
学习了一段时间 LangChain,了解到用
create_agent()创建的 Agent 的用法,以及底层init_chat_model()与模型的交互,决定以古法的方式 亲自创建一个 AI Agent, 要实现的功能是把原来用 ApacheAirflow做的一个从猫收留网站上查看有没有新进入收容所的猫,有则发邮件通知。换成 AI Agent 的话,功能列表是
Read More- 使用 AWS Bedrock 上的一个 Claude 模型
- 用 Telegram 创建一个 Bot, 配置好 Bot Token 与 Chat ID
- 工具方面,提供读文件,写文件,和更新文件的函数,web_fetch, 还有向 Telegram 发送消息的函数
- AI Agent 从一个特定的网页上收集猫的信息,借助文件判定是否是新的
- 发现新的猫,向 Telegram Bot 发送通知, 每只新猫一个消息,消息包含猫的基本信息,图片与链接
在上一篇 LangChain 核心组件之 Agent 有介绍到模型。模型其实是一个很粗泛的概念,放到任何领域都有立身之地, 比如各种建模,经济增长模型,Covid 感染模型等。但来到 AI 时代,会不会只要有人一开口说模型便默认为大语言模型(LLM)呢?而如今的 LLM 模型又基本就是 Transformer 模型,所谓的模型开源只是开放了一堆的 Token 的权重值,不同源软件开源,拿过来能随意定制使用。
大语言模型更像是人类知识的压缩包,可用它生成多种形式的内容,比如文本、图像、音频等。模型在生成内容的过程中,还支持下面几种形式的交互
- 工具调用:可以引导模型通知 Agent 调用工具,如计算,互联网搜索,API 调用等
- 结构化输出:模型本身就支持按照约定的规则格式化输出内容
- 多模态:不仅能生成文本,还能生成图像、音视频等
- 推理:模型可以进行推理,如数学计算、逻辑推理等,就是经常看到的 Thinking 的过程
最初在 Llama3 刚发布的年代,在使用 MCP 时还要查哪个模型支不支持工具使用,现在基本上以上特性是模型的标配了。现在几大商业模型就是 OpenAI 的 GPT, Anthropic 的 Claude,Google 的 Gemini, Musk 的 Grok 在下一梯队。国外的模型选择很清晰,反而中国的大语言模型众多, 仿佛不出个自己的大语言模型就像个互联网公司。
Read More经过了一番
LangChain的学习之后,我们开始跟随LangChain的官方文档系统性的学习。首先是它的核心组件,包括Agents,Models,Messages,Tools,Short-term memory,Streaming, 和Structured output. 现在从 Agents 开始。创建 Agent
create_agent是可用于正式产品中创建 Agent 的函数, 它返回的是一个langgraph.graph.state.CompiledStateGraph对象,而非一个XxxAgent样的东西。所以它创建的是一个状态图,图吗,就有顶点和边,Agent 就是这个图中移动,比如在Model和Tools之间往复, 或在中间加入的互动的(Human-in-the-loop).
Read MoreLangGraph把与模型,工具,以及人的交互做成一个图还是很表意的,下面是来源于官方文档的表示 Agent 的状态图。所谓大语言模型的记忆功能,就是要在说当前这句话的时候让 LLM 知道整个对话的上下文。比如说与人对话
- A: 给我讲个笑话
- B: 有一天,有人问你:“你喜欢什么?”, 你回答:“我喜欢一切……只要不叫‘考试’。” 😄 够快,够短,有没有让你会心一笑?
- A: 再来一个
- B: 问:海里面最怕什么? 答:脱水。
#3 当 A 问 "再来一个" 时候,B 因为有基于前面对话的上下文,所以能理解 "再来一个" 来一个笑话,而不是一个妞什么的,也记得曾经讲过一个笑话,而不 至于重复之前的笑话。如果突然有一天 A 对 B 突兀的说 "再来一个",B 就会有些傻眼了,AI 在没有上下文的情况也是一样。
不过人与人之间对话的上下文是互相的,两方的共同记忆,双方都是建立在你知道我问了什么,你自己回复了什么的基础之上的。而于大语言模型的对话时, 大语言模型是没有记忆的,就好像和一个失忆的人对话一样,记忆责任全在一方,你和 LLM 每一次对话时都要不停的唠叨:
我曾经问了这个,你回复过那个,问过这个,你回复过那个......,我现在问一个问题,请基于我们的会话历史作出回答
和机器对话就是这么傻傻的,当对话历史过大的时候因为上下文大小限制的原因,就必须压缩总结之前的对话内容,压缩后总会失真,这就是为什么大语言模型会 不断降智的一个原因。
Read More
前段时间 OpenClaw 确实很火,尤其是在中国,它在 2025 年 11 月上线后,最初名字是 Clawbot, 中间更名为 Molbot, 最后定名为 OpenClaw. 我在它 真正火热当中并没有产生多大兴趣去跟风,只最近一个月想看看它到底是个什么东西。弄了个虚拟机装上后,就是可以连接各个大模型, 打通与国外流行的即时通讯 软件,能自动化的就是它的 Cron Jobs.
