《Hands-On Large Language Models》阅读笔记(十一)
一鼓作气,继续阅读本书,来到了第十一章,本章的标题是 “为分类任务微调表示模型”,而嵌入模型也是表示模型的一种,前一章有学过如何训练和微调嵌入模型。 第 4 章中学习了使用预训练模型进行文本分类,本章将要学习对 BERT 模型的多种微调方法,以适应分类任务。还是文本分类,下一章也就是原书的最后一章才会讲到微调生成模型, 这才是本人更加期待的内容,还是按顺序来消化吧。
在第 4 章处理监督分类时采用过两类模型:特定任务模型(如情感分析)和用于生成文本嵌入表示的嵌入模型。在微调时是否要冻结一部分参数可分为参数高效微调与全量微调
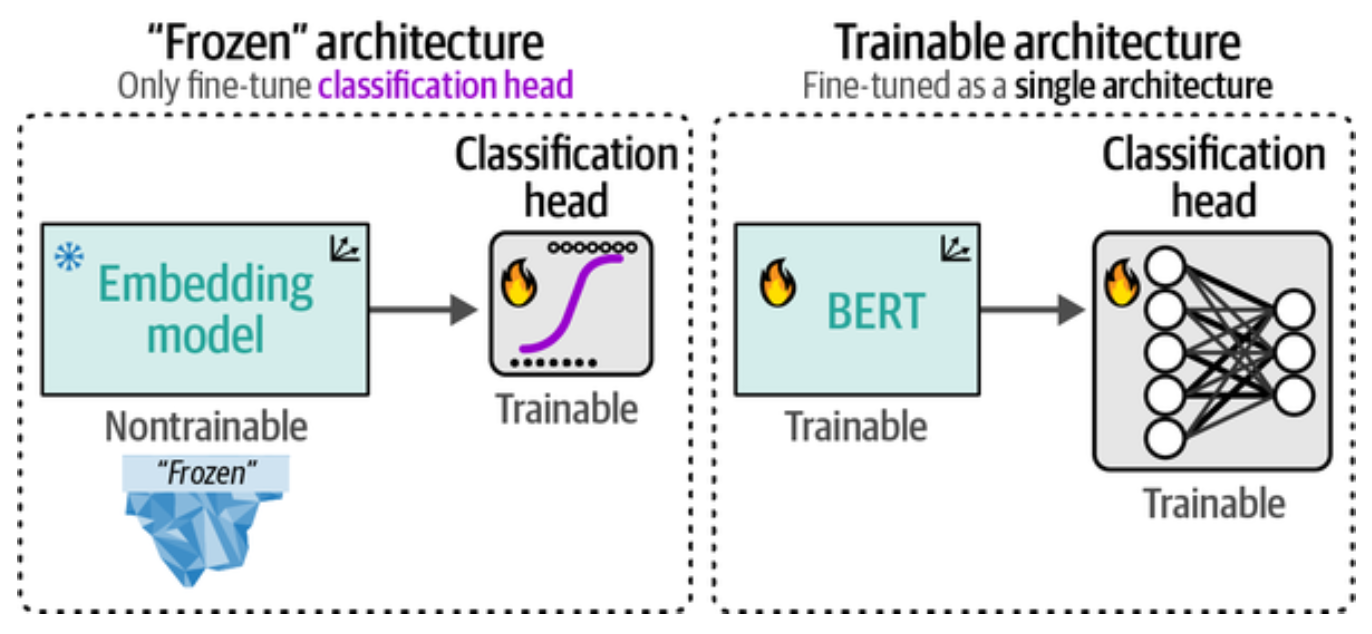
左边是冻结嵌入模型参数,仅微调分类头(classification head),右边是全量微调的架构, 嵌入模型和分类头的参数都可更新,如果我们有充足的训练数据和计算资源可进行全量微调。 全量微调时反向传播过程将从分类头开始, 逐层贯穿整个 BERT 模型。
下面来实践一个微调预训练的 BERT 模型,让模型能进行情感分析,训练数据是我们前面用到过的烂番茄数据集,基础模型是 bert-base-cased.
