《Hands-On Large Language Models》阅读笔记(十三)
这应该是阅读本书的最后一篇笔记了,下一本书的目标是《Build a Large Language Model (From Scratch)》。大模型的三步走,预训练、微调、和偏好调优。 本篇的来了解最后一步偏好调优, 对齐(Preference-Tuning / Alignment RLHF), RLHF 是一个像那些 RoPE, LoRA, MoE, SFT 等经常见得着但不知道意义的高级词。 RLHF(Reinforcement Learning from Human Feedback): 用人类的偏好判断来训练一个"打分模型",再用强化学习让语言模型朝高分方向优化。
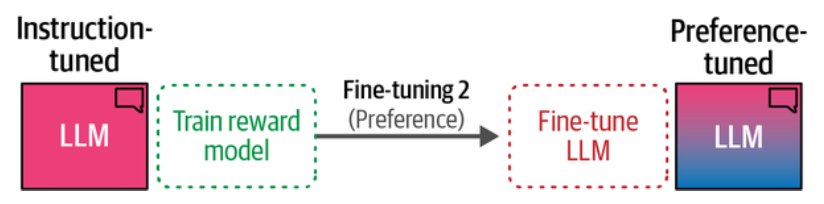
模型经过指令微调后更听话了,我们还要最后的训练来进一步改进其行为,使用与我们期望它在不同场景中的表现保持一致。做法就是让一个偏好评估者(人或其他方式) 评估模型生成内容的质量
- 如果分数较高,更新模型,以鼓励它产生更多这类生成内容
- 如果分数较低,更新模型,以抑制它产生这类内容
我们可以训练一个叫作奖励模型(reward model) 的模型来实现偏好评估自动化,是要在偏好调优步骤之前增加一个步骤,即训练一个奖励模型
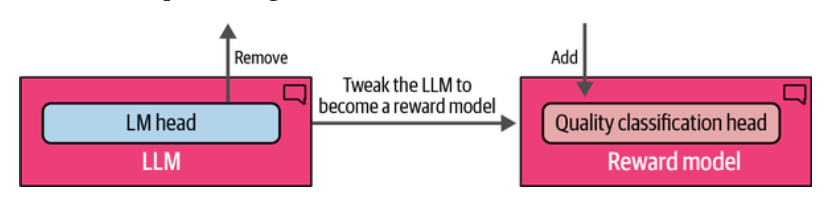
经过指令微调的模型,去掉建模头(LM Head), 加上质量分类头(Quality classification head), 让该分类头只输入单一的分数。如果观察前一篇微调出来的模型
TinyLlama-1.1B-sft 它最后有一个 lm_head 层。
奖励模型预期的工作方式是,给它一个提示词和生成内容对,它会输入一个单一的数值分数,表示该生成内容对于该提示词的偏好/质量。训练奖励模型需要一个偏好数据集。 所以偏好训练的数据集的一条记录可表示为一个元组
