
Java 中有关抽象的可遍历的对象有 Iterator, Iterable 和 Java 8 的 Stream, Iterable 可简单的用如下代码转换为 Stream
StreamSupport.stream(iterable.spliterator(), false)
再回过头来,为什么要把 Iterator 或 Iterable 转换为 Stream, 因为 Iterator 和 Iterable 只提供有限的遍历操作,如 Iterator 接口的全部四个方法
hasNext()
next()
forEachRemaining(consumer)
remove()同样 Iterable 也只有
iterator(),forEach(consumer), 和spliterator()方法。而 Java 8 的 Stream 就大不一样的,带有大量的链式操作方法,如 filter, map, flatMap, collect 等。因此如果我们已有一个 Iterator 类型,能够被转换为 Stream 类型的话将会大大简化后续的转换,处理操作。具体的从 Iterator 到 Stream 的转换方式有两种 Read More

得益于 Java 8 的 default 方法特性,Java 8 对 Map 增加了不少实用的默认方法,像
getOrDefault,forEach,replace,replaceAll,putIfAbsent,remove(key, value),computeIfPresent,computeIfAbsent,compute和merge方法。另外与 Map 相关的Map.Entry也新加了多个版本的comparingByKey和comparingByValue方法。为达到熟练运用上述除
getOrDefault和forEach外的其他方法,有必要逐一体验一番,如何调用,返回值以及调用后的效果如何。看看每个方法不至于 Java 8 那么多年还总是if(map.containsKey(key))...那样的老套操作。前注:Map 新增方法对 present 的判断是 map.containsKey(key) && map.get(key) != null,简单就是 map.get(key) != null,也就是即使 key 存在,但对应的值为 null 的话也视为 absent。absent 就是 map.get(key) == null。
不同 Map 实现对 key/value 是否能为 null 有不同的约束, HashMap, LinkedHashMap, key 和 value 都可以为 null 值,TreeMap 的 key 为不能为 null, 但 value 可以为 null, 而 Hashtable, ConcurrentMap 则 key 和 value 都不同为 null。一句话 absent/present 的判断是 map.get(key) 是否为 null。
方法介绍的顺序是它们相对于本人的生疏程度而定的。每个方法介绍主要分两部分,参考实现代码与示例代码执行效果。参考实现代码摘自 JDK 官方的 Map JavaDoc。
getOrDefault 方法
本想忽略这个方法的测试,因为涉及到 key 存在,值为 null 的情况。当 key 不存在或相关联的值为 null 时,返回默认值,否则返回实际值。不要认为 key 存在时总是返回 map.get(key) 的值。
参考实现:
Read MoreJava 8 的 Lambda 特性较之于先前的泛型加入更能鼓舞人心的,我对 Lambda 的理解是它得以让 Java 以函数式思维的方式来写代码。而写出的代码是否是函数式,并不单纯在包含了多少 Lambda 表达式,而在思维,要神似。
实际中看过一些代码,为了 Lambda 表达式而 Lambda(函数式),有一种少年不识愁滋味,为赋新词强说愁的味道。从而致使原本一个简单的方调用硬生生的要显式的用类如
apply(),accept(obj)等形式。不仅造成代码可读性差,且可测试性也变坏了。为什么说的是快乐的使用 Java 8 的 Lambda 呢?我窃以为第一个念头声明 Lambda 表达式为实例/类变量(像本文第一段代码那样),而不是方法的,一定会觉得如此使用方式很快乐的。所谓独乐乐,不如众乐乐;独乐乐,众不乐定然是更大的快乐; 更极致一些,不管什么时候必须是:我快乐,所以你也快乐。
一方面也在于 Java 还没有进化到 JavaScript 或 Scala 那样的水平,JavaScript 的函数类型变量,不一定要用
apply或call, 直接括号就能实现方法调用。Scala 的函数类型用括号调用也会自动匹配到apply或update等方法上去。 Read MoreJava 8 引入的 Optional 类型,基本是把它当作 null 值优雅的处理方式。其实也不完全如此,Optional 在语义上更能体现有还是没有值。所以它不是设计来作为 null 的替代品,如果方法返回 null 值表达了二义性,没有结果或是执行中出现异常。
在 Oracle 做 Java 语言工作的 Brian Goetz 在 Stack Overflow 回复 Should Java 8 getters return optional type? 中讲述了引入 Optional 的主要动机。
Our intention was to provide a limited mechanism for library method return types where there needed to be a clear way to represent “no result”, and using null for such was overwhelmingly likely to cause errors.
