《从零构建大模型》阅读笔记(三) - 因果和多头注意力
接下来,我们将改进自注意力机制,引入因果机制和多头机制。因果机制是让模型预测只访问前序的 token,多头机制是将注意力机制分成多个 "头", 每个头关注数据的不同特征,以提升模型在复杂任务中的性能.
使用因果注意力(causal attention) 隐藏未来词汇
前一文学过的自注意力,对于当前 token 会计算它与所有 token 的注意力分数(相似度),而因果注意力(又称掩码注意力: masked attention)在预测时只需关注当前和前序 token. 这是符合前因后果自然逻辑的,还是拿读书作类比,想要弄清楚当前在讲什么,我们只用去翻看前面有过什么说明与铺叙.
现在将通过标准自注意力机制来创建因果注意力机制,对于每个处理的 token, 需要遮盖住当前 token 之后的 token,参考以下两个图:
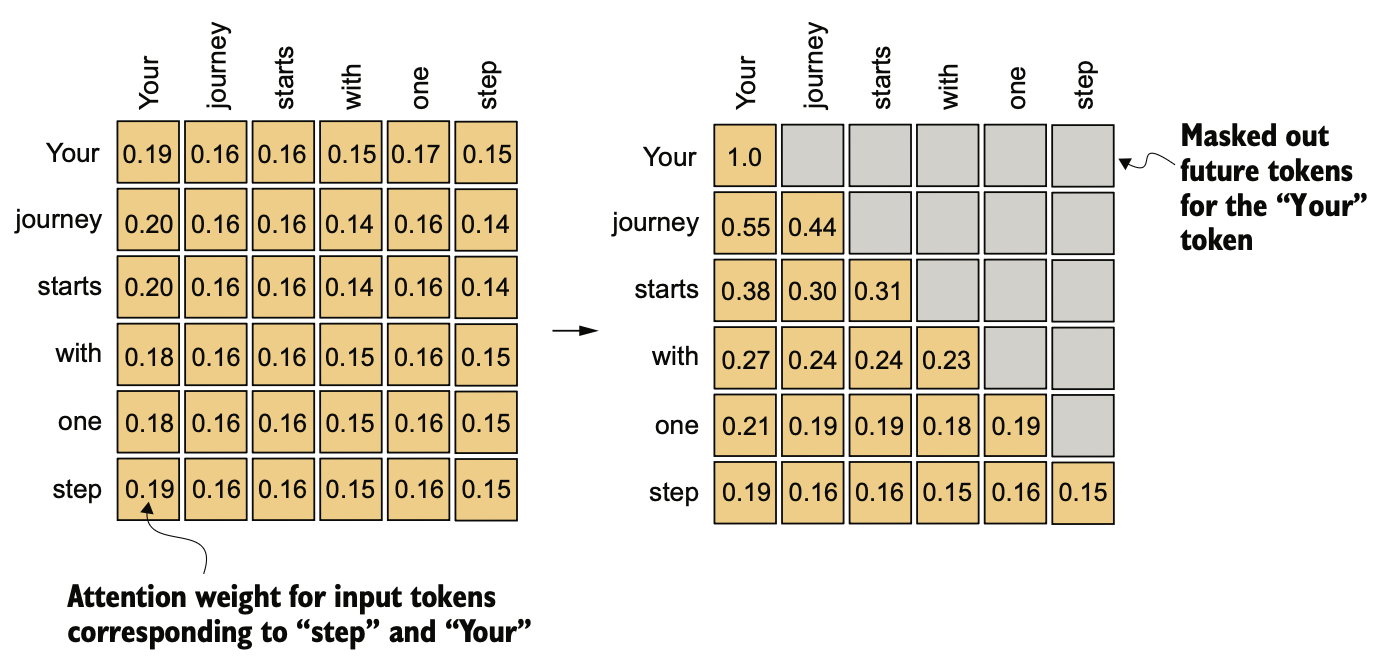
左图是标准注意力机制,在按序处理每一个输入 token 时会计算它与所有 token 的注意力分数,而右图的因果注意力机制,只关注当前 token 之前的 token, 比如处理第一个 token "Your" 时只关注它自己,处理第二个 token "journey" 时只关注 "Your" 和 "journey" 两个 token, 以此类推.
