《Hands-On Large Language Models》阅读笔记(八)
第九章:多模态 LLM
本书第二部分(使用预训练模型)除了 "文本分类","文本聚类和主题建模" 两章外,其他的 "提示词工程", "高级文本生成技术与工具","语义搜索与 RAG" 这三章都只是对原有知识的巩固. 现在学习本部分的最后一章 "多模态 LLM" 应该能了解到一些模型处理图片的相关知识, 这对我来说是新的知识。
多模态就是指模型能够处理多种类型的数据,比如文本、图像、音频等,而不仅仅是文本,如果你的模型只能处理图像和音频也是多模态。视觉 Transformer (Vision Transformer, ViT) 在图像识别任务中超越了传统的卷积神经网络(CNN)。ViT 的核心功能是将非结构化的图像数据转换为可用于分类等任务的数值表示。 像处理自然语言一样来处理图像。
对于文本,Transformer 编码器对文本拆分再编码成数值表示,对文本的切割看成是一维的,ViT 对图像按水平方向和垂直方向进行网格化切割成小块,这和 CNN 用卷积核来提取图像特征的方式类似。
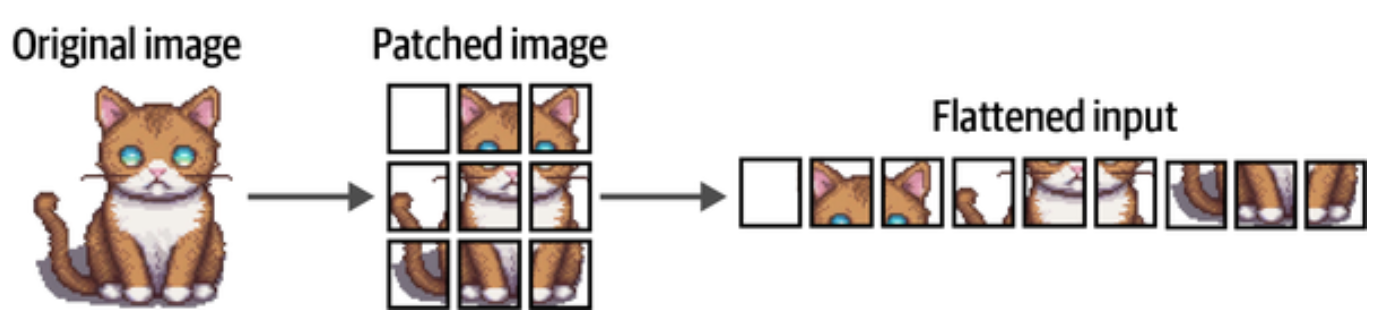
文本的词汇量是有限的,所以可以把文本分割的 Token 映射为一个数值,切成的图片块太过多样性,无法为每一种可能的图片块分配一个 Token. Transformer 的做法是把图片块平铺后对所有图像块实施线性嵌入操作,像文本嵌入一样把一组图片块转换为嵌入向量。这些蕴含语义信息的向量便可作为 Transformer 模型的标准化输入。
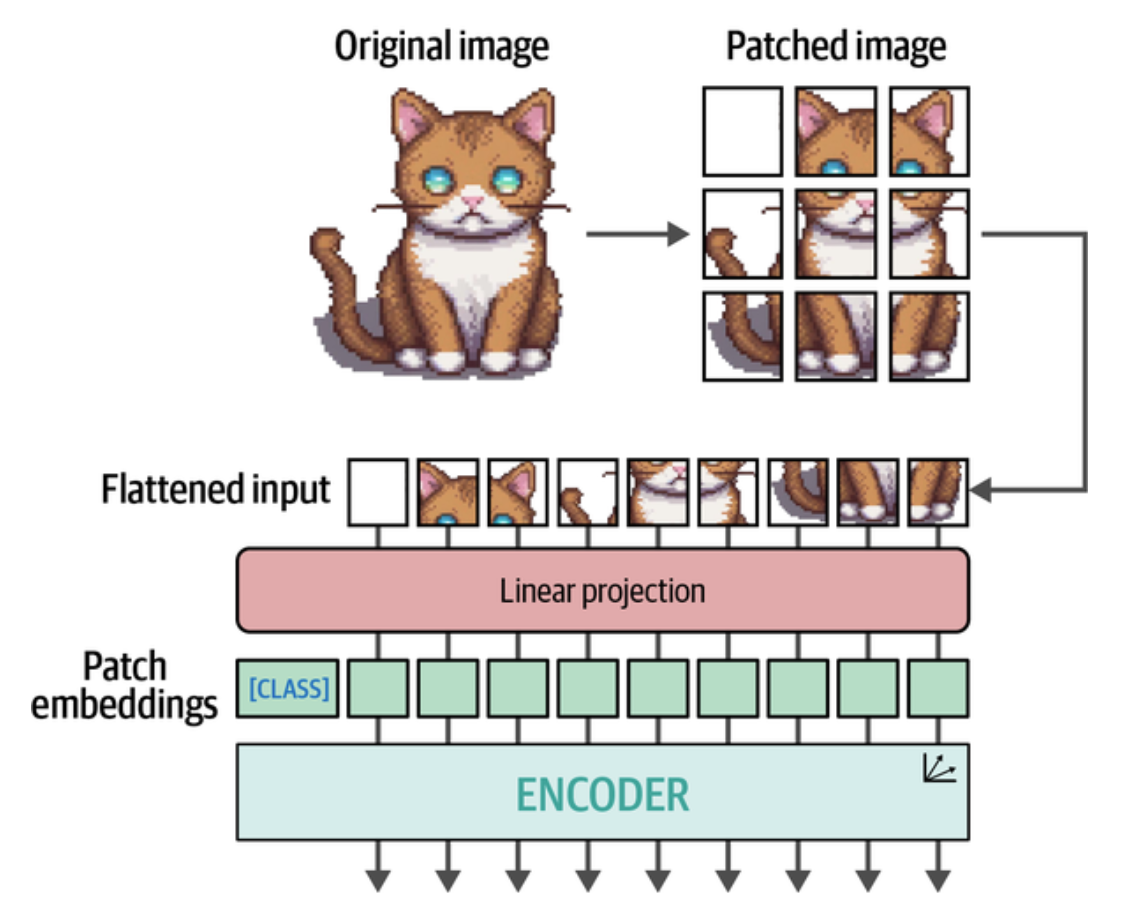
比如按论文 An Image is Worth 16x16 Words 的那样把图像切成 16x16 像素大小的小块, 每个小块被展平为一个向量,然后通过线性变换映射到一个固定维度的嵌入空间中,这些嵌入向量就可以输入到 Transformer 模型中进行处理。
当这种图片嵌入向量进入编码器后,视觉与文本模态的处理路径就完全相同了,这种架构统一性为多模态模型的构建奠定了重要基础。想像一下,那视频和音频是怎么处理的呢? 视频首先分割成帧,每帧图像按上述方式处理成嵌入向量,音频则可以通过短时傅里叶变换(STFT)等方法将其转换为频谱图,然后再进行类似的切块和嵌入处理 -- 这是在 IntelliJ IDEA 中书写时 AI 自动提示出来的。
多模态嵌入模型可在同一向量空间(Embedding Space 或 Latent Space)中为不同模态生成嵌入向量,所以可以直接比较不同模态之间的相似性,比如文本和图像之间的相似性。 对比语言-图像预训练(CLIP - Contrastive Language-Image Pre-training) 模型就是一个典型的多模态嵌入模型。
CLIP 是能同时计算图像嵌入与文本嵌入的模型,这种独特的跨模态对齐能力使 CLIP 及其同类模型可支撑以下核心应用场景
- 零样本分类 通过比对图像嵌入与类别描述文本的嵌入向量,实现无需训练数据的精准分类。
- 语义聚类 将图像集合与关键词库进行联合聚类,揭示视觉内容与文本概念的潜在关联。
- 跨模态检索 在海量多模态数据中,实现文本-图像的双向即时检索。
- 生成引导 驱动图像生成模型(如稳定扩散模型 3 - Stable Diffusion 3)实现更精准的文本-图像对齐。
CLIP 的训练数据是带描述的图像,它采用双编码器架构,文本编码器处理描述文本,生成语义嵌入; 图像编码器处理图像,生成图像嵌入; 经过联合训练后, 配对的图文数据将在共享的向量空间中获得高度对齐的嵌入向量表示,匹配图文对的相似度。所以 CLIP 训练分三步
- 分别使用图像编码器和文本编码器处理输入的图像和文本,生成对应的嵌入向量
- 使用余弦相似度计算图像嵌入和文本嵌入之间的相似度
- 根据预期相似度更新文本编码器和图像编码器参数,使得配对的图文数据在共享的向量空间中距离逐渐缩小
好像预训练的起步都是训练如何分类
开始 OpenCLIP 实战
下载三个图片, puppy.png, cat.png, car.png
{kind=link}
{kind=link}
{kind=link}
