《Hands-On Large Language Models》阅读笔记(一)
第一章:大语言模型简介
应该还是在前年读了 《Build a Large Language Model (From Scratch)》前面一小部分,就中断了, 如今又找来一本相关的书籍 《Hands-On Large Language Models》试着啃一啃,能明白多少是多少。拿着中英文的两个版本对照着看,有些中文翻译最好还是不译的好。 这里只会一些杂乱的笔记,算不得什么记要,重要的信息仍然在书上。
学习中相关的测试代码放在 GitHub 仓库 yabqiu/Hands-On-Large-Language-Models, 主要是在 macOS 苹果芯片上进行的测试。虽然官方有一个相应的仓库 HandsOnLLM/Hands-On-Large-Language-Models, 但作为沉浸式学习,亲自根据自己的口味撸一遍代码是非常必要的,所以也会发现我学习时的代码与书中不完全相同。
文字的计算机语义处理有过 Bag-of-words, word2vec, sequence-to-sequence, 再就是 BERT, GPT 这些概念了。
写作 "Attention Is All You Need" 这篇论文的作者们真是太伟大了,拿不到诺贝尔奖,也应该给他们个图灵奖,虽然其中的技术并非很高级,
但这篇论文在 AI 发展史中绝对有着里程碑式的意义。
模型从大的功能分为
- 仅编码的表示模型(representation model),如种种嵌入模型,都比较小的,约几百兆大小, 像 BERT(bidirectional encoder representations from Transformers)
- 生成模型(generative model), 关注生成文本, 通常不会被训练用于生成嵌入, 像 GPT(Generative Pre-trained Transformer)
LLM 这个概念不仅指生成模型,也包括表示模型。生成式 LLM 就是一种 Seq2Seq 的文本生成系统,补全或者说猜测下一个 Token, 所以生成模型又称补全模型
(completion model), OpenAI V1 的 API 有一个是 /v1/chat/completions. 通过训练和微调可以做成指令模型 (instruct model) 或对话模型(chat model).
指令型模型,不仅能补全,而是试图回答问题。
GPT-1 参数量 117M, GPT-2: 1.5B, GPT-3: 175B, 想想现在的非开源的 ChatGPT 5.5, Claude 4.7 的规模不知道会有多大了,好不容易在本地跑上一个 70B 的模型又如何。
上下文长度或窗口,当输入一段文字,模型每预测下一个 Token 后又会把它作为输入(自回归 - auto-regressive), 所以在生成新 Token 时当前上下文长度不断增加。
2023 年 ChatGPT(GPT-3.5) 的发布被称为 生成式 AI 元年, 又叫做 ChatGPT 时刻,除了最广泛的 Transformer 架构外,也有别的如 Mamba 和 RWKV.
LLM 现在更多是指生成式模型,最初步的预训练通常不针对特定的任务或应用,而仅用于预测下一个词,这样的模型称为基础模型(base model)或基座模型(foundation model), 这些模型通常不会遵循指令。
拿一个基座模型,针对具体任务进一步训练,使之能遵循指令,这叫微调,最花钱耗时的是基座模型的预训练. 基础模型和微调模型都属于预训练模型,这些名称有点乱。
特别是模型参数的表示法,一到中文中反而让人糊涂了,比如 3.8B 的参数,硬是要说成 38 亿参数,这个没法和国际接轨了,在这种特定行业的术语应该用 3.8B。 好吧,记住两个对应 10 亿一个 B,万亿是一个 T,按这个关系转换。
下面是要先开始上手模型的使用,还不急着教授如何训练一个基础模型。要用到 Hugging Face 上的一个模型,Python 环境,先安装如下依赖,用 uv 吧
uv add transformers torch accelerate
在 macOS 下,苹果芯片 M4 Pro,
1from transformers import AutoModelForCausalLM, AutoTokenizer
2
3model_name = "microsoft/Phi-3-mini-4k-instruct"
4
5model = AutoModelForCausalLM.from_pretrained(
6 model_name,
7 torch_dtype="auto",
8 device_map="mps", # "cuda" if Nvidia, "cpu" if neither
9)
10
11tokenizer = AutoTokenizer.from_pretrained(model_name)
运行正常的话会下载 7.6GB 的模型,好家伙,一上来就搞了一个大的
1hf cache ls
2ID SIZE LAST_ACCESSED LAST_MODIFIED REFS
3----------------------------------- ---- ----------------- -------------- ----
4model/microsoft/Phi-3-mini-4k-in... 7.6G a few seconds ago 10 minutes ago main
模型文件目录在 ~/.cache/huggingface/hub, Hugging Face 网站的文件列表是 Phi-3-mini-4k-instruct,
本地跑模型就是太费硬盘,每个 LLM 客户端工具都有自己的格式与目录。
下载完后,加载执行,这里没任何输出,如果调试查看 tokenizer 的话,这个分词器的词汇大小(vocab_size) 是 32000,加上特殊字符就是 32011.
