《Hands-On Large Language Models》阅读笔记(二)
第三章:LLM 的内部机制
这一章才是本书的最重要的部分,一个支撑现在大语言模型的基石,那就是 Transformer 模型, 占据了本书约 12% 的篇幅。学完分词与词嵌入后,现在开始探究
Transformer 模型的工作原理。我们把 Transformer LLM 看成是一个接收文本输入并生成响应的系统, 模型总是在预测下一个 Token, 每个 Token
的生成都是模型的一次前向传播(forward pass). 在生成当前 Token 后,会将该生成的 Token 追加到输入序列中,作为下一次预测的输入(
或者说调整下次生成的提示词), 如此循环往复,逐个生成 Token,直到完成整段响应——这种机制称为自回归(autoregressive) 生成。
这种使用生成的前一个 Token 又作为输入来生成下一个 Token 的模型被称为自回归模型(autoregressive model)。而 BERT 是双向(Bidirectional)编码模型。
前向传播的组成, 分词器后就是由 Transformer 堆叠而成的神经网络,最后是一个 LM head, 它负责将 Transformer 块的输出转换为 Token 的概率分数。
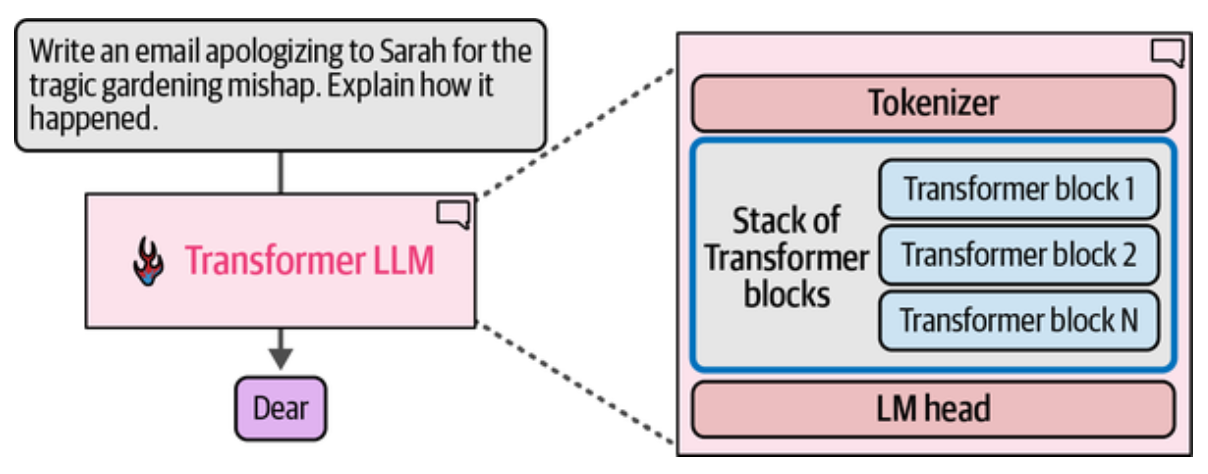
LLM 根据提示词生成第一个 token 的过程被称为预填充(Prefill) 阶段,后续 Token 生成是自回归解码阶段。
Prefill 阶段,模型一次性接收完整提示词,分词,嵌入向量,再经过 N 层 Transformer 做全量 Self-Attention 计算--所有 token 之间两两相互关注, 来理解整个上下文语义,这部分是并行。这个阶段最重要的副产品是 KV Cache. 最终,最后一个 Token 的隐藏状态被送到 LM head, 输出词汇表上所有 token 的概率分数,采样出第一个 token. 这一阶段的耗时决定了 TTFT(Time To First Token).
Decode (解码) 是自回归生成后续 Token 的阶段。新生成的 Token 放到 Prompt 序列后,组成新的序列,再经过上面的类似的步骤,不过因为已处理的 Token 只需读取 KV Cache, 所以相当是只处理新生成的那一个 Token,计算量大大降低,再到达 LM Head 得到词汇上所有 token 的概率分数, 采样出下一个 token. 这一阶段的耗时决定了 TPOT(Time Per Output Token).