该基础模型有 12 层 Transformer 编码器, 每层有 768 个隐藏单元和 12 个注意力头, 总共有 110M 参数。
1import numpy as np
2import evaluate
3from datasets import load_dataset
4from transformers import AutoTokenizer, AutoModelForSequenceClassification
5from transformers import DataCollatorWithPadding, TrainingArguments, Trainer
6
7# 在 macOS 下还能用 load_dataset("rotten_tomatoes") 加载数据,在 Linux 下必须加上 namespace
8tomatoes = load_dataset("cornell-movie-review-data/rotten_tomatoes")
9train_data, test_data = tomatoes["train"], tomatoes["test"] # 各 8530, 1066 条数据
10# 训练集和测试集又各自有一半是正面评价(label=1,一半是负面评价(label=0)
11
12model_id = "bert-base-cased"
13
14# num_labels=2 表示二分类任务,BERT 顶层会接一个 2 维分类头
15model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=2)
16tokenizer = AutoTokenizer.from_pretrained(model_id)
17
18# 对批次中的序列进行填充,使其长度与最长序列一致
19data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
20
21# batch 后 example 的格式为 {"text": ["sentence1", "sentence2", ...], "label": [0, 1, ...]}
22def preprocess_function(examples):
23 # 对 examples.text 中的文本进行分词后编码,每段文本编码后长度不一
24 return tokenizer(examples["text"], truncation=True)
25
26# 对训练数据和测试数据进行分词处理
27tokenized_train = train_data.map(preprocess_function, batched=True)
28tokenized_test = test_data.map(preprocess_function, batched=True)
29
30# 这是用来观测,不参与训练过程,也就不会影响训练结果
31def compute_metrics(eval_pred):
32 """
33 计算 F1 分数(F-score: F1 = F-measure with β=1), 它是衡量精确率和召回率的综合指标,以正面为例
34 精确率(Precision)为预测为正面的样本,真正是正面的比例; 召回率(Recall)为所有是正面的样本,被正确预测为正面的比例
35 """
36 logits, labels = eval_pred # 分别为 eval_pred.elements 中两组数据
37
38 # argmax 是返回最大值所在的索引,如 logits=[[-1.2, 2.5], [3.1, -0.8], [0.3, 1.9]] 表示负面和正面评分, 最后它返回 [1, 0, 1]
39 predictions = np.argmax(logits, axis=-1)
40
41 # 预测的结果 predictions 与实际的标签 labels 对比, 算出 F1 分数
42 load_f1 = evaluate.load("f1")
43 f1 = load_f1.compute(predictions=predictions, references=labels)["f1"]
44 return {"f1": f1}
45
46# 用于参数调优的训练参数
47training_args = TrainingArguments(
48 "sentiment_model",
49 learning_rate=2e-5, # BERT 微调的典型学习率
50 per_device_train_batch_size=16,
51 per_device_eval_batch_size=16,
52 num_train_epochs=1,
53 weight_decay=0.01, # L2 正则化,防止过拟合
54 save_strategy="epoch", # 每轮结束保存一次
55 eval_strategy="epoch", # 每轮训练后自动评估并调用 compute_metrics
56 report_to="none"
57)
58
59# 执行训练过程的 Trainer
60trainer = Trainer(
61 model=model,
62 args=training_args,
63 train_dataset=tokenized_train,
64 eval_dataset=tokenized_test,
65 processing_class = tokenizer,
66 data_collator=data_collator,
67 compute_metrics=compute_metrics, # 前面若没有配置 eval_strategy 的话 compute_metrics 不会被调用
68)
69
70trainer.train()
71trainer.save_model()
训练完查看 trainer.evaluate() 的输出为
| Training Loss | Validation Loss | Step | F1 |
|---|---|---|---|
| 0.409350 | 0.363490 | 534 | 0.855796 |
1{'eval_loss': 0.36348992586135864, 'eval_f1': 0.8557964184731386}
训练后作个测试,用新的 sentiment_model 与基础模型 bert-base-cased 进行对比,看看微调后的模型在分类任务上是否有提升。
1from transformers import pipeline, AutoTokenizer
2
3bert_model = "bert-base-cased"
4tokenizer = AutoTokenizer.from_pretrained(bert_model)
5
6def classify(classifier_model, sentences: list[str]):
7 classifier = pipeline(
8 "text-classification",
9 model=classifier_model,
10 tokenizer=tokenizer
11 )
12 return classifier(sentences)
13
14inputs = [
15 "This movie is fantastic! I really enjoyed it.",
16 "The plot was boring and the acting was terrible."
17]
18
19print(bert_model, classify(bert_model, inputs))
20print("sentiment_model", classify("sentiment_model", inputs))
输出结果为
1bert-base-cased [{'label': 'LABEL_0', 'score': 0.7182996869087219}, {'label': 'LABEL_0', 'score': 0.724980354309082}]
2sentiment_model [{'label': 'LABEL_1', 'score': 0.9684972763061523}, {'label': 'LABEL_0', 'score': 0.9542821049690247}]
bert-base-cased 判定第一句为负面评价,第二句也是负面评价,其实不微调 bert-base-cased 而用它来进行分类是没有意义的,而微调后的
sentiment_model 模型是能正确判定第一句为正面评价,第二句为负面评价,显然微调后的模型在符合了我们的特定任务需求。
冻结层(Freezing Layers)
训练时可冻结网络的某些的参数,下面将会冻结 BERT 模型的主体结构,仅对分类头进行微调,并学习如何冻结层。
1from transformers import AutoModelForSequenceClassification, AutoTokenizer
2
3model_id = "bert-base-cased"
4model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=2)
5tokenizer = AutoTokenizer.from_pretrained(model_id)
6
7for name, param in model.named_parameters():
8 print(name)
下面打印了所有的层, bert-base-cased 模型的层数为 12 层(编码器),最后还有一个独立分类头(classifier)。
1bert.embeddings.word_embeddings.weight
2bert.embeddings.position_embeddings.weight
3bert.embeddings.token_type_embeddings.weight
4bert.embeddings.LayerNorm.weight
5bert.embeddings.LayerNorm.bias
6bert.encoder.layer.0.attention.self.query.weight
7bert.encoder.layer.0.attention.self.query.bias
8bert.encoder.layer.0.attention.self.key.weight
9bert.encoder.layer.0.attention.self.key.bias
10bert.encoder.layer.0.attention.self.value.weight
11bert.encoder.layer.0.attention.self.value.bias
12bert.encoder.layer.0.attention.output.dense.weight
13bert.encoder.layer.0.attention.output.dense.bias
14bert.encoder.layer.0.attention.output.LayerNorm.weight
15bert.encoder.layer.0.attention.output.LayerNorm.bias
16bert.encoder.layer.0.intermediate.dense.weight
17bert.encoder.layer.0.intermediate.dense.bias
18bert.encoder.layer.0.output.dense.weight
19bert.encoder.layer.0.output.dense.bias
20bert.encoder.layer.0.output.LayerNorm.weight
21bert.encoder.layer.0.output.LayerNorm.bias
22......
