RAG(Retrieval-Augmented Generation) 中文名为检索增强生成, 在 LLM 更早期火过的概念,因为那时候上下文较小,所以要检索 LLM 中没有内容(私有数据) 须先在本地用相关性算法找到一些相关的片断,拼接到输入提示词中发送给 LLM。而目前上下文都达到 1M 以上的级别,一次会话甚至可以把私有的内容全部塞 提示词中而喂给 LLM, 就不必用 RAG, 而且内容更完整. 比如你可以把整部小说内容让 LLM 去阅读,然后根据输出总结,或讨论关于该小说的各种问题。 像现在的 Agent Skills 的 Reference 就会把一大段内容丢给 LLM.
所谓的检索(Retrieval) 即在与 LLM 交互之前,从本地(如向量数据库)中找到一些相关的片断,拼接到提示词中,以此达到增强内容生成的效果.
这里不去讨论 RAG 是否已死的问题,只想简单的用 Python, PostgreSQL 加 pgvector 扩展来体验一下什么是 RAG, 以及它的基本流程是什么样子的. 并且对向量数据库中是如何存储和检索的.
Read More各种 AI 编程工具,如 Codex, Claude Code, Gemini 等提供了一些类似的斜线命令,每个斜线命令大约也是对应着一段特定的提示词。由于工作中更方便的使用 Copilot, 所以本文来探讨如何定义自己的 Copilot 斜线命令。比如想要定义一个命令
/c2py-dataclass用于实现把 C/C++ 的类或结构转换成 Python 的 @dataclass 类,并遵循 Python 的命名规则和设置默认字段值, 也就是采用如下提示词Covert following C/C++ class/struct to Python dataclass, following Python naming convention, and set default field values.
<C/C++ source code goes here>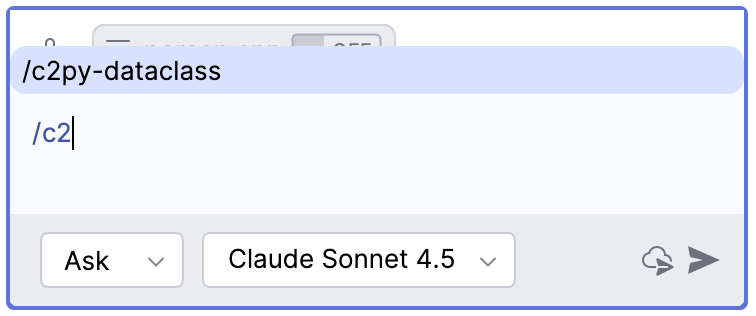
有了自定义的
/c2py-dataclass命令的话,就不需要每次重复上面的描述,而只用输入/c2py-dataclass然后指定某个 C++ 代码文件或粘贴 C/C++ 代码就能实现转换需求。实现方式可以借鉴几天前写的一篇 准备迎接 Vibe Coding - 相关工具与资源 中关于 Spec Kit 一节。
实现方法
开门见山吧,想要添加一个自定义的命令,如
/c2py-dataclass, 仅需在项目目录中添加.github/prompts/c2py-dataclass.prompt.md文件, 立马就会在 Copilot 中出现一个/c2py-dataclass命令,在.github/prompts/c2py-dataclass.prompt.md添加所需的提示词即可。要像
Read MoreSpec Kit那样的话可以使用两个文件.github/agents/c2py-dataclass.agent.md和.github/prompts/c2py-dataclass.prompt.md来配合。
2022 年 11 月 ChatGPT 横空出世, 史称 ChatGPT 时刻, 从那一刻起, 不管你接不接受, 事情正在迅速起变化. 如果写代码从记事本, 一边查文档开始, 到 IDE 的智能提示, 再到 Google 搜索代码, 从 StackOverflow 拷贝代码, 甚至是用 ChatGPT 对话抄写代码这些阶段, 软件工程方面并没有发生太大的变化.
在去年面对 AI 还犹豫做什么的时候, 今年毫无疑问就是 AI Agent. 就目前 AI 最大的成就莫过于解决掉了很多程序员的工作问题. 程序员们在面临 AI 应该作出什么变化的话, 那 Vibe Coding 就不得不认真去看待. Vibe Coding 给我们带来某种快感的同时, 也伴随着焦虑. 从 TDD, BDD, DDD, 到现在的 SDD, 大脑就外包给了 LLM.