下面是一个更简单的文本生成的 pipeline 示例
1import transformers
2from transformers import pipeline
3
4transformers.logging.set_verbosity_error()
5
6pipe = pipeline(
7 "text-generation",
8 model="microsoft/Phi-3-mini-4k-instruct",
9 device_map="mps",
10 torch_dtype="auto",
11 max_new_tokens=100,
12)
13
14messages = [{
15 "role": "user",
16 "content": "Write an email apologizing to Sarah for the tragic gardening mishap. Explain how it happened."
17}]
18
19output = pipe(messages)
20print(output[0]["generated_text"][-1]["content"])
LM head 也是一个简单的神经网络层,我们打印一下 model 就可以按顺序显示所有层
1from transformers import AutoModelForCausalLM
2
3model = AutoModelForCausalLM.from_pretrained(
4 "microsoft/Phi-3-mini-4k-instruct",
5 device_map="mps",
6 torch_dtype="auto",
7)
8
9print(model)
对于这个模型得到的是
1Phi3ForCausalLM(
2 (model): Phi3Model(
3 (embed_tokens): Embedding(32064, 3072, padding_idx=32000)
4 (layers): ModuleList(
5 (0-31): 32 x Phi3DecoderLayer(
6 (self_attn): Phi3Attention(
7 (o_proj): Linear(in_features=3072, out_features=3072, bias=False)
8 (qkv_proj): Linear(in_features=3072, out_features=9216, bias=False)
9 )
10 (mlp): Phi3MLP(
11 (gate_up_proj): Linear(in_features=3072, out_features=16384, bias=False)
12 (down_proj): Linear(in_features=8192, out_features=3072, bias=False)
13 (activation_fn): SiLUActivation()
14 )
15 (input_layernorm): Phi3RMSNorm((3072,), eps=1e-05)
16 (post_attention_layernorm): Phi3RMSNorm((3072,), eps=1e-05)
17 (resid_attn_dropout): Dropout(p=0.0, inplace=False)
18 (resid_mlp_dropout): Dropout(p=0.0, inplace=False)
19 )
20 )
21 (norm): Phi3RMSNorm((3072,), eps=1e-05)
22 (rotary_emb): Phi3RotaryEmbedding()
23 )
24 (lm_head): Linear(in_features=3072, out_features=32064, bias=False)
25)
- 最外层是
model和lm_head model内部是embed_tokens(词汇表大小 32064, 向量维度 3072), 和layers.layers是一个堆叠的 Transformer 解码器层,由 32 个Phi3DecoderLayer类型的块组成- 每一个 Transformer 块包含一个注意力层(self_attn) 和一个前馈神经网络层(mlp-multilayer perceptron(多层感知器))
- 最后
lm_head收到一个大小为 3072 的向量,并输出一个大小等于模型词汇表大小的向量(32064),即每个元素对应一个 Token Embedding 的概率分数。
输入进行分词,嵌入向量,计算词汇表中每个 Token 的概率分数,解码策略选择一个输出 Token, 可选择分数最高的,或引入随机性选择第二高或第三高的
Token, 选择分数最高的还往往无法产生最佳输出。每次选择概率最高的 Token 叫做贪婪解码(greedy decoding), 对应于 Temperature=0, 这种方式缺乏创意.