对于一个矩阵,把左上到右下对角线以上的元素都置为零的操作叫做取下三角矩阵(Lower Triangular Matrix), 或下三角化(Lower triangularization),
NumPy 中的 np.tril 函数可以实现这个操作. transformers.AutoModelForCausalLM 类就是用来加载因果注意力机制的模型.
因果注意力的掩码实现
上一节在看到遮盖对角线以上 token 的图时, 首先想到矩阵的下三角化操作,这也是只关注当前及前序 token 的一种阅读和思考方式。继续往下阅读, 发现因果注意力机制在遮盖后序 token 的操作确实是在作矩阵的下三角化操作.
参考上一篇 SelfAttentionV2, 重复如下
1import torch.nn as nn
2import torch
3
4class SelfAttentionV2(nn.Module):
5
6 def __init__(self, d_in, d_out, qkv_bias=False):
7 super().__init__()
8 self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
9 self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
10 self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
11
12 def forward(self, input):
13 # 线性层会自动进行矩阵乘法并添加偏置项(如果有的话)
14 keys = self.W_key(input)
15 queries = self.W_query(input)
16
17 attn_cores = queries @ keys.T # 计算注意力分数
18 attn_weights = torch.softmax(attn_cores / keys.shape[-1] ** 0.5, dim=-1) # 归一化为注意力权重
19 print(attn_weights)
20
21 values = self.W_value(input)
22 context_vec = attn_weights @ values # 在值向量上加权求和得到上下文向量
23 return context_vec
把计算值向量移到加权求和之前, 并打印出注意力权重 attn_weights, 如下代码使用 SelfAttentionV2
1if __name__ == '__main__':
2 inputs = torch.tensor([
3 [0.43, 0.15, 0.89], # Your (x^1)
4 [0.55, 0.87, 0.66], # journey (x^2)
5 [0.57, 0.85, 0.64], # starts (x^3)
6 [0.22, 0.58, 0.33], # with (x^4)
7 [0.77, 0.25, 0.10], # one (x^5)
8 [0.05, 0.80, 0.55], # step (x^6)
9 ])
10
11 torch.manual_seed(789)
12 sa_v2 = SelfAttentionV2(3, 2)
13 print(sa_v2(inputs))
输出归一化后的注意力权重是
1tensor([[0.1921, 0.1646, 0.1652, 0.1550, 0.1721, 0.1510],
2 [0.2041, 0.1659, 0.1662, 0.1496, 0.1665, 0.1477],
3 [0.2036, 0.1659, 0.1662, 0.1498, 0.1664, 0.1480],
4 [0.1869, 0.1667, 0.1668, 0.1571, 0.1661, 0.1564],
5 [0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.1585],
6 [0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
7 grad_fn=<SoftmaxBackward0>)
对这个注意力权重下三角化
1masked_attn_weights = torch.tril(attn_weights)
2print(masked_attn_weights)
输出为
1tensor([[0.1921, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
2 [0.2041, 0.1659, 0.0000, 0.0000, 0.0000, 0.0000],
3 [0.2036, 0.1659, 0.1662, 0.0000, 0.0000, 0.0000],
4 [0.1869, 0.1667, 0.1668, 0.1571, 0.0000, 0.0000],
5 [0.1830, 0.1669, 0.1670, 0.1588, 0.1658, 0.0000],
6 [0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
7 grad_fn=<TrilBackward0>)
下一步要对下三角化的注意力权重矩阵重新进行归一化,用简单的归一化操作
1row_sums = masked_attn_weights.sum(dim=-1, keepdim=True)
2masked_attn_weights_norm = masked_attn_weights / row_sums
3print(masked_attn_weights_norm)
归一化后每一行之和为 1
1tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
2 [0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],
3 [0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],
4 [0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],
5 [0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],
6 [0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
7 grad_fn=<DivBackward0>)
注意力权重矩阵中把对角线以上的分量值置为零后,这就消除了未来 token 对计算当前 token 的上下文向量的影响.
