《从零构建大模型》阅读笔记(二) - 自注意力
来到第三章,关于注意力机制(attention mechanism), Transformer 可以说是由《Attention Is All You Need》这篇论文起的火,那 Attention 几乎就是 Transformer, 也就是现代 LLM 的核心。在学习 Attention 之前先通过类比的方式理解一下什么是注意力机制,以及为什么取名为 Attention 这个词.
当你读到一句话里某个词时,你的大脑不会孤立地看这个词,而是会"环顾四周"——看看其他词,决定哪些词对理解当前这个词最有帮助,然后把注意力集中在那些词上。 LLM 的 Attention 机制,做的正是同一件事。而且通常看书时,多是翻看前面的部分,帮助当前的理解,找到故事的因果关系, 很少查阅后面的内容, 这就是因果注意力.
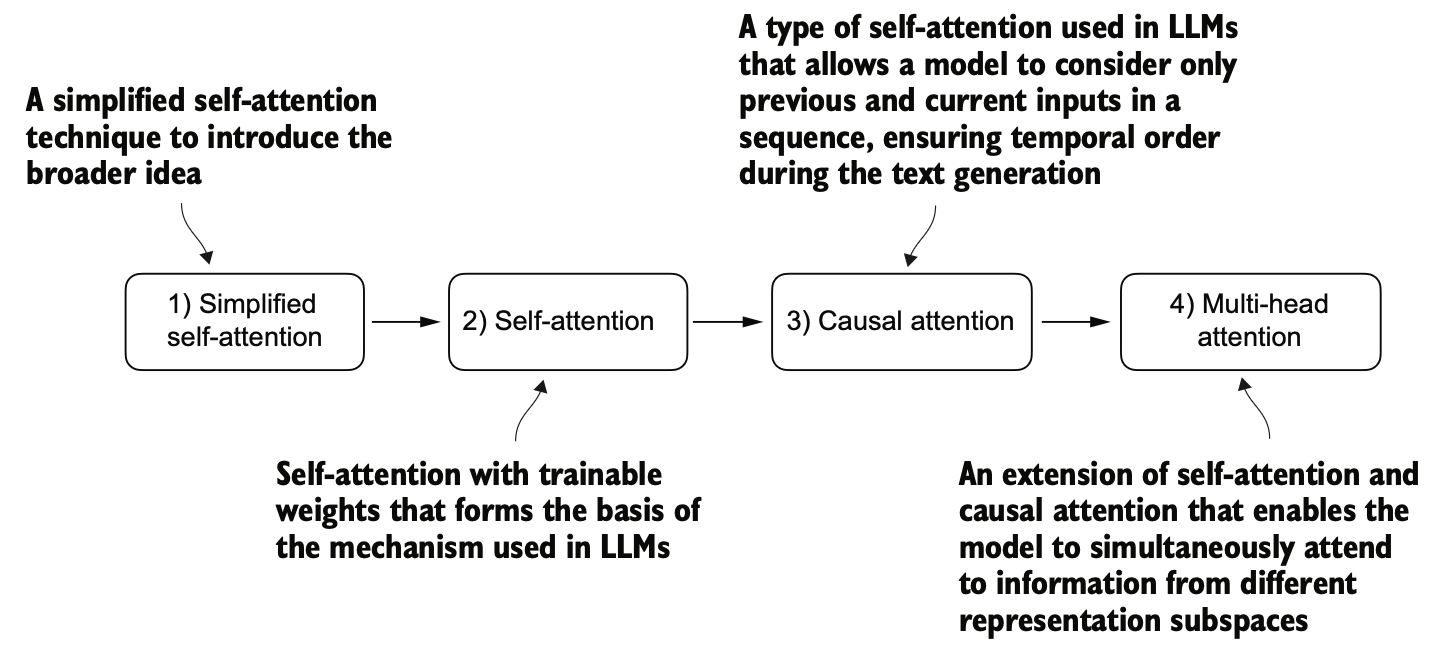
本章将由浅入深的介绍以下 Attention 各种变体的原理和实现细节。