下面过程演示如何输出第一个 Token
1tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
2
3prompt = "The capital of France is"
4
5input_ids = tokenizer(prompt, return_tensors="pt").input_ids
6input_ids = input_ids.to(model.device) # move to GPU
7model_output = model.model(input_ids)
8
9lm_head_output = model.lm_head(model_output[0]) # 由 LM head 得到词表中每个 Token 的概率分数, 它的 shape 是 [1, 5, 32064]
10token_id = lm_head_output[0, -1].argmax(-1) # 最后一个 Token 对应词表的概率分数,选择最高的那个 Token
11word = tokenizer.decode(token_id)
12print(word)
Paris
流处理与 KV Cache
下面这两张图很好的展示了 Prompt 如何被分词,嵌入,经过 Transformer 块 并行处理,最后一个 Token 到达 LM head 得到整个词表中每个 Token 概率分数,解码策略选择下一个输出 Token; 再把输出 Token 附加到 Prompt 回归处理,又得到下一个 Token, 直至完成输出的全过程。
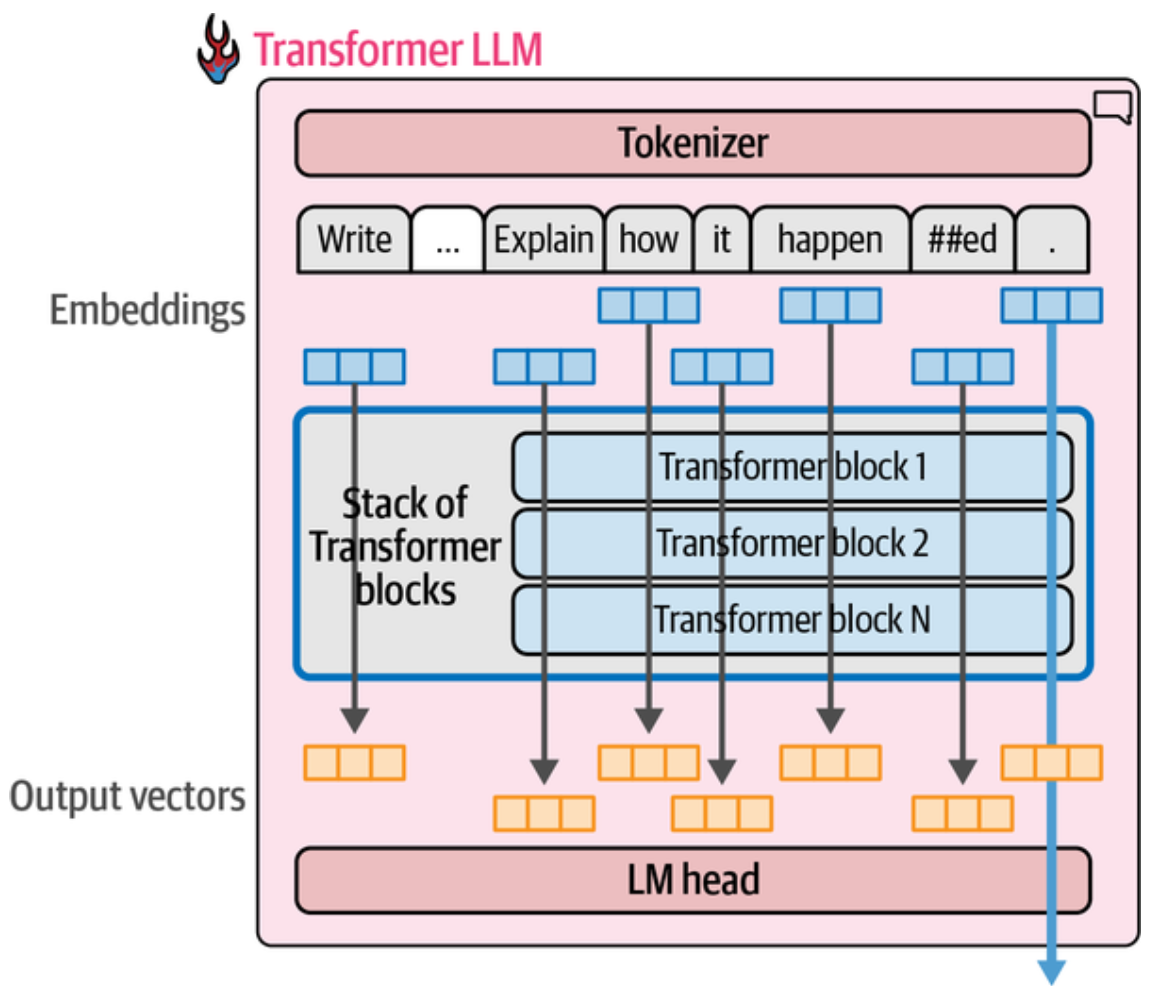
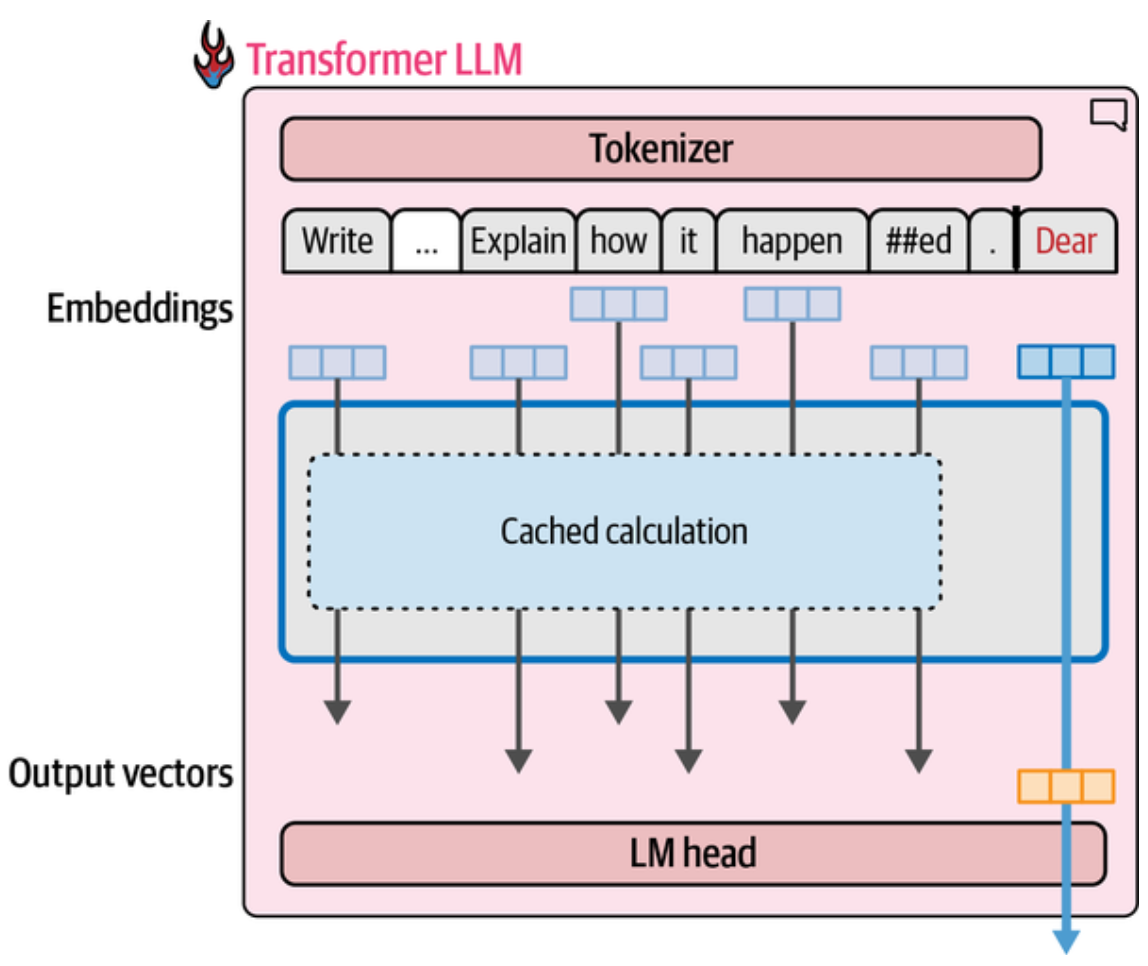
每个 Token 经过 Transformer 块时是并行处理的,我们注意到左图第一次处理 Prompt 时,Self-Attention 计算做了最大的贡献,缓存了 Embedding/Output vector 的缓存,即 KV Cache, 预测出第一个输出 Token(这里的 Dear), 随后该输出 Token 附加到 Prompt, 作同样的处理, 但其他 Token 的计算都可从缓存中获得,实际上像是在只需要为新 Token 预测下一个 Token。因此也能感觉到生成第一个 Token 的艰难, 能进入到 LLM 的 Token 数目就是上下文窗口大小。
测试是否启用 KV Cache 的生成时间差异
1import time
2
3prompt = "Write a very long email apologizing to Sarah for the tragic gardening mishap. Explain how it happened."