界面上功能不少,最后发现真正有用的就是那个 Cron Jobs, 比如自己设置了一个每日两次的定时任务,实现的是从监控一个猫收容网上的列表,当发现有新的猫 就发送到指定的 Telegram Bot 上,描述很简单,但 Agent 确实很聪明,不用告诉它细节,它自己知道怎么本地文件来辅助判断是否为新猫。聪明的另一个原因是 OpenClaw 蹭了我 $20 Claude 会员的光。但到 4 月 4 日,Claude 订阅会员不让绑定到 OpenClaw 之后,试用了 Google 免费的 API Key 不怎么理想。
也不想再多折腾,如果只是要一个
Cron Job的话可以自己用LangChain实现一个。听说 OpenClaw 十分耗 Token, 于是对它的提示词有点好奇。 本文将查看一下一个新鲜的OpenClaw的提示词长什么样子。于是又新装了一个
Read MoreOpenClawv2026.4.9 版本,使用本地的Ollama模型,由于未能成功设置OpenClaw使用代理来访问OllamaAPI, 于是在Ollamaservice 前端放了一个反向代理,该反向代理也是临时用 Vibe Coding 搓出来的。让OpenClaw使用通过反向代理http://localhost:9091来访问实际的Ollamahttp://localhost:11434, 并在反向代理中记录下对OllamaAPI 完整的请求与响应数据,使用什么模型都无所谓。上一篇 LangChain 1.2 入门学习 中使用了特定的 ChatOllama/ChatGoogleGenerativeAI, 或统一的 init_chat_model 方式创建一个与 LLM 的交互程序,并以此基础实现了一个简单的 AI Agent, 工具调用是根据响应中消息格式手工调用的, 会话处理是自己拼接全部对话历史。现在知名的 LLM 都支持推理,所以顺代也用灰色字体显示了 'thinking' 的文本内容。
本文直接学习官方 Quickstart 中的一个
AI Agent, 该 Agent 实现了以下功能- 有了上下文,会记忆会话历史
- 支持调用多个工具
- 提供结构化一致性的响应数据格式
- 能通过上下文处理用户特定的信息
- 跨交互维护会话状态
AI 界日新月异,新名词层出不穷,像 Prompt Engineering, Context Engineering, 到如今又来了 Harness Engineering. 现在最怕两个人出来搞事情, Dario Amodei 和 Andrej Karpathy, 前者宣称 AI 可替代一切,人变得一文不值,后者专造名词。在大语言模型时代,搞机器学习了,专注模型的不用多少人, 多数人还能在 AI 上蹭热点的话就剩下 AI Agent 的这个赛道了,其余就是应用了,例如 Vibe Coding,或更贴近具体业务的应用。
像各大 AI 编程工具,如 Codex, Claude Code, OpenCode, GitHub Copilot, Gemini, Cursor, Antigravity, Trae 本质上都是在比拼各家 AI Agent 的能力。最近火的那个 OpenClaw 也是一个学习 AI Agent 的好范例。
而 AI Agent 方面的框架首当其冲就是 LangChain, 它提供了 Python 和 TypeScript 两种语言的支持,网上有人做了个 langchain4j, 这种跟随项目恐怕也坚持不了多久。其他 AI Agent 框架有 [Pydantic AI], 微软的 AutoGen, Crew AI, AWS Strands Agents. 各大语言模型 OpenAI, Anthropic, Gemini 都有自己的 SDK, 但要开发一个 Multi Agent 的系统更需要一个第三方的 AI Agent 框架来整合各家模型的能力,提供统一的接口和工具,这个框架就是 LangChain.
Read MoreRAG(Retrieval-Augmented Generation) 中文名为检索增强生成, 在 LLM 更早期火过的概念,因为那时候上下文较小,所以要检索 LLM 中没有内容(私有数据) 须先在本地用相关性算法找到一些相关的片断,拼接到输入提示词中发送给 LLM。而目前上下文都达到 1M 以上的级别,一次会话甚至可以把私有的内容全部塞 提示词中而喂给 LLM, 就不必用 RAG, 而且内容更完整. 比如你可以把整部小说内容让 LLM 去阅读,然后根据输出总结,或讨论关于该小说的各种问题。 像现在的 Agent Skills 的 Reference 就会把一大段内容丢给 LLM.
所谓的检索(Retrieval) 即在与 LLM 交互之前,从本地(如向量数据库)中找到一些相关的片断,拼接到提示词中,以此达到增强内容生成的效果.