里面其他有意思的信息
1SPECIAL_TOKENS_ATTRIBUTES: ['bos_token', 'eos_token', 'unk_token', 'sep_token', 'pad_token', 'cls_token', 'mask_token']
2added_tokens_encoder: {'</s>': 2, '<s>': 1, '<unk>': 0, '<|assistant|>': 32001, '<|endoftext|>': 32000, '<|end|>': 32007, '<|placeholder1|>': 32002, '<|placeholder2|>': 32003, '<|placeholder3|>': 32004, '<|placeholder4|>': 32005, '<|placeholder5|>': 32008, '<|placeholder6|>': 32009, '<|system|>': 32006, '<|user|>': 32010}
3model_input_names: ['input_ids', 'attention_mask']
4special_tokens_map: {'bos_token': '<s>', 'eos_token': '<|endoftext|>', 'pad_token': '<|endoftext|>', 'unk_token': '<unk>'}
5vocab_file: '/Users/yanbin/.cache/huggingface/hub/models--microsoft--Phi-3-mini-4k-instruct/snapshots/f39ac1d28e925b323eae81227eaba4464caced4e/tokenizer.model'
6vocab_files_names: {'tokenizer_file': 'tokenizer.json', 'vocab_file': 'tokenizer.model'}
7model_max_length: 4096注意到该模型的后缀为 -instruct, 表示这是一个经过指令微调过的模型,它是能理解指令,进行对话的. 继续实现像 LangChain 的一个 init_chat_model()
1generator = pipeline(
2 "text-generation",
3 model=model,
4 tokenizer=tokenizer,
5 return_full_text=False,
6 max_new_tokens=500,
7 do_sample=False
8)
9
10output = generator([
11 {"role": "user", "content": "Create a funny joke about chickens."}
12])
13
14print(output[0]["generated_text"])
15# output: [{'generated_text': ' Why did the chicken join the band? Because it had the drumsticks!'}]
输出为
Why did the chicken join the band? Because it had the drumsticks!
几个注意的参数
- return_full_text: False 时只返回生成的文本,不返回输入的文本
- max_new_tokens: 允许模型生成的最大 Token 数
- do_sample: 决定模型是否采用策略来选择下一个 Token, False 时选择概率最高的 Token, temperature 的创意值就是基于不同的采用策略来来选择下一个 Token 的。
模型分两大类,表示模型(仅编码, 如 BERT) 与生成模型(仅解码, 如 GPT 系列),这两类都被视为 LLM, 通常面对终端用户的是生成模型。
第二章: Token 和 Embedding
Tokens 和 Embeddings, 这两个词翻译成中文都怪怪的, 词元, 嵌入, 还是用英文吧。Token 就是 LLM 的词汇,Token 数字化即
Embedding. Token embedding 一个著名的先驱就是 word2vec.