有更简单的方式,在得到注意力分数(attn_cores)后直接对对角线以上部分进行 -♾️掩码操作

用代码来实现
1mask = torch.ones_like(attn_cores).triu(diagonal=1) # 创建上三角掩码,遮盖未来位置
2masked_attn_cores = attn_cores.masked_fill(mask.bool(), -torch.inf)
3attn_weights = torch.softmax(masked_attn_cores / keys.shape[-1] ** 0.5, dim=1) # 归一化为注意力权重
4print(attn_weights)
这样算出来的 attn_weights 和前面的 masked_attn_weights_norm 是一样的,都是
1tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
2 [0.5517, 0.4483, 0.0000, 0.0000, 0.0000, 0.0000],
3 [0.3800, 0.3097, 0.3103, 0.0000, 0.0000, 0.0000],
4 [0.2758, 0.2460, 0.2462, 0.2319, 0.0000, 0.0000],
5 [0.2175, 0.1983, 0.1984, 0.1888, 0.1971, 0.0000],
6 [0.1935, 0.1663, 0.1666, 0.1542, 0.1666, 0.1529]],
7 grad_fn=<SoftmaxBackward0>)
这样完整的 forward() 方法是
1 def forward(self, input):
2 # 线性层会自动进行矩阵乘法并添加偏置项(如果有的话)
3 keys = self.W_key(input)
4 queries = self.W_query(input)
5
6 attn_cores = queries @ keys.T # 计算注意力分数
7 mask = torch.ones_like(attn_cores).triu(diagonal=1) # 创建上三角掩码,遮盖未来位置
8 masked_attn_cores = attn_cores.masked_fill(mask.bool(), -torch.inf)
9 attn_weights = torch.softmax(masked_attn_cores / keys.shape[-1] ** 0.5, dim=1) # 归一化为注意力权重
10
11 values = self.W_value(input)
12 context_vec = attn_weights @ values # 在值向量上加权求和得到上下文向量
13 return context_vec
