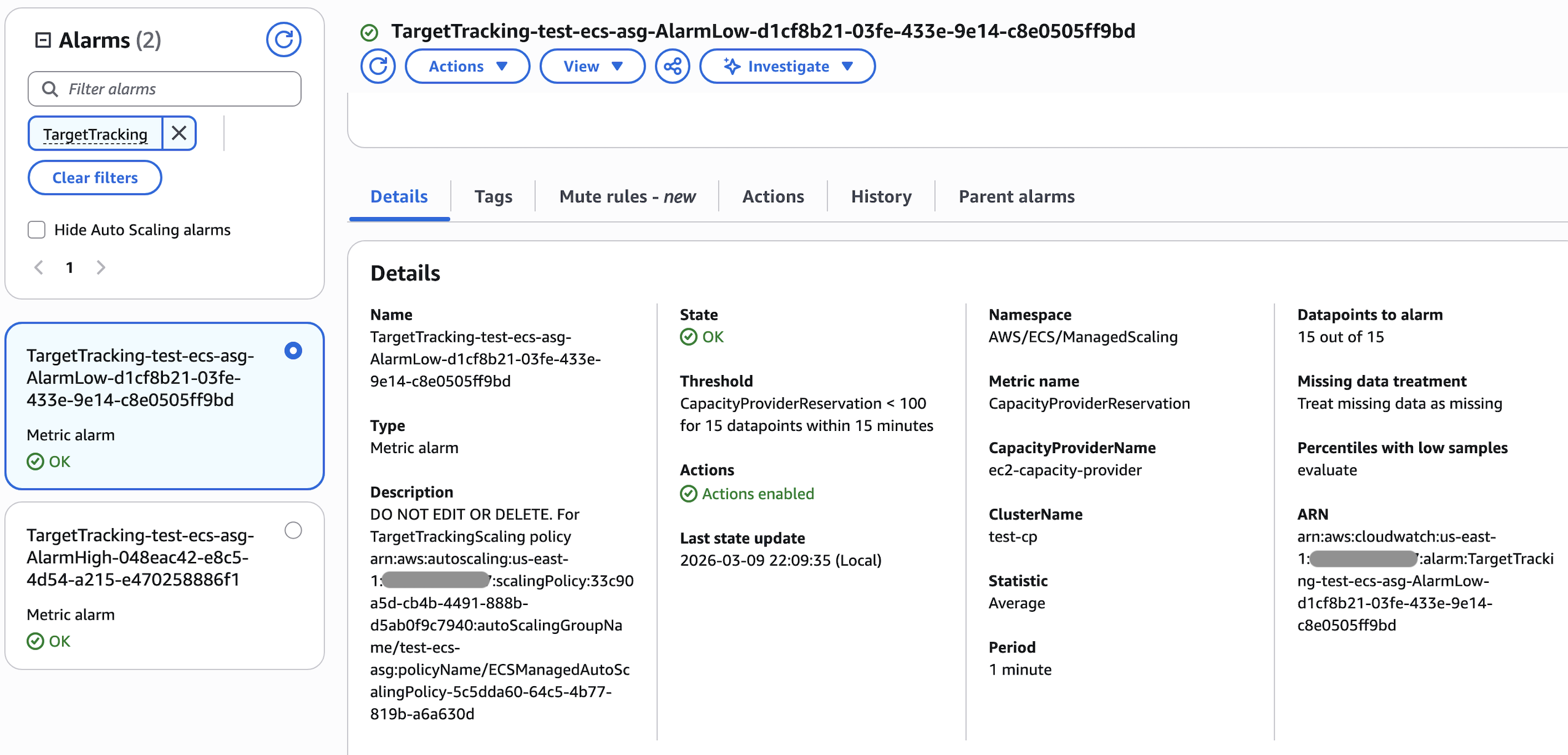
它同样每分钟检查一次 Cluster test-cp 的 CapacityProviderReservation 指标,连续 15 次都小于 100 就会触发 AutoScaling Policy
的 Scale In(Down) 操作,准备关闭空闲的 EC2 实例. 这就是为什么要等候 15 分钟的原因了。
而 CapacityProviderReservation 这个指标数据是由 ECS 的 AutoScaling 记录的,当改变 ECS Task 的 Desired Count 时,对比当前 EC2
实例的资源情况,是否能满足(富余) ECS Task 的资源需求来设置 CapacityProviderReservation 的值,有下面几种情况
- 当 EC2 资源不足以运行所有 ECS Desired Count 的 Task 时,
CapacityProviderReservation> 100 - 当 EC2 资源满足(富余) ECS Desired Count 的 Task 时,
CapacityProviderReservation< 100 - 当 EC2 资源刚刚好运行所有 ECS Desired Count 的 Task 时,
CapacityProviderReservation= 100
前面两个 Cloudwatch Alarm 就是通过检查 CapacityProviderReservation 的值来触发 AutoScaling Policy 的 Scale Out(Up) 和 Scale In(Down) 操作的。
