AWS ECS 使用 EC2 Capacity Provider (Managed Instances)
上篇 AWS ECS 使用 EC2 Capacity Provider (EC2 Auto Scaling) 学习了如何在 ECS 中使用 Capacity Provider + EC2 Auto Scaling 来部署一个简单的 Web 应用,以及了解 ECS 如何管理 EC2 的 Auto Scaling Group.
ECS Capacity Providers 是于 2019 年 12 月发布的,随同的功能支持了 Fargate, Fargate Spot, 和 EC2 AutoScaling. 而 Managed Instances 在 2025-09-30 才加入的新特性,见 Announcing Amazon ECS Managed Instances.
在近六年之间, AWS 大概也理解到了 Capacity Provider + EC2 Auto Scaling 的复杂性,虽说可由 ECS 来管理 EC2 的 ASG, 但毕竟有个 ASG 在那里。 ECS 与 EC2 ASG 之间联接由 CloudWatch Metrics, Alarms, EC2 ASG 的 Dynamic scaling policies 和 Lifecycle hooks 的一整套机制协作。 经常还不得不在 EC2 ASG 与 ECS 两个界面之间来回找问题。而 Managed Instances 的出现则将 EC2 实例的管理完全透明化了,在 EC2 端压根就不存在 一个相应的 ASG, 更不需要 CloudWatch Alarms 之类的关联组件。
Managed Instances 与 EC2 Auto Scaling 之间就好比 Serverless 与 非 Serverless 的区别,用 Managed Instances 之后你只管控制好 ECS Desired Count(ECS AutoScaling), 其余的都由 Managed Instances 来管理,在界面上只需要关注 ECS Infrastructure 中的 Container Instances. 由 Managed Instances 管理的 EC2 实例,你即使用有管理员权限都无法关闭它,只能全权由 Managed Instances 来控制。试图关闭这样的 EC2 实例时报错

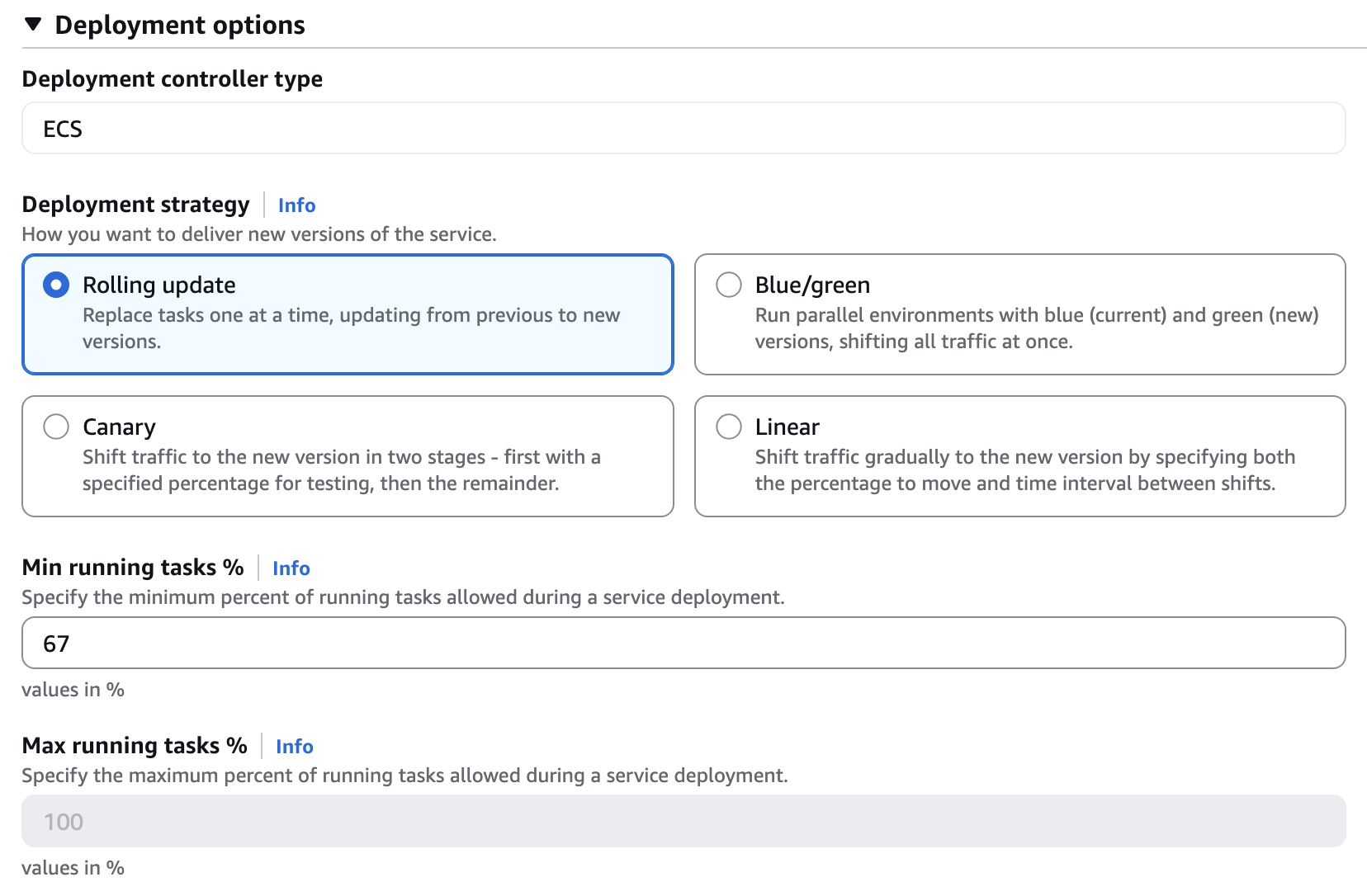
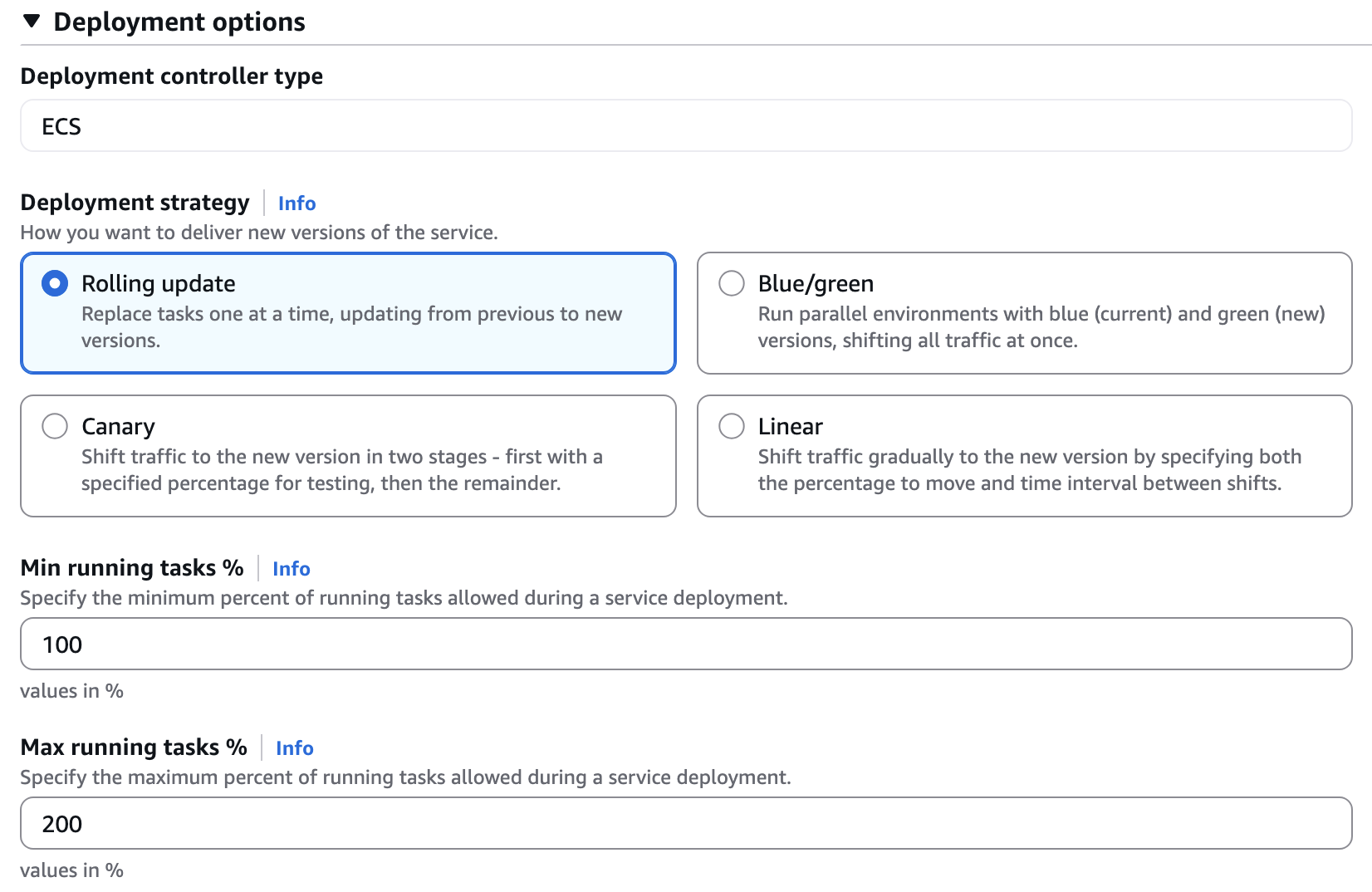