- 简化的自注意力(Simplified self-attention)
- 自注意力(Self-attention): 带有可训练权重的自注意力机制
- 因果注意力(Causal attention): 只关注序列中先前和当前的输入,从而保持文本生成的时间顺序
- 多头注意力(Multi-head attention): 自注意力和因果注意力的组合,可同时关注来自不同表示子空间的信息
自注意力机制 允许输入序列中的每个位置关注同一序列中所有位置并权衡重要性,这是基于 Transformer 架构的当代大语言模型的关键组成部分,
也是最具挑战性的部分之一。
没有可训练权重的简单自注意力
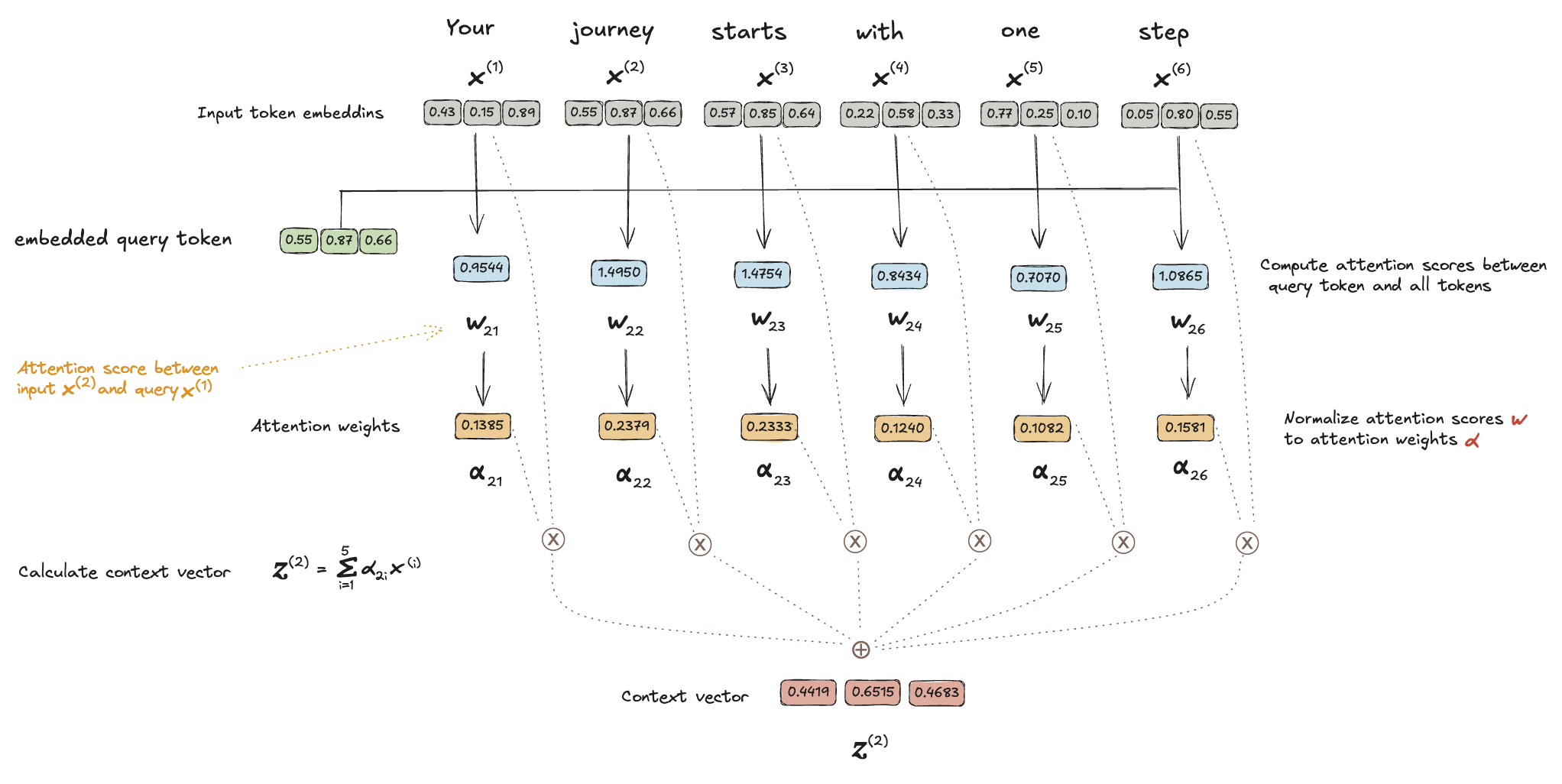
假如我们有一行文本 Your journey starts with one step 以单词进行分词,并嵌入到如下 3 维向量空间中,我们将学习在自注意力机制中,
为输入序列中的每个 token x(i) 如何计算相应的上下文向量(context vector) 𝒛(i).
