《从零构建大模型》阅读笔记(一) - 分词和嵌入
读完《Hands-On Large Language Models》又回头重新看《Build a Large Language Model from Scratch》一书,阅读时零乱记点什么。
大语言模型构建通常包括两个阶段: 预训练(pre-training)和微调(fine-tuning), 有时也把偏好调优当作一个单独阶段,其实也是一种形式的微调。 预训练使用未标注的大量文本数据理解语言结构,即自监督学习,预训练生成的模型为基础模型(base/foundation model), 这能够完成文本预测任务。 再经过指令微调或分类任务微调后就能回答问题或进行分类了。
Transformer 架构最初由 Google 于 2017 年的论文 "Attention is All You Need" 提出,它已成为了现代大语言模型的基础架构,基本上 LLM 指的就是这种架构。 Transformer 的两个子模块:编码器(encoder)和解码器(decoder), 一大关键组件是自注意力机制(self-attention), 使模型能够捕捉输入序列中不同位置之间的关系和依赖性。 Transformer 的并行处理能力和长距离依赖建模能力使其成为了训练大规模语言模型的理想选择。Transformer 的变体有 BERT(Bidirectional Encoder Representations from Transformers)、GPT(Generative Pre-trained Transformer)等。
GPT-3 基础模型预训练数据集为过滤后的 Common Crawl, WebText2, Book1, Books2, 和 Wikipedia, 在共 3000 亿 Token 上进行训练, 文本压缩后大小为 700G 左右。Llama 扩展了它的训练数据范围,包括 Arxiv 论文(92G)和 StackExchange 上的代码问答(78G)。训练基础模型成本极高, GPT-3 的预训练成本高达 460 万美元。
分词和嵌入相关的概念有 BPE(byte pair encoding), word2vec. GPT-2 参数 117M, 词嵌入维度是 768, GPT-3 参数 175B, 它的词嵌入维度是 12,288。
简单实现一个分词,使用小说 "The Verdict" 的文本内容 the-verdict.txt 中的词汇创建一个分词器,不包含在其中的词标识为 "<|unk|>".
1import re
2
3split_pattern = re.compile(r'([,.:;?_!"()\']|--|\s)')
4cleanup_pattern = re.compile(r'\s+([,.?!"()\'])')
5
6# 按标点符号,空格拆分,结果也包含标点符号本身,并过滤掉纯空白字符串
7def split_text(text: str) -> list[str]:
8 return [t for t in split_pattern.split(text) if t.strip()]
9
10class SimpleTokenizerV1:
11 TOKEN_UNKNOWN = "<|unk|>"
12 SPECIAL_TOKENS = ["<|endoftext|>", TOKEN_UNKNOWN]
13
14 def __init__(self, all_words: list[str]):
15 vocab = list(all_words) + self.SPECIAL_TOKENS
16 self.str_to_int = {word: i for i, word in enumerate(vocab)}
17 self.int_to_str = {v: k for k, v in self.str_to_int.items()}
18
19 def encode(self, text: str) -> list[int]:
20 unk_id = self.str_to_int[self.TOKEN_UNKNOWN]
21 return [self.str_to_int.get(t, unk_id) for t in split_text(text)]
22
23 def decode(self, ids: list[int]) -> str:
24 text = " ".join(self.int_to_str.get(i, self.TOKEN_UNKNOWN) for i in ids)
25 return cleanup_pattern.sub(r'\1', text) # 移除特定符号前的空格
26
27def create_tokenizer() -> SimpleTokenizerV1:
28 with open("the-verdict.txt", "r") as f:
29 raw_text = f.read()
30
31 all_words = sorted(set(split_text(raw_text)))
32 return SimpleTokenizerV1(all_words)
33
34if __name__ == '__main__':
35 tokenizer = create_tokenizer()
36
37 text = """"It's the last he painted, you know,"
38 Mrs. Gisburn said with pardonable pride.
39 Hello, do you like tea?"""
40
41 ids = tokenizer.encode(text)
42 print("encode: ", ids)
43 print("decode: ", tokenizer.decode(ids))
取 the-verdict.txt 中全部单词含标点符号,去重后排序,再加上两个特殊的 Token, <|endoftext|>, <|unk|>, 然后映射为列表中的索引.