相比于 ECS 直接用 EC2(ASG),通过 Capacity Provider 使用 EC2 的方式,还有一个好处就是可以实现 Min and max running tasks: 100% min and 200% max 的部署方式,即启动与当前等量的任务来替换全部旧任务,即使是高峰期也能较安心的部署。而 ECS 直接用 EC2 的时只能实现 Min and max running tasks: max 最大 100%, 部署时不得不先关掉部分旧任务,再启动新任务来替换,造成部署过程中减少任务数影响到吞吐率.
| ECS 直接使用 EC2, Max running task % 锁定在 100% | ECS 通过 Capacity Provider 的 EC2, 没有 100% 的限制 |
|---|---|
 |  |
Managed Instances 可以配置 vCPU, Memory, GPU 等约束条件,在运行时由 Capacity Provider 自动为你选择 EC2 实例类型. 而对于计算型的任务 还是较倾向于直接锁定 EC2 的实例类型, 如 AMD CPU 的 c8a.4xlarge 等。
下面是一个 Web 应用部署实例,使用 t3.medium 实例类型,它有 2 vCPU, 4 GiB 内存, Web 任务需要 1 vCPU, 1 GiB 内存,这样实际在一个
t3.medium 实例上可以运行 2 个 Web 任务。
下面是相关的 Terraform 脚本如下
capacity-provider.tf
1resource "aws_ecs_capacity_provider" "ec2" {
2 name = "ec2-capacity-provider"
3 cluster = aws_ecs_cluster.main.name
4
5 managed_instances_provider {
6 infrastructure_role_arn = aws_iam_role.ecs_infrastructure.arn
7 propagate_tags = "CAPACITY_PROVIDER"
8
9 infrastructure_optimization {
10 scale_in_after = 300
11 }
12 instance_launch_template {
13 ec2_instance_profile_arn = var.ecs_instance_profile_arn
14 storage_configuration {