Tokenization 即通常的分词,OpenAI Platform tokenizer

看个 encode/decode 的例子,重用上面声明的 tokenizer, 补充下面的代码
1tokenizer = AutoTokenizer.from_pretrained(model_name)
2
3prompt = "Write an email apologizing to Sarah for the tragic garding mishap. Explain ho it happened.<|assistant|>"
4print(tokenizer.tokenize(prompt))
5tokenized = tokenizer(prompt, return_tensors="pt").to("mps")
6print(tokenized.input_ids)
7
8generate_ouput = model.generate(
9 input_ids=tokenized.input_ids,
10 attention_mask=tokenized.attention_mask,
11 pad_token_id=tokenizer.eos_token_id, # 用 eos_token_id 来填充输入文本,是一个常用做法
12 max_new_tokens=20
13)
14
15print(tokenizer.decode(generate_ouput[0]))
每次执行都要重新加载 7.6GB 的模型到 macOS 的统一内存中,LLM 作为服务的话肯定不能这么干(应只加载模型一次)。看输出
1['▁Write', '▁an', '▁email', '▁apolog', 'izing', '▁to', '▁Sarah', '▁for', '▁the', '▁trag', 'ic', '▁gard', 'ing', '▁m', 'ish', 'ap', '.', '▁Exp', 'lain', '▁ho', '▁it', '▁happened', '.', '<|assistant|>']
2tensor([[14350, 385, 4876, 27746, 5281, 304, 19235, 363, 278, 25305,
3 293, 17161, 292, 286, 728, 481, 29889, 12027, 7420, 5089,
4 372, 9559, 29889, 32001]], device='mps:0')
5Write an email apologizing to Sarah for the tragic garding mishap. Explain ho it happened.<|assistant|> Subject: Sincere Apologies for the Gardening Mishap
6
7Dear Sarah从这里可以看到输入是怎么被拆分的,有完整单词,也有单词的一部分,标点符号是个单独的 Token, 还有一些特殊的 Token, 例如 <|assistant|>
是一个特殊的 Token, 用于标识模型生成的文本的开始, 从 tokenizer 的 added_tokens_encoder 和 added_tokens_decoder 就能对
<|assistant|> 进行特殊处理, 除了 <|assistant|> 外,还有 <|user|>, <|system|>, 用过 LangChain 的是不是很熟悉啊,像
ToolMessage 等估计还能用 <|placeholder1|> 等
注意到空格不作为单独的 Token 看待,而是每个 Token 前都有一个 ▁ 隐藏字符,有则是一个独立的词,无则与前面的 Token 连接在一起的。
分词器流行的有 BPE(byte pair encoding, 广泛用于 GPT 模型)和 WordPiece(用于 BERT 模型)。分词的粒度有以下几种
- 词级分词: 这种分词很自然,按空格切开,在早期的
word2vec等模型很常见,但对前后缀不同 Token, 例如play,playing,played等, 词级分词会把它们当成不同的 Token, 导致词汇表过大, 模型难以学习到它们之间的关系. - 子词级分词: 解决了上面的前后缀的问题,例如上面只要训练
play, 后缀ing,ed则可与多数动词组合, 而且还能创造新词。 - 字符级分词和字节级分词: play 被拆成
p,l,a,y四个 Token, 或者按 unicode 拆成单个字节, 这就脱离了语义,不知在什么模型中用到
以下是不同分词器产生的效果比较
1from transformers import AutoTokenizer
2
3colors_list = [