然后是使用模型 "openai/clip-vit-base-patch32" 对图片和文本进行编码,计算相似度
1import numpy as np
2
3from PIL import Image
4from transformers import CLIPProcessor, CLIPModel, CLIPTokenizer
5import torch.nn.functional as F
6
7# 加载模型与输入
8model_id="openai/clip-vit-base-patch32"
9clip_tokenizer = CLIPTokenizer.from_pretrained(model_id)
10clip_processor = CLIPProcessor.from_pretrained(model_id) # 相当于处理文本的 tokenizer
11model = CLIPModel.from_pretrained(model_id) # CLIPModel 内含两个编码器:文本编码器和图像编码器(ViT)
12
13def image_caption_score(image_file: str, caption: str):
14 image = Image.open(image_file).convert("RGB")
15
16 inputs = clip_tokenizer(caption, return_tensors="pt")
17 print("caption inputs: ", inputs)
18 # caption inputs: {'input_ids': tensor([[49406, 320, 6829, 1629, 530, 518, 2583, 49407]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1]])}
19
20 print("caption tokens: ", clip_tokenizer.convert_ids_to_tokens(inputs["input_ids"][0]))
21 # caption tokens: ['<|startoftext|>', 'a</w>', 'puppy</w>', 'playing</w>', 'in</w>', 'the</w>', 'snow</w>', '<|endoftext|>']
22
23 # 整个文本转换成了一个维度为 512 的嵌入向量,这是一个文本嵌入操作
24 text_embedding = model.get_text_features(**inputs).pooler_output
25 print("caption embedding shape: ", text_embedding.shape)
26 # caption embedding shape: torch.Size([1, 512])
27
28 processed_image = clip_processor(text=None, images=image, return_tensors="pt")["pixel_values"]
29 print("processed_image shape: ", processed_image.shape)
30 # processed_image shape: torch.Size([1, 3, 224, 224])
31 # 1: batch, 3: RGB 三个通道,224*224: 图像被缩小/裁剪成了 224*224 的大小
32
33 # 输出采样的图片区域,是一个 224*224 的 RGB 图片
34 # 为什么是 224*224, 因为模型 openai/clip-vit-base-patch32", patch 大小是 32*32, 而 224*224 包含 7*7 个 patch
35 save_sample_image(processed_image, image_file)
36
37 # 上面 49 个 patch 铺平后被编码成了一个维度为 512 的嵌入向量,这是一个图像嵌入操作