15 storage_size_gib = 30
16 }
17
18 network_configuration {
19 subnets = var.subnet_ids
20 security_groups = var.ec2_security_groups
21 }
22
23 instance_requirements {
24 vcpu_count {
25 min = 2
26 }
27
28 memory_mib {
29 min = 4096
30 }
31 allowed_instance_types = ["t3.medium"]
32 burstable_performance = "included"
33 }
34 }
35 }
36 tags = {
37 Name = "test-cp"
38 }
39}
40
41data "aws_iam_policy_document" "ecs_infra_trust" {
42 statement {
43 actions = ["sts:AssumeRole"]
44 effect = "Allow"
45 principals {
46 type = "Service"
47 identifiers = ["ecs.amazonaws.com"]
48 }
49 }
50}
51
52resource "aws_iam_role" "ecs_infrastructure" {
53 name = "ECSInfraRole"
54 assume_role_policy = data.aws_iam_policy_document.ecs_infra_trust.json
55}
56
57resource "aws_iam_role_policy_attachment" "ecs_infrastructure" {
58 role = aws_iam_role.ecs_infrastructure.name
59 policy_arn = "arn:aws:iam::aws:policy/AmazonECSInfrastructureRolePolicyForManagedInstances"
60}
通过 allowed_instance_types = ["t3.medium"] 来锁定使用 t3.medium 类型,注意 cpu 和 memory 的配置不能与此有冲突,并且 t3.medium
是 burstable 的类型, 所以必须加上 burstable_performance = "included" 才能选择到.
