《Hands-On Large Language Models》阅读笔记(九)
第三部分: 训练和微调语言模型 - 构建文本嵌入模型
终于来到了可以真正实战的部分,前面的章节都是关于理解和使用大语言模型的知识,现在可以开始动手实践了。涉及到训练和微调模型, 不过本书只讲了如何训练一个嵌入模型,要学习训练一个生成模型的知识还得看 Build a Large Language Model (From Scratch) 这本书,或者参考 Karpathy 的 nanoGPT 项目。
先从构建一个文本嵌入模型开始吧。嵌入模型是 NLP 的基础,它可应用于多种场景, 如监督分类(supervised classification), 无监督分类(unsupervised classification), 语义搜索等, 甚至为 ChatGPT 赋予记忆功能。
嵌入模型的功能就是把非结构化的文本转换为数值表示的向量,这样才可计算,这一转换过程称为嵌入(embedding)。对输入进行嵌入通常由 LLM 执行, 这样的模型就是嵌入模型。嵌入模型可针对多种目的进行训练,如基于语义,或情感的分类等,比如通过微调使嵌入模型关注情感倾向,通过向模型展示足够多的语义相似文档, 引导模型向语义分析的方向发展,使用情感数据则向情感分析的方向发展。
训练,微调和引导嵌入模型的方法很多,其中最强大的且应用最广泛的技术是对比学习。
对比学习
对比学习是训练和微调文本嵌入模型的一种主要技术。对比学习的目标是训练嵌入模型,使相似文档在向量空间中距离更近,而不相似文档相距更远。 对比学习的基本理念是,向模型输入相似的和不相似的文档对作为示例,这是学习文档之间的相似性或差异性并构建相关模型的最佳方式。
在自然语言处理领域,对比学习的一个框架是 sentence-transformers, 相应的技术是 SBERT(Sentence-BERT),它减小了原始 BERT 的计算开销。在 SBERT 之前句子嵌入通常使用交叉编码器(cross-encoder) 架构,并结合 BERT 模型来实现,交叉编码器计算 n 个句子两两相似度,需要 n(n-1)/2 次计算。
SBERT 有一种更快地创建可进行语义比较的嵌入向量的方式,采用双编码器,并通过损失函数对句子嵌入进行优化,这种方法比交叉编码器更快。
构建嵌入模型
在预训练嵌入模型时,可能听说过自然语言推理 NLI(Natural Language Inference), 即判断前提(premise) 和假设(hypothesis) 两个句子间的三种关系:蕴含(正例), 矛盾(负例), 和不相关(中性)关系。
- 蕴含(Entailment): "小明今天骑自行车去了图书馆" 和 "小明今天骑自行车了" 之间的关系是蕴含的,两句向量应该接近
- 矛盾(Contradiction): "小明今天骑自行车去了图书馆" 和 "小明今天哪儿也没去" 的关系就是矛盾的,两句向量应该很远
- 中性(Neutral): "小明今天骑自行车去了图书馆" 和 "小明今天买了三斤肉" 的关系是中立的,两句向量距离应该适中,去图书馆与买肉没有关系
我们将使用 GLUE(General Language Understanding Evaluation benchmark) 基准数据集来创建和微调嵌入模型。它包含了 392,702 带有推理关系标注(蕴含, 矛盾, 中立)的句子对。我们将使用其中的 5 万对来训练模型,剩下的用来评估模型性能。
这还得开动我的 4090 来构建这样的嵌入模型了, 在有 4090 的 Linux 机器下准备
1mkdir jupyter-lab && cd jupyter-lab
2python3.14 -m venv .venv
3source .venv/bin/activate
4pip install jupyterlab
5jupyter lab --ip=0.0.0.0 --ServerApp.token='' --no-browser
jupyter lab 启动后就可以用 http://IntelliJ IDEA 中创建 Jupyter
Notebook 文件 *.ipynb, 然后打开文件后选择连接到该 External Server.