4 '102;194;165', '252;141;98', '141;160;203',
5 '231;138;195', '166;216;84', '255;217;47'
6]
7
8def show_tokens(sentence, tokenizer_name):
9 print(f"------{tokenizer_name=}------")
10 tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
11 token_ids = tokenizer(sentence).input_ids
12 for idx, t in enumerate(token_ids):
13 token = tokenizer.decode(t)
14 if token == "\n":
15 print('\r')
16 else:
17 print(
18 f'\x1b[0;30;48;2;{colors_list[idx % len(colors_list)]}m' +
19 tokenizer.decode(t) +
20 '\x1b[0m',
21 end=' '
22 )
23 print("")
24
25
26text = """
27English and CAPITALIZATION
28🎵 鸟
29show_tokens False None elif == >= else: two tabs:" " Three tabs: " "
3012.0*50=600
31"""
32
33show_tokens(text, "bert-base-uncased") # WordPiece, 词汇大小 30522
34show_tokens(text, "bert-base-cased") # WordPiece, 词汇大小 28996
35show_tokens(text, "gpt2") # BPE, 词汇大小 50257
36show_tokens(text, "google/flan-t5-small") # SentencePiece, 词汇大小 32100
37show_tokens(text, "Xenova/gpt-4") # BPE, 词汇大小略多于 100,000
38show_tokens(text, "bigcode/starcoder2-15b") # BPE, 词汇大小 50,257
39show_tokens(text, "facebook/galactica-1.3b") # BPE, 词汇大小 50,000
40show_tokens(text, "microsoft/Phi-3-mini-4k-instruct") # BPE, 词汇大小 32,000
效果图

执行完后本地有了以下几个模型,分词器非常的小
1hf cache list
2ID SIZE LAST_ACCESSED LAST_MODIFIED REFS
3----------------------------------- ------ -------------- -------------- ----
4model/Xenova/gpt-4 7.2M 21 minutes ago 21 minutes ago main
5model/bert-base-cased 649.9K 22 minutes ago 22 minutes ago main
6model/bert-base-uncased 698.2K 26 minutes ago 26 minutes ago main
7model/facebook/galactica-1.3b 2.1M 21 minutes ago 21 minutes ago main
8model/google/flan-t5-small 3.2M 22 minutes ago 22 minutes ago main
9model/gpt2 2.9M 22 minutes ago 22 minutes ago main
10model/microsoft/Phi-3-mini-4k-in... 7.6G 13 hours ago 15 hours ago main
bert-base-uncased,bert-base-cased: 分别为大小写不敏感与敏感的bert,不敏感则全转换成小写,不认识的标识为[UNK],##特殊字符表示是前面是否有空格。gpt2,Xenova/gpt-4: 不认识的显示为问号,Token 前自带空格表示是否与前面相连。gpt2一个tab对应一个token, 而Xenova/gpt-4一个token可表示多个空白,比如适于生成 Python 代码.gpt-4中有自己的eliftoken