这里有个疑问,虽然对 attn_cores 注意力分数把未来 token 掩盖住了,但计算 q, k, v 三个向量时都用到了完整 input(所有 token)?
回答自己的问题,比如对于一段提示词,前半部分告诉模型要做什么,后加一堆的约束条件,如果大语言模型在生成输出前不通读一遍完整的提示,仅仅根据当前 token 和前序 token 来预测下一个 token 的话,最好的输出结果肯定不能满足提示词中的约束条件.
利用 dropout 掩码额外的注意力权重
dropout 是一种仅在深度学习训练期间使用的技术(训练结束后会取消),训练过程中随机忽略一些隐藏层单元,以减少对特定隐藏层单元的依赖,从而避免过拟合。 在 Transformer 架构中,通常会在两个地方使用 dropout: 1) 计算注意力权重之后,2) 将这些权重应用于值向量之后(不就是得到上下文向量之后吗?)
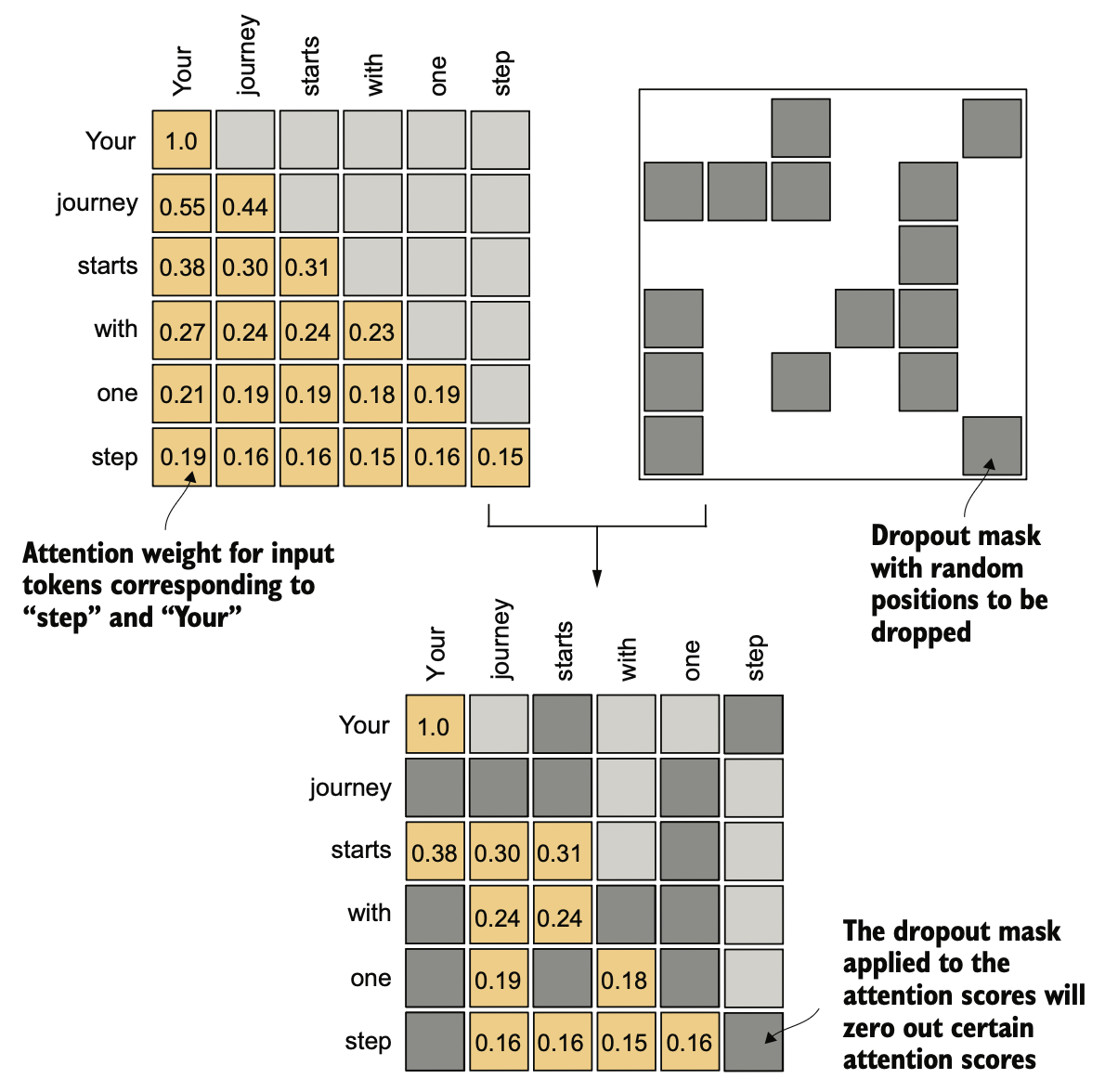
该图中是把 dropout 掩码操作放在计算注意力权重之后, 左上是因果注意力权重矩阵,右上角的值被 Mask 了,右上是按 50% 生成的一个 6x6(input token 数为 6) 的 dropout 掩码矩阵,下中是把注意力权重矩阵和 dropout 掩码矩阵进行元素级乘法得到的最终注意力权重矩阵.
先了解一下 Dropout 类的行为
1torch.manual_seed(123) # 让同样 dropout 率时被遮盖的元素位置每次都相同
2dropout = torch.nn.Dropout(0.5) # 50% dropout 率
3example = torch.ones(3, 4) # 生成一个全是 1 的矩阵
4print(dropout(example))
输出
1tensor([[2., 2., 0., 2.],
2 [2., 0., 0., 0.],
3 [0., 2., 0., 2.]])
选择 dropout 率为 0.5 时,example 矩阵一半的元素被置为 0,剩下的元素会按 1/0.5=2 的比例进行放大,所以原本是 1 的值变成了 2. 把 dropout
率改为 0.3 测试,dropout(example) 的值为
1tensor([[1.4286, 1.4286, 1.4286, 1.4286],
2 [1.4286, 1.4286, 1.4286, 1.4286],
3 [0.0000, 1.4286, 0.0000, 1.4286]])
drop 了 2 个元素,example 矩阵共 12 个值,如果按 12*0.3=3.6, 怎么算至少也要清掉 3 个值,然而实际上 0.3 的含义是它对 12 个元素中每一个独立的值有被置为 0 的概率为 0.3,最后的总体表现可能只 drop 了两个值。但剩余元素放大的倍数是确定的,1/(1-0.3)=1.4286.