4input_ids = tokenizer(prompt, return_tensors="pt").input_ids.to(model.device)
5
6time0 = time.time()
7generation_output = model.generate(
8 input_ids,
9 max_new_tokens=100,
10 use_cache=True, # False
11)
12print(time.time() - time0)
当 use_cache=True 时,耗时约 10 秒,当 use_cache=False 时耗时翻倍到了约 20 秒,生成的 Token 越多差距越大。
Transformer 块的内部结构
Transformer 模型的核心就是那些堆叠的 Transformer 块,原始 Transformer 论文中约为 6 个,现在许多 LLM 中超过 100 个,比如模型
microsoft/Phi-3-mini-4k-instruct 有 32 层,块与块之间首尾相连,是链式处理的。
每一个 Transformer 块又由自注意力层(Self-attention) 和 前馈神经网络层(Feedforward neural network) 两部分组成。
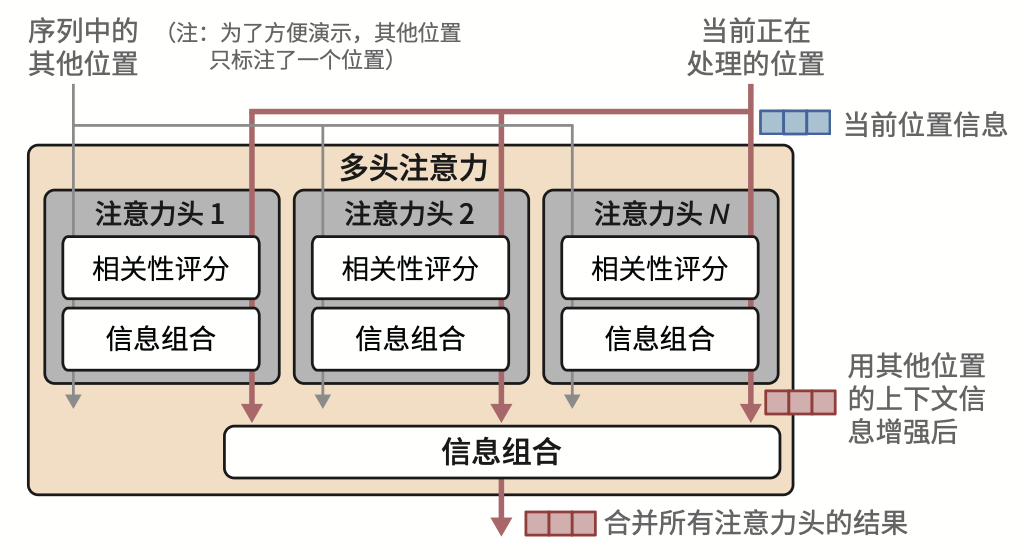
每个注意力(self-attention) 在处理当前 Token 时会与它之前的 Token 进行相关性评分,把这些分数组合成单一的输出向量,为了赋予 Transformer 更强大的注意力能力,注意力机制被复制多分,并行执行。每一个执行就是注意力头(attention head), 并行的注意力头就组成了多头注意力, 多头注意力并行计算出的结果再合并成单一向量。
为什么叫做注意力,就像人在阅读的时候,会回头翻看之前哪些重要与当前位置相关联的信息,模型里的 Attention 机制也是做一样的事情,在处理当前 Token 时也会回头看之前输入的 Token 哪些权重高值得关注,哪里权重低可被忽略。注意力机制的引入使得 Transformer 模型能够捕捉长距离的依赖关系, 理解上下文中的复杂关系。
注意力反映到计算方式那就是 Transformer 的精髓,这就是为什么叫做 "Attention Is All You Need". 下面试着肤浅的理解一下注意力计算方式。
注意力的输入包括当前 Token 的向量嵌入与所有前序 Token 的向量嵌入,输出目标是为当前位置生成与前序 Token 相关的一个新的向量嵌入。
模型训练好后,为每一层(Transformer Block)中的每一个注意力头(attention head)产生一套独立的 Wq, Wk, Wv, 即三个投影矩阵,分别是
- 查询投影矩阵(query projection matrix),即 Wq(Weight of Query),表示 "我想找什么"
- 键投影矩阵(key projection matrix), 即 Wk(Weight of Key),表示 "我能提供什么标签"
- 值投影矩阵(value projection matrix), 即 Wv(Weight of Value),表示 "我实际贡献的内容"
以 GPT-3 模型为例,它有 96 层 Transformer 块,每个块中有 96 个注意力头,一共就有 96 * 96 = 9216 套 Wq, Wk, Wv. 多头注意力的每个注意力进行的是同样的计算,只是使用各自的投影矩阵 Wq, Wk, 和 Wv.