38 image_embedding = model.get_image_features(processed_image).pooler_output
39 print("image_embedding shape: ", image_embedding.shape)
40 # image_embedding shape: torch.Size([1, 512])
41
42 # 计算它们的相似度
43 score = F.cosine_similarity(image_embedding, text_embedding)
44 print(f"{image_file}->{caption}: {score.tolist()[0]:.2f}")
45
46
47def save_sample_image(processed_image: np.ndarray, image_file: str):
48 img = processed_image.squeeze(0) # [3, 224, 224] 去掉了第一维
49 img = img.permute(1, 2, 0).numpy() # [224, 224, 3],CHW → HWC, 通道优先变换为高度优先, C: Channel
50
51 img_np = (img - img.min()) / (img.max() - img.min()) * 255
52 img_np = img_np.astype(np.uint8)
53
54 Image.fromarray(img_np).save("sample-" + image_file)
55
56
57if __name__ == '__main__':
58 image_files = ["puppy.png", "cat.png", "car.png"]
59 captions = [
60 "a puppy playing in the snow",
61 "a pixelated image of a cute cat",
62 "A supercar on the road \nwith the sunset in the background"
63 ]
64 for image_file in image_files:
65 for caption in captions:
66 image_caption_score(image_file, caption)
这里保留了重复编码图片和描述的代码,实际使用中对所有出现的图片和描述只需要编码一次。代码中有详细的过程注释,主要过程就是把图片和描述同时编码到维度为 512 的向量空间中,然后就可以计算它们的余弦相似度,把结果整理如下






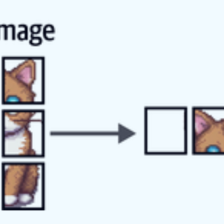
图片取样可能会把最小边缩放到 224,保持宽高比不变,所以有些图片会被裁剪掉一部分,或者在边缘添加黑色填充。对于有些长宽比较极端的图片, 可能只是取了一小部分,比如本文第一个图片,长宽为 1384*330, 取样的图片如下
还可以用简单的 sentence-transformers 加载 CLIP
1from PIL import Image
2
3images = [Image.open(image_file).convert("RGB") for image_file in image_files]
4
5from sentence_transformers import SentenceTransformer, util
6
7model = SentenceTransformer("clip-ViT-B-32")
8
9image_embeddings = model.encode(images)
10text_embeddings = model.encode(captions)
11
12sim_matrix = util.cos_sim(
13 image_embeddings, text_embeddings
14)
15
16print(sim_matrix)
输出一样的相似度值
1tensor([[0.3315, 0.1863, 0.1084],
2 [0.1488, 0.3463, 0.0947],
3 [0.0762, 0.1260, 0.3098]])