应用到我们之前算出的注意力权重矩阵
1torch.manual_seed(123)
2dropout = torch.nn.Dropout(0.5)
3print(dropout(attn_weights))
1tensor([[2.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
2 [0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
3 [0.7599, 0.6194, 0.6206, 0.0000, 0.0000, 0.0000],
4 [0.0000, 0.4921, 0.4925, 0.0000, 0.0000, 0.0000],
5 [0.0000, 0.3966, 0.0000, 0.3775, 0.0000, 0.0000],
6 [0.0000, 0.3327, 0.3331, 0.3084, 0.3331, 0.0000]],
7 grad_fn=<MulBackward0>)
之前归一化好像又白干了,不知道后面还要不要再进行一次归一化操作?
实现一个简化的因果注意力类
有了前面分解步骤的因果注意力和 dropout 的学习和理解,下面写一个简单的 CausalAttention 类
1import torch
2import torch.nn as nn
3
4
5class CausalAttention(nn.Module):
6 def __init__(self, d_in, d_out, context_length, dropout, qkv_bias=False):
7 super().__init__()
8 self.d_out = d_out
9 self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
10 self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
11 self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
12 self.dropout = nn.Dropout(dropout) # 添加一个 dropout 层
13 self.register_buffer( # 让缓冲区会与模型一起自动移动到适当的设备(CPU 或 GPU) 上
14 'mask',
15 torch.triu(torch.ones(context_length, context_length), diagonal=1)
16 )
17
18 def forward(self, x):
19 b, num_tokens, d_in = x.shape # 2, 6, 3
20 keys = self.W_key(x)
21 queries = self.W_query(x)
22 values = self.W_value(x)
23
24 attn_scores = queries @ keys.transpose(1, 2) # 和 queries @ keys.T 是一样的
25
26 # 把注意力分数转换为因果注意力权重, 即标准注意力权重下三角化
27 attn_scores.masked_fill_( # 带 '_' 的函数就地执行
28 self.mask.bool()[:num_tokens, :num_tokens], -torch.inf)
29 attn_weights = torch.softmax(attn_scores / keys.shape[-1] ** 0.5, dim=-1)
30
31 attn_weights = self.dropout(attn_weights)
32
33 context_vec = attn_weights @ values
34 return context_vec
使用该 CausalAttention 类
1if __name__ == '__main__':
2 inputs = torch.tensor([
3 [0.43, 0.15, 0.89], # Your (x^1)
4 [0.55, 0.87, 0.66], # journey (x^2)
5 [0.57, 0.85, 0.64], # starts (x^3)
6 [0.22, 0.58, 0.33], # with (x^4)
7 [0.77, 0.25, 0.10], # one (x^5)``
8 [0.05, 0.80, 0.55], # step (x^6)
9 ])
10
11 # 这里把一个 token 序列 inputs 复制了两份,用来模型一个 batch 为 2 的输入
12 batch = torch.stack((inputs, inputs), dim=0) # shape: [2, 6, 3]
13
14 torch.manual_seed(123)
15
16 d_in, d_out = 3, 2
17 context_length = batch.shape[1] # 6, num_of_tokens
18 ca = CausalAttention(d_in, d_out, context_length, 0.0)
19
20 context_vecs = ca(batch)
21
22 print(context_vecs)
23 print("context_vecs.shape:", context_vecs.shape)
这里引入了 batch 和 context_length 两个概念,batch 是通过复制 inputs 为两份进行模拟的,context_length 为序列的长度。上面代码执行结果为
1tensor([[[-0.4519, 0.2216],
2 [-0.5874, 0.0058],
3 [-0.6300, -0.0632],
4 [-0.5675, -0.0843],
5 [-0.5526, -0.0981],
6 [-0.5299, -0.1081]],
7
8 [[-0.4519, 0.2216],
9 [-0.5874, 0.0058],
10 [-0.6300, -0.0632],
11 [-0.5675, -0.0843],
12 [-0.5526, -0.0981],
13 [-0.5299, -0.1081]]], grad_fn=<UnsafeViewBackward0>)
14context_vecs.shape: torch.Size([2, 6, 2])
稍加回顾一下,前面学习了三种类型的注意力:
- 简单注意力,没有实际的用途,只是为了帮助我们理解注意力分数,权重,以及最后的上下文向量是如何计算的
- 带有 q, k, v 权重矩阵的标准自注意力,计算注意力分数,权重和上下文向量需要经过这三个权重矩阵,而它们是可训练的
- 因果注意力,首先它也是一个标准的自注意力,但对注意力权重矩阵遮盖了后序 token 对应的值,并且加上 dropout,以防止模型过拟合
再往下学习就是现代大语言模型都采用的终极多头注意力,所以这是必要的,下面学习如何由单头注意力扩展到多头注意力.