23bert.encoder.layer.11.output.LayerNorm.bias
24bert.pooler.dense.weight
25bert.pooler.dense.bias
26classifier.weight
27classifier.bias
12 层编码器编号为 0-11,每一层包含多个注意力头(attention heads),前馈神经网络(全连接网络, dense network 或 FFN)以及层归一化(layer normalization)组件. 这里又看到注意力头的 q(query), k(key), v(value) 权重和偏置参数。
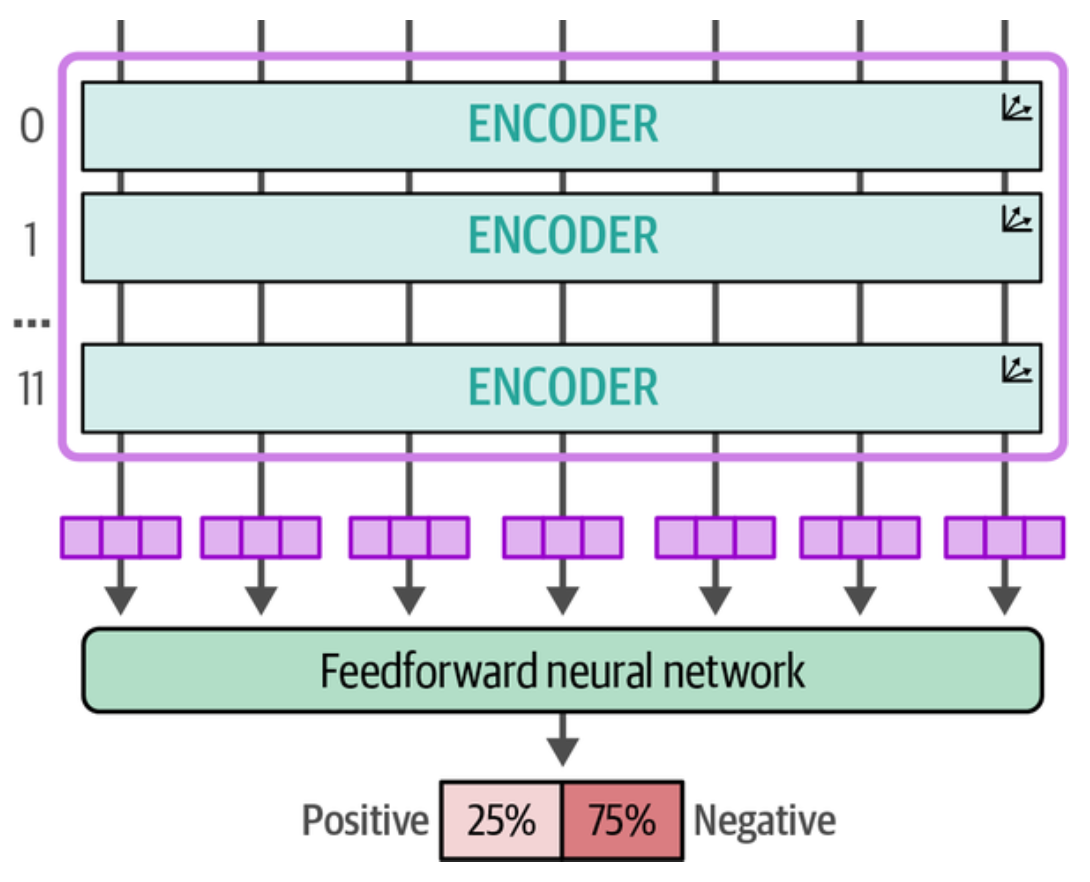
我们可以选择哪些层(0-11 层编码器,或分类头)进行冻结,比如所有编码器层冻结,分类头不冻结
1for name, param in model.named_parameters():
2 if name.startswith("classifier"):
3 param.requires_grad = True # True 为不冻结,可训练(更新参数),默认为 True, 所以可简化为冻结不是 "classifier" 开头的层
4 else:
5 param.requires_grad = False
冻结编码器层后,然后重用一样的代码来微调模型,因为只对分类头进行微调,所以训练速度显著提升,
训练完查看 trainer.evaluate() 的输出为
| Training Loss | Validation Loss | Epoch | F1 |
|---|---|---|---|
| 0.698450 | 0.688880 | 1 | 0.610845 |
1{'eval_loss': 0.6888798475265503, 'eval_f1': 0.6108452950558214}
F1 分数比之前的 0.855796 明显下降了不少。
或者尝试冻结前面的 10 个编码器块
1for name, param in model.named_parameters():
2 if name.startswith("bert.encoder.layer.10"):
3 break
4 param.requires_grad = False
同样的方式训练后查看 trainer.evaluate() 的输出为
| Training Loss | Validation Loss | Epoch | F1 |
|---|---|---|---|
| 0.476780 | 0.413234 | 1 | 0.810395 |
1{'eval_loss': 0.41323378682136536, 'eval_f1': 0.8103946102021174}
比冻结全部编码器层的 F1 分数 0.610845 提升很多,虽然没有全量微调的 0.855796 那么高,但训练速度提升了很多,且性能损失不大。
如果计算资源有限的情况下,仅训练部分层仍能取得可接受的效果。针对这一应用场景,我们可以逐步冻结编码器块并实施微调操作,最后的结论是,
仅需要训练前 5 个编码器块即可获得接近完整训练所有编码器层的性能表现。所以资源有限的情况下并不用训练所有的层,但要找到哪些层可被冻结得靠经验了。
少样本分类(Few-Shot Classification)
分类器仅通过少量标注样本即可学习并识别不同的目标标签,看起来有点类似于增强型 SBERT。再看 Few-Shot Classification 的技术核心思想是通过为每个类别精心标注少量高质量的数据点来完成模型训练。但又不像增强型 SBERT 有黄金数据集和白银数据集,少样本分类只需要黄金数据?