注意一些特殊的 Token, 像 [UNK]: unknown, [SEP]: 段落分割, [PAD]: 填充,[CLS]: 分类,classification, [MASK]: 训练过程中用于隐藏
Token,猜猜猜用的。不同分词器会有自己特殊 Token, 如 Phi-3 的 <|user|>, <|system|>, <|assistant|> 用于 ChatBot 的.
分词中包含的 Token 是由三个主要因素决定的:分词方法,用于初始化分词器的参数, 以及训练分词器的目标数据所在的领域。分词方法最常用就是 BPE,
分词器参数包括词表大小,特殊 Token, 大小写处理策略。
Token Embedding, 词分好了,这样语言变成 Token 序列了,要为每个 Token 找到最佳的数值表示,这样才能被计算。一个 Token 并只不是对应一个标量值, 还将映射为一个向量,每个分量值就是权重值,开始随机初始化,训练模型就是调教这些权重值。
测试 Embedding
1from transformers import AutoModel, AutoTokenizer
2
3tokenizer = AutoTokenizer.from_pretrained("microsoft/deberta-base")
4model = AutoModel.from_pretrained("microsoft/deberta-v3-xsmall")
5
6tokens = tokenizer('Hello world')
7for token in tokens.input_ids:
8 print(tokenizer.decode(token), ':', token)
9
10tokens = tokenizer('Hello world', return_tensors="pt")
11
12output = model(**tokens)
13
14print(output)
15print(output[0].shape)
观察上面的输出
1[CLS] : 1
2Hello : 31414
3 world : 232
4[SEP] : 2
5BaseModelOutput(last_hidden_state=tensor([[[-3.4844, 0.0862, -0.1819, ..., -0.0612, -0.3904, 0.3018],
6 [ 0.1899, 0.3203, -0.2313, ..., 0.3726, 0.2478, 0.8022],
7 [ 0.2070, 0.5029, -0.0490, ..., 1.2188, -0.2271, 0.8574],
8 [-3.4277, 0.0643, -0.1427, ..., 0.0659, -0.4363, 0.3845]]],
9 dtype=torch.float16, grad_fn=<NativeLayerNormBackward0>), hidden_states=None, attentions=None)
10torch.Size([1, 4, 384])
Hello world 拆成 4 个 Token, 每个 Token 嵌入到一个包含 384 个数值的向量中(这种情景下 嵌入 的意义就表达出来了)。
output[0] 有三个维度,第一个维度是 batch(同时向模型发送多个句子), 第二个维度对应每一个 Token,第三个维度是每个 Token 的向量。
把 batch, token, token embedding 用一张图来表示
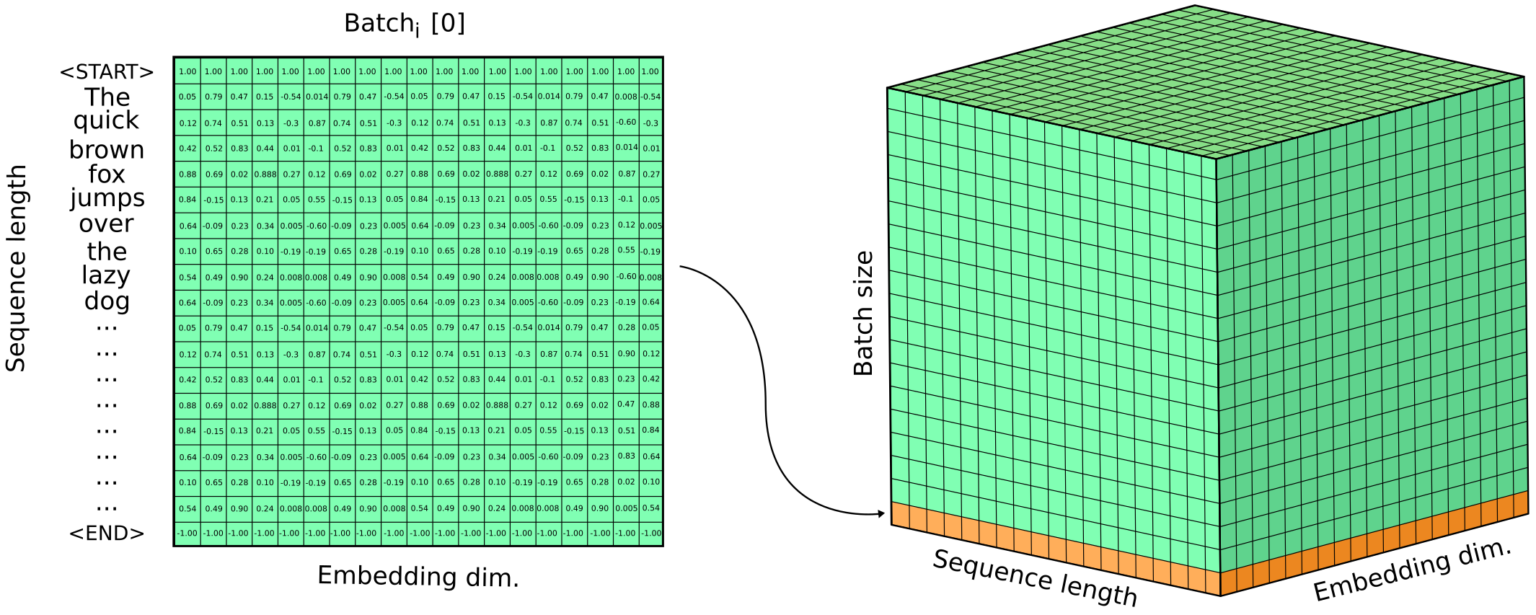
这是 Token Embeddings, 一个 Token 对应的一个向量,LLM 还有 Text Embeddings 的概念,用单个向量来表示多个 Token 组成的文本,又想到了 RAG. RAG 的文本资料切分和向量化就是做的文本嵌入,一个向量表示一个文本切片。生成文本嵌入有多种方法,常见方法之一就是对每个 Token Embedding 向量取平均值, 组成一个新的向量。高质量的文本嵌入要使用专门为文本嵌入训练的模型。
1from sentence_transformers import SentenceTransformer
2
3model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")
4vector = model.encode("Best movie ever!")
5
6print(vector.shape) # (768,)
上面代码把 Best movie ever! 嵌入到了一个维度为 768 的向量中。
Token Embeddings 除了在文本和语言生成方面有用,还应用于其他许多领域,如推荐引擎,机器人技术。下面来学习 word2vec.