infrastructure_role_arn 需要指定为一个有 arn:aws:iam::aws:policy/AmazonECSInfrastructureRolePolicyForManagedInstances
policy, 能被 ecs.amazonaws.com assume 的 IAM role 即可。
使用 Managed Instances 时 EC2 除了可以指定 Security group, subnets, storage 外,其他都几乎都不能自定义。比如 AMI 是由
Managed Instances 指定的,像 ecs-managed-instances-standard-x86_64-20260220222634, 它是专门优化的,并且 EC2 会每 14
天被自动更新一次,来保证安全和性能的优化。
ecs.tf
1resource "aws_ecs_cluster" "main" {
2 name = "test-cp"
3 setting {
4 name = "containerInsights"
5 value = "enabled"
6 }
7}
8
9resource "aws_ecs_service" "main" {
10 name = "my-service"
11 cluster = aws_ecs_cluster.main.id
12 task_definition = aws_ecs_task_definition.main.arn
13 desired_count = 1
14 network_configuration {
15 subnets = var.subnet_ids
16 security_groups = var.ec2_security_groups
17 }
18
19 capacity_provider_strategy {
20 capacity_provider = aws_ecs_capacity_provider.ec2.name
21 base = 1
22 weight = 1
23 }
24
25 load_balancer {
26 target_group_arn = aws_lb_target_group.main.arn
27 container_name = "my-container"
28 container_port = 80
29 }
30}
31
32resource "aws_ecs_task_definition" "main" {
33 family = "my-task"
34 requires_compatibilities = ["MANAGED_INSTANCES","EC2"]
35 network_mode = "awsvpc"
36
37 container_definitions = jsonencode([
38 {
39 name = "my-container"
40 image = "strm/helloworld-http"
41 cpu = 1024
42 memory = 1024
43 stopTimeout = 5
44 portMappings = [
45 {
46 containerPort = 80
47 hostPort = 80
48 protocol = "tcp"
49 }
50 ]
51 }
52 ])
53}
54
55resource "aws_appautoscaling_target" "ecs_target" {
56 max_capacity = 10
57 min_capacity = 1
58 resource_id = "service/${aws_ecs_cluster.main.name}/${aws_ecs_service.main.name}"
59 scalable_dimension = "ecs:service:DesiredCount"
60 service_namespace = "ecs"
61}