执行结果
1encode: [1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7, 1131, 5, 355, 1126, 628, 975, 10]
2decode: " It' s the last he painted, you know," Mrs. Gisburn said with pardonable pride. <|unk|>, do you like tea?The Verdict 中没有 Hello, 所以被标记为 <|unk|>. 在不同的大语言模型还会加入其他的特殊 Token,如
- [BOS] Beginning Of Sequence: 标记文本的起点
- [EOS] End Of Sequence: 标记文本的结束,类似 <|endoftext|>, 特别是用于连接多个不相关的文本,比如两篇不同的文章用
[EOS]分隔开来 - [PAD] Padding: 当使用 batch size 大于 1 的批量数据训练 LLM 时,数据文本长度不一,用
[PAD]填充匹配到最大的文本长度
GPT 模型仅使用 <|endoftext|>, 它与 [EOS] 作用相似,此外 <|endoftext|> 也常用于文本填充,即作为 [PAD] 来用。GPT 分词器也不使用
<|unk|> 来处理超出词汇表范围的 Token, 而是使用 BPE 分词器将其拆分成更小的子词(subword) 来处理。
BPE (Byte Pair Encoding) 分词器
GPT-2, GPT-3 和 ChatGPT 原始模型用的 BPE 分词方案,用 Python 库 tiktoken(当前版本 0.13) 来体验一下
1import tiktoken
2
3tokenizer = tiktoken.get_encoding("gpt2")
4text = "your 明, how are you? <|endoftext|> In someunknownPlace."
5ids = tokenizer.encode(text, allowed_special={"<|endoftext|>"}) # 用于识别输入中的 <|endoftext|> 为特殊 token
6
7# 出错: ValueError: Encountered text corresponding to disallowed special token '<|endoftext|>'.
8# ids = tokenizer.encode(text)
9print(ids)
10
11print(tokenizer.decode(ids))
12
13for id in ids:
14 print(f"{id}: '{tokenizer.decode([id])}'")
输出为
1[5832, 10545, 246, 236, 11, 703, 389, 345, 30, 220, 50256, 554, 617, 34680, 27271, 13]
2you 明, how are you? <|endoftext|> In someunknownPlace.
35832: 'you'
410545: ' �'
5246: '�'
6236: '�'
711: ','
8703: ' how'
9389: ' are'
10345: ' you'
1130: '?'
12220: ' '
1350256: '<|endoftext|>'
14554: ' In'
15617: ' some'
1634680: 'unknown'
1727271: 'Place'
1813: '.'
- 中文
明拆成了三个 Token, 打印时没问题,单个 Token 解码后显示乱码 - Token 自带空格,表示是否与前相连,如
you: 5832,you: 345 是两个不同的 Token. - <|endoftext|> 它被分配了一个最大的 Token ID, 比如用于训练 GPT-2, GPT-3, ChatGPT 的原始模型词表大小为 50257, 最后一个 ID 50256 即是 <|endoftext|>
- BPE 碰到未知的单词,如
someunknownPlace, 会将其拆分成更小的子词甚至单个字符,所以它不需要特殊 Token <|unk|> - tokenizer(gpt2) 的一些信息,
eot_token: 50256,max_token_value: 50256,n_vocab: 50257,special_tokens_set: {'<|endoftext|>'}
list(tiktoken.registry.ENCODING_CONSTRUCTORS.keys()) 中包含了以下 encoding