说的是 Optional 提供了一个有限的机制让类库方法返回值清晰的表达有与没有值,避免很多时候 null 造成的错误。并非有了 Optional 就要完全杜绝 NullPointerException。
在 Java 8 之前一个实践是方法返回集合或数组时,应返回空集合或数组表示没有元素; 而对于返回对象,只能用 null 来表示不存在,现在可以用 Optional 来表示这个意义。
自 Java8 于 2014-03-18 发布后已 5 年有余,这里就列举几个我们在项目实践中使用 Optional 常见的几个用法。
Optional 类型作为字段或方法参数
这儿把 Optional 类型用为字段(类或实例变量)和方法参数放在一起来讲,是因为假如我们使用 IntelliJ IDEA 来写 Java 8 代码,IDEA 对于 Optional 作为字段和方法参数会给出同样的代码建议: Read More
对列表的去重处理,Java 8 在
Stream接口上提供了类似于 SQL 语句那样的distinct()方法,不过它也只能基于对象整体比较来去重,即通过 equals/hashCode 方法。distinct方法的功效与以往的new ArrayList(new HashSet(books))差不多。用起来是List<Book> unique = book.stream().distinct().collect(Collectors.toList())
并且这种去重方式需要在模型类中同时实现 equals 和 hashCode 方法。
回到实际项目中来,我们很多时候的需求是要根据对象的某个属性来去重。比如接下来的一个实例,一个 books 列表中存在 ID 一样,name 却不同的 book, 我们认为这是重复的,所以需要根据 book 的 id 属性对行去重。在 collect 的时候用到的方法是
collectinAndThen(...), 下面是简单代码: Read More
Spring 的 JdbcTemplate 为我们操作数据库提供非常大的便利,不需要显式的管理资源和处理异常。在我们进入到了 Java 8 后,JdbcTemplate 方法中的回调函数可以用 Lambda 表达式进行简化,而本文要说的正是这种 Lambda 简化容易给我们带来的一个 Bug, 这是我在一个实际项目中写的单元测试发现的。
下面就是我们的一个样板代码,在我们的UserRespository中有一个方法 findAll() 用于获得所有用户:1public List<User> findAll() { 2 List<User> users = new ArrayList<>(); 3 jdbcTemplate.query("select id, name from user", rs -> { 4 while (rs.next()) { 5 users.add(new User(rs.getInt("id"), rs.getString("name"))); 6 } 7 }); 8 return users; 9}
Read More- 当我们在使用 Java 8 的 Lambda 表达式时,表达式内容需要抛出异常,也许还会想当然的让当前方法再往外抛来解决编译问题,如下面的代码
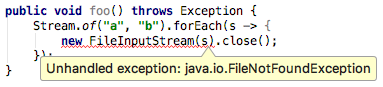 让
让 main()方法抛出Exception还是不解决决编译错误,仍然提示 "Unhandled exception: java.io.FileNotFoundException"。
因为我们可能保持着惯性思维,忽略了 Lambda 本身就是一个功能性接口方法的实现,所以把上面的代码还原为匿名类的方式1public void foo() { 2 Stream.of("a", "b").forEach(new Consumer<String>() { 3 @Override 4 public void accept(String s) { 5 new FileInputStream(s).close(); 6 } 7});
那么对于上面那种情况应该如何处理呢? Read More Java 8 之前如何重复使用注解
在 Java 8 之前我们不能在一个类型重复使用同一个注解,例如 Spring 的注解@PropertySource不能下面那样来引入多个属性文件@PropertySource("classpath:config.properties")
上面的代码无法在 Java 7 下通过编译,错误是: Duplicate annotation
@PropertySource("file:application.properties")
public class MainApp {}
于是我们在 Java 8 之前想到了一个方案来规避 Duplicate Annotation 的错误: 即声明一个新的 Annotation 来包裹@PropertySource, 如@PropertySources1@Retention(RetentionPolicy.RUNTIME) 2public @interface PropertySources { 3 PropertySource[] value(); 4}
然后使用时两个注解齐上阵 Read More- 今天继续探讨
CompletableFuture的特性,它并发时的性能如何呢?我们知道集合的stream()后的操作是序列化进行的,parallelStream()是能够并发执行的,而用CompletableFuture可以更灵活的控制并发。
我们先可以对比一下 parallelStream() 与 CompletableFuture 的性能差异
假设一个这样的耗时 1000 毫秒的计算任务1private static int getJob() { 2 try { 3 Thread.sleep(1000); 4 } catch (InterruptedException e) { 5 } 6 return 50; 7}
分别用下面两个方法来测试,任务数可以通过参数来控制 Read More - 继续对 CompletableFuture 的学习,本然依然不对它的众多方法的介绍,其实也不容易通过一篇述说完所有 CompletableFuture 的操作。此处重点了解下 CompletableFuture 几类操作时所使用的线程,CompletableFuture 的方法重点在它的静态方法以及实现自 CompletionStage 接口的方法,如果是意图异步化编程,反而自我标榜的 Future 中的方法用的少了。
CompletableFuture 根据任务的主从关系为- 提交任务的方法,如静态方法 supplyAsync(supplier[, executor]), runAsync(runnable[, executor])
- 回调函数,即对任务执行后所作出回应的方法,多数方法了,如 thenRun(action), thenRunAsync(action[, executor]), whenComplete(action), whenCompleteAsync(action[, executor]) 等
根据执行方法可分为同步与异步方法,任务都是要被异步执行,所以提交任务的方法都是异步的。而对任务作出回应的方法很多分为两个版本,如- 同步方法,如 thenRun(action), whenComplete(action)
- 异步方法,如 thenRunAsync(action[, executor]), whenCompleteAsync(action[, executor]), 异步方法可以传入线程池,否则用默认的
因此所要理解的 CompletableFuture 的线程会涉及到任务与回调函数所使用的线程。 Read More