
上篇 AWS ECS 使用 EC2 Capacity Provider (EC2 Auto Scaling) 学习了如何在 ECS 中使用 Capacity Provider + EC2 Auto Scaling 来部署一个简单的 Web 应用,以及了解 ECS 如何管理 EC2 的 Auto Scaling Group.
ECS Capacity Providers 是于 2019 年 12 月发布的,随同的功能支持了 Fargate, Fargate Spot, 和 EC2 AutoScaling. 而 Managed Instances 在 2025-09-30 才加入的新特性,见 Announcing Amazon ECS Managed Instances.
在近六年之间, AWS 大概也理解到了 Capacity Provider + EC2 Auto Scaling 的复杂性,虽说可由 ECS 来管理 EC2 的 ASG, 但毕竟有个 ASG 在那里。 ECS 与 EC2 ASG 之间联接由 CloudWatch Metrics, Alarms, EC2 ASG 的 Dynamic scaling policies 和 Lifecycle hooks 的一整套机制协作。 经常还不得不在 EC2 ASG 与 ECS 两个界面之间来回找问题。而 Managed Instances 的出现则将 EC2 实例的管理完全透明化了,在 EC2 端压根就不存在 一个相应的 ASG, 更不需要 CloudWatch Alarms 之类的关联组件。
Managed Instances 与 EC2 Auto Scaling 之间就好比 Serverless 与 非 Serverless 的区别,用 Managed Instances 之后你只管控制好 ECS Desired Count(ECS AutoScaling), 其余的都由 Managed Instances 来管理,在界面上只需要关注 ECS Infrastructure 中的 Container Instances. 由 Managed Instances 管理的 EC2 实例,你即使用有管理员权限都无法关闭它,只能全权由 Managed Instances 来控制。试图关闭这样的 EC2 实例时报错
Read More在我 X 中 AWS 上不同应用的部署策略 中提到过在 AWS 部署服务(特别是 Web 服务时), 基于采用过以下演进的方式
- EC2(AutoScaling) + 直接 EC2 中部署本地应用, 靠 userdata 完成应用部署 2 EC2(AutoScaling) + ECS(AutoScaling), 运行容器,Replica 模式,有两个层次的 AutoScaling 要单独控制,比较麻烦
- ECS + EC2(AutoScaling), 运行容器,Daemon 模式。由 EC2 来驱动部署 ECS Task
- ECS(AutoScaling) + Fargate, 运行容器。这是最简单的,但硬件资源受限, 想要强大的 CPU, 没门
- ECS(AutoScaling) + Capacity Provider(EC2) + EC2(Managed AutoScaling), 运行容器。由 ECS Task 发起 EC2 实例需求
- ECS(AutoScaling) + Capacity Provider(Fargate),运行容器,Serverless 就是简单,同样硬件资源受限
- EKS,开启 Auto mode,一切变得简单,像是 Capacity Provider(EC2). 但会涉及到复杂的 EKS 配置管理,集群内网络,如 ELB,
基于服务的 WAF, IAM Role. 但基本是一次的工作,建立了健壮的 EKS, 以后部署任何应用都变得很轻松。
对于 #2 和 #3, 如果选择 Network 模式为
Read Morevpc的话,即每个容器都会有自己的 IP 地址,并且 Target Group 中注册的是 IP 地址,这时候 AutoScaling 在缩减实例时就要靠 AutoScaling 的 Lifecycle Hook 来处理对相应 ECS Task 的通知,因为 EC2 的 AutoScaling 只知在开始关闭实例停止向相应实例 转发请求. 如果 Network 模式为默认的Bridge则没问题,因为请求是过通 NAT 方式(如 32768:80) 由 EC2 实例转发到其中的容器。 自从 Terraform resource "aws_iam_role" 不推荐使用 "inline_policy" 和 "managed_policy_arns" 以后,就尝试了用 "aws_iam_policy_attachment" 来为 iam role 指定 AWS 内置和自定义的 IAM policy。因为在官方文档 aws_iam_role 中最先看到的就是 aws_iam_policy_attachment, 其实仔细阅读该文档的话,建议是
自从 Terraform resource "aws_iam_role" 不推荐使用 "inline_policy" 和 "managed_policy_arns" 以后,就尝试了用 "aws_iam_policy_attachment" 来为 iam role 指定 AWS 内置和自定义的 IAM policy。因为在官方文档 aws_iam_role 中最先看到的就是 aws_iam_policy_attachment, 其实仔细阅读该文档的话,建议是- 用 "aws_iam_role_policy" 来代替 "inline_policy"