['gpt2', 'r50k_base', 'p50k_base', 'p50k_edit', 'cl100k_base', 'o200k_base', 'o200k_harmony']
对比一下这几个 encoding
| encoding | eot_token | max_token_value | n_vocab | special_tokens_set |
|---|---|---|---|---|
| gpt2 | 50256 | 50256 | 50257 | {'<|endoftext|>'} |
| r50k_base | 50256 | 50256 | 50257 | {'<|endoftext|>'} |
| p50k_base | 50256 | 50280 | 50281 | {'<|endoftext|>'} |
| p50k_edit | 50256 | 50283 | 50284 | {'<|endoftext|>', '<|fim_middle|>', '<|fim_prefix|>', '<|fim_suffix|>'} |
| cl100k_base | 100257 | 100276 | 100277 | {'<|endofprompt|>', '<|endoftext|>', '<|fim_middle|>', '<|fim_prefix|>', '<|fim_suffix|>'} |
| o200k_base | 199999 | 200018 | 200019 | {'<|endofprompt|>', '<|endoftext|>'} |
| o200k_harmony | 199999 | 201087 | 201088 | {'<|call|>', '<|channel|>', '<|constrain|>', '<|endofprompt|>', '<|endoftext|>', '<|end|>', '<|message|>', '<|reserved_200000|>', '<|reserved_200001|>', ... '<|reserved_201087|>', '<|return|>', '<|startoftext|>', '<|start|>'} |
上表中 p50k_base 的 eot_token 是 50256, 但词汇大小为 50281, 那么它们之间是什么, 用代码查看一下
1tokenizer = tiktoken.get_encoding("p50k_base")
2for code in range(50256, 50281):
3 print(f"{code}:'{tokenizer.decode([code])}'")
输出
150256:'<|endoftext|>'
250257:' '
350258:' '
450259:' '
550260:' '
6.....................
750280:' '
后面全部是不断增加的空格, 而 o200k_harmony 中有大量的保留 Token, 从 <|reserved_200000|> 到 <|reserved_201087|>。
使用滑动窗口进行数据采样
为了让模型能预测下一个 Token, 接下来准备训练模型的输入-目标对,这和监督学习中的对照学习很类似

如上图,使用上下文长度为 4 的滑动窗口,蓝色窗口生成一个 input, 红色窗口是右移一个 Token 产生相应的 target. 窗口大小,input 与 target 窗口(context), 偏移(步幅-stride) 是可以调整,stride 小的话,input 与 target 的重叠部分较大。这种从 input 到 target 的训练就可以用来训练预测下一个 Token. 实际要的 input/target 对是转换为数字 Token 列表, 在 PyTorch 中 input/target 存储为两个 Tensor 对。
下面是从 the-verdict.txt 中创建训练数据(dataloader)的完整代码
1import torch
2import tiktoken
3from torch.utils.data import Dataset, DataLoader
4
5class GPTDatasetV1(Dataset):
6 def __init__(self, full_text, tokenizer, max_length, stride):
7 self.input_ids = []
8 self.target_ids = []
9
10 token_ids = tokenizer.encode(full_text)
11
12 for i in range(0, len(token_ids) - max_length, stride):