SetFit: 少样本高效微调方案
SetFit(Sentence Transformer Fine-tuning), 又是 sentence-transformer 架构的微调方案,仅需少量标注样本,SetFit 表现即可媲美基于大量标注数据集的微调。
SetFit 的三个关键阶段
- 采样训练数据:通过对标注数据的类内与类间样本选择,生成包含正例与负例的训练对。
- 微调嵌入模型:利用生成的训练数据,对预训练的嵌入模型进行微调
- 训练分类器:在优化后的嵌入模型基础上构建分类头,并使用之前生成的训练数据对其进行训练
这和增强型 SBERT 真的很像,都是由少量标注良好的数据产生更大量的训练数据,来微调或训练模型。
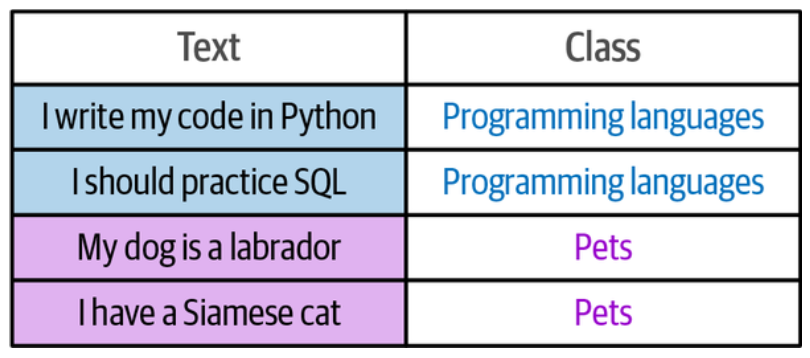
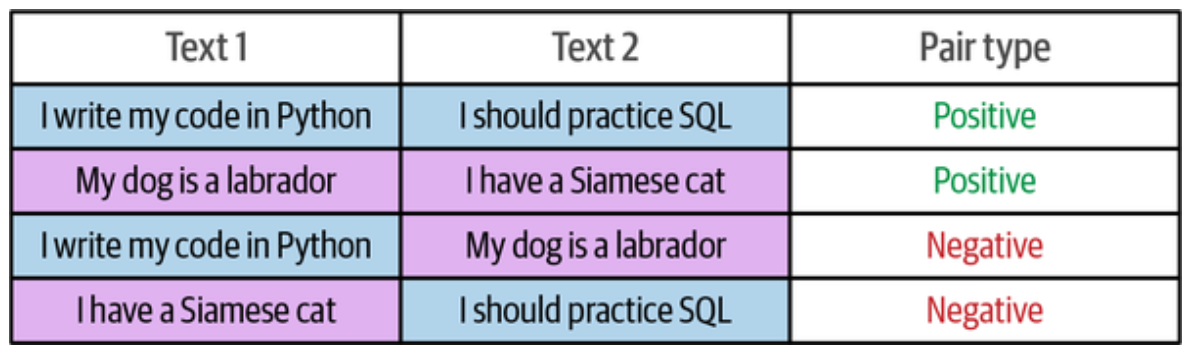
由左边良好标注的数据通过选择生成右边更大量的标注数据,然后用来微调嵌入模型,最后构建分类头再进行训练。
setfit 库当前版本为 1.1.3, 它对 transformers 和 sentence-transformers 的版本有要求标明的是
1 "sentence-transformers[train]>=3",
2 "transformers>=4.41.0",
而实际上 pip install setfit 会安装 transformers==5.9.0 和 sentence-transformers==5.5.1,这与 setfit 是不兼容的,
只要一 import setfit 就会报错
ImportError: cannot import name 'default_logdir' from 'transformers.training_args' (/home/yanbin/aaa/.venv/lib/python3.12/site-packages/transformers/training_args.py)
安装时需要指定 transformers 的版本
1pip install setfit transformers==4.57.6
安装的 sentence-transformers 版本仍为 5.5.1, 最后的搭配是 setfit 1.1.3, transformers 4.57.6, sentence-transformers 5.5.1.
不知道 setfit 现在是否还常用,显然该项目不怎么活跃了,主要的更新还是两年前。现在流行的微调方案 LLM zero/few-shot prompting, LoRA/PEFT, FastFit.