将单头(single-head)注意力扩展到多头(multi-head)注意力
多头(multi-head) 是指将注意力机制分成多个头,每个头独立工作。下面是两种实现多头注意力的方式
叠加多个单头注意力层
不要被叠加(stack) 这个词误导了,从数据结构上来说 Stack 的结构是逐个处理的,而多头注意力更像是并排放的,它们可以并行处理。在
《Attention Is All You Need》这篇论文中描述多头注意力的时候是用的 concat, parallel 这样的词
MultiHead(Q, K, V ) = Concat(head1, ..., headh)WO
从结构上可以理解为多个单头依次排列,每个注意力头有自己的 Wq, Wk, 和 Wv 权重矩阵,分别计算 Q, K, V 向量,注意力权重,应用因果掩码和 dropout, 算出各自的上下文向量,最后合并上下文向量。比如两个注意力头 head1, head2, 输出维度是 2, 它们分别算出自己的上下文向量, 合并后得到最终的上下文向量.
Z1: [-0.7, -0.1]
Z2: [0.7, 0.4]
合并后的上下文向量 Z: [-0.7, -0.1, 0.7, 0.4]
有了这个理解后,我们基于前面的 CausalAttention 写出一个 MultiHeadAttentionWrapper 类
1import torch
2import torch.nn as nn
3
4from causal_attention import CausalAttention
5
6
7class MultiHeadAttentionWrapper(nn.Module):
8 def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
9 super().__init__()
10 self.heads = nn.ModuleList(
11 [CausalAttention(d_in, d_out, context_length, dropout, qkv_bias) for _ in range(num_heads)]
12 )
13
14 def forward(self, x):
15 return torch.cat([head(x) for head in self.heads], dim=-1)
加了一个新参数 num_heads,叠加多少个注意力头. __init__ 方法中把多个 CausalAttention 实例放在一个 ModuleList 中,每个
CausalAttention 实例都有自己独立的一套可训练的 Wq, Wk, 和 Wv 权重矩阵。forward()
方法则会触发每个注意力去计算上下文向量,并把它们输出的上下文向量进行拼接。原来每个上下文向量的维度是 d_out=2, 现在是 d_out * num_heads=4.
使用该 MultiHeadAttentionWrapper 类的代码
1if __name__ == '__main__':
2 inputs = torch.tensor([
3 [0.43, 0.15, 0.89], # Your (x^1)
4 [0.55, 0.87, 0.66], # journey (x^2)
5 [0.57, 0.85, 0.64], # starts (x^3)
6 [0.22, 0.58, 0.33], # with (x^4)
7 [0.77, 0.25, 0.10], # one (x^5)``
8 [0.05, 0.80, 0.55], # step (x^6)
9 ])
10
11 # 这里把一个 token 序列 inputs 复制了两份,用来模型一个 batch 为 2 的输入
12 batch = torch.stack((inputs, inputs), dim=0) # shape: [2, 6, 3]
13
14 torch.manual_seed(123)
15
16 d_in, d_out = 3, 2
17 context_length = batch.shape[1] # 6, num_of_tokens
18 mha = MultiHeadAttentionWrapper(d_in, d_out, context_length, 0.0, num_heads=2)
19
20 context_vecs = mha(batch)
21
22 print(context_vecs)
23 print("context_vecs.shape:", context_vecs.shape)
输出的结果是
1tensor([[[-0.4519, 0.2216, 0.4772, 0.1063],
2 [-0.5874, 0.0058, 0.5891, 0.3257],
3 [-0.6300, -0.0632, 0.6202, 0.3860],
4 [-0.5675, -0.0843, 0.5478, 0.3589],
5 [-0.5526, -0.0981, 0.5321, 0.3428],
6 [-0.5299, -0.1081, 0.5077, 0.3493]],
7
8 [[-0.4519, 0.2216, 0.4772, 0.1063],
9 [-0.5874, 0.0058, 0.5891, 0.3257],
10 [-0.6300, -0.0632, 0.6202, 0.3860],
11 [-0.5675, -0.0843, 0.5478, 0.3589],
12 [-0.5526, -0.0981, 0.5321, 0.3428],
13 [-0.5299, -0.1081, 0.5077, 0.3493]]], grad_fn=<CatBackward0>)
14context_vecs.shape: torch.Size([2, 6, 4])
单头注意力的 context_vecs.shape 是 [2, 6, 2], 双头拼接起来就是 [2, 6, 4].
