《Hands-On Large Language Models》阅读笔记(三)
第四章:文本分类
文本分类(Text Classification) 是 NLP 中常见的任务之一,如不同语义的分类,动物,植物; 肉类,还是水果,蔬菜,开心还是悲伤,或业务分类等。 表示模型和生成模型在文本分类中的作用不容忽视。
下面是用预训练模型对 Hugging Face 上的电影评论数据集 rotten_tomatoes 进行文本分类的测试。
1from datasets import load_dataset
2data = load_dataset("rotten_tomatoes")
3print(data)
里面包含三部分的数据 train 训练集,validation 验证集,test 测试集。我们将用训练集训练模型,使用测试集来验证结果,
附加的验证集用来验证模型的泛化能力。rotten_tomatoes 中记录有两个字段,分别为
text: 电影评论文本label: 电影评论的标签,0 代表负面评论,1 代表正面评论。
1DatasetDict({
2 train: Dataset({
3 features: ['text', 'label'],
4 num_rows: 8530
5 })
6 validation: Dataset({
7 features: ['text', 'label'],
8 num_rows: 1066
9 })
10 test: Dataset({
11 features: ['text', 'label'],
12 num_rows: 1066
13 })
14})
三个数据集中每个数据集都有一半正面评论,一半负面评论,我们将要做的就是用 rotten_tomatoes 的训练集中打了标签的数据训练,然后用测试集中的评论进行测试,
最后对比测试集中每条评论的 label. 比如我们 data["train"].shuffle() 看到的头几条记录
| text | label | |
|---|---|---|
| 0 | one of the best inside-show-biz yarns ever . | 1 |
| 1 | offers absolutely nothing i hadn't already seen . | 0 |
| 2 | it all adds up to good fun . | 1 |
| n | ... | .. |
使用特定任务模型进行分类
使用预训练表示模型进行分类,通过两种方式:使用特定任务模型, 或使用嵌入模型。这些模型是通过微调基础模型(如 BERT) 而创建。我们在 Hugging Face 成千上万的文本分类模型中我们选择如下两个模型
- 特定任务的模型:
Twitter-roBERTa-base for Sentiment Analysis基础模型,这是一个对 Twitter 数据进行情感分析微调的模型.RoBERTa是BERT的一个变体。 - 嵌入模型:
sentence-transformers/all-mpnet-base-v2
下面是完整的分类代码
1from transformers import pipeline
2from datasets import load_dataset
3import numpy as np
4from tqdm import tqdm
5from transformers.pipelines.pt_utils import KeyDataset
6from sklearn.metrics import classification_report
7
8def evaluate_performance(y_true, y_pred):
9 performance = classification_report(
10 y_true, y_pred,
11 target_names=["Negative Review", "Positive Review"]
12 )
13 print(performance)
14
15data = load_dataset("rotten_tomatoes")
16model_path = "cardiffnlp/twitter-roberta-base-sentiment-latest"
17
18pipe = pipeline(
19 model=model_path,
20 tokenizer=model_path,
21 top_k=None,
22 return_all_scores=True,
23 device_map="mps"
24)
25
26y_pred = []
27classified = pipe(KeyDataset(data["test"], "text")) # 对测试集文本进行分类, 1 或 0
28for output in tqdm(classified, total=len(data["test"])):
29 scores = {item["label"]: item["score"] for item in output}
30 negative_score = scores["negative"]
31 positive_score = scores["positive"]
32 assignment = np.argmax([negative_score, positive_score]) # negative_score >= positive_score -> 0, 反之为 1
33 y_pred.append(assignment)
34
35evaluate_performance(data["test"]["label"], y_pred) # 对测试集文本评出的 1, 0 与测试集 label 对比
这个特定任务的模型 Twitter-roBERTa-base for Sentiment Analysis, 使用 pipeline 之后只输出三个评分,在列中顺序不确定
1[
2 {"label": "negative", "score": 0.1},
3 {"label": "neutral", "score": 0.2},
4 {"label": "positive", "score": 0.7}
5]
该代码与原书有一点差别,书中的代码在 macOS 下运行有问题,因为 output 中的三个元素不总是按 negative, neutral, positive 的顺序排列.