应用 SetFit 进行微调的代码
1from datasets import load_dataset
2from setfit import sample_dataset, SetFitModel, TrainingArguments as SetFitTrainingArguments, Trainer as SetFitTrainer
3
4tomatoes = load_dataset("cornell-movie-review-data/rotten_tomatoes") # 8530 条数据
5train_data, test_data = tomatoes["train"], tomatoes["test"]
6sampled_train_data = sample_dataset(train_data, num_samples=16) # 每个类别各采样 16 条记录,共 32 条
7
8model = SetFitModel.from_pretrained("sentence-transformers/all-mpnet-base-v2")
9
10args = SetFitTrainingArguments(
11 "setfit_fine_tune_model",
12 num_epochs=3,
13 num_iterations=20 # 要生成的文本对数量
14)
15args.eval_strategy = args.evaluation_strategy
16
17trainer = SetFitTrainer(
18 model=model,
19 args=args,
20 train_dataset=sampled_train_data,
21 eval_dataset=test_data,
22 metric="f1"
23)
24
25trainer.train()
26trainer.model.save_pretrained("setfit_fine_tune_model")
执行中看到输出的训练数据统计
1***** Running training *****
2 Num unique pairs = 1280
3 Batch size = 16
4 Num epochs = 3
前面 num_samples=16 表示正负样本各采样 16 条记录,共 32 条记录,num_iterations=20 表示要生成的文本对数量,每个正例对和负例对都进行双向扩展,
最终生成了 16 * 2 * 20 * 2 = 1280 个文本对。
评估 trainer.evaluate() 的输出为
{'f1': 0.8465204957102002}
在只有最初的 32 条标注数据的情况下,f1=0.8465 与使用全部 8530 条标注数据微调的模型 f1=0.8557 的性能表现非常接近,SetFit 这种极少样本高效微调方案有时可以考虑的。
实际生成的 1280 个文本对的数据可以用下面的代码查看
1x_train, y_train = trainer.dataset_to_parameters(trainer.train_dataset)
2pair_dataset, loss = trainer.get_dataset(x_train, y_train, args=trainer.args)
3
4print(len(pair_dataset))
5print(pair_dataset.to_pandas().head())
model = SetFitModel.from_pretrained() 未明确定义分类头时,系统默认采用逻辑回归模型,可用 model.model_head, model.model_body
来查看分类头和嵌入模型的结构. model.model_body 中没看到 classifier, model 也没有 named_parameters 属性。
model.model_head 看到的是一个 LogisticRegression.
如果 SetFitModel.from_pretrained() 部分代码改成
1model = SetFitModel.from_pretrained(
2 "sentence-transformers/all-mpnet-base-v2",
3 use_differentiable_head=True,
4 head_params={"out_features": 2}
5)
model.model_head 看到的是
SetFitHead({'in_features': 768, 'out_features': 2, 'temperature': 1.0, 'bias': True, 'device': 'cuda'})
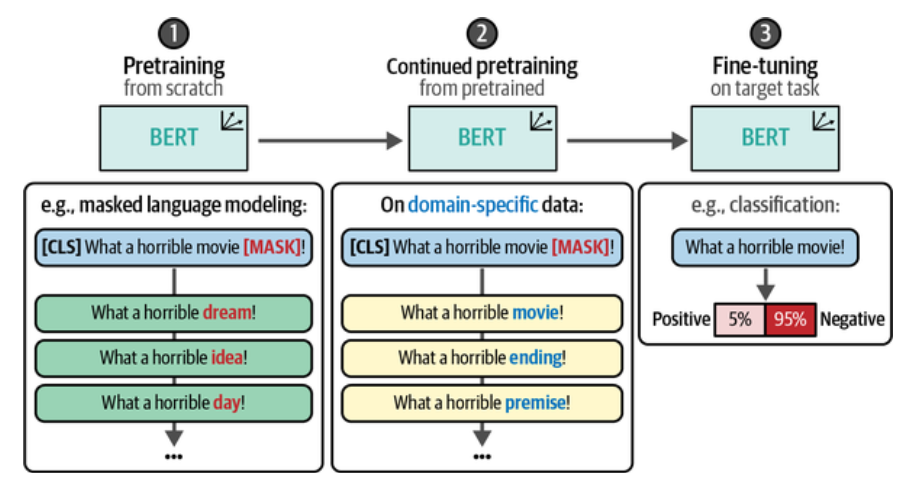