加载 GLUE 数据集
1from datasets import load_dataset
2
3train_dataset = load_dataset("nyu-mll/glue", "mnli")
4print(train_dataset)
5
6train_dataset = load_dataset(
7 "nyu-mll/glue", "mnli", split="train"
8).select(range(50_000)).remove_columns("idx")
9
10train_dataset
数据集 nyu-mll/glue 的子集 mnli 包含了 train, validation_matched, validation_mismatched, test_matched,
test_mismatched 数据集,如果用 load_dataset("nyu-mll/glue", "mnli") 加载打印出来是
1DatasetDict({
2 train: Dataset({
3 features: ['premise', 'hypothesis', 'label', 'idx'],
4 num_rows: 392702
5 })
6 validation_matched: Dataset({
7 features: ['premise', 'hypothesis', 'label', 'idx'],
8 num_rows: 9815
9 })
10 validation_mismatched: Dataset({
11 features: ['premise', 'hypothesis', 'label', 'idx'],
12 num_rows: 9832
13 })
14 test_matched: Dataset({
15 features: ['premise', 'hypothesis', 'label', 'idx'],
16 num_rows: 9796
17 })
18 test_mismatched: Dataset({
19 features: ['premise', 'hypothesis', 'label', 'idx'],
20 num_rows: 9847
21 })
22})
我们这里只取 train 数据集,label 的取值, 0=蕴含(Entailment), 1=中性(Neutral), 2=矛盾(Contradiction), 下面是几个样本
| premise | hypothesis | label |
|---|---|---|
| Conceptually cream skimming has two basic dimensions - product and geography. | Product and geography are what make cream skimming work. | 1 |
| How do you know? All this is their information again. | This information belongs to them. | 0 |
| (Read for Slate 's take on Jackson's findings.) | Slate had an opinion on Jackson's findings. | 0 |
| Gays and lesbians. | Heterosexuals. | 2 |
| Vrenna and I both fought him and he nearly took us. | Neither Vrenna nor myself have ever fought him. | 2 |
注: 以上用 Pandas 输出的 pd.DataFrame(train_dataset[:10]).to_markdown(index=False)
训练模型
实战开始了,通常我们可以选择一个现有的 sentence-transformers 模型进行微调,但这里将从头开始训练一个嵌入模型。下面也是基于一个预训练的嵌入模型(如
bert-base-uncased) 训练的,为何还叫做从头开始训练呢?可能是因为 bert-base-uncased 只是一个通用的预训练模型,没有为相似度作优化。
接着要确定两件事
- 确定一个用于嵌入单词的预训练模型,将使用不区分大小写版的 BERT 基座模型,用
microsoft/mpnet-base作为基础嵌入模型也行 - 定义一个用于优化模型的损失函数(loss function), 将使用 softmax 损失函数
所需依赖有
1pip install sentence_transformers datasets 'accelerate>=1.1.0' tqdm
下面是训练模型的完整代码
1from datasets import load_dataset
2from sentence_transformers import SentenceTransformer