1import torch
2
3inputs = torch.tensor([
4 [0.43, 0.15, 0.89], # Your (x¹)
5 [0.55, 0.87, 0.66], # journey (x²)
6 [0.57, 0.85, 0.64], # starts (x³)
7 [0.22, 0.58, 0.33], # with (x⁴)
8 [0.77, 0.25, 0.10], # one (x⁵)
9 [0.05, 0.80, 0.55], # step (x⁶)
10])
计算两两 Token 嵌入向量之间的注意力分数 W
以 x(2) (journey) 为例计算它相应的上下文向量 𝒛(2), 这个增强的上下文向量 𝒛(2) 也是一个嵌入, 它包含了关于 x(2) 及其他所有输入元素的信息。
1query = inputs[1]
2attn_scores_2 = torch.empty(inputs.shape[0])
3for i, x_i in enumerate(inputs):
4 attn_scores_2[i] = torch.dot(x_i, query)
5print(attn_scores_2)
每个输入 Token 的向量与查询 Token 的向量进行点积操作的值即为相应的注意力分数.
点积(dot products) 本质上就是两个向量相同位置的值相乘再求和,如 0.43*0.55+0.15*0.87+0.89*0.66=0.9544. 点积也是度量两个向量相似度的一种方式,
它表示两个向量夹角的余弦值(夹角为 0 度时余弦值最大,即方向相同时相似度最高)和模长, 点积越大,相似度越高。在自注意力机制中,
点积决定了序列中每个元素对其他元素的关注程度, 点积越大,两个元素之间的相似度和注意力分数就越高。
1tensor([0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865])
注意到 x2 自己与自己算相似度的话应该是最相近的, 从以上的值看 1.4950 也确实是所有分数中最高的。
对注意力分数归一化(normalize) 为注意力权重
这里归一化处理后得到相应的注意力权重,我们很容易被归一化(normalize)这个听起来高大上的词吓倒,归一化从字面上理解为把数值归到 [0,1] 区间去,
或者把总和归为 1. 普通的归一化就是除以它们的总和,即把不在 [0,1] 之间的值转换为这个区间的值,俗称 weight. 比如两个人各有 6 和 4 个苹果,
转换为 weight 就是分别为 6/(6+4)=0.6 和 4/(6+4)=0.4, 这两个值就在 [0,1] 之间了。
前面算出的注意力分数有 [0,1] 区间外的值,如 1.4950, 1.4754, 1.0865, 下面作一个简单的归一化, 实际代码就是第一行
1attn_weights_2_tmp = attn_scores_2 / attn_scores_2.sum()
2print("Attention weights:", attn_weights_2_tmp)
3print("Sum:", attn_weights_2_tmp.sum())
输出归一化后的各个权重值和总和为
1Attention weights: tensor([0.1455, 0.2278, 0.2249, 0.1285, 0.1077, 0.1656])
2Sum: tensor(1.0000)
这种归一化有时叫 sum normalization 或 simplex projection, 而在实际应用中,特别是对于这种概率分布的情况,用 softmax 函数进行归一化更为常见,
这种方法能更好地处理极值,并在训练期间提供更有利的梯度特性。
1attn_weights_2 = torch.softmax(attn_scores_2, dim=0)
2print("Attention weights:", attn_weights_2)
3print("Sum:", attn_weights_2.sum())
得到的结果是
1Attention weights: tensor([0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581])
2Sum: tensor(1.)