注意到上下文向量的头两列的值与 CausalAttention 计算出来的是一样的,因为 MultiHeadAttentionWrapper 内部在初始化第一个
CausalAttention 实例时,与之前的三个权重矩阵是相同的; 而初始化第二个 CausalAttention 实例时三个权重矩阵就有不一样的随机值了,
所以 MultiHeadAttentionWrapper 算出来上下文向量的后两列的值不同,也就是多头 MultiHeadAttentionWrapper 中的两个 CausalAttention
有不同的权重矩阵,所以它们算出来的上下文向量值不一样.
但目前的 forward 方法中
1 def forward(self, x):
2 return torch.cat([head(x) for head in self.heads], dim=-1)
两个 head(x) 看似串行处理的, 其实在 PyTorch C++ 内部已作了并行优化,甚至可以先合成为大矩阵然后在 GPU 中并行运算.
通过权重划分实现多头注意力
上面实现是通过组合多个 CausalAttention 实例来构造 MultiHeadAttentionWrapper, 我们可以进一步简化,只实现一个 MultiHeadAttention
类。
1class MultiHeadAttention(nn.Module):
2 def __init__(self, d_in, d_out, context_length, dropout, num_heads, qkv_bias=False):
3 super().__init__()
4 assert d_out % num_heads == 0, "d_out must be devisible by num_heads"
5
6 self.d_out = d_out
7 self.num_heads = num_heads
8 self.head_dim = d_out // num_heads # 减少投影维度以匹配所需的输出维度
9
10 self.W_query = nn.Linear(d_in, d_out, bias=qkv_bias)
11 self.W_key = nn.Linear(d_in, d_out, bias=qkv_bias)
12 self.W_value = nn.Linear(d_in, d_out, bias=qkv_bias)
13
14 self.out_proj = nn.Linear(d_out, d_out) # 使用一个线程性来组合头的输出
15
16 self.dropout = nn.Dropout(dropout)
17 self.register_buffer("mask", torch.triu(torch.ones(context_length, context_length), diagonal=1))
18
19 def forward(self, x):
20 b, num_tokens, d_in = x.shape # b 是 batch
21 keys = self.W_key(x) # keys, queries, values 的形状为
22 queries = self.W_query(x) # (b, num_tokens, d_out)
23 values = self.W_value(x)
24
25 # 添加一个 num_heads 维度来隐式地分隔矩阵,然后展开最后一个维度
26 # (b, num_tokens, d_out) -> (b, num_tokens, num_heads, head_dim)
27 keys = keys.view(b, num_tokens, self.num_heads, self.head_dim)
28 queries = queries.view(b, num_tokens, self.num_heads, self.head_dim)
29 values = values.view(b, num_tokens, self.num_heads, self.head_dim)
30
31 keys = keys.transpose(1, 2) # 从形状 (b, num_heads, num_tokens, head_dim)
32 queries = queries.transpose(1, 2) # 交换第 1 和第 2 维,index 是基于 0
33 values = values.transpose(1, 2) # 变成 (b, num_tokens, num_heads, head_dim)
34
35 attn_scores = queries @ keys.transpose(2, 3) # 计算每个头的点积
36 attn_scores.masked_fill_(self.mask.bool()[:num_tokens, :num_tokens], -torch.inf)
37 attn_weights = torch.softmax(attn_scores / self.head_dim ** 0.5, dim=-1)
38 attn_weights = self.dropout(attn_weights)
39
40 context_vec = (attn_weights @ values).transpose(1, 2) # 形状为 (b, num_heads, num_tokens, head_dim)
41 context_vec = context_vec.contiguous().view(b, num_tokens, self.d_out) # 组合头
42 context_vec = self.out_proj(context_vec) # 添加一个可选的线性投影
43 return context_vec
这就很考验线性代数的能力了,反正我是看不太明白。主要思路是: 虽然是多头注意力,但不必显式地创建多个 CausalAttention 实例,
而是把原本属于多个头的同类型的矩阵合成一个大矩阵,只作逻辑上的隔离,这样就能把之前要串行多次矩阵乘法通过投影或转置变换成为一次大矩阵的乘法,
如此更能有效利用 GPU 的并行计算能力以提高效率.
