 修改私有属性来 Mock 可能不是一种很好的测试方式, 因为属性名是动态的,但有时不得已而为了,例如下面的代码:
修改私有属性来 Mock 可能不是一种很好的测试方式, 因为属性名是动态的,但有时不得已而为了,例如下面的代码:1public class UserService { 2 private ExternalApi external = ExternalApi.default(); 3 private UserDao userDao; 4 5 public UserService(UserDao userDao) { 6 this.userDao = userDao; 7 } 8 9 public User findUserById(int id) { 10 return userDao.findById(external.convertId(id)); 11 } 12}
测试时欲隔离对 ExternalApi 的外部依赖, 当然可以把它也作为构造函数的一个参数,这样创建 UserService 实例时就可以 Mock external 属性。不过 external 经常是不变的,所以作为方法参数的必要性也不大。这就希望能在构造出 UserService 之后对 external 私有属性进行 Mock 处理。
在 Mockito 1.x 和 2.x 下要使用不同的方式,分别使用到 Whitebox 和 FieldSetter 类,它们都来自于mockito.internal.util.reflection包,可见 Mockito 打心底不推荐直接使用它们,但谁叫它们是 public 的呢。还有一种方式是使用 PowerMock + Mockito, 这是后话。 Read More Java 测试的 Mock 框架以前是用 JMockit, 最近用了一段时间的 Mockito, 除了它流畅的书写方式,经常这也 Mock 不了,那也 Mock 不了,需要迁就于测试来调整实现代码,使得实现极不优雅。比如 Mockito 在 私有方法,final 方法,静态方法,final 类,构造方法面前统统的缴械了。powermock 虽然可作 Mockito 的伴侣来突破 Mockito 本身的一些局限,但是我一用它来 Mock 一个构造方法就出错
Java 测试的 Mock 框架以前是用 JMockit, 最近用了一段时间的 Mockito, 除了它流畅的书写方式,经常这也 Mock 不了,那也 Mock 不了,需要迁就于测试来调整实现代码,使得实现极不优雅。比如 Mockito 在 私有方法,final 方法,静态方法,final 类,构造方法面前统统的缴械了。powermock 虽然可作 Mockito 的伴侣来突破 Mockito 本身的一些局限,但是我一用它来 Mock 一个构造方法就出错Caused by: java.lang.ClassNotFoundException: org.mockito.exceptions.Reporter
原因是 Mockito 变化太快,powermock 跟不上它的步伐 -- https://github.com/powermock/powermock/issues/684,于是我只能止步。
不得已再祭出 JMockit 这号称(也确实是)一无所不能的大杀器,在此见识一下它怎么 Mock 构造函数的
本篇实例所使用的 JMockit 版本是 1.30, 当前最新版 1.31, 由于尚未被 Maven 中央仓库收录,所以暂用 1.30。在 pom.xml 中如下方式引入 Read More- 在 Java 中对于下面最简单的泛型类
class A<T> {
设想我们使用时
public void foo() {
//如何在此处获得运行时 T 的具体类型呢?
}
}new A<String>().foo();
是否能在foo()方法中获得当前的类型是 String 呢?答案是否定的,不能。在foo()方法中 this 引用给不出类型信息,this.getClass()就更不可能了,因为 Java 的泛型不等同于 C++ 的模板类,this.getClass()实例例是被所有的不同具体类型的 A 实例(new A<String>(), new A<Integer>() 等) 共享的,所以在字节码中类型会被擦除到上限。
我们可以在 IDE 的调试时看到这个泛型类的签名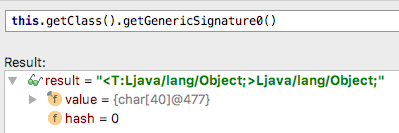 Read More
Read More  在上一篇中尝试了 使用 Javassist 运行时生成泛型子类,这里要用另一个更方便的字节码增加组件 Byte Buddy 来实现类似的功能, 但代码上要直白一些。就是运用 Byte Buddy 在运行时生成一个类的子类,带泛型的,给类加上一个注解,可生成类文件或 Class 实例,不过这里更进一步,实现的方法是带参数的。
在上一篇中尝试了 使用 Javassist 运行时生成泛型子类,这里要用另一个更方便的字节码增加组件 Byte Buddy 来实现类似的功能, 但代码上要直白一些。就是运用 Byte Buddy 在运行时生成一个类的子类,带泛型的,给类加上一个注解,可生成类文件或 Class 实例,不过这里更进一步,实现的方法是带参数的。
用 Byte Buddy 操作起来更简单,根本不需要接触任何字节码相关的,诸如常量池等概念。与 Javassist 相比,Byte Buddy 更为先进的是能生成的类文件都是可加载运行的,不像 Javassist 生成的类文件反编译出来是看起来是正常的,但一加载执行却不那回事。
本例所使用的 Byte Buddy 的版本是当前最新的 1.6.7,在 Maven 项目中用下面的方式引入依赖<dependency>
下面是几个需要在本例中用到的类定义 Read More
<groupId>net.bytebuddy</groupId>
<artifactId>byte-buddy</artifactId>
<version>1.6.7</version>
</dependency>
Java 8 之前如何重复使用注解
在 Java 8 之前我们不能在一个类型重复使用同一个注解,例如 Spring 的注解@PropertySource不能下面那样来引入多个属性文件@PropertySource("classpath:config.properties")
上面的代码无法在 Java 7 下通过编译,错误是: Duplicate annotation
@PropertySource("file:application.properties")
public class MainApp {}
于是我们在 Java 8 之前想到了一个方案来规避 Duplicate Annotation 的错误: 即声明一个新的 Annotation 来包裹@PropertySource, 如@PropertySources1@Retention(RetentionPolicy.RUNTIME) 2public @interface PropertySources { 3 PropertySource[] value(); 4}
然后使用时两个注解齐上阵 Read More