1import gensim.downloader as api
2
3# 下载 Embedding (66M, glove,训练数据来自维基百科,向量大小:50)
4# 其他选项如: 'word2vec-google-news-300', 可查看 https://github.com/piskvorky/gensim-data
5model = api.load("glove-wiki-gigaword-50")
6
7similarities = model.most_similar([model['king']], topn=5)
8for word, score in similarities:
9 print(f"{word:<10} {score:.4f}")
找相似的 Token,找到
1king 1.0000
2prince 0.8236
3queen 0.7839
4ii 0.7746
5emperor 0.7736
word2vec 有两种训练方式, skip-gram 和 CBOW(Continuous Bag of Words) 来训练用一个词预测它周围的词,Skip-gram 输入中心词输出周围的词,
CBOW 相反,输入周围的词预测中心词。word2vec 的两个主要思想是 skip-gram 和负采样(negative sampling),
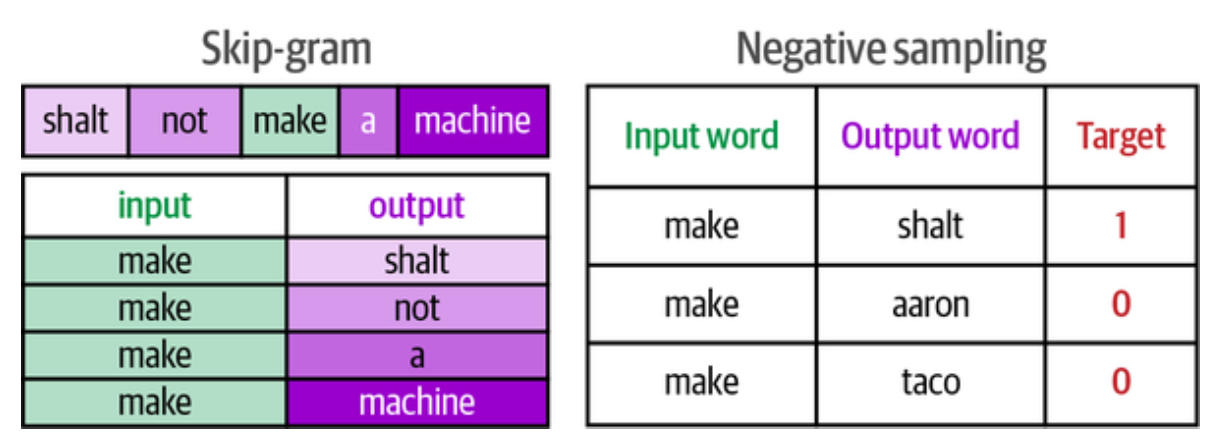
word2vec 是用滑动窗口来训练一个词来预测它周围的词,最后也是把 Token 嵌入到一个向量中,最终训练的是不断地优化嵌入向量中的权重值,
用以预测两个向量之间是否具有某种关系。
最后是一个训练歌曲推荐系统的实例,
完整代码
1import gzip
2
3import pandas as pd
4from pathlib import Path
5
6import time
7from gensim.models import Word2Vec
8
9current_folder = Path(__file__).parent
10
11# https://storage.googleapis.com/maps-premium/dataset/yes_complete/train.txt
12with gzip.open(current_folder.joinpath('train.txt.gz'), 'rt') as f:
13 lines = f.readlines()[2:]
14 playlist = [s.rstrip().split() for s in lines if len(s.split())>1]
15 print(f"number of playlist: {len(playlist)}")
16 for ids in playlist[:2]:
17 print(f"number of song in this playlist: {len(ids)}: {str(ids[:10]).rstrip(']')}, ....")