一个注意力的计算过程就是以当前 Token 与前序 Token 的向量嵌入作为输入,与当前注意力头的三个投影矩阵 Wq, Wk, Wv 进行运算得到当前 Token 与前序 Token 的相关性评分,再归一成单一向量。下面是一个 Attention head 针对当前 Token 的计算得到当前 Token 与前序每个 Token 的相关性评分。
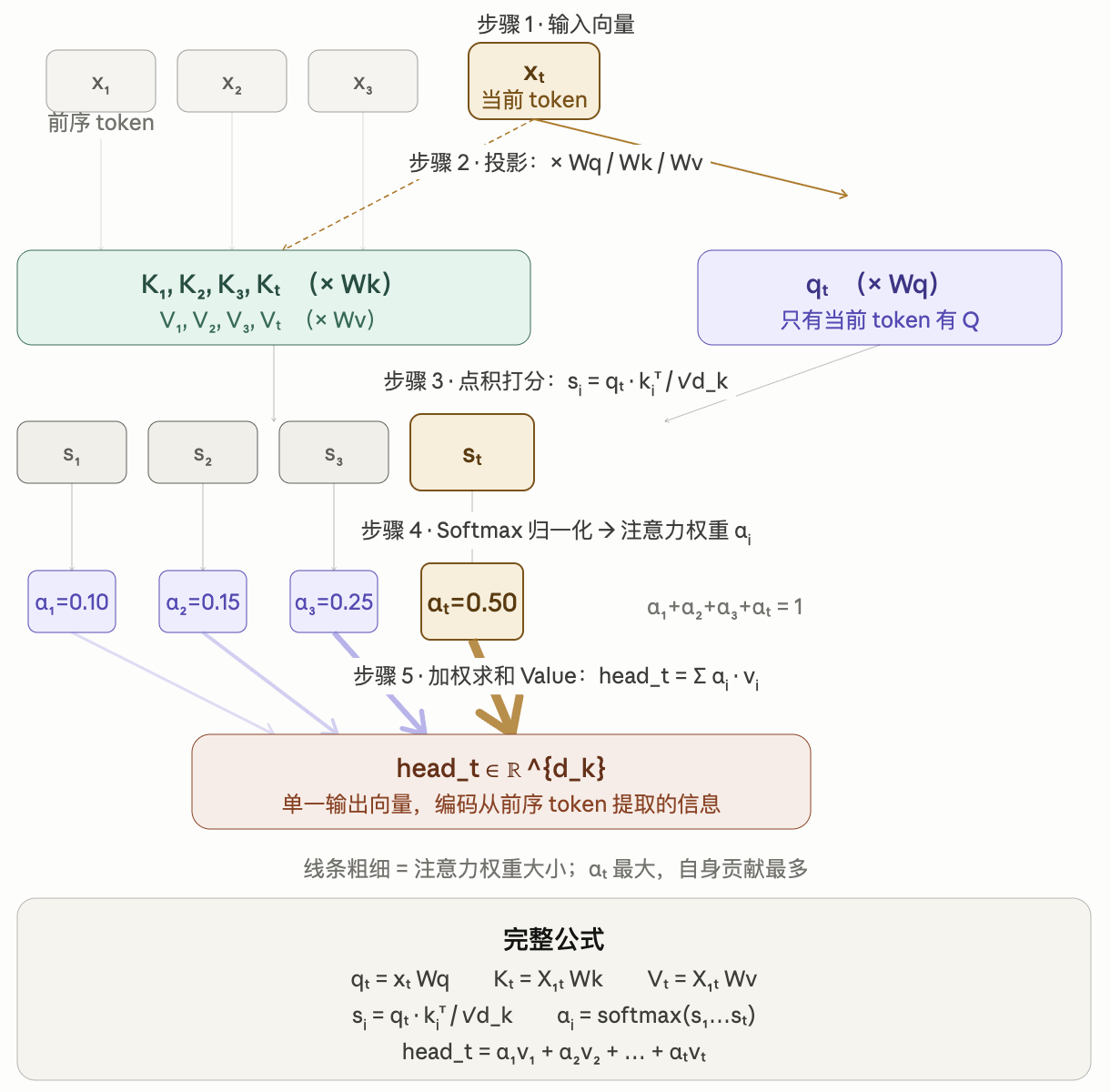
Transformer 架构自发布以来,一直在进行着改进,以提升模型性能和效率,包括用更大的数据集训练,优化训练过程和学习率,及架构本身的调整。比如有稀疏注意力 (Sparse attention, 与之对应的就是全注意力: full-attention) 和滑动窗口注意力。稀疏注意力让模型只看少量的前序 Token, 生成快,但质量会下降, 这就是用空间换时间,GPT-3 会交替使用全注意力与稀疏注意力。Transformer 的自回归特性,只关注前序 Token, 而 BERT 可关注两个方向的 Token.
Llama 2 和 Llama 3 等模型又发展出了分组查询注意力(Grouped-Query Attention) 和多查询注意力(Multi-query attention), 与稀疏注意力一样, 增效方式都是通过减小涉及的矩阵大小来提高大模型推理的可扩展性,多查询注意力在所有注意力头之间共享 Wk 和 Wv 矩阵,保持独立的 Wq 矩阵。 分组查询注意力不是所有的注意力头共享一套 Wk 和 Wv, 但是使用少于注意力头数目的 Wk 和 Wv.
Flash Attention 是一种广受欢迎的方法和实现,可以显著提升 GPU 上 Transformer LLM 的训练和推理速度。它通过优化 GPU 共享内存 (GPU’s shared memory,SRAM)和高带宽内存(high bandwidth memory,HBM)之间的数据加载和迁移来加速注意力计算.