我们可以从 softmax 的基础实现理解它的工作原理
1 def softmax_naive(x):
2 return torch.exp(x) / torch.exp(x).sum(dim=0)
3
4 attn_weights_2_naive = softmax_naive(attn_scores_2)
5 print("Attention weights:", attn_weights_2_naive)
6 print("Sum:", attn_weights_2_naive.sum
这段代码输出的值与使用 torch.softmax() 结果是一致的,只是这种简单的 softmax_naive 在处理大输入或小输入值时可能会遇到数值稳定性问题,
比如溢出和下溢,PyTorch 的 softmax 经受过了大量的实践检验和性能优化.
torch.exp(x) 对每个元素求了自然指数 ex, 它有两个功能:
- 把负数变成正数 (ex 总是为正数)
- 放大差异 (大的指数级变大,小的值趋近于 0)
计算上下文向量 𝒛(2):
有了归一化的注意力权重后,接下来是最后一步,将所有输入 Token 的嵌入向量与相应的注意力权重相乘并求和,得到嵌入维度(这里是 3)相同的上下文向量 𝒛(2):
1query = inputs[1]
2context_vec_2 = torch.zeros(query.shape) # 嵌入维度是 3, 所以它的形状是 (3)
3for i, x_i in enumerate(inputs): # 6 个 Token,所以循环 6 次
4 context_vec_2 += attn_weights_2[i] * x_i
5print(context_vec_2)
输出
1tensor([0.4419, 0.6515, 0.5683])
上下文向量与嵌入向量的维度是一样的.
书中的这行代码 query = inputs[1] 可能会让人有点误解,其实单这一步与第二个 Token 的嵌入(inputs[1]) 是没有直接关系的,只是 torch.zeros(query.shape)
构造了与嵌入维度(3) 相同的一个向量. 不过循环中用到的 attn_weights_2 确实是 inputs[1] 与输入中的每一个 Token 计算出来的相应权重值。
这里的例子是针对 x2 计算出相应的上下文向量 𝒛(2), 用同样的方式可计算出其他所有的 𝒛(i) 值。
下面是魔幻一样的 PyTorch 矩阵操作计算 attention 分数,权重,以及 context vector 的三行代码
1attn_scores = inputs @ inputs.T # 计算所以注意力分数,inputs.T 是矩阵的转置, 行列互换,匹配维度才能进行矩阵乘法
2attn_weights = torch.softmax(attn_scores, dim=-1) # softmax 归一化, 在最后一个维度上归一化
3all_context_vecs = attn_weights @ inputs # 加权求和得 context vector
@ 是矩阵乘法运算符, 矩阵乘法的规则是内维度相等,即 [m X n] X [p X q] 时要求 n==p.
打印出以上三个矩阵的值,可以对比一下前面有关 x2 的计算结果,看看是否一致
1print(f"attention scores: \n{attn_scores}\n")
2print(f"attention weights: \n{attn_weights}\n")
3print(f"all_context_vecs: \n{all_context_vecs}")
所有值
1attention scores:
2tensor([[0.9995, 0.9544, 0.9422, 0.4753, 0.4576, 0.6310],
3 [0.9544, 1.4950, 1.4754, 0.8434, 0.7070, 1.0865],
4 [0.9422, 1.4754, 1.4570, 0.8296, 0.7154, 1.0605],
5 [0.4753, 0.8434, 0.8296, 0.4937, 0.3474, 0.6565],
6 [0.4576, 0.7070, 0.7154, 0.3474, 0.6654, 0.2935],
7 [0.6310, 1.0865, 1.0605, 0.6565, 0.2935, 0.9450]])
8
9attention weights:
10tensor([[0.2098, 0.2006, 0.1981, 0.1242, 0.1220, 0.1452],
11 [0.1385, 0.2379, 0.2333, 0.1240, 0.1082, 0.1581],
12 [0.1390, 0.2369, 0.2326, 0.1242, 0.1108, 0.1565],
13 [0.1435, 0.2074, 0.2046, 0.1462, 0.1263, 0.1720],
14 [0.1526, 0.1958, 0.1975, 0.1367, 0.1879, 0.1295],
15 [0.1385, 0.2184, 0.2128, 0.1420, 0.0988, 0.1896]])
16
17all_context_vecs:
18tensor([[0.4421, 0.5931, 0.5790],
19 [0.4419, 0.6515, 0.5683],
20 [0.4431, 0.6496, 0.5671],
21 [0.4304, 0.6298, 0.5510],
22 [0.4671, 0.5910, 0.5266],
23 [0.4177, 0.6503, 0.5645]])
如果把 attn_scores = inputs @ inputs.T 拆解为两两点积计算 attention 分数的方式就要用两层循环
1attn_scores = torch.empty(inputs.shape[0], inputs.shape[0])
2for i, x_i in enumerate(inputs):
3 for j, x_j in enumerate(inputs):
4 attn_scores[i, j] = torch.dot(x_i, x_j)
5print(attn_scores)
这种没有可训练权重的简单自注意力,实际上几乎没有实用价值,不过它把注意力机制的核心思想表达了出来,在下一节中我们还会回顾这一部分的内容。
实现带可训练权重的自注意力机制
在原始的 Transformer 架构,GPT 模型和多数其他流行的大语言模型中使用的自注意力机制又叫做缩放点积注意力(scaled dot-product attention).