18
19total_songs = {id for ids in playlist for id in ids}
20print(f"total songs: {len(total_songs)}")
21
22# https://storage.googleapis.com/maps-premium/dataset/yes_complete/song_hash.txt
23with gzip.open(current_folder.joinpath('song_hash.txt.gz'), 'rt') as f:
24 lines = f.readlines()
25 songs = [[field.strip() for field in s.split('\t')] for s in lines]
26 songs_df = pd.DataFrame(songs, columns=['id', 'title', 'artist'])
27 songs_df = songs_df.set_index('id')
28 print(f"songs_df shape: {songs_df.shape}")
29 print(f"songs_df sample: \n {songs_df.head()}")
30
31time0 = time.time()
32model = Word2Vec(sentences=playlist, vector_size=32, window=20, min_count=1, workers=4)
33print(f"training time: {time.time() - time0:.2f}s")
34print(f"model parameters: {model.wv.vectors.shape}\n")
35
36print(f"model parameters: {model.wv.vectors.shape}")
37
38def recommend_songs(song_id: str, topn=5):
39 similarities = model.wv.most_similar(positive=song_id, topn=topn)
40
41 print(f"similar songs of [{songs_df.loc[song_id]['title']}]:\n")
42
43 print(f"{'No':<2} {'Title':<30} {'Score'}")
44 for idx, (similar_id, score) in enumerate(similarities):
45 print(f"{idx+1:<2} {songs_df.loc[similar_id]['title']:<30} {score:.4f}")
46
47recommend_songs('2172')
48print(f"\n{"*" * 50}\n")
49recommend_songs('21720', 2)
输出如下
1number of playlist: 11088
2number of song in this playlist: 97: ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ....
3number of song in this playlist: 205: ['78', '79', '80', '3', '62', '81', '14', '82', '48', '83', ....
4total songs: 75261
5songs_df shape: (75262, 2)
6songs_df sample:
7 title artist
8id
90 Gucci Time (w\/ Swizz Beatz) Gucci Mane
101 Aston Martin Music (w\/ Drake & Chrisette Mich... Rick Ross
112 Get Back Up (w\/ Chris Brown) T.I.
123 Hot Toddy (w\/ Jay-Z & Ester Dean) Usher
134 Whip My Hair Willow
14training time: 3.03s
15model parameters: (75261, 32)
16
17similar songs of [Fade To Black]:
18
19No Title Score
201 Signs 0.9947
212 Mama I'm Coming Home 0.9945
223 Highway To Hell 0.9939
234 November Rain 0.9939
245 Flying High Again 0.9934
25
26**************************************************
27
28similar songs of [Flor Sin Retono]:
29
30No Title Score
311 Maruja 0.9908
322 Amargo Adios 0.9895
这是在做什么呢?从 "train.txt.gz" 读出来的每一行是一个播放列表,共有 11088 个列表,播放列表中是每首歌的 ID, 该文件中一共有 75261 个唯一的 ID. 在训练时每一行就是一句话,一个 ID 是一个 Token, 经常出现在一个播放列表,并且离得越近的 ID 越相似。
看关键的用于训练的代码
1model = Word2Vec(sentences=playlist, vector_size=32, window=20, min_count=1, workers=4)
训练的数据集就是 playlist, 所有歌的 ID 组成了一个词汇表(从 playlist 中抽取, 大小为 75261),每个 ID(Token) 嵌入到一个维度为 32 的向量中,
滑动窗口大小为 20, 只关注与当前 ID(Token) 前后距离 20 以内的相关歌曲,四个 workers 进行并行训练,
训练后会产生一个形状为 (75261, 32) 的 model.wv.vectors 权重值,即模型参数,训练好了就能用余弦相似度匹配歌曲进行推荐了。向量索引与
Token 之间的对应关系存储在 model.wv.index_to_key 和 model.wv.key_to_index.
为了不草草结束,这里也加一个书上第二章的学习小结,分词就是把文本转换为 Token Id, 常见的分词方案应该是子词分解。分词器算法(如 BPE, WordPiece,
SentencePiece) 要考虑的参数有词表大小,特殊 Token, 大小写处理,以及应用领域等因素,如空白,多连续空格的表示。
分词器为不同的应用领域会引入不同的特殊 Token, 如 <|user|>, <|assistant|>, <|system|> 用于 ChatBot 的. 用一个 Token
可表示连续的几个空格,方便于编程代码的输出。
在 LLM 之前, word2vec, GloVe 和 fastText 等词嵌入方法非常流行,现在为 LLM 的上下文相关的词嵌入所取代。除了词嵌入(Token Embeddings), 用于训练, 还有文本嵌入(Text Embeddings),在 RAG 中使用。word2vec 算法依赖两个主要思想: skip-gram 模型和负采样。
永久链接 https://yanbin.blog/hands-on-large-language-models-reading-notes-1/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。