3from sentence_transformers.sentence_transformer import losses
4from sentence_transformers.sentence_transformer.evaluation import EmbeddingSimilarityEvaluator
5from sentence_transformers.sentence_transformer.training_args import SentenceTransformerTrainingArguments
6from sentence_transformers.sentence_transformer.trainer import SentenceTransformerTrainer
7
8# 加载训练数据,使用前 50,000 条记录进行训练
9train_dataset = load_dataset(
10 "nyu-mll/glue", "mnli", split="train"
11).select(range(50_000)).select_columns(["premise", "hypothesis", "label"])
12
13# 选择基座模型, 不区分大小写的 bert 模型
14# 该模型的参数为 0.1B,12 层 Transformer, 12 个注意力头
15embedding_model = SentenceTransformer('bert-base-uncased', device="cuda")
16
17# 定义损失函数
18train_loss = losses.SoftmaxLoss(
19 model=embedding_model,
20 embedding_dimension=embedding_model.get_embedding_dimension(), # 该模型的嵌入维度为 768
21 num_labels=3 # 0, 1, 2 三种不同的 label
22)
23
24# 定义评估器,使用语义文本相似度基准(Semantic Textual Similarity Benchmark, STSB)
25# 这是一个由人工标注的句子对数据集,相似度分数在 1 ~ 5 之间
26val_sts = load_dataset("nyu-mll/glue", "stsb", split="validation")
27evaluator = EmbeddingSimilarityEvaluator(
28 sentences1=val_sts["sentence1"],
29 sentences2=val_sts["sentence2"],
30 scores=[score/5 for score in val_sts["label"]], # 值转换为 0~1 之间,同余弦相似度的范围一致
31 main_similarity="cosine"
32)
33
34# 定义训练参数
35args = SentenceTransformerTrainingArguments(
36 output_dir="base_embedding_model",
37 num_train_epochs=1, # 只训练一个 epoch(轮次)
38 per_device_train_batch_size=32,
39 per_device_eval_batch_size=32,
40 warmup_steps=100, # 前 100 步学习率从 0 线性增长
41 fp16=True,
42 eval_steps=100,
43 logging_steps=100
44)
45
46# 训练模型
47# 它负责 前向传播 -> 计算损失 -> 反向传播 -> 参数更新
48# 自动保存最优检查点到输出目录,此处为 base_embedding_model
49trainer = SentenceTransformerTrainer(
50 model=embedding_model,
51 args=args,
52 train_dataset=train_dataset,
53 loss=train_loss,
54 evaluator=evaluator
55)
56
57trainer.train()
整体的训练流程
1[MNLI 数据]
2hypothesis + premise + label
3 ↓
4[BERT 编码] × 2 → 两个 768维向量
5 ↓
6[SoftmaxLoss] 用 NLI 分类任务微调 BERT
7 ↓
8[每100步] 在 STSB 上测余弦相似度相关系数
9 ↓
10[保存] 最终得到一个高质量的句子嵌入模型
训练后在 Jupyter Lab 中的输出为
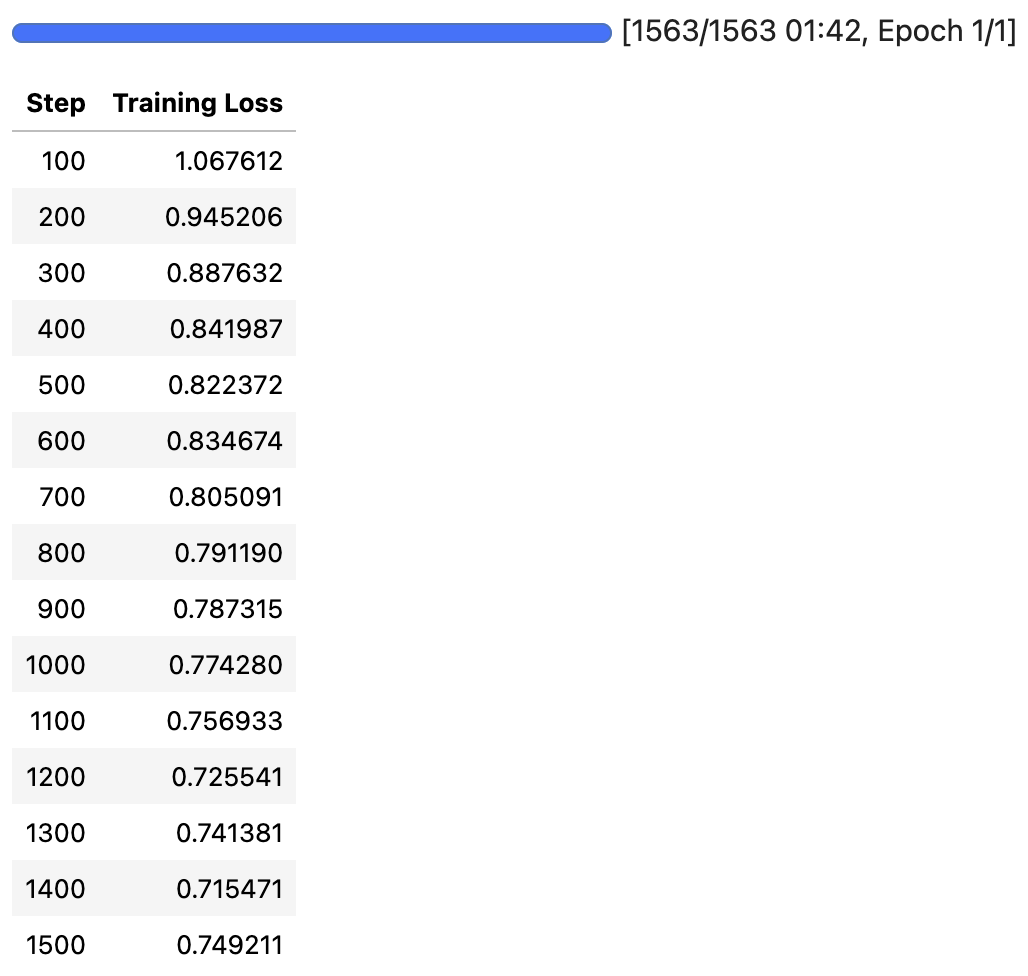
共有 50,000 条训练数据,batch size 为 32,训练步数就为 1563(ceil(50,000/32)) 步.