在前面简单自注意力机制中,我们计算了某个特定的输入对于序列中所有输入向量的加权和得到相应的上下文向量,所有输入 Token 的上下文向量就组成了一个上下文矩阵。 现在要往其中引入在模型训练期间可更新的权重矩阵,有了这些权重矩阵,模型(特别是模型内部的注意力模块) 才能学会产生 "好的" 上下文向量。
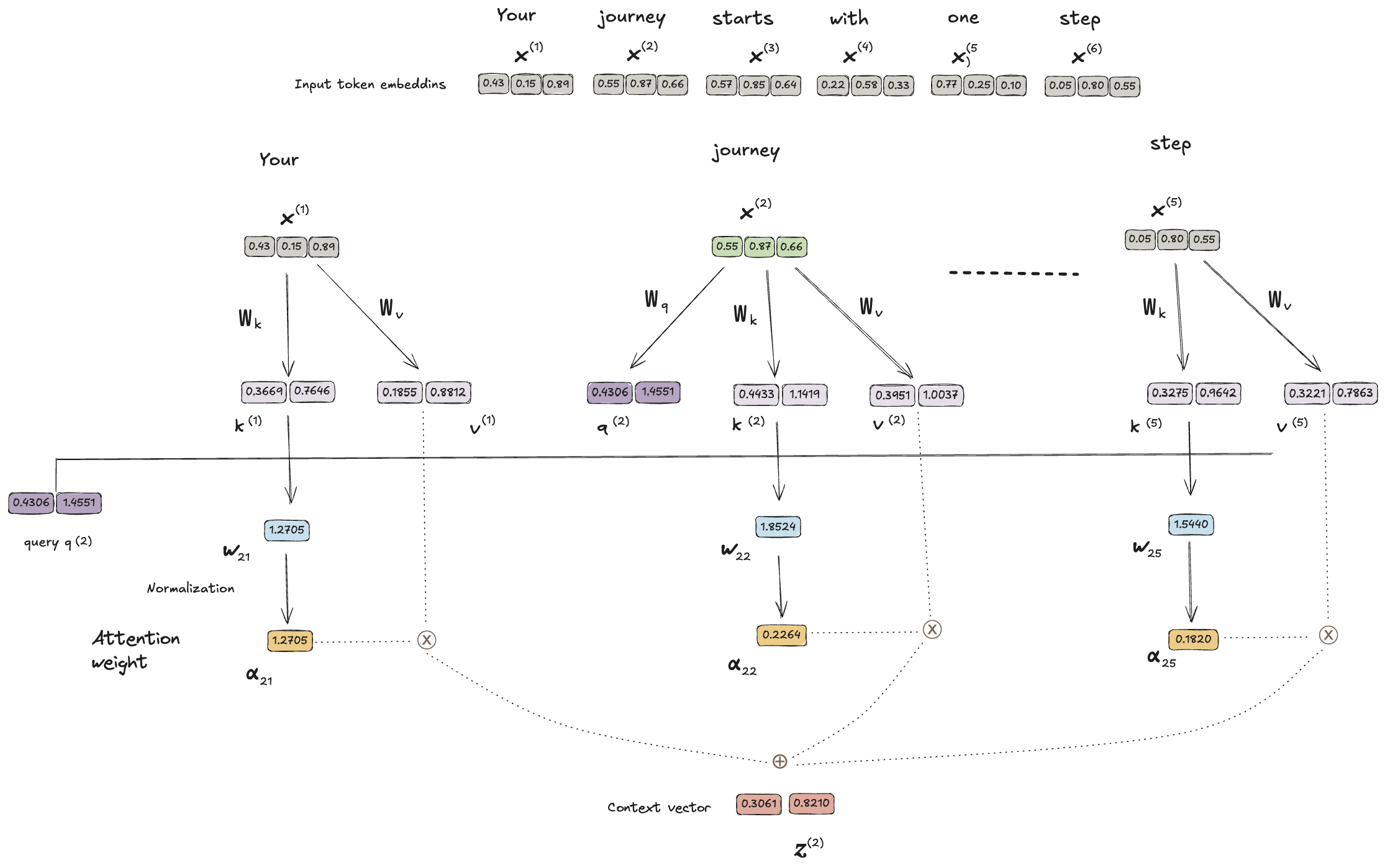
逐步计算注意力权重
上一节介绍了简单注意力机制如何算得某一个输入 Token 的上下文向量(context vector), 计算的过程如下
- 计算 Token 之间的相似度分数(点积)
- 相似度分数归一化(softmax)
- 加权求和得到 context vector(和嵌入维度相同)
下面要引入 Wq, Wk, 和 Wv 这三个可训练的权重矩阵, 计算 context vector 的途径将有一些变化。
对于某一个输入 Token, 我们将通过 Wq, Wk, 和 Wv 来计算得到最后的上下文向量, 由于 Wq, Wk, 和 Wv 的权重矩阵是可在训练过程中更新的,所以训练好的 Wq, Wk, 和 Wv 就是引导着计算出更好的上下文向量,这也是训练的意义所在。 当然 LLM 还有更多的其他可训练参数,如 FFN 前馈网络层中的 W1, W2(有时还有 W3) 等。
同样,便于说明我们只计算第二个 Token(journey) x2 对应的上下文向量 𝒛(2)
先定义几个变量,并为该 Attention 初始化相应的 W_query, W_key, W_value
1x_2 = inputs[1]
2d_in = inputs.shape[1] # 维度 3
3d_out = 2 # 定义输出维度为 2
4
5torch.manual_seed(123)
6W_query = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=True)
7W_key = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=True)
8W_value = torch.nn.Parameter(torch.rand(d_in, d_out), requires_grad=True)
9
10print(f"{W_query=}\n\n {W_key=}\n\n {W_value=}") # 每个的形状都是 [3,2]
在 GPT 模型中,输入和输出向量的维度通常是相同的,这里为了便于理解计算过程,设置了 d_in=3 和 d_out=2 不同的维度。由于 torch.manual_seed(123)