13 input_chunk = token_ids[i:i + max_length]
14 target_chunk = token_ids[i + 1:i + max_length + 1]
15 self.input_ids.append(torch.tensor(input_chunk))
16 self.target_ids.append(torch.tensor(target_chunk))
17
18 def __len__(self):
19 return len(self.input_ids)
20
21 def __getitem__(self, idx):
22 return self.input_ids[idx], self.target_ids[idx]
23
24def create_dataloader_v1(full_text, batch_size=4, max_length=256, stride=128,
25 shuffle=True, drop_last=True, num_workers=0):
26 tokenizer = tiktoken.get_encoding("gpt2")
27 dataset = GPTDatasetV1(full_text, tokenizer, max_length, stride)
28 dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=shuffle,
29 drop_last=drop_last, num_workers=num_workers
30 )
31 return dataloader
32
33
34with open("the-verdict.txt", "r") as f:
35 raw_text = f.read()
36
37dataloader = create_dataloader_v1(raw_text, batch_size=1, max_length=4, stride=1, shuffle=False)
dataloader 是可迭代的,我们查看第一次迭代的内容
1print(next(iter(dataloader)))
[tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]
如果调整 batch_size 为 2,重新构建 dataloader, 查看第一个元素就是
1[
2 tensor([[ 40, 367, 2885, 1464], [ 367, 2885, 1464, 1807]]),
3 tensor([[ 367, 2885, 1464, 1807], [2885, 1464, 1807, 3619]])
4]
对输出进行了格式化,这样一个批次可以包含两套 input/target 对,对内存占用会更高,不仅是内存的影响,较小的批次大小还会导致在模型更新时产生更多的噪声。 这里 max_length=4 也是为了演示,实际训练大语言模型时,输入大小通常不小于 256; stride(步幅)决定了重叠的大小,过多的重叠可能会增加模型的过拟合风险。
从 dataloader.dataset, 或 dataloader.sampler.datasource, dataloader.batch_sampler.sampler.data_source 下可以看到 input_ids 和 target_ids 这两个 tensor 列表对

创建 Token 嵌入(Embeddings)
下一步要把 Token 映射到向量空间去,该向量空间又叫潜空间(Latent Space), 由于类 GPT 大语言模型是使用反向传播算法(backpropagation algorithm) 训练的深度神经网络,因此需要连续的向量表示或嵌入。
读到这里有点迷糊,向量空间是什么,Token 怎么嵌入到向量空间去,向量空间的每个维度的分向量是什么?下面以一个简单的例子来由浅入深地理解。
假如我们有一个仅含 6 个单词的小型词汇表,并且想要创建维度为 3 的嵌入(BPE GPT-2 的词汇大小为 50,257, 嵌入维度是 768), 理解了小的再往大拓展。
1vocab_size = 6
2output_dim = 3
然后用 PyTorch 实例化一个嵌入层,为确保结果的可复现(能与书中保持一致),设置随机种子为 123
1torch.manual_seed(123)
2embedding_layer = torch.nn.Embedding(vocab_size, output_dim) # nn 是 Neural Network 的缩写
3embedding_layer.weight
这会产生一个权重矩阵
1Parameter containing:
2tensor([[ 0.3374, -0.1778, -0.1690],