Vibe Coding 最早由 OpenAI 联合创始人, 前特斯拉 AI 负责人 Andrej Karpathy 于 2025 年 2 月提出的一个新型编码方式. Vibe Coding 给人一种最直白的感觉就是只与大语言模型对话的形式生成软件, 代码完全是个黑盒, 不直接修改代码, 基本都不看代码, 有编译等问题继续与 LLM 对话. 这种软件生产方式还要像传统方式来 Review 代码就很难了, AI 不辞辛苦生成的大量代码, 可能也不适于人类进行审核了.
Vibe Coding 成就了不少一人一公司, 但也不必过于相信有些人在网络上过份吹嘘的那样--零编程经验, 不写一行代码. 小白确实能用 Vibe Coding 做出一个东西来, 但真零编程经验, 技术框架选型就描述不清, 例如用 Vue.js, React.js, Next.js, 或者什么编程语言适合做什么事情等.
有编程经验搭配上了 Vibe Coding 一定能做的更好. 也别信什么 90% 代码是 AI 写的, Vibe Coding 就是一个黑盒. 那 Vibe Coding 试个多人协作的大型项目. 或者 Vibe Coding 做个银行, 政府, 航空航天项目? 这种关键领域的项目我想每一行代码都必须由人工审核. 所以远古的仍然稳定运行着的 COBOL 代码一直无法升级替换, 换成 AI 也别想简单的就能重写它们, 如果不需要重新测试的话, 那没问题.
Read More AI 领域真是风头正劲,各种概念扑面而来,像 AGI, RAG, AI Agent, Agentic AI 等,目前的 MCP(Model Context Protocol, 模型上下文协议) 又随处可见。MCP 是 Anthropic 于 2024 年 11 月底推出的一种开放标准,旨在统一大模型与外部数据源和工具之间的通信协议。MCP 使用 LLM 应用能安全的访问和操作外部资源,轻松的实现了 Function Calling 的功能。
AI 领域真是风头正劲,各种概念扑面而来,像 AGI, RAG, AI Agent, Agentic AI 等,目前的 MCP(Model Context Protocol, 模型上下文协议) 又随处可见。MCP 是 Anthropic 于 2024 年 11 月底推出的一种开放标准,旨在统一大模型与外部数据源和工具之间的通信协议。MCP 使用 LLM 应用能安全的访问和操作外部资源,轻松的实现了 Function Calling 的功能。
试想一下,以前问大语言模型一个复杂一点的计算题12345 的 6.7 次方是多少?
光语言模型只会在自己的向量数据库里找简单的碰到过的计算题,如 100 的 2 次方,但看到偏门的计算就会出现幻觉了,因为它没有实际的计算引擎。下面是在 LM Studio 中使用 qwen2.5-7b-instruct-mlx 模型时的结果 Read More 学习完用 Transformers 和 llama.cpp 使用本地大语言模型后,再继续探索如何使用 Ollama 跑模型。Ollama 让运行和管理大语言模型变得更为简单,它构建在 llama.cpp 之上,并有优化,性能表现同样不俗。下面罗列一下它的特点
学习完用 Transformers 和 llama.cpp 使用本地大语言模型后,再继续探索如何使用 Ollama 跑模型。Ollama 让运行和管理大语言模型变得更为简单,它构建在 llama.cpp 之上,并有优化,性能表现同样不俗。下面罗列一下它的特点- 从它的 GitHub 项目 ollama/ollama, Go 语言代码 90.8%, C 代码 3.4%
- Ollama 不仅能运行 Llama 模型,还支持 Phi 3, Mistral, Gemma 2 及其他
- Ollama 支持 Linux, Windows, 和 macOS, 安装更简单,不用像 llama.cpp 那样需从源码进行编译,并且直接支持 GPU 的
- Ollama 有自己的模型仓库,无需申请访问权限,可从 Ollama 拉取所需模型,或 push 自己的模型到 Ollama 仓库pull llama3.2-vision
- Ollama 仓库的模型是量化过的,某个模型有大量的 tag 可选择下载,如 llama3.2 的 tags 有 1b, 3b, 3b-instruct-q3_K_M, 1b-instruct-q8_0, 3b-instruct-fp16 等