Network 采用了 vpc, 每个容器将会从 VPC 获得自己的 IP 地址,Security Group 更易配置,初始启动一个任务。实际项目中应创建 ECS 的 AutoScaling
规则来控制 Desired Count, 后面测试将手工来调节。
elb.tf
1resource "aws_lb" "test-cp" {
2 name = "test-cp-lb"
3 internal = true
4 subnets = var.subnet_ids
5 security_groups = var.elb_security_groups
6
7}
8
9resource "aws_lb_listener" "main" {
10 port = 80
11 protocol = "HTTP"
12 load_balancer_arn = aws_lb.test-cp.arn
13 default_action {
14 type = "forward"
15 target_group_arn = aws_lb_target_group.main.arn
16 }
17}
18
19resource "aws_lb_target_group" "main" {
20 name = "test-cp-tg"
21 port = 80
22 protocol = "HTTP"
23 vpc_id = var.vpc_id
24 target_type = "ip"
25}
单纯测试 Managed Instances 类型的 Capacity Provider 可以不用建立 ELB, 作为一个较完备的应用还是加上这一层。
在运行以上的 Terraform 脚本时,请填入对应环境的以下变量
1 subnet_ids
2 ecs_instance_profile_arn
3 elb_security_groups
4 ec2_security_groups
5 vpc_id
准备好 AWS Credentials, 再补上 AWS Provider 后, 运行
1terraform init
2terraform apply-auto-approve
成功后会产生整个架构。在 ECS cluster test-cp 的 Infrastructure 将会看到
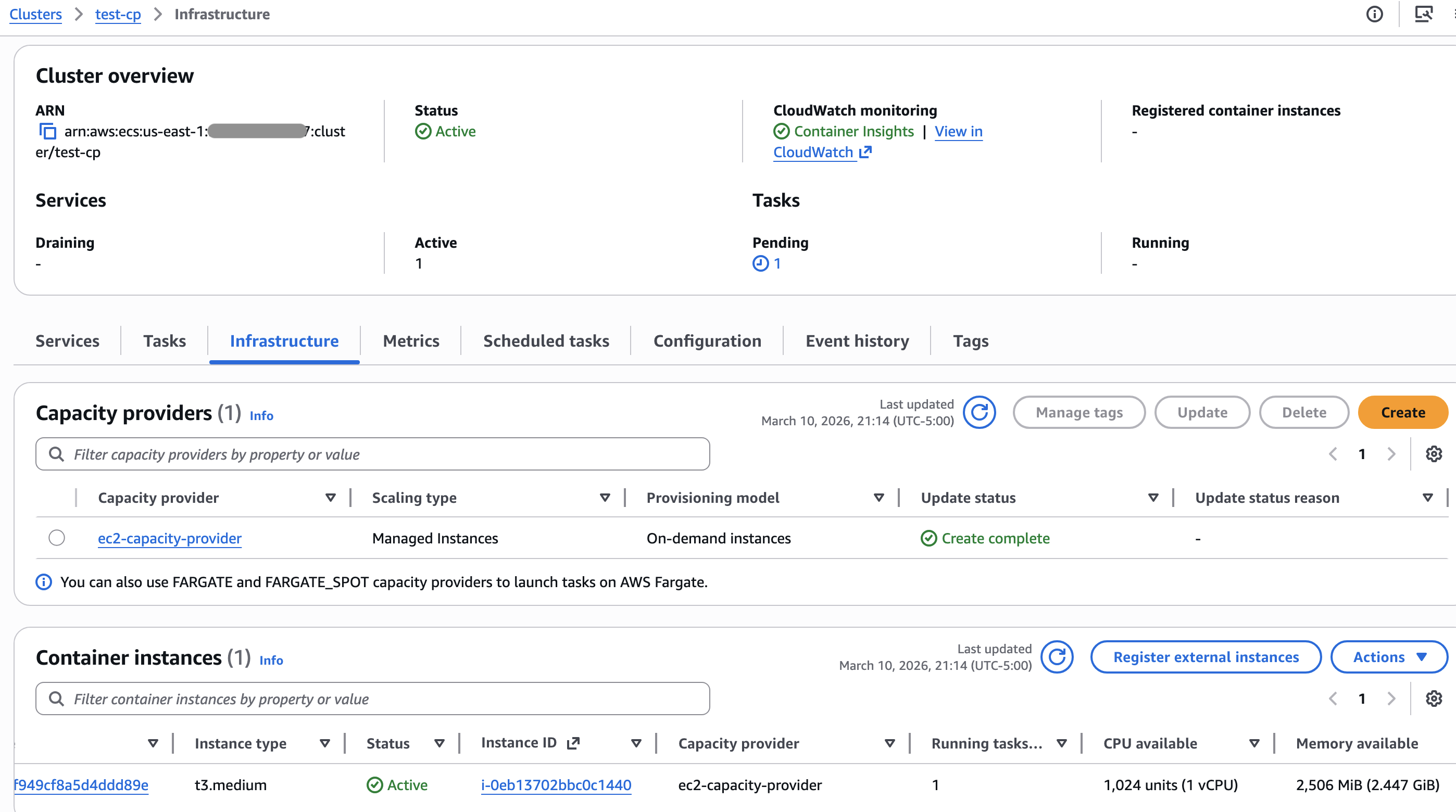
使用了 Managed Instances 的 Capacity Provider 的管理界面就只要这个就行了。对于相应 EC2 的管理十分有限,不能指定 key_name,
也没有 Session Manager 可以连,不能自定义 userdata, 可以说 Managed Instances 产生的 EC2 是无法管理的。
由 Managed Instances 生成的 EC2 的 userdata 内容为
1[settings.ecs]
2cluster = 'arn:aws:ecs:us-east-1:123456789000:cluster/test-cp'
3awsvpc-block-imds = true
4[settings.two]
5platform-revision = 'Linux-X86_64-1.0.0-55'
6available-memory = 3530
下面是 Capacity Provider 的界面

下面直接改变 ECS Service my-service 的 Desired Count
- Desired Count 为 2: 因现有
t3.medium实例上还有充足的 CPU/Memory 资源,所以直接在其上运行一个新任务
- Desired Count 为 3:由于现有实例 CPU 资源不足,所以必须新启一个 EC2 实例来运行新的任务

- Desired Count 为 4 时又会在新的 EC2 实例上运行一个新任务, 这里就不再往测试了
- 现在把 Desired Count 改为 2:发现从运行两个 Task 的 EC2 上停掉了一个任务,而不是从运行一个任务的 EC2 实例上停掉任务