3 [ 0.9178, 1.5810, 1.3010],
4 [ 1.2753, -0.2010, -0.1606],
5 [-0.4015, 0.9666, -1.1481],
6 [-1.1589, 0.3255, -0.6315],
7 [-2.8400, -0.7849, -1.4096]], requires_grad=True)
以上矩阵每一行代表一个 Token, 每个 Token 用大小为 3 维的向量表示,每个维度代表某种特征。扩展为 GPT-2 的就是一个 50257 x 768 大小的矩阵。
注:有一种独热编码(one-hot encoding) 方式,比如用
[[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]
每行只有对应该 Token 索引的一位为 1,其余全为 0,用来唯一标识一个 Token。
如果我们有多个 Token IDs, 从向量空间 6 x 3 中找出与其对应的三维嵌入向量
1embedding_layer(torch.tensor([2, 3, 2, 1]))
Token ID 即索引,所以从全词汇表向量空间取出对应以上 Token 的三维嵌入向量矩阵(或者说把 [2, 3, 2, 1 ] 嵌入 3 维的向量中)
1tensor([[ 1.2753, -0.2010, -0.1606],
2 [-0.4015, 0.9666, -1.1481],
3 [ 1.2753, -0.2010, -0.1606],
4 [ 0.9178, 1.5810, 1.3010]], grad_fn=<EmbeddingBackward0>)
按照 [2, 3, 2, 1] 中表示的索引从 6 x 3 的矩阵中取出相应的行组成新的矩阵。
编码单词位置信息
大语言模型的自注意力机制(self-attention mechanism) 无法感知 Token 在序列中的位置或顺序,因为它本质上与位置无关。 从前一节的 [2, 3, 2, 1], 其中相同的 Token 2 都转换为相同的向量表示,嵌入位置信息能区分语序和捕捉长短距离依赖,以提升大语言模型对 Token 顺序及其相互关系的理解能力,从而实现更准确,更具上下文感知力的预测。
有两种位置信息嵌入策略,
- 绝对位置嵌入(absolute positional embedding), 像 Vim 中设置
set norelativenumber, 绝对的位置编号 1,2,3,4..., 如正弦/余弦固定编码 (Sinusoidal PE), 可学习位置编码(Learnable Positional Encoding) - 相对位置嵌入(relative positional embedding), 关注 Token 之间的相对位置或距离,像 Vim 中可设置
set relativenumber, 显示 ...3,2,1,10,1,2,3...,如旋转位置编码 RoPE
GPT 模型使用的是可学习绝对位置嵌入,先来看它的实现原理
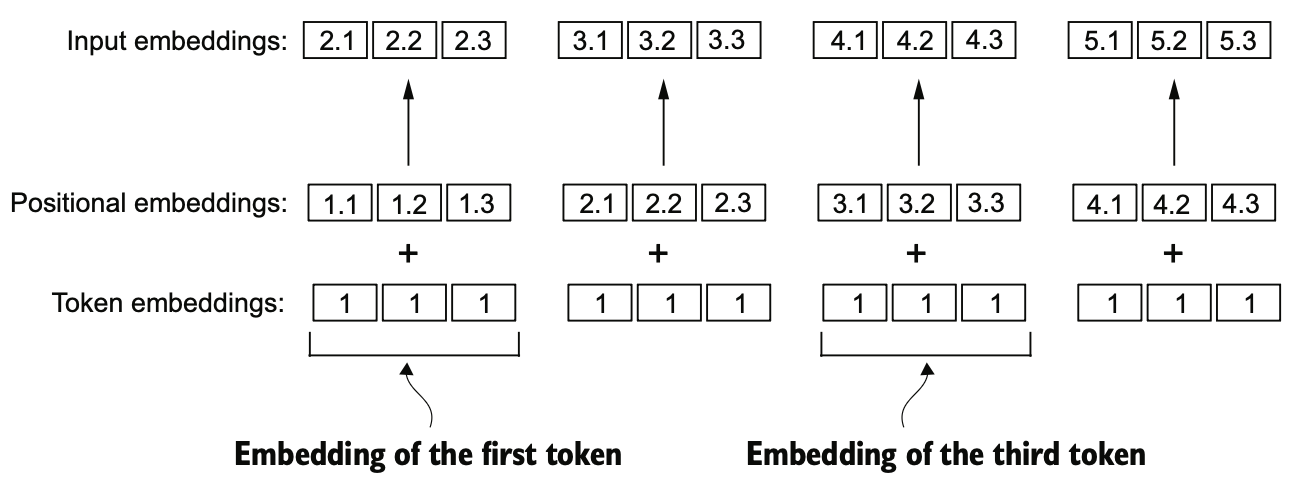
假如文本有四个重复的单词,转换成四个相同的 Token, 得到相同的 Token 嵌入 [1, 1, 1], 第一个向量加上位置嵌入 [1.1, 1.2, 1.3], 可以理解为点号前表示当前 Token 的位置信息,点号后表示向量内部各分量的位置信息,合起来 [2.1, 2.2, 2.3] 就表示了每一个分量在嵌入矩阵中的绝对信息。
这种方式需要预先初始化一个 (预训练最大长度 * 编码维度) 的矩阵作为位置向量,并把位置编码作为可训练参数,它的缺点是没有外推性,假如预训练的最大长度为 512 的话,它最多只能处理长度为 512 的输入,再长就无法处理或者要进行截断。GPT 新版的模型或许有办法来突破输入长度限制。
正弦/余弦固定编码,又称三角位置编码(Trigonometric Positional Encoding), 是一种很神奇的编码方式,它通过计算偶数维分量的正弦函数, 奇数维分量的余弦函数来计算出位置编码。
RoPE(Rotary Position Embedding) 已成为现代大语言模型的位置编码事实上的标准, RoPE 通过旋转 Q、K 向量,使得 QKᵀ 点积自然包含两个 token 的相对距离,不需要单独设计相对位置模块。
跳过书中的可学习位置编码的实现细节,后面如果自己实现一个简单 GPT 的话将会采用 RoPE 相对编码方式。
永久链接 https://yanbin.blog/build-a-large-language-model-from-scratch-reading-notes-1/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。