最后 ECS ASG 关闭某个 EC2 实例还不只是简单的基于 termination_policies:OldestInstance 直接就找个 EC2 关了。由于 Capacity Provider
配置了 managed_termination_protection = "ENABLED", 所以 EC2 的 Scale in 是受保护的。
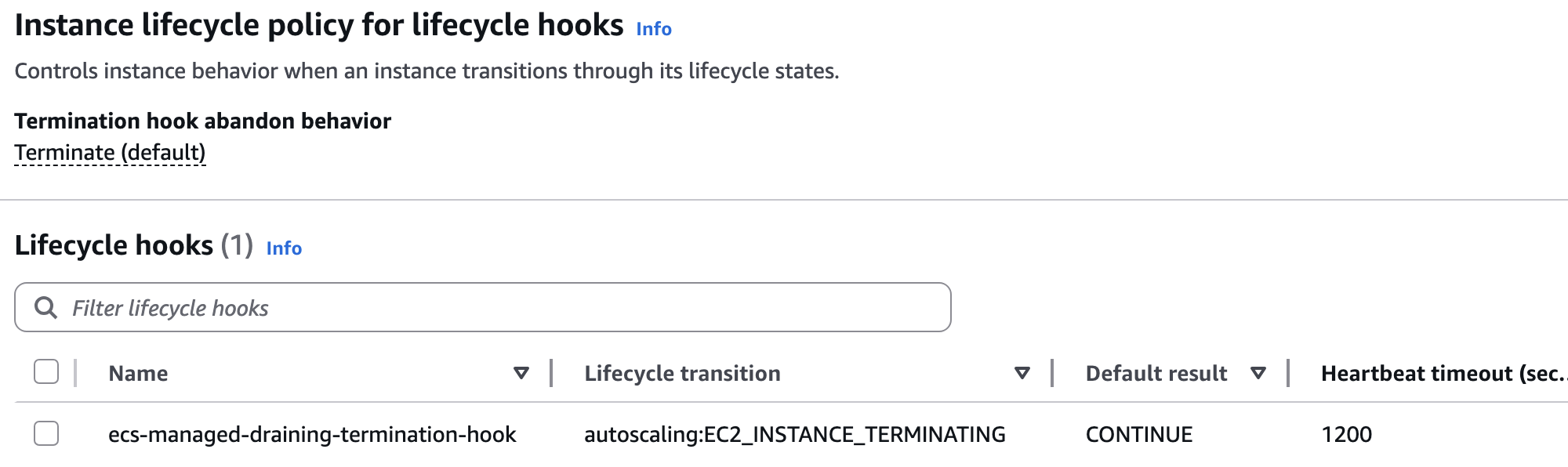
所以 EC2 的 Scale in 操作会先触发一个 Lifecycle Hook, 让要确保将要关闭的 EC2 上没有 ECS Task 在运行,或是是让 ECS 有机会把该 EC2 实例上运行的 Task 迁移到其他 EC2 实例上,等迁移完了再真正的关掉该 EC2 实例。
所以从 EC2 ASG 的 Activity 日志中我们可以看到一个 ASG Lifecycle Hook 介入的中间过程, 实际的 Scale In 操作由于受保护而 Cancle 掉。
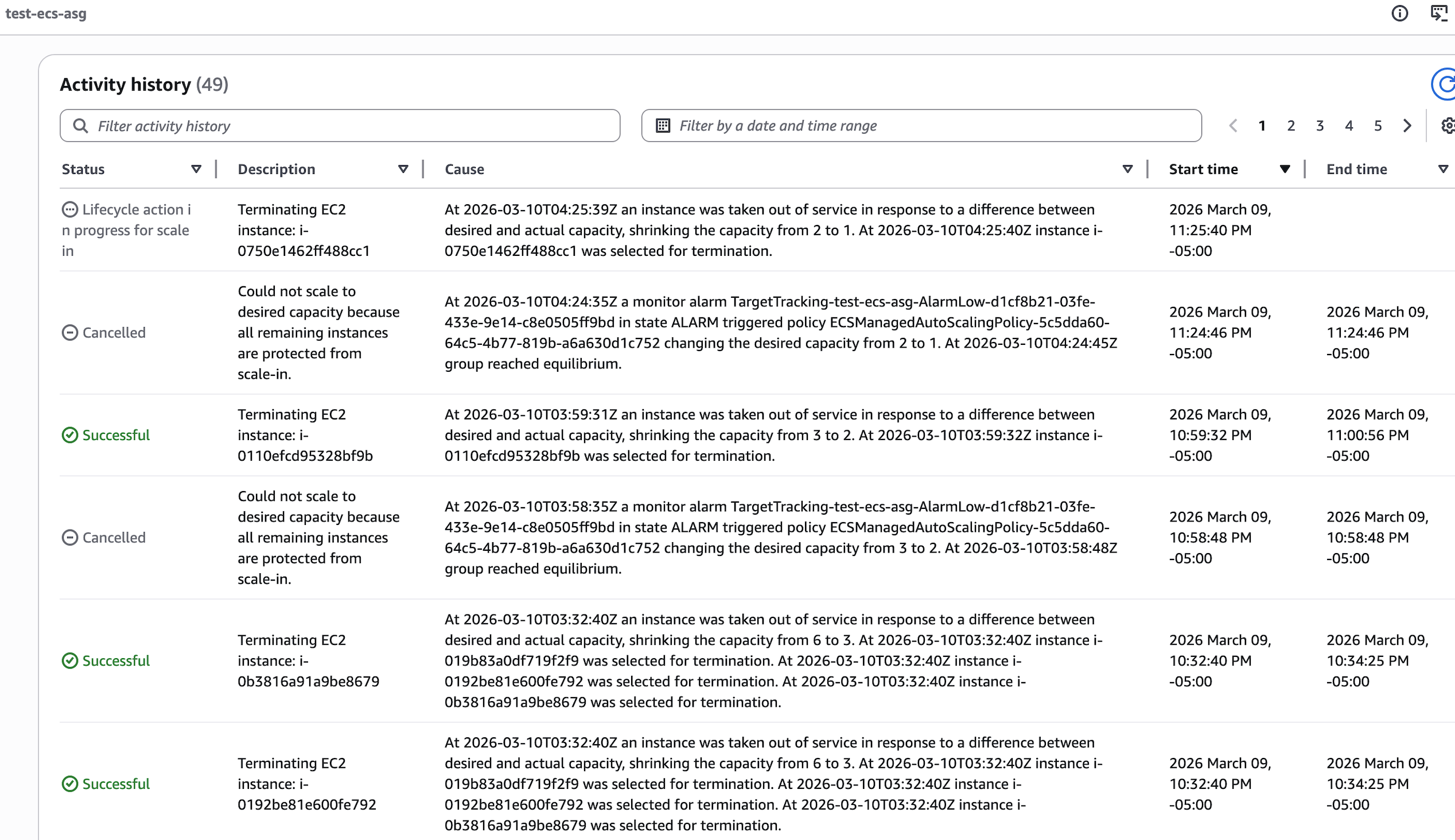
等待 EC2 ASG 的 Lifecyle Hook 安全的处置完该 EC2 后,最终把它关闭掉
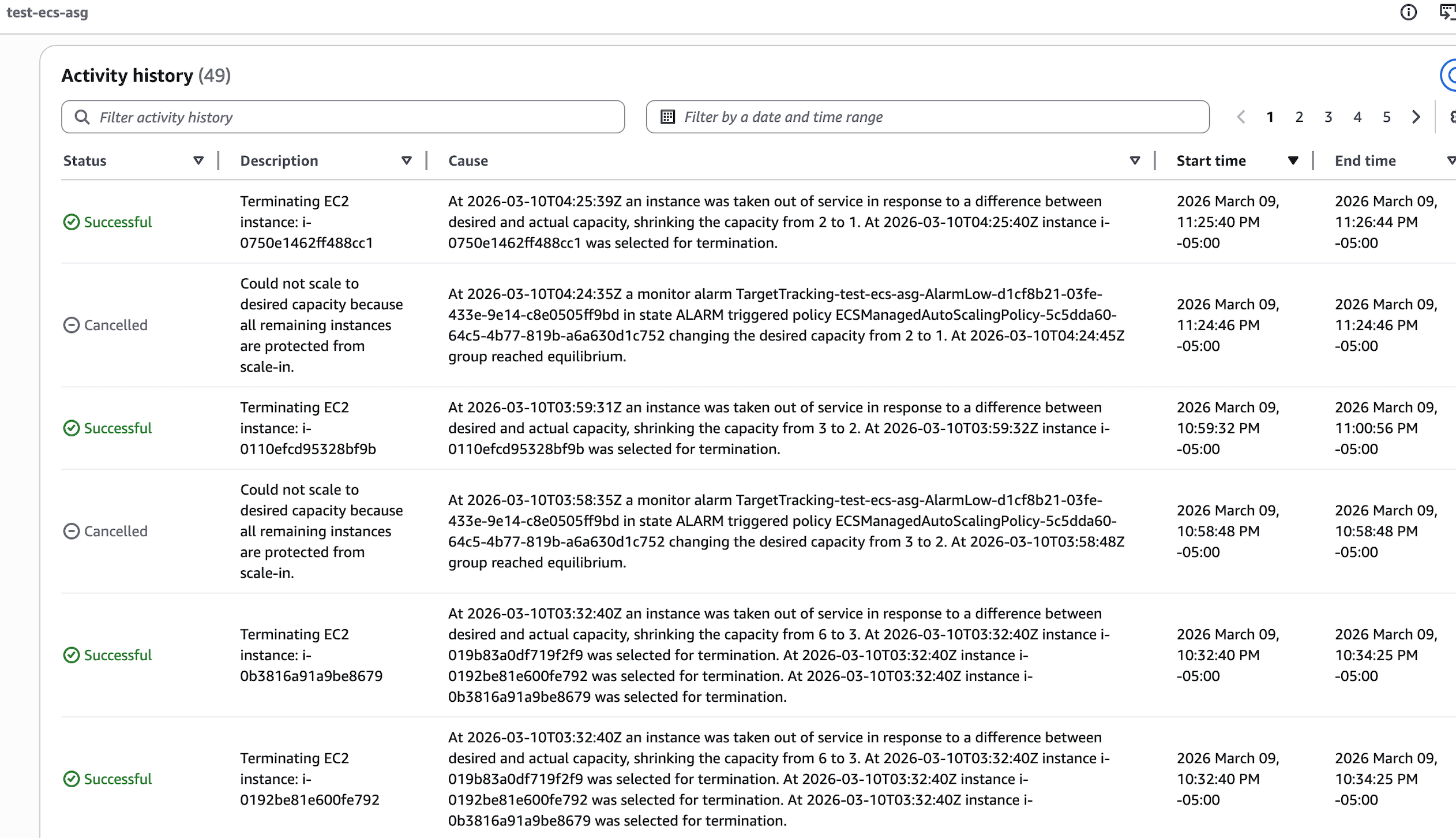
一个 TargetTracking-test-ecs-asg-AlarmLow-d1 cf8b21-03fe-433e-9e14-c8e0505ff9bd 的 Alarm 发生可能会一性把多个空闲的 EC2 实例
关掉的,而不只是把 EC2 ASG 的 Desired Cound 减 1. 这样就能更快的达到平衡状态(CapacityProviderReservation = 100)。
总结