基于掩码语言建模(MLM: Masked Language Modeling) 的再预训练
预训练的模型基于非常通用的数据进行的训练,在微调之前再次用特定领域的数据实施掩码语言建模继续预训练,可以让模型更好地适应特定领域的语言特征和术语, 从而提升微调后的性能表现。
1from datasets import load_dataset
2from transformers import AutoTokenizer, AutoModelForMaskedLM, TrainingArguments, Trainer
3from transformers import DataCollatorForLanguageModeling
4
5tomatoes = load_dataset("cornell-movie-review-data/rotten_tomatoes")
6train_data, test_data = tomatoes["train"], tomatoes["test"] # 各 8530, 1066 条数据
7
8model_id = "bert-base-uncased"
9
10# 加载掩码语言建模(MLM) 模型
11model = AutoModelForMaskedLM.from_pretrained(model_id)
12tokenizer = AutoTokenizer.from_pretrained(model_id)
13
14def preprocess_function(examples):
15 return tokenizer(examples["text"], truncation=True)
16
17# 对数据进行分词处理,并且移除标签
18tokenized_train = train_data.map(preprocess_function, batched=True).remove_columns("label")
19tokenized_test = test_data.map(preprocess_function, batched=True).remove_columns("label")
20
21# 使用 Token 为单位的掩码操作,遮住 15% 的 Token,来训练模型预测被遮住的 Token,用特殊的 [MASK] Token 来遮盖被遮住的 Token
22# 也可以采用 DataCollatorForWholeWordMask 遮盖单词,让训练模型预测被遮盖的单词
23# 预测单词比预测 Token 更难,因为模型的处理单位是 Token, 一个单词可能由多个 Token 组成
24data_collator = DataCollatorForLanguageModeling(
25 tokenizer=tokenizer,
26 mlm=True,
27 mlm_probability=0.15,
28)
29
30# 后面的训练过程就和前面的一样了
31training_args = TrainingArguments(
32 "mlm_continued_pretraining_model",
33 learning_rate=2e-5,
34 per_device_train_batch_size=16,
35 per_device_eval_batch_size=16,
36 num_train_epochs=10,
37 weight_decay=0.01,
38 save_strategy="epoch",
39 report_to="none"
40)
41
42trainer = Trainer(
43 model=model,
44 args=training_args,
45 train_dataset=tokenized_train,
46 eval_dataset=tokenized_test,
47 data_collator=data_collator
48)
49
50# 保存 Tokenizer
51tokenizer.save_pretrained("mlm_continued_pretraining_model")
52
53trainer.train()
54
55trainer.save_model()
训练完后测试对比基础模型与经过 MLM 再预训练的模型预测遮盖词的能力
1from transformers import pipeline
2
3def predict_mask(model_id):
4 mask_filter = pipeline("fill-mask", model=model_id)
5 preds = mask_filter("What a horrible [MASK]!")
6 print(f"Predictions for {model_id}:")
7 for pred in preds:
8 print(f">>> {pred['sequence']}")
9
10predict_mask("bert-base-cased")
11print("*" * 50)
12predict_mask("mlm_continued_pretraining_model")
输出结果为
1Predictions for bert-base-cased:
2>>> What a horrible idea!
3>>> What a horrible dream!
4>>> What a horrible thing!
5>>> What a horrible day!
6>>> What a horrible thought!
7**************************************************
8Predictions for mlm_continued_pretraining_model:
9>>> what a horrible movie!
10>>> what a horrible film!
11>>> what a horrible thing!
12>>> what a horrible mess!
13>>> what a horrible idea!
显然经过用电影评论的数据集再预训练后,更倾向于预测与电影相关的词汇,如 movie, film, mess, idea 等,而基础模型预测的是一些通用的词汇,如 idea, dream, thing, day, thought 等,也是更会说行话了,如果拿一堆脏话来预训练就学会骂人了。
在通过领域特定数据进行再预训练后, 就可继续用训练集进一步微调,加载上面生成的模型,微调的过程与前面完全一样了
1from transformers import AutoModelForSequenceClassification, AutoTokenizer
2
3model = AutoModelForSequenceClassification.from_pretrained("mlm_continued_pretraining_model", num_labels=2)
4tokenizer = AutoTokenizer.from_pretrained("mlm_continued_pretraining_model") # 前面预训练时保存了 tokenizer
命名实体识别(Named Entity Recognition, NER)
命名实体识别的用意是识别文本中具有特定意义的实体,如人名、地名、组织机构等,比如用于处理敏感数据,与文本分类任务有点类似,只是粒度不一样,NER 处理的是单词级别,而不是整个文本。
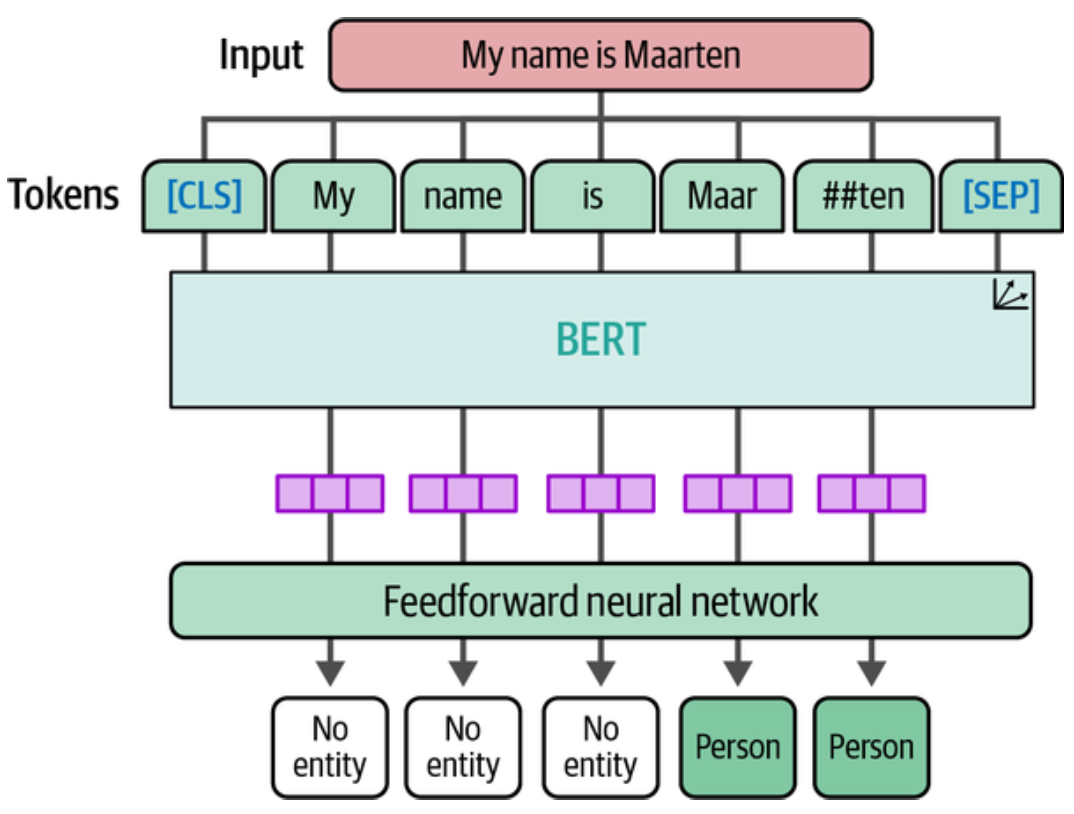
如上图所示,NER 需要判定文本中的 Token 是否含有实体信息,这有点类似从图片中识别出人脸一样。
数据准备
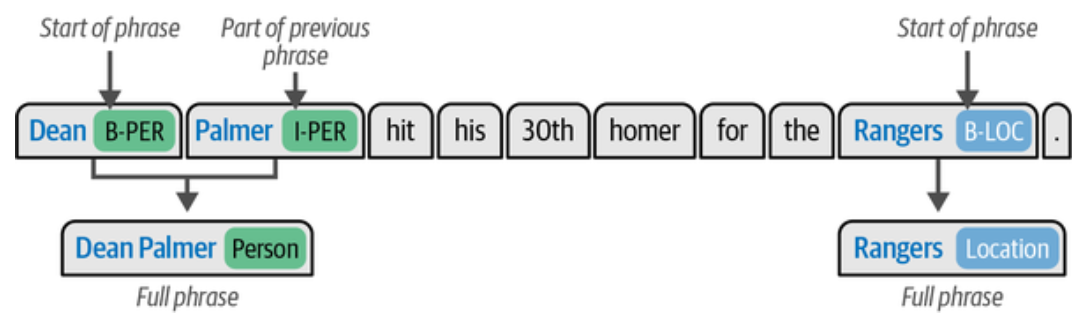
采用英文版的 CoNLL-2003 数据集,该数据集包含了四类实体:人名(PER),地名(LOC),组织机构(ORG)和杂项(MISC), 每个实体都被标注为一个特定的标签,分别如下
- 0: 非实体
- 1: B-PER: 人名实体的开始
- 2: I-PER: 人名实体的内部
- 3: B-ORG: 组织机构实体的开始
- 4: I-ORG: 组织机构实体的内部
- 5: B-LOC: 地名实体的开始
- 6: I-LOC: 地名实体的内部
- 7: B-MISC: 杂项实体的开始
- 8: I-MISC: 杂项实体的内部
1from datasets import load_dataset
2
3dataset = load_dataset("lhoestq/conll2003")
4dataset["train"][848]
新版的 datasets.load_dataset() 需要加上 namespace(如这里的 lhoestq), 而且不能用 trust_remote_code=True 从远加载数据集了。
下面通过 dataset["train"][848] 的输出来理解它的数据是如何表示的
1{'id': '848',
2 'tokens': ['Dean', 'Palmer', 'hit', 'his', '30th', 'homer', 'for', 'the', 'Rangers', '.'],
3 'pos_tags': [22, 22, 38, 29, 16, 21, 15, 12, 23, 7],
4 'chunk_tags': [11, 12, 21, 11, 12, 12, 13, 11, 12, 0],
5 'ner_tags': [1, 2, 0, 0, 0, 0, 0, 0, 3, 0]}
ner_tags 就是对应 tokens 中每个单词的实体标签.