(提示词,被接受的生成内容,被拒绝的生成内容, 偏好标签(接受内容评分, 拒绝内容评分))
生成偏好数据的一种方法是向 LLM 提供一个提示词,让它生成两个不同的结果,然后人工标哪个可接受,另一个应拒绝,也就是偏好于哪一个结果。奖励模型的训练步骤是
- 用奖励模型对被接受的生成内容评分
- 用奖励模型对被拒绝的生成内容评分
训练目标是确保对被接受的内容的评分高于被拒绝生成内容的得分。
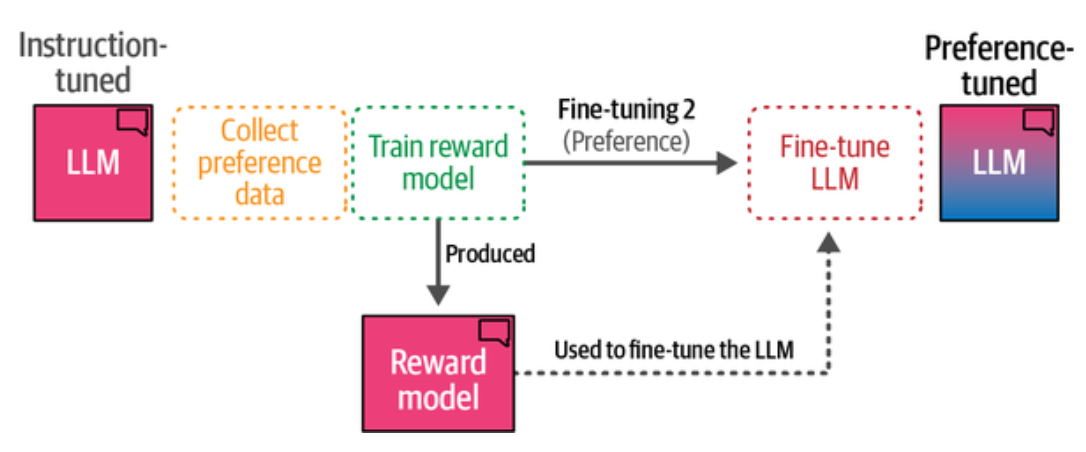
由此我们得到偏好调优的三个步骤
- 收集偏好数据
- 训练奖励模型
- 微调 LLM (奖励模型作为偏好评估器)
奖励模型的想法可以扩展到其他领域,例如对有用性(helpfulness) 评分,或对安全性(safety) 评分。
使用训练好的奖励模型来微调 LLM 的一种常用方法是近端策略优化(Proximal Policy Optimization, PPO). PPO 是一种流行的强化学习技术,通过确保 LLM 不会过度偏离预期奖励来优化经过指令微调的 LLM.
PPO 的一个缺点是至少需要训练两个模型--奖励模型和 LLM,这导致它的成本可能比实际所需的成本高。PPO 的一个替代方案是直接偏好优化(Direct Preference Optimization, DPO). DPO 不使用奖励模型来评判生成内容的质量,而是让 LLM 自己来完成这项工作。也就是将 LLM 自身作为奖励模型。
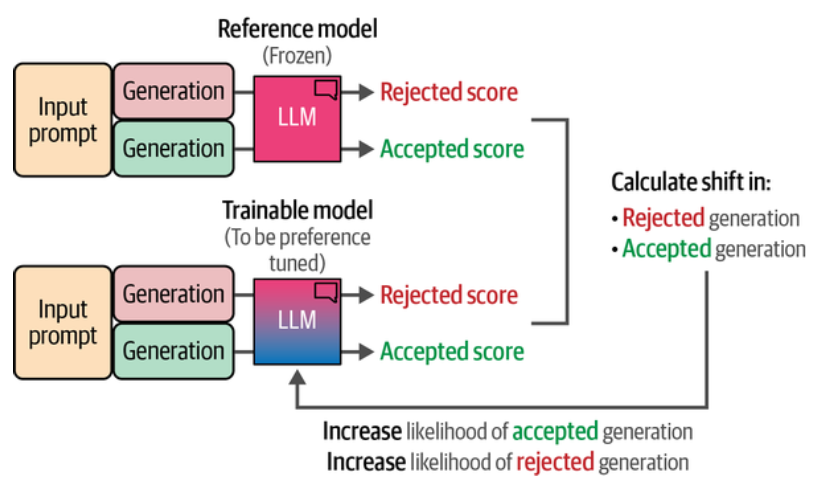
左边是通过奖励模型作为偏好评估器进行偏好调优,右边是不使用单独训练的奖励模型,而是用 LLM 的一个副本。在训练过程中,我们需从两个模型中提取生成内容 Token 级别的对数概率,并计算偏移,通过跟踪参考模型和可训练模型之间的差异来优化被接受的生成内容相对于被拒绝的生成内容的似然概率.