几个关键的配置,对于 Capacity Provider:
managed_termination_protection = "ENABLED"ECS 确保任务迁移完再终止实例managed_scaling.status = "ENABLED"打开 Managed scaling: Turned on, ECS 接管扩缩容. 现在知道所谓的由 ECS 接管就是它会 做以下三件事- ECS AutoScaling 在 Desired Count 发生改变时 把
CapacityProviderReserversion写到 CloudWatch Metrics 中,Namespace 为ECS/ManagedScaling, Dimension:CapacityProviderName, ClusterName, 值为CapacityProviderReserversion. - 为关联的 EC2 ASG 创建一个
Synamic scaling policies, 如ECSManagedAutoScalingPolicy-xxxx - 创建两个 CloudWatch Alarm, 一个是
TargetTracking-test-ecs-asg-AlarmHigh-xxx在CapacityProviderReserversion大于 100 时触发增加 EC2 实例(每分钟), 另一个是TargetTracking-test-ecs-asg-AlarmLow-xxx,在CapacityProviderReserversion小于 100 时触发减少 EC2 实例(每十五分钟, 确切的说是每分钟检测一查,连续 15 次都小于 100 时触发)
- ECS AutoScaling 在 Desired Count 发生改变时 把
managed_draining = "ENABLED"默认为ENABLED, 会给相应的 EC2 ASG 创建一个 Lifecycle Hook, 它内部能通过EventBridge的方式通知道 ECS, 然后完成 Draining 操作.
对于 EC2 AutoScaling:
加上
AmazonECSManagedtag, 声明该 EC2 ASG 被 Capacity Provider 接管1 tag { 2 key = "AmazonECSManaged" 3 value = true 4 propagate_at_launch = true 5 }protect_from_scale_in = trueScale in 时进行保护, 防止 EC2 ASG 绕过 ECS 自行缩容
下一篇将要尝试一下 Capacity Provider 的 Managed Instances 的方式,那种方式应该更简单,现在猜测都不需要显式的 EC2 AutoScaling.
应该是使用 Capacity Provider 的趋势所在。
ECS Capacity Providers 于 2019 年 12 月引入的,发布时支持了 Fargate, Fargate Spot, 和 EC2 AutoScaling. 而 Managed Instances 在 2025-09-30 才加入的新特性,见 Announcing Amazon ECS Managed Instances
永久链接 https://yanbin.blog/aws-ecs-capacity-provider-ec2-auto-scaling/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。