- 用 "aws_iam_role_policy_attachment" 来代替 "managed_policy_arns"
然后在项目中为避免 inline_policy 和 managed_policy_arns 的警告而选择了通用的 aws_iam_policy_attachment, 同时原来也用的 "aws_iam_policy",而非 "aws_iam_role_policy。 所以才撞入到以前一直用 aws_iam_role(inline_policy, managed_policy_arns) + aws_iam_policy 就没出过问题。 Read More- 这是近些天遇到的一个问题,因为早先使用 ECS 为求快速验证新的 Docker Image, 一直是用相同的 Tag 覆盖 ECR 中原有的 Docker Image,然后停掉 ECS 中相应的 Task, 新的 Task 起来,拉取最新 Docker Image,这样不用重新部署 Infrastructure, 以最小的改动就能达到偷梁换柱的效果。比如下面的情景:
- ECS 任务定义中所用的 Image 是 123456789012.dkr.ecr.us-east-1.amazonaws.com/demo:1.10
- 构建新的 Docker Image, 然后再 docker push 123456789012.dkr.ecr.us-east-1.amazonaws.com/demo:1.10
- 覆盖后,在 ECR 中将有两个 Tag, 刚 push 的是
1.10, 被覆盖的变成-, 多次覆盖将会产生更多的- - 停掉 ECS 相应的 Task, 新的 Task 起来,拉取 123456789012.dkr.ecr.us-east-1.amazonaws.com/demo:1.10 代表的新镜像
这种做法在以前是灵验的,每次修改代码,覆盖现有 Tag, 重启 Task 就能快速测试, 不用重新创建 Task Definition 和别的 Infrastructure。
然而最近突然不起作用了,本地不断的修改代码,构建新的镜像,覆盖原有 Tag, 重启 Task, 可是依旧跑的是老代码。怀疑 ECR 中的 Image 有问题,用 docker pull 下来看确实是新代码,就差进到 ECS Task 实例中去找问题。而且即使是重新运行 Terraform 来部署整个 Infrastructure 都无济于事,就是 aws_ecs_service 中指定了 force_new_deployment = true 也没辙,因为只要 Docker Image 的 Tag 没变, Terraform 就认为是 no change。 Read More - 本文主要验证用 Python 写的 AWS Lambda 与 Java 客户端之间如何双向传递二进制数据,这里不涉及到 Lambda 流输入输出的问题。比如一个 Python AWS Lambda 的处理方法声明是
def lambda_handler(event, context):
通过我们用 Lambda 调用时会传给
pass # or do somethingevent一个 JSON 格式的字符串,反应到 AWS Lambda 时event就是一个字典。但当要传递二进制数据如何做呢?直觉的做法就是用 base64 编码二进制字节为普通的字符串,比如要节约网络传输的数据量,需要对文本进行压缩,格式可以是这样{"input": base64Encode(gzipCompress("text content......"))}
然后在 Lambda 端取出input的值作相应的 base64 解码再解压缩。
对于大文本,即使是压缩后再编码为 base64 也比直接传送原始文本数据要节约网络带宽。
这种方案实际也是可行的,然而我们在实际使用 Java AWS Lambda SDK 时有些动作会自动帮我们实现的,那就是二进制数据自动 base64 编码。 Read More - AWS 自 2014 年推出 Lambda 时仅支持 Node.js,而后添加了对 Python, Ruby, Java, C#, F#, PowerShell 的支持,再来到 2018 年可以自定义运行时了,比如用性能较好的 C, C++, Rust, Go 等语言。见 AWS Lambda Now Supports Custom Runtimes and Enables Sharing Common Code Between Functions.
如果使用 Python, Java 写 Lambda 时觉得还不得快,不想要明显的预热过程,也许 1000 毫秒的任务只想要 600 毫秒就能完成,内存还希望再压缩一些,那着实能在每月千百万次 Lambda 调用的情况下节省一笔可观的支出,那么可以试一试 C, C++, Rust, Go 等编译成了机器指令的语言,况且前三者没有 GC, 执行效率会更高。
本日志记录一下如何用 C++ 创建一个 AWS Lambda, 以及可如何应付 Lambda 的复用。本文主要参考自下面两处
自定义运行时可选择 X86_64 或 arm64 的 Amazon Linux 2023 或 Amazon Linux 2。部署时可选择的 runtime 相应有 provided.al2023, provided.al2, 推荐使用 provided.al2023。runtime provided 不被支持了。