分词
1from transformers import AutoModelForTokenClassification, AutoTokenizer
2
3label2id = {
4 "O": 0, "B-PER": 1, "I-PER": 2, "B-ORG": 3, "I-ORG": 4,
5 "B-LOC": 5, "I-LOC": 6, "B-MISC": 7, "I-MISC": 8
6}
7id2label = {index: label for label, index in label2id.items()}
8
9model_id = "bert-base-cased"
10tokenizer = AutoTokenizer.from_pretrained(model_id)
11model = AutoModelForTokenClassification.from_pretrained(
12 model_id,
13 num_labels=len(label2id),
14 id2label=id2label,
15 label2id=label2id
16)
17
18tokens = tokenizer.encode("My name is Maarten")
19print(tokenizer.convert_ids_to_tokens(tokens))
输出为
1['[CLS]', 'My', 'name', 'is', 'Ma', '##arte', '##n', '[SEP]']
注意,标记的数据是基于完整单词而非子词 Token 构建的,这里的单词 Maarten 被折成了三个 Token, Ma, ##arte, 和 ##n,
所以我们需要在分词过程中将原始标签与对应的子词 Token 对齐。比如说对于这三个 Token,对齐后的标签应该是
Ma: B-PER, ##arte: I-PER, ##n: I-PER
下面是标签的对齐过程,不作详细说明了
1def align_labels(examples):
2 token_ids = tokenizer(examples["tokens"], truncation=True, is_split_into_words=True)
3 labels = examples["ner_tags"]
4 updated_labels = []
5 for index, label in enumerate(labels):
6
7 # 将词元映射到它们各自的单词
8 word_ids = token_ids.word_ids(batch_index=index)
9 previous_word_idx = None
10 label_ids = []
11
12 for word_idx in word_ids:
13 # 新单词的开始
14 if word_idx != previous_word_idx:
15 previous_word_idx = word_idx
16 updated_label = -100 if word_idx is None else label[word_idx]
17 label_ids.append(updated_label)
18 # 将特殊词元标记为-100
19 elif word_idx is None:
20 label_ids.append(-100)
21 # 如果标签是B-XXX,我们将其改为I-XXX
22 else:
23 updated_label = label[word_idx]
24 if updated_label % 2 == 1:
25 updated_label += 1
26 label_ids.append(updated_label)
27
28 updated_labels.append(label_ids)
29 token_ids["labels"] = updated_labels
30 return token_ids
31
32tokenized = dataset.map(align_labels, batched=True)
下面是评估指标和命名实体识别的微调代码
1import evaluate
2import numpy as np
3from transformers import DataCollatorForTokenClassification, TrainingArguments, Trainer
4
5# Load sequential evaluation
6seqeval = evaluate.load("seqeval") # 需安装依赖 'pip install seqeval'
7
8def compute_metrics(eval_pred):
9 # Create predictions
10 logits, labels = eval_pred
11 predictions = np.argmax(logits, axis=2)
12
13 true_predictions = []
14 true_labels = []
15
16 # Document-level iteration
17 for prediction, label in zip(predictions, labels):
18
19 # token-level iteration
20 for token_prediction, token_label in zip(prediction, label):
21
22 # We ignore special tokens
23 if token_label != -100:
24 true_predictions.append([id2label[token_prediction]])
25 true_labels.append([id2label[token_label]])
26
27 results = seqeval.compute(predictions=true_predictions, references=true_labels)
28 return {"f1": results["overall_f1"]}
29
30data_collator = DataCollatorForTokenClassification(tokenizer=tokenizer)
31
32# Training arguments for parameter tuning
33training_args = TrainingArguments(
34 "ner_model",
35 learning_rate=2e-5,
36 per_device_train_batch_size=16,
37 per_device_eval_batch_size=16,
38 num_train_epochs=1,
39 weight_decay=0.01,
40 save_strategy="epoch",
41 report_to="none"
42)
43
44# Initialize Trainer
45trainer = Trainer(
46 model=model,
47 args=training_args,
48 train_dataset=tokenized["train"],
49 eval_dataset=tokenized["test"],
50 data_collator=data_collator,
51 compute_metrics=compute_metrics,
52)
53trainer.train()
54trainer.save_model()
对于 NER 任务快速过一下代码,并不想花太多时间在它上面,感觉不会有太大的用处。
训练完后 ner_model 的大小为 412MB, 评估 trainer.evaluate() 的输出为
| Training Loss | Validation Loss | Step | F1 |
|---|---|---|---|
| 0.233101 | 0.146051 | 878 | 0.8989684 |
1{'eval_loss': 0.14605116844177246, 'eval_f1': 0.8989684177114744}
用一下训练好的模型来检验它的效果如何
1from transformers import pipeline
2
3token_classifier = pipeline ("token-classification", model="ner_model")
4entities = token_classifier("My name is Marten and I live in Amsterdam, working for a company called Microsoft. Who is Michael Jackson?")
5print(entities)
输出为
1[{'entity': 'B-PER', 'score': np.float32(0.9946502), 'index': 4, 'word': 'Mart', 'start': 11, 'end': 15},
2{'entity': 'I-PER', 'score': np.float32(0.9913817), 'index': 5, 'word': '##en', 'start': 15, 'end': 17},
3{'entity': 'B-LOC', 'score': np.float32(0.9963955), 'index': 10, 'word': 'Amsterdam', 'start': 32, 'end': 41},
4{'entity': 'B-ORG', 'score': np.float32(0.9753651), 'index': 17, 'word': 'Microsoft', 'start': 72, 'end': 81},
5{'entity': 'B-PER', 'score': np.float32(0.9554849), 'index': 21, 'word': 'Michael', 'start': 90, 'end': 97},
6{'entity': 'I-PER', 'score': np.float32(0.8640685), 'index': 22, 'word': 'Jackson', 'start': 98, 'end': 105}]
模型成功识别出了人名 Marten 和 Michael Jackson, 地名 Amsterdam, 以及组织机构 Microsoft, 说明模型微调达到预期的目的。
小结
我们学习了在特定任务上微调预训练表示模型的若干方法,知道如何进行全量微调,或冻结某些层进行部分参数的微调。使用 SetFit 少样本分类技术, 了解了如何通过少量标注数据生成大量训练数据来微调模型。学习了使用掩码语言建模(MLM) 进行再预训练来提升模型在特定领域的适应能力。 最后还实践了命名实体识别(NER) 任务,了解了如何准备数据、对齐标签,并实际测试了训练出模型的能力。
永久链接 https://yanbin.blog/hands-on-large-language-models-reading-notes-11/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。