BLIP-2 技术赋予传统语言模型视觉认知
BLIP-2(Bootstrapping Language-Image Pre-training), 它通过构建名为 Querying Transformer(Q-Former) 的智能桥梁,巧妙连接预训练视觉编码器与预训练 LLM, 而非重新构建整个系统架构, 仅需要训练 Q-Former 模块。完整过程是
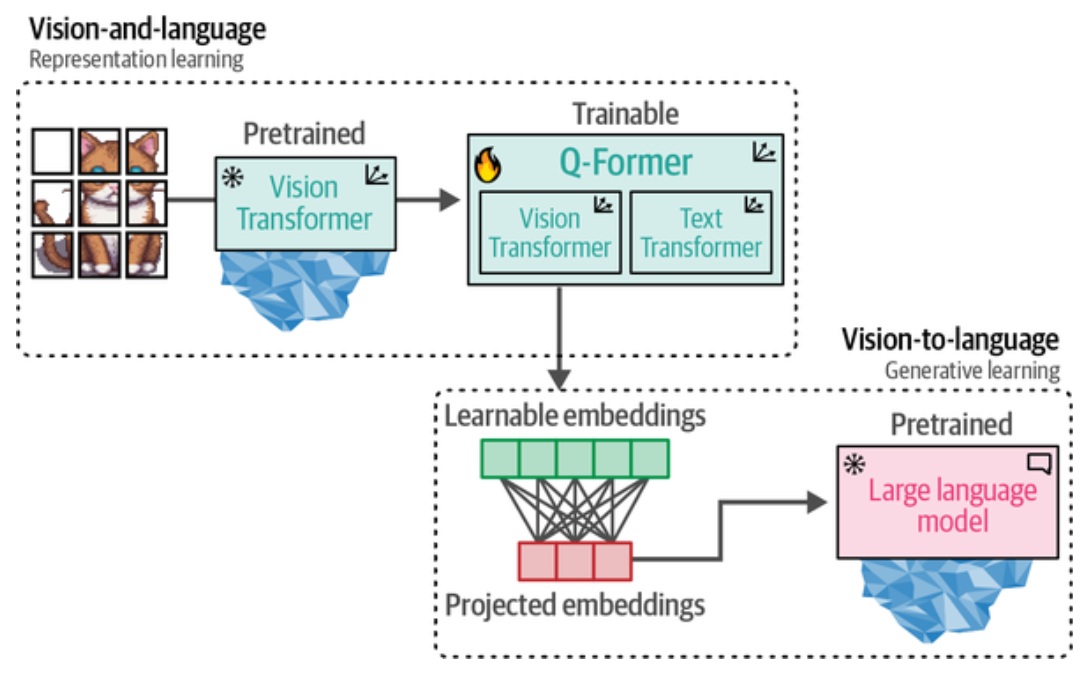
多模态输入预处理
同时输入文本和图片时
1from PIL import Image
2
3from transformers import AutoProcessor, Blip2ForConditionalGeneration
4
5model_name = "Salesforce/blip2-opt-2.7b"
6blip_processor = AutoProcessor.from_pretrained(model_name)
7model = Blip2ForConditionalGeneration.from_pretrained(model_name).to("mps")
8# print(model.vision_model, model.language_model)
9print(model)
10
11image = Image.open("car.png").convert("RGB")
12image_pixels = blip_processor(images=image, return_tensors="pt").to("mps")["pixel_values"]
13print(image_pixels.shape) # torch.Size([1, 3, 224, 224])
14
15text = "Her vocalization was remarkably melodic"
16token_ids = blip_processor(text=text, return_tensors="pt").to("mps")["input_ids"][0]
17tokens = blip_processor.tokenizer.convert_ids_to_tokens(token_ids)
18print(tokens) # ['</s>', 'Her', 'Ġvocal', 'ization', 'Ġwas', 'Ġremarkably', 'Ġmel', 'odic']
blip_model 中同时有 vision_model 和 language_model, 这里图片和文本分开来处理的,也可一次调用 blip_processor() 同时处理
1inputs = blip_processor(text=text, images=image, return_tensors="pt").to("mps")
Token 中的特殊符号 Ġ, 实际代表空格,就是当前 Token 是否与前面的 Token 紧密相连,这是为了打印时故意把空格字符(32) 加上 256 变成了 288,
这样就能在打印时清晰地看到空格的位置了。
model 打印出来看到里面的层次
把以上 model 的输出放到 整体结构 BLIP-2 是一个视觉-语言多模态模型,由三个主要模块串联组成: ① Vision Encoder(视觉编码器) 基于 EVA-CLIP ViT-g/14,是一个大型视觉 Transformer: ② Q-Former(查询变换器)—— 核心创新 这是 BLIP-2 的关键桥梁模块,设计目的是将高维视觉特征"压缩"成语言模型能理解的 token: 维护 32 个可学习 query token(维度 768) 12 层交替执行两种 attention: MLP 维度 768→3072→768,激活函数 GELU 最终输出 32 × 768 的压缩视觉表示 这种设计让模型只用 32 个 token 就能表达整张图像的关键信息,大幅降低语言模型的计算压力。 ③ Language Model(语言模型) 基于 OPT-2.7B(OPTForCausalLM): 几个值得注意的设计细节 Cross-attention 的"每隔一层"模式:Q-Former 12 层中,只有第 0、2、4、6、8、10 层(偶数层)有 cross-attention,奇数层只有 self-attention。这降低了计算量,同时让 query 在"吸收视觉信息"和"内部整合"之间交替。 维度的三级变换:1408(视觉)→ 768(Q-Former)→ 2560(语言),每个阶段都有明确的维度对齐。 OPT 使用 ReLU 而非 GELU:这是 OPT 系列模型的历史选择,与当时大多数 LLM 不同。 冻结策略:训练时视觉编码器和语言模型通常是冻结的,只训练 Q-Former,这正是 BLIP-2 参数效率高的原因。Claude 中,得到一个 BLIP-2 很清晰的解释点击展开查看 Claude 对 model 输出的解释

下面是两个带有图片时的用例,分别是给指定图片生成描述和基于聊天的多模态提示词
生成图像描述
输入 car.png 这张图片,让模型输出一段对该图片的描述
1from PIL import Image
2
3from transformers import AutoProcessor, Blip2ForConditionalGeneration
4
5model_name = "Salesforce/blip2-opt-2.7b"
6blip_processor = AutoProcessor.from_pretrained(model_name)
7model = Blip2ForConditionalGeneration.from_pretrained(model_name).to("mps")
8
9image = Image.open("car.png").convert("RGB")
10inputs = blip_processor(images=image, return_tensors="pt").to("mps")
11
12generated_ids = model.generate(**inputs, max_new_tokens=50)
13generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=True)
14print(generated_text[0].strip())
输出为
an orange supercar driving on the road at sunset
没问题
基于聊天的多模态提示词
和上面的代码类似,只是 blip_processor() 处理图片时用 text 参数加上一段提示词让模型回答问题,这里不写完整代码,但换一张 cat.png 图片
1image = Image.open("cat.png").convert("RGB")
2
3prompt = "Question: Write down what you see in this picture. Answer:"
4inputs = blip_processor(images=image, text=prompt, return_tensors="pt").to("mps")
5
6generated_ids = model.generate(**inputs, max_new_tokens=50)
7generated_text = blip_processor.batch_decode(generated_ids, skip_special_tokens=True)
8print(generated_text[0].strip())
输出为
Question: Write down what you see in this picture. Answer: a cat
小结
本章学习了 LLM 实现多模态能力的核心机制,了解了 ViT 如何对图片进行编码,从左到右,从上往下把图片按网格切分,然后平铺再转换成嵌入向量,
再与它相关联的文本嵌入放在同一个向量空间,这样就能像处理文本一样处理图片,进行分类,相似度计算等。BLIP-2 通过引入 Q-Former 模块,
把视觉与传统的 LLM 连接了起来。
[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。