这里不去讨论 RAG 是否已死的问题,只想简单的用 Python, PostgreSQL 加 pgvector 扩展来体验一下什么是 RAG, 以及它的基本流程是什么样子的. 并且对向量数据库中是如何存储和检索的.
Read More各种 AI 编程工具,如 Codex, Claude Code, Gemini 等提供了一些类似的斜线命令,每个斜线命令大约也是对应着一段特定的提示词。由于工作中更方便的使用 Copilot, 所以本文来探讨如何定义自己的 Copilot 斜线命令。比如想要定义一个命令
/c2py-dataclass用于实现把 C/C++ 的类或结构转换成 Python 的 @dataclass 类,并遵循 Python 的命名规则和设置默认字段值, 也就是采用如下提示词Covert following C/C++ class/struct to Python dataclass, following Python naming convention, and set default field values.
<C/C++ source code goes here>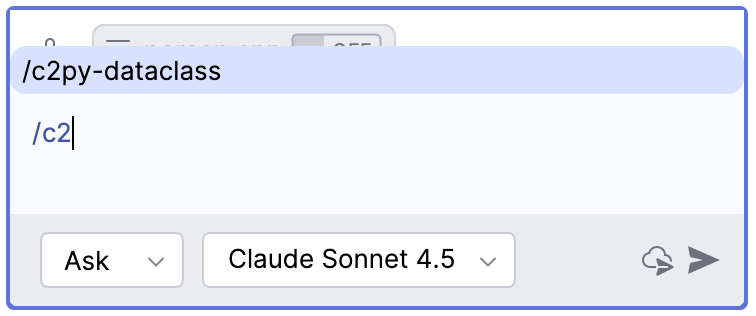
有了自定义的
/c2py-dataclass命令的话,就不需要每次重复上面的描述,而只用输入/c2py-dataclass然后指定某个 C++ 代码文件或粘贴 C/C++ 代码就能实现转换需求。实现方式可以借鉴几天前写的一篇 准备迎接 Vibe Coding - 相关工具与资源 中关于 Spec Kit 一节。
实现方法
开门见山吧,想要添加一个自定义的命令,如
/c2py-dataclass, 仅需在项目目录中添加.github/prompts/c2py-dataclass.prompt.md文件, 立马就会在 Copilot 中出现一个/c2py-dataclass命令,在.github/prompts/c2py-dataclass.prompt.md添加所需的提示词即可。要像
Read MoreSpec Kit那样的话可以使用两个文件.github/agents/c2py-dataclass.agent.md和.github/prompts/c2py-dataclass.prompt.md来配合。
2022 年 11 月 ChatGPT 横空出世, 史称 ChatGPT 时刻, 从那一刻起, 不管你接不接受, 事情正在迅速起变化. 如果写代码从记事本, 一边查文档开始, 到 IDE 的智能提示, 再到 Google 搜索代码, 从 StackOverflow 拷贝代码, 甚至是用 ChatGPT 对话抄写代码这些阶段, 软件工程方面并没有发生太大的变化.
在去年面对 AI 还犹豫做什么的时候, 今年毫无疑问就是 AI Agent. 就目前 AI 最大的成就莫过于解决掉了很多程序员的工作问题. 程序员们在面临 AI 应该作出什么变化的话, 那 Vibe Coding 就不得不认真去看待. Vibe Coding 给我们带来某种快感的同时, 也伴随着焦虑. 从 TDD, BDD, DDD, 到现在的 SDD, 大脑就外包给了 LLM.
Vibe Coding 最早由 OpenAI 联合创始人, 前特斯拉 AI 负责人 Andrej Karpathy 于 2025 年 2 月提出的一个新型编码方式. Vibe Coding 给人一种最直白的感觉就是只与大语言模型对话的形式生成软件, 代码完全是个黑盒, 不直接修改代码, 基本都不看代码, 有编译等问题继续与 LLM 对话. 这种软件生产方式还要像传统方式来 Review 代码就很难了, AI 不辞辛苦生成的大量代码, 可能也不适于人类进行审核了.
Vibe Coding 成就了不少一人一公司, 但也不必过于相信有些人在网络上过份吹嘘的那样--零编程经验, 不写一行代码. 小白确实能用 Vibe Coding 做出一个东西来, 但真零编程经验, 技术框架选型就描述不清, 例如用 Vue.js, React.js, Next.js, 或者什么编程语言适合做什么事情等.
有编程经验搭配上了 Vibe Coding 一定能做的更好. 也别信什么 90% 代码是 AI 写的, Vibe Coding 就是一个黑盒. 那 Vibe Coding 试个多人协作的大型项目. 或者 Vibe Coding 做个银行, 政府, 航空航天项目? 这种关键领域的项目我想每一行代码都必须由人工审核. 所以远古的仍然稳定运行着的 COBOL 代码一直无法升级替换, 换成 AI 也别想简单的就能重写它们, 如果不需要重新测试的话, 那没问题.
Read More