C++ 代码可选择用 GCC 或 Clang 来编译,既然 AWS Lambda 实际的运行时会用到 Amazon Linux 2023,那我们就直接选择 Docker 镜像 amazonlinux:2023 作为我们的编译环境。 Read More  不觉一晃还是在五年前记录过一篇 Dockerfile 中命令的两种书写方式的区别,其中提到过 Dockerfile 中可选择用 ENTRYPOINT 或 CMD 来启动进程,并且在 ENTRYPOINT 和 CMD 都支持 exec, shell 和增强型 shell 方式。如果同时有 ENTRYPOINT 和 CMD(或 docker 运行时的 CMD), 则 CMD 将为 ENTRYPOINT 提供参数。
不觉一晃还是在五年前记录过一篇 Dockerfile 中命令的两种书写方式的区别,其中提到过 Dockerfile 中可选择用 ENTRYPOINT 或 CMD 来启动进程,并且在 ENTRYPOINT 和 CMD 都支持 exec, shell 和增强型 shell 方式。如果同时有 ENTRYPOINT 和 CMD(或 docker 运行时的 CMD), 则 CMD 将为 ENTRYPOINT 提供参数。
在原来那篇文中认为 shell 无法接收到 docker stop 或 docker -s SIGTERM 发来的信号,也许是随着 Docker 版本的变迁,Docker 变得越发聪明了起来,无论何种格式的 ENTRYPOINT, 都能够收到 SIGTERM 信号,比如在 Java 的 ShutdownHook 能捕捉到该信号,得以在进程停止之前作必要的清理工作。
进行本文相关研究的主因是部署在 ECS(Fargate) 中的 Java Web 服务,Task 总是因为 OutOfMemoryError 被杀掉,而在应用程序日志中却见不着半点线索说 JVM 的 OutOfMemoryError,即使后来给 Fargate 配上了 EFS, 加了+XX:+HeapDumpOnOutOfMemoryError XX:HeapDumpPath=/efsJVM参数,在任务被 kill 时在 /efs 上从来就都没生成过内存映像文件。最后发现是因为 JVM 的 -Xmx 配置太高,留给 Fargate 容器的太少的缘故。 Read More- 分布式计算有这么一个需求,主进程准备好输入数据,然后根据输入中某个 Items 动态调用若干计算进程,待到所有计算完成后再汇集结果。这一需求移植到 AWS 上就像是下面这样子
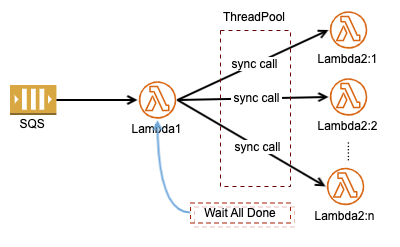 但在一个 Lambda 中同步调用其他 Lambda 时就有个费时费钱的问题,虽然我们采用线程池来调用 Lambda2, 由于每个同步调用的耗时不相同, Lambda1 最终要等待最慢的那个调用结束后才能对所有结果进行聚集处理。这就是著名的“长板效应”, Lambda1 多数时候是在无谓的等待当中消耗着你的钱财。
Read More
但在一个 Lambda 中同步调用其他 Lambda 时就有个费时费钱的问题,虽然我们采用线程池来调用 Lambda2, 由于每个同步调用的耗时不相同, Lambda1 最终要等待最慢的那个调用结束后才能对所有结果进行聚集处理。这就是著名的“长板效应”, Lambda1 多数时候是在无谓的等待当中消耗着你的钱财。
Read More - 无论在何处,有多重任务要处理时,并发编程总是要得到考虑的。比如有 IO 等待时的并发或 CPU 密集型时的并行计算,并发通常是指在同一个 CPU 上按时间片轮换执行,并行是任务在不同的 CPU 上执行。能有效使用 CPU 多核的语言可以让线程运行在不同的核上实现并行,如果是启动的子进程能由操作系统运行在其他 CPU 核上。
回到 AWS Lambda 中的 Python 代码,如果是处理 IO 等待,使用多线程并发就行,大致的代码如下:with ThreadPoolExecutor(10) as executor:
以上代码在 AWS Lambda 中是可以运行的。
result = executor.map(task_function, task_inputs)
如果是 CPU 密集型的任务,用 Python 的多线程就要歇菜了,因为存在著名的 Python's GIL 的约束。 这时候就必须要考虑多进程并行的方式,同时应知晓当前选择的 Lambda 运行环境有多少个 CPU 内核,因为如果是单核的话再多进程也无济于事,没必要启动多于核心数的进程。 底下是本人上篇博客测试收集的不同 AWS Lambda 内存选择对应的 CPU 核心数,以及实际可用内存大小的关系表 Read More - 目前(2023-05-25) AWS Lambda 的内存选择区间是 128MB ~ 10240MB, 最长运行时间为 15 分钟,但没有 vCPU 个数的选择。vCPU 的数量是基于所选内存大小而有不同的,如果我们在 Lambda 中需使用多进程充分发挥 CPU 性能的话,有必要了解当前 Lambda 所在运行环境的 CPU 内核数,甚至是单核的频率。
CPU 个数可用如下 Python 内置的其中一个方法取得multiprocessing.cpu_count()
要获得 CPU 频率或内存的话,将要用到
os.cpu_count()psutil组件的方法,可把 psutil 做成 Lambda 层以引用,或与 Lambda 函数代码一同打成 zip 包。
安装方法psutilpip install --target . psutil
psutil 会安装到当前目录,然后在当前目录下再创建 lambda_function.py 文件,再打包 Read More