我们可以使用这些分数优化可训练模型的参数,使其在生成被接受的内容时更有信心,在生成被拒绝的内容时更缺乏信心。与 PPO 相比,DPO 在训练过程中更加稳定, 准确度也更高
使用 DPO 进行偏好调优
上一篇中经过第一次的指令微调后的模型目录为 TinyLlama-1.1B-sft,这一次我们要基于它进行 DPO 偏好调优,先来了解一下用来微调偏好的数据集。
1from datasets import load_dataset
2dpo_dataset = load_dataset("argilla/distilabel-intel-orca-dpo-pairs")
3print(dpo_dataset)
4dpo_dataset["train"].to_pandas()
1DatasetDict({
2 train: Dataset({
3 features: ['system', 'input', 'chosen', 'rejected', 'generations', 'order', 'labelling_model', 'labelling_prompt', 'raw_labelling_response', 'rating', 'rationale', 'status', 'original_chosen', 'original_rejected', 'chosen_score', 'in_gsm8k_train'],
4 num_rows: 12859
5 })
6})其中的数据通过调用 gpt-4-1106-preview 模型来生成的,输入 input, 有两个输出,chosen 和 rejected, rating 中分别是它们对应的分数,
如 [9.0, 8.0], chosen_score 选择了高分项作为偏好。
下面是基于上一篇进行了指令优化的 TinyLlama-1.1B-sft 模型,使用 DPO 进行偏好调优,生成的模型目录为 TinyLlama-1.1B-dpo。
以下是完整代码,在代码中加入详细的注释,主要过程是转换测试数据格式,因为上回保存模型时存回了 float32 格式,为节约显存,加载后又要再次进行 4
位量化,整个训练过程与进行 QLoRA 十分类似。
1from peft import LoraConfig, prepare_model_for_kbit_training, get_peft_model, PeftModel
2from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
3from trl import DPOConfig, DPOTrainer
4
5def format_prompt(example):
6 """使用TinyLlama的<|user|>模板格式化提示词"""
7
8 # 格式化答案
9 system = "<|system|>\n" + example["system"] + "</s>\n"
10 prompt = "<|user|>\n" + example["input"] + "</s>\n<|assistant|>\n"
11 chosen = example["chosen"] + "</s>\n"
12 rejected = example["rejected"] + "</s>\n"
13 return {
14 "prompt": system + prompt,
15 "chosen": chosen,
16 "rejected": rejected,
17 }
18
19# 格式化数据集并选择相对简短的答案
20dpo_dataset = load_dataset(
21 "argilla/distilabel-intel-orca-dpo-pairs", split="train"
22)
23dpo_dataset = dpo_dataset.filter(
24 lambda r:
25 r["status"] != "tie" and
26 r["chosen_score"] >= 8 and
27 not r["in_gsm8k_train"]
28)
29dpo_dataset = dpo_dataset.map(
30 format_prompt, remove_columns=dpo_dataset.column_names
31)
32
33model_name = "TinyLlama-1.1B-sft"
34
35# 4 位量化配置 -- QLoRA 中的 Q
36bnb_config = BitsAndBytesConfig(
37 load_in_4bit=True, # 用 4 位精度加载模型
38 bnb_4bit_quant_type="nf4", # 量化类型
39 bnb_4bit_compute_dtype="bfloat16", # 计算数据类型
40 bnb_4bit_use_double_quant=True # 应用嵌套量化
41)
42
43# 在 GPU 上加载要训练的模型,如果 GPU 支持, device_map="auto" 会加载到 GPU
44model = AutoModelForCausalLM.from_pretrained(
45 model_name,
46 device_map="auto",
47
48 # 普通 SFT 可以忽略此设置
49 quantization_config=bnb_config,
50)
51
52model.config.use_cache = False
53model.config.pretraining_tp = 1
54
55# 加载 Llama 分词器
56tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
57tokenizer.pad_token = tokenizer.eos_token
58tokenizer.padding_side = "left"