1negative_score = output[0]["score"]
2positive_score = output[2]["score"]
我们对测试集中的文本 KeyDataset(data["test"], "text") 进行分类,正面为 1,负面为 0, 中性的也标为 0,最后把分类的结果与测试集 label 对比,
输出分类报告。
1 precision recall f1-score support
2
3Negative Review 0.76 0.88 0.81 533
4Positive Review 0.86 0.72 0.78 533
5
6 accuracy 0.80 1066
7 macro avg 0.81 0.80 0.80 1066
8 weighted avg 0.81 0.80 0.80 1066
准确率 80%
使用嵌入模型进行分类
监督分类, 有标注数据的情况下,也不需要微调模型. 用一个嵌入模型把训练集和测试集文本转换为向量,把这些嵌入向量作为分类器的输入特征, 然后在训练集上训练逻辑回归模型。
1from sentence_transformers import SentenceTransformer
2from sklearn.linear_model import LogisticRegression
3
4model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2", device="mps")
5
6train_embeddings = model.encode(data["train"]["text"], show_progress_bar=True)
7test_embeddings = model.encode(data["test"]["text"], show_progress_bar=True)
8
9print(train_embeddings.shape)
10print(test_embeddings.shape)
11
12clf = LogisticRegression(random_state=42)
13clf.fit(train_embeddings, data["train"]["label"])
14
15y_pred = clf.predict(test_embeddings)
16evaluate_performance(data["test"]["label"], y_pred)
使用了标注过的训练集数据,关键是上面的两行高亮行代码,参考标注列的值应用嵌入向量构建一个逻辑回归模型,最后对测试集的文本向量进行分类,最后出来的结果
1(8530, 768)
2(1066, 768)
3 precision recall f1-score support
4
5Negative Review 0.85 0.86 0.85 533
6Positive Review 0.86 0.85 0.85 533
7
8 accuracy 0.85 1066
9 macro avg 0.85 0.85 0.85 1066
10 weighted avg 0.85 0.85 0.85 1066
嵌入向量的维度是 768,准确率提升到 85%,比特定任务模型的准确率 80% 还高。
那么没有标注数据如何分类呢?有一种分类方式叫做零样本分类(zero-shot classification), 在已知标签定义(只有名称)的情况下, 尝试在模型未针对这些标签进行训练的情况下预测输入文本的标签.
前面说得这么高级,其实就是把文本向量化后,与定义的两个文本向量 A negative review, A positive review 哪个更接近,
就是两个向量的余弦相似度计算, 算不得什么新内容
1import numpy as np
2from sentence_transformers import SentenceTransformer
3from sklearn.metrics.pairwise import cosine_similarity
4
5model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2", device="mps")
6label_embeddings = model.encode(["A negative review", "A positive review"])
7
8test_embeddings = model.encode(data["test"]["text"], show_progress_bar=True)
9sim_matrix = cosine_similarity(test_embeddings, label_embeddings)
10y_pred = np.argmax(sim_matrix, axis=1) # 对测试集中的每一个文本分别计算与 label_embeddings 中两个向量的距离
11
12evaluate_performance(data["test"]["label"], y_pred)
最后识别出来的结果是
1 precision recall f1-score support
2
3Negative Review 0.78 0.77 0.78 533
4Positive Review 0.77 0.79 0.78 533
5
6 accuracy 0.78 1066
7 macro avg 0.78 0.78 0.78 1066
8 weighted avg 0.78 0.78 0.78 1066
也不差,把预定义的两个标签文本调整一下还能更准确一些。
使用生成模型进行分类
生成模型因其功能总是比特定任务的模型或嵌入模型大很多,它是序列到序列(Seq2Seq)模型,进去是 Token 序列出来也是 Token 序列。 使用生成模型分类就要写好提示词,比如告诉模型,这个评论 "xxx", 是正面还是负面的,正面回答 1,负面回答 0.
T5(Text-to-Text Transfer Transformer) 模型架构与原始的 Transformer 类似,它将 12 个编码器和 12 个解码器堆叠在一起。 T5 系列模型首先使用掩码语言模型(MLM) 进行预训练,就是玩遮住某个 Token 的猜字游戏。之后在多种任务上进行微调, 这些任务接近我们所熟知的 GPT 模型中的指令,训练后能做事情的。
书中的例子在 macOS(Apple Chip) 和 Linux(RTX 4090) 下都跑不出来,书中用的 Transformers 版本太老了,没有 text2text-generation,
换成了下面的版本才行
1from transformers.pipelines.pt_utils import KeyDataset
2from transformers import T5ForConditionalGeneration, T5Tokenizer
3
4model_name = "google/flan-t5-small"
5tokenizer = T5Tokenizer.from_pretrained(model_name)
6
7model = T5ForConditionalGeneration.from_pretrained(
8 model_name,
9 # device_map="mps",
10 torch_dtype="auto",
11)
12
13prompt = "Is the following sentence positive or negative?"