硬编码了随机数种子,所以用 torch.rand(d_in, d_out) 生成的 W_query, W_key, 和 W_value 的值是固定的。输出如下
1W_query=Parameter containing:
2tensor([[0.2961, 0.5166],
3 [0.2517, 0.6886],
4 [0.0740, 0.8665]], requires_grad=True)
5
6 W_key=Parameter containing:
7tensor([[0.1366, 0.1025],
8 [0.1841, 0.7264],
9 [0.3153, 0.6871]], requires_grad=True)
10
11 W_value=Parameter containing:
12tensor([[0.0756, 0.1966],
13 [0.3164, 0.4017],
14 [0.1186, 0.8274]], requires_grad=True)
设置 requires_grad=True 以便在训练中更新这些矩阵,即不冻结该权重矩阵。
训练时通过反向传播更新 Wq, Wk, 和 Wv 的权重矩阵
- Wq: 学会 “怎么提问”,推理时表示 "我想找什么"
- Wk: 学会 “怎么被匹配”,推理时表示 "我能被什么匹配"
- Wv: 学会 "提取什么内容"
推理时,针对当前的 Token
- Wq: 表示 "我想找什么",变成一个提问向量
- Wk: 表示 "我有什么",用来和 query 匹配
- Wv: 表示 "我能提供什么",找到实际要提取的内容
接下来,计算查询向量,键向量,和值向量
1query_2 = x_2 @ W_query # x_2 形状是 [3], W_query 形状是 [3,2], 输出 query_2 的形状是 [2]
2key_2 = x_2 @ W_key
3value_2 = x_2 @ W_value
4print(f"{query_2=}\n{key_2=}\n{value_2=}")
输出为
1query_2=tensor([0.4306, 1.4551], grad_fn=<SqueezeBackward4>)
2key_2=tensor([0.4433, 1.1419], grad_fn=<SqueezeBackward4>)
3value_2=tensor([0.3951, 1.0037], grad_fn=<SqueezeBackward4>)
以 query_2 = x_2 @ W_query 为例,这里把 x(2) 通过 W_query 投影到一个新的空间,从 3 维压缩到 2 维,生成 query_2