学习了所有的注意力机制,最常见的矩阵运算就是矩阵乘法(@),是一种矩阵中所有元素要相互参与多次的,相乘又相加的运算,由于 GPU 有大量的核,所以 GPU 是最擅长这种大量的,简单的运算。两个同阶方阵可以相乘,同型的两个矩阵(但不是方阵)不能直接相乘,需要通过转置才能相乘.
使用刚创建的 MultiHeadAttention 的方式是一样的
1batch = torch.stack((inputs, inputs), dim=0) # shape: [2, 6, 3]
2
3torch.manual_seed(123)
4
5d_in, d_out = 3, 2
6context_length = batch.shape[1] # 6, num_of_tokens
7mha = MultiHeadAttention(d_in, d_out, context_length, 0.0, num_heads=2)
8
9context_vecs = mha(batch)
10
11print(context_vecs)
12print("context_vecs.shape:", context_vecs.shape)
输出结果的维度是不一样的
1tensor([[[0.3190, 0.4858],
2 [0.2943, 0.3897],
3 [0.2856, 0.3593],
4 [0.2693, 0.3873],
5 [0.2639, 0.3928],
6 [0.2575, 0.4028]],
7
8 [[0.3190, 0.4858],
9 [0.2943, 0.3897],
10 [0.2856, 0.3593],
11 [0.2693, 0.3873],
12 [0.2639, 0.3928],
13 [0.2575, 0.4028]]], grad_fn=<ViewBackward0>)
14context_vecs.shape: torch.Size([2, 6, 2])
MultiHeadAttentionWrapper 和 MultiHeadAttention 为什么输出的维度不同,因为 d_out 在两个类的含义不一样,d_out 在前者中是每
head 的输出维度,而在后者中表示所有 head 合并后的总输出维度,所以对于 MultiHeadAttention, 使用 d_out*2 作为新的 d_out,
则两种实现输出的维度就一样了。
在学习注意力时使用了很小的嵌入维度和注意力头数量以便于理解,实际上一个大语言模型都用了很大数量的嵌入维度和注意力头数量。如最小的 GPT-2 模型(117M)有 12 个注意力头,嵌入维度为 768,token 的上下文长度是 1024,最大的 GPT-2 模型(1.5B)有 25 个注意力头,嵌入维度是 1600. 在 GPT 模型中,token 输入和上下文嵌入维度是相同的(d_in = d_out).
小结
以下小结照搬了原书中的第三章小节
- 注意力机制可以将输入元素转换为增强的上下文向量表示,这些表示涵盖了关于所有输入的信息。
- 自注意力机制通过对输入进行加权求和来计算上下文向量表示。
- 在简化的注意力机制中,注意力权重是通过点积计算得出的。
- 点积是两个向量的元素逐个相乘并将这些乘积相加的一种简洁计算方法。
- 尽管矩阵乘法不是必需的,但它可以通过替代嵌套的 for 循环使计算更高效、更紧凑。
- 在用于大语言模型的自注意力机制(也被称为“缩放点积注意力”)中,我们引入了可训练的权重矩阵来计算输入的中间变换:查询矩阵、值矩阵和键矩阵。
- 在处理从左到右读取和生成文本的大语言模型时,我们会添加一个因果注意力掩码,以防止模型访问未来的词元。
- 除了使用因果注意力掩码将注意力权重置 0,还可以添加 dropout 掩码来减少大语言模型中的过拟合。
- 基于 Transformer 的大语言模型中的注意力模块涉及多个因果注意力实例,这被称为“多头注意力”。
- 可以通过堆叠多个因果注意力模块实例来创建多头注意力模块。
- 创建多头注意力模块的一种更高效的方法是使用批量矩阵乘法。
[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。