14
15y_pred = []
16
17for text in KeyDataset(data["test"], "text"):
18 inputs = tokenizer(f"{prompt} {text}", return_tensors="pt")
19 outputs = model.generate(**inputs, max_new_tokens=10)
20 text = tokenizer.decode(outputs[0], skip_special_tokens=True)
21 y_pred.append(0 if text == "negative" else 1)
22
23evaluate_performance(data["test"]["label"], y_pred)
最后的结果是
1 precision recall f1-score support
2
3Negative Review 0.83 0.85 0.84 533
4Positive Review 0.85 0.83 0.84 533
5
6 accuracy 0.84 1066
7 macro avg 0.84 0.84 0.84 1066
8 weighted avg 0.84 0.84 0.84 1066
使用 ChatGPT 进行分类
OpenAI 分享过 ChatGPT 的偏好调优(preference tuning) 的大体过程,手动创建输入提示词(指令数据)的期望输出,并使用这些数据创建了模型的第一个版本。
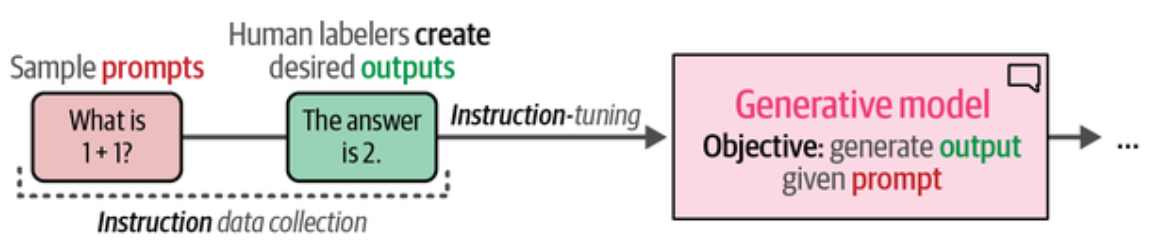
很好奇这样训练了 1+1 后会算 1+2 吗?
最后是一个使用 OpenAI API 和 API Key 使用在线 ChatGPT 模型的例子,这与本书和主题其实关系不大,这是我们日常创建 AI Agent 的工作。
不过作为本章结尾,还是放上来看看。
1import openai
2from transformers.pipelines.pt_utils import KeyDataset
3
4client = openai.OpenAI(api_key=API_KEY)
5
6def chatgpt_generate(prompt, model="gpt-5.4-mini"):
7 return client.chat.completions.create(
8 model="gpt-3.5-turbo",
9 messages=[
10 {"role": "user", "content": prompt}
11 ],
12 temperature=0
13 ).choices[0].message.content
14
15prompt = """Predict whether the following document is a positive or negative movie review:"
16
17{}
18
19If it is positive return 1 and if it is negative return 0. Do not give any other answers.
20"""
21
22y_pred = []
23
24cc = 0
25for text in KeyDataset(data["test"], "text"):
26 text = chatgpt_generate(prompt.format(text))
27 time.sleep(1)
28 print(text, cc)
29 cc = cc + 1
30 y_pred.append(int(text))
31
32evaluate_performance(data["test"]["label"], y_pred)
为了这个测试又消耗了不少 Token, 而且逐个请求也很慢,输出结果是
1 precision recall f1-score support
2
3Negative Review 0.89 0.95 0.92 533
4Positive Review 0.95 0.88 0.91 533
5
6 accuracy 0.92 1066
7 macro avg 0.92 0.92 0.92 1066
8 weighted avg 0.92 0.92 0.92 1066
准确度还是更高了。
应该要对调用 ChatGPT 做优化,如可以批处理,或者一个提示词中包含多行文本,让 ChatGPT 按顺序返回每行文本的 1 或 0 标记。
小结
本章学了不同的文本分类的方法,包括
- 使用特定任务模型进行分类
- 使用嵌入模型和已标记的数据生成逻辑回归模型进行分类(有监督分类),没标记的数据直接用嵌入模型来计算相似度进行分类(无监督分类)
- 使用生成模型分类,如 T5(Text-to-Text Transfer Transformer) 和 ChatGPT 模型进行分类. 使用生成模型分类好像没有必要写在本书中, 它其实是一个如何使用 ChatGPT 的专题
[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。