向量,即把当前 token 嵌入变换成有效的提问向量, key_2 和 value_2 的操作类似。
在权重矩阵 W 中, "权重" 是 "权重参数" 的简称,表示在训练过程中优化的神经网络参数,这与注意力权重是不同的。 注意力权重决定了上下文向量对输入的不同部分的依赖程度。
我们的目标仍然是计算一个上下文向量 𝒛(2), 仍然需要所有输入 Token 的键向量和值向量,可以用矩阵乘法得到所有的键向量和值向量
1keys = inputs @ W_key
2values = inputs @ W_value
3print(f"{keys.shape=}, {values.shape=}") # keys.shape=torch.Size([6, 2]), values.shape=torch.Size([6, 2])
成功地将所有 6 个 token 从三维空间映射到了二维(d_out=2) 嵌入空间.
接下来计算注意力分数,这就回到了我们前面那个简单注意力机制的轨道上来了,可以想见,再后面就是 softmax 归一化和加权求和得到上下文向量了.
计算单个 query_2 与 keys_2 的相似度分数,用点积的方式
1keys_2 = keys[1]
2attn_scores_22 = query_2.dot(key_2)
3print(attn_scores_22) # tensor(1.8524, grad_fn=<DotBackward0>)
或者由矩阵乘法的方式计算 query_2 与所有 keys 的相似度分数
1attn_scores_2 = query_2 @ keys.T
2print(attn_scores_2) # tensor([1.2705, 1.8524, 1.8111, 1.0795, 0.5577, 1.5440], grad_fn=<SqueezeBackward4>)
第 2 个 1.8524 是一样的.
再将注意力分数归一为注意力权重
1d_k = keys.shape[-1]
2attn_weights_2 = torch.softmax(attn_scores_2 / d_k**0.5, dim=-1)
3print(attn_weights_2) # tensor([0.1500, 0.2264, 0.2199, 0.1311, 0.0906, 0.1820], grad_fn=<SoftmaxBackward0>)
这里经过一次缩放注意力分数,通过将注意力分数除以键向量的嵌入维度的平方根来进行缩放,可防止点积值过大导致 softmax 梯度消失.