59
60peft_config = LoraConfig(
61 lora_alpha=32, # LoRA 缩放
62 lora_dropout=0.1, # LoRA 层的 dropout
63 r=64, # Rank
64 bias="none",
65 task_type="CAUSAL_LM",
66 target_modules = ["k_proj", "gate_proj", "v_proj", "up_proj", "q_proj", "o_proj", "down_proj"] # 目标层
67)
68
69# 准备用于训练的模型
70model = prepare_model_for_kbit_training(model) # model 是前面用 4 位量化后的模型
71model = get_peft_model(model, peft_config)
72
73training_arguments = DPOConfig(
74 output_dir="./checkpoints",
75 per_device_train_batch_size=2,
76 gradient_accumulation_steps=4,
77 optim="paged_adamw_32bit",
78 learning_rate=1e-5,
79 lr_scheduler_type="cosine",
80 logging_steps=10,
81 bf16=True,
82 beta=0.1,
83 max_length=512,
84 gradient_checkpointing=True,
85 warmup_steps=0.1
86)
87
88dpo_trainer = DPOTrainer(
89 model,
90 train_dataset=dpo_dataset,
91 args=training_arguments,
92 processing_class=tokenizer,
93)
94
95dpo_trainer.train()
96
97# 保存适配器, TinyLlama-1.1B-dpo-qlora/adapter_config.json 中记录了 base_model
98# "base_model_name_or_path": "TinyLlama-1.1B-sft"
99dpo_trainer.model.save_pretrained("TinyLlama-1.1B-dpo-qlora")
100
101sft_model = AutoModelForCausalLM.from_pretrained(model_name)
102
103# 合并DPO 和SFT模型
104dpo_model = PeftModel.from_pretrained(
105 sft_model,
106 "TinyLlama-1.1B-dpo-qlora",
107 device_map="auto",
108)
109dpo_model = dpo_model.merge_and_unload()
110dpo_model.save_pretrained("TinyLlama-1.1B-dpo")
111tokenizer.save_pretrained("TinyLlama-1.1B-dpo")
目录 TinyLlama-1.1B-dpo-qlora 中的数据也是量化后取 Rank=64 时的部分参数,所以它的大小只有 97M
1ls -lh TinyLlama-1.1B-dpo-qlora
2total 97M
3-rw-rw-r-- 1 yanbin yanbin 5.1K Jun 1 20:09 README.md
4-rw-rw-r-- 1 yanbin yanbin 1.1K Jun 1 20:09 adapter_config.json
5-rw-rw-r-- 1 yanbin yanbin 97M Jun 1 20:09 adapter_model.safetensors
6drwxrwxr-x 2 yanbin yanbin 4.0K Jun 1 20:09 ref
在其中有个 adapter_config.json 文件,其中的 "base_model_name_or_path": "TinyLlama-1.1B-sft",, 所以可直接加载它合并到基础模型中
1from peft import AutoPeftModelForCausalLM
2
3dpo_model = AutoPeftModelForCausalLM.from_pretrained(
4 "TinyLlama-1.1B-dpo-qlora",
5 low_cpu_mem_usage=True,
6 device_map="auto"
7)
8dpo_model = dpo_model.merge_and_unload()
9dpo_model.save_pretrained("TinyLlama-1.1B-dpo")
SFT 和 DPO 相结合是一个很好的方法,可以对模型进行微调以实现基本对话功能,然后根据人类偏好来调整其回答,但是要进行两轮训练。自 DPO 发布以来, 新的偏好对齐方法也不断出现,如 ORPO(Odds Ratio Preference Optimization), 它将 SFT 和 DPO 合并为一个训练过程。
本章小结
本章认识了训练生成式 LLM 的三步骤,预训练,指令微调,偏好调优。指令微调时使用适配器的一种方案 LoRA 技术实现了参数高效微调(PEFT). 指令微调让 LLM 能对话,偏好调优(数据对齐) 进一步改进模型,让答案更受欢迎。
永久链接 https://yanbin.blog/hands-on-large-language-models-reading-notes-13/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。