再等了很久,也是用两个 EC2 实例各自运行一个 Task, 从资源来讲有些浪费, 看来还是优先考虑性能,也不会把一个任务从一个 EC2 实例上挪到另一个去。
- 把 Desired Count 改为 1,

那么什么时候会把空闲的 EC2 实例关闭呢?大概等了七八分钟,没有运行任务的 EC2 上出现 Deregistrating, 并且一两秒间从该列表中消失了。

剩下的事情就是 Capacity Provider 把该 EC2 实例也结束掉。
最后只省下一个 EC2 实例

而且这个是更老的 EC2 实例,Capacity Provider` 优先关闭新的 Task.
如果 Container 实例卡在了 ACTIVE 或 DRAINING 状态,但无法关闭或运行任务,需要用命令强行注销,命令是
1aws ecs deregister-container-instance --cluster <cluster-name> --container-instance <id> --force
在删除 Capacity Provider 时可能会碰到 Cannot remove capacity provider. It is either part of the default strategy or has non stopped tasks
可以先把与之关联的 Service 的 Desired Count 设为 0, 等待任务都停掉了, 确保与它相关的 Container Instances 被清理掉,这时可以先删除
Service, 再删除 Capacity Provider 就不会有问题了。
Task 的 host' 和 awsvpc` Network 模式
使用 Managed Instances 时,ECS Task 的 Network 模式只支持 host 和 awsvpc. 默认为 host 模式。这里就有个问题了,如果启动一个 EC2,
vCPU 和 Memory 满足多个 ECS Task 时,如何用 host 模式运行多个任务呢?如果是 bridge 模式还好说,用不同的本地端口与容器内商品,比如
32768:8080, 32769:8080 来映射,那用 host 如何支持多个容器呢?
总不能在 EC2 宿主机上启动两个 8080 端口吧?当然不能,所以选择 host 网络模式时,只能在一个 EC2 上运行一个 Task, 在已有的 EC2 实例上有足够的
CPU/Memory 资源剩余来运行另一个 Task 也没用,相当于是 EC2 到 ECS Task 的 Daemon 模式,在 Target Group 上注册的也是 EC2 的 Instance ID.
相比于 bridge 模式(Managed Instances 不支持),host 的网络效率要高,因为省去了端口映射的 NAT 过程。
那选择 awsvpc Network 模式呢?和直接使用 EC2 时用 awsvpc 模式类似,每个容器都会使用一个独立的 ENI 来获得一个独立的 IP 地址,每个 ENI
上就可以使用相同的端口来运行多个 Task 了。
但 AWS 在 Web 控制台界面上显示有所不同,如果是在自己管理 EC2 的上,选择 awsvpc 模式运行 ECS Task 时,在 EC2 实例上会显示至少两个
private IPv4 地址,EC2 本身的 IP + 每个任务的 IP. 而使用 Managed Instances 时选择 awsvpc 时,在 EC2 实例上只会显示一个自身的 IP
地址, 任务的独立 IP 要在任务属性中才能看到。
这时,在 Target Group 上注册的就是每一个 Task 容器的 IP 地址了,而不是 EC2 实例的 IP 地址了。
如果一个 Managed Instance 中只运行一个 Task, 那么用 host Network 模式更省事,不需要额外的 ENI, 如果要在一个 EC2 实例上运行多个任务的话,
只能选择 awsvpc 网络模式。
[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。