最后一步就是由注意力权重,针对值向量进行加权求和得到上下文向量
1context_vector_2 = attn_weights_2 @ values
2print(context_vector_2) # tensor([0.3061, 0.8210], grad_fn=<SqueezeBackward4>)
最后小结一下引入 Wq, Wk, 和 Wv 这三个可训练权重矩阵后,计算上下文向量的过程如下
- 通过 Wk, 和 Wv 算出所有 token(包括自己) 的 k, v 向量,再用 Wq 计算出当前 token 的 q 向量
- 由 q 向量计算与每个 token 的 k 向量的注意力分数
- 归一化注意力分数为注意力权重
- 注意力权重与每个 token 的 v 向量加权求和得到上下文向量
自注意力包含的可训练权重矩阵 Wq, Wk, 和 Wv 随着模型在训练中接触更多的数据,它会调整其中的权重参数, 从而在第 1 步就影响到计算 q, k, v 向量值,最终影响上下文向量的值。
另外, 目前常被提及的 KV Cache 指的就是通过 Wk, 和 Wv 计算出来的 k, v 向量的缓存,避免了在生成文本时每次都要重新计算 k, v 向量,从而提高了推理效率。
把带有 Q, K, V 的自注意力实现为 Python 类
前面逐步演示了如何通过三个可训练的矩阵来计算上下文向量,下面实现为 Python 类,有两个版本
1import torch
2import torch.nn as nn
3
4
5class SelfAttentionV1(nn.Module):
6
7 def __init__(self, d_in, d_out):
8 super().__init__()
9
10 # 创建注意力对象是创建三个 q, k, v 权重矩阵
11 self.W_query = nn.Parameter(torch.rand(d_in, d_out))
12 self.W_key = nn.Parameter(torch.rand(d_in, d_out))
13 self.W_value = nn.Parameter(torch.rand(d_in, d_out))
14
15 # 前向传播时调用
16 def forward(self, x):
17 keys = x @ self.W_key
18 queries = x @ self.W_query
19 values = x @ self.W_value
20
21 attn_cores = queries @ keys.T # 计算注意力分数
22 attn_weights = torch.softmax(attn_cores / keys.shape[-1] ** 0.5, dim=-1) # 归一化为注意力权重
23 context_vec = attn_weights @ values # 在值向量上加权求和得到上下文向量
24 return context_vec
这里直接使用了 torch.nn.Module 作为基类,当把输入传给注意力的时候,nn.Module 会自动调用前向传播方法 forward(), 计算出上下文向量。
测试一下
1torch.manual_seed(123)
2sa_v1 = SelfAttentionV1(3, 2)
3print(sa_v1(inputs))
得到
1tensor([[0.2996, 0.8053],
2 [0.3061, 0.8210],
3 [0.3058, 0.8203],
4 [0.2948, 0.7939],
5 [0.2927, 0.7891],
6 [0.2990, 0.8040]], grad_fn=<MmBackward0>)
第 2 个 token 的上下文向量是 [0.3061, 0.8210],与前面分步算出来的是一样的。
还可以使用 PyTorch 的 nn.Linear 层来进一步优化上一个 SelfAttentionV1 的实现,nn.Linear 提供了优化的权重初始化方案,
从而有助于模型训练的稳定性和有效性。
1class SelfAttentionV2(nn.Module):
2
3 def __init__(self, d_in, d_out, qkv_bias=False):
4 super().__init__()
5 self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
6 self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
7 self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
8
9 def forward(self, x):
10 # 线性层会自动进行矩阵乘法并添加偏置项(如果有的话)
11 keys = self.W_key(x)
12 queries = self.W_query(x)
13 values = self.W_value(x)
14
15 attn_cores = queries @ keys.T # 计算注意力分数
16 attn_weights = torch.softmax(attn_cores / keys.shape[-1] ** 0.5, dim=-1) # 归一化为注意力权重
17 context_vec = attn_weights @ values # 在值向量上加权求和得到上下文向量
18 return context_vec
nn.Linear() 初始化了不一样的权重值,所以在测试时会得到不一样的输出结果,上下文向量中分量值可以是负的。
下面的内容将是因果注意力(causal attention) 和多头注意力(multi-head attention) 的实现细节,将在下一篇笔记本记载。
小结
本文学习了两种注意力机制,简单注意力机制和带可训练参数的注意力机制, 下面再重复一遍它们的计算步骤,帮助加深理解
从简单注意力机制中我们学习了注意力机制的目标是计算输入 Token 的上下文向量,其计算方式步骤是
- 计算 Token 之间的相似度分数(点积)
- 相似度分数归一化(softmax)
- 加权求和得到 context vector(和嵌入维度相同)
注意力引入三个可训练权重矩阵(Wq, Wk, 和 Wv) 后,其计算上下文向量的步骤为
- 通过 Wk, 和 Wv 算出所有 token(包括自己) 的 k, v 向量,再用 Wq 计算出当前 token 的 q 向量
- 由 q 向量计算与每个 token 的 k 向量的注意力分数
- 归一化注意力分数为注意力权重
- 注意力权重与每个 token 的 v 向量加权求和得到上下文向量
[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。