- 如果在 Ollama 上没有的模型,可以到 HuggingFace 上下载,或量化后再传到 Ollama 仓库
其他更多特性我们将在使用当中体验,仍然是在 i9-13900F + 64G 内存 + RTX 4090 + Ubuntu 22.4 台上进行 Read More- 继续体验 Meta 开源的 Llama 模型,前篇 试用 Llama-3.1-8B-Instruct AI 模型 直接用 Python 的 Tranformers 和 PyTorch 库加载 Llama 模型进行推理。模型训练出来的精度是 float32, 加载时采用的精度是 torch.bfloat16。
注:数据类型 torch.float32, torch.bfloat16, 与 torch.float16 有不同的指数(Exponent),尾数(Fraction)宽度, 它们都有一位是符号位,所以剩下的分别为指数位和尾数位宽度, torch.float32(8, 23), torch.bfloat16(8, 7), torch.float16(5, 10)。
模型依赖于 GPU 的显存,根据经验, 采用 16 位浮点数加载模型的话,推理所需显存大小(以 GB 为单) 是模型参数量(以 10 亿计) 的两倍,如 3B 模型需要约 6G 显存。如果对模型进一步量化,如精度量化到 4 位整数,则所需显存大小降为原来的 1/4 到 1/3, 意味着 3B 模型只要 2 G 显存就能进行推理。所以我们可以把一个 3B 的模型塞到手机里去运行,如果是 1B 的模型 int4 量化后内存占用不到 1G(0.5 ~ 0.67)。
本文体验 llama.cpp 对模型进行推理,在 Hugging Face 的用户设置页面 Local Apps and Hardware, 可看到一些流行的跑模型的应用程序,分别是- 生成文本的: llama.cpp, LM Studio, Jan, Backyard AI, Jellybox, RecurseChat, Msty, Sanctum, LocalAI, vLLM, node-llama-cpp, Ollama, TGI
- 文生图的: Draw Things, DiffusionBee, Invoke, JoyFusion
- IT 从业人员累的一个原因是要紧跟时代步伐,甚至是被拽着赶,更别说福报 996. 从早先 CGI, ASP, PHP, 到 Java, .Net, Java 开发是 Spring, Hibernate, 而后云时代 AWS, Azure, 程序一路奔波在掌握工具的使用。而如今言必提的 AI 模型更是时髦,n B 参数, 量化, 微调, ML, LLM, NLP, AGI, RAG, Token, LoRA 等一众词更让坠入云里雾里。
去年以机器学习为名买的(游戏机)一直未被正名,机器配置为 CPU i9-13900F + 内存 64G + 显卡 RTX 4090,从进门之后完全处于游戏状态,花了数百小时对《黑神话》进行了几翻测试。
现在要好好用它的 GPU 来体验一下 Meta 开源的 AI 模型,切换到操作系统 Ubuntu 20.04, 用 transformers 的方式试了下两个模型,分别是- Llama-3.1-8B-Instruct: 显存使用了 16G,它的老版本的模型是 Meta-Llama-3-8B-Instruct(支持中文问话,输出是英文)
- Llama-3.2-11B-Vision-Instruct: 显存锋值到了 22.6G(可以分析图片的内容)
都是使用的 torch_dtype=torch.bfloat16, 对于 24 G 显存的 4090 还用不着主内存来帮忙。如果用 float32 则需更多的显存,对于 Llama-3.2-11B-Vision-Instruct 使用 float32, 则要求助于主内存,将看到Some parameters are on the meta device because they were offloaded to the cpu.
反之,对原始模型降低精度,量化成 8 位或 4 位则更节约显卡,这是后话,这里主要记述使用上面的 Llama-3.1-8B-Instruct 模型的过程以及感受它的强大,可比小瞧了这个 8B 的小家伙。所以在手机上可以离线轻松跑一个 1B 的模型。 Read More