位置嵌入: RoPE(Rotary Position Embedding)
位置嵌入是 Transformer 模型中用于表示 Token 在序列中的嵌入位置信息的一种技术,这对自然语言非常重要, 相同的 Token 通过不同顺序组合可有多种截然不同的意思。 原始 Transformer 用序号来标记 Token 位置,但当模型扩展到更大的规模时就成了挑战。RoPE 不把位置信息编码到 Token 向量中,而是通过旋转 Wq 和 Wk 把位置编码成旋转角度。
小结
Transformer LLM 每次处理提示词时可并发,最后生成一个 Token, 新 Token 回归组成新的提示词再预测后面的 Token, 已处理的 Token 计算有 KV Cache 供后面重用,所以感觉上第一个 Token 很耗时,后面的 Token 更快.
Transformer LLM 有三个核心组件,分词器,堆叠的 Transformer 块,和 LM head
提示词的最后一个 Token 会进入到 LM head, 然后得到模型词汇表中每个 Token 的概率分数,解码策略选择一个输出下一个 Token, 解码策略不同对应不同的 temperature, 新 Token 回归到提示词重复执行相同的过程称为自回归(autoregressive) .
每一个 Transformer 块由自注意力和前馈神经网络两部分组成,自注意力又由多个注意力头组成,每个注意力头有独立的 Wq, Wk, Wv 矩阵,计算当前 Token 与前序 Token 的相关性评分。一般训练出来的模型 Wq, Wk, Wv 矩阵的套数是 Transformer 块数 * 注意力头数. 不同的注意力优化通过共享 Wk, Wv 矩阵或减小注意的前序 Token 数来优化。
永久链接 https://yanbin.blog/hands-on-large-language-models-reading-notes-2/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。