1TrainOutput(global_step=1563, training_loss=0.8133826545622588, metrics={'train_runtime': 102.5122, 'train_samples_per_second': 487.747, 'train_steps_per_second': 15.247, 'total_flos': 0.0, 'train_loss': 0.8133826545622588, 'epoch': 1.0})查看生成的模型目录
1$ du -sh base_embedding_model
24.9G base_embedding_model
3$ ls base_embedding_model
4checkpoint-1000 checkpoint-1500 checkpoint-1563 checkpoint-500
5ls -lh base_embedding_model/checkpoint-500
6total 1.3G
7drwxrwxr-x 2 yanbin yanbin 4.0K May 26 13:10 1_Pooling
8-rw-rw-r-- 1 yanbin yanbin 14K May 26 13:10 README.md
9-rw-rw-r-- 1 yanbin yanbin 746 May 26 13:10 config.json
10-rw-rw-r-- 1 yanbin yanbin 283 May 26 13:10 config_sentence_transformers.json
11-rw-rw-r-- 1 yanbin yanbin 418M May 26 13:10 model.safetensors
12-rw-rw-r-- 1 yanbin yanbin 277 May 26 13:10 modules.json
13-rw-rw-r-- 1 yanbin yanbin 831M May 26 13:10 optimizer.pt
14-rw-rw-r-- 1 yanbin yanbin 15K May 26 13:10 rng_state.pth
15-rw-rw-r-- 1 yanbin yanbin 1.4K May 26 13:10 scaler.pt
16-rw-rw-r-- 1 yanbin yanbin 1.5K May 26 13:10 scheduler.pt
17-rw-rw-r-- 1 yanbin yanbin 241 May 26 13:10 sentence_bert_config.json
18-rw-rw-r-- 1 yanbin yanbin 695K May 26 13:10 tokenizer.json
19-rw-rw-r-- 1 yanbin yanbin 351 May 26 13:10 tokenizer_config.json
20-rw-rw-r-- 1 yanbin yanbin 1.7K May 26 13:10 trainer_state.json
21-rw-rw-r-- 1 yanbin yanbin 5.5K May 26 13:10 training_args.bin
训练出的输出文件占 4.9G. 如果进行多轮(如 num_train_epochs=2) 训练, 那么会增加更多的目录,如 checkpoint-2000, checkpoint-2500 等,
所以每多一轮文件大小增加一倍。
在执行 trainer.train() 前与后 evaluator(embedding_model) 的值分别为
前
1{'pearson_cosine': 0.5917194531209226, 'spearman_cosine': 0.5931742011707938}
后
1{'pearson_cosine': 0.61245920788679, 'spearman_cosine': 0.6768015560359488}
pearson_cosine 从 0.59 涨到了 0.61.
深入评估模型
除了用 STSB 测试模型,GLUE(nyu-mll/glue) 基准数据集还包含多个用于评估的数据集。用于评估嵌入模型的基准还有很多,大规模文本嵌入基准(Massive
Text Embedding Benchmark, MTEB) 为此而生,MTEB 涵盖 8 个嵌入任务,涉及 58 个数据集和 112 种语言。
8 个嵌入任务是
- Bitext Mining(双语文本挖掘), 代表数据集 BUCC, Tatoeba
- Classification(分类), 代表数据集 AmazonPolarity, Emotion, IMDB, ToxicConversations
- Clustering(聚类), 代表数据集 ArxivS2S, RedditP2P, TwentyNewsgroup
- Pair Classification(句对分类), 代表数据集:SprintDuplicateQuestions、TwitterSemEval2015
- Reranking(重排序), 代表数据集:AskUbuntuDupQuestions、SciDocsRR
- Retrieval(信息检索), 代表数据集:MSMARCO、NQ、HotpotQA、FEVER、TREC-COVID
- Semantic Textual Similarity/STS(语义文本相似度), 代表数据集:STS12~STS22、STSB、BIOSSES、SICK-R
- Summarization(文本摘要), 代表数据集:SummEval
详细用法请参考官方文档 Evaluation with MTEB, 书中的内容有点陈旧。
损失函数
最早的 sentence-transformers 模型用 softmax 损失函数进行训练,可供选择的损失函数很多,通常不再建议使用 softmax, 其他损失函数可能更高效。
在现实中损失函数(Loss Function) 常常与代价函数(Cost Function), 或目标函数(Objective Function) 混用,有时候无需把它们严格区分。 说到目标函数的话,我们在进行优化操作就会提到它,大体也相当,优化操作也是进行梯度下降找最小值。但它们也有概念上的区别,损失函数看单个样本, 代价函数看全局,目标函数是真正被优化的。
两个常用且表现普遍较好的损失函数
- 余弦相似度(Cosine similarity)
- 多负例排序(MNR-Multiple negatives ranking)
余弦相似度损失函数常用于语义文本相似度任务,数值介于 0 和 1 之间,值越大越相似(cos(θ), 越接近 1, 夹角越小越相似, 不要与余弦距离搞混)。 它的原理很简单——首先计算两段文本的两个嵌入向量之间的余弦相似度,然后将其与标注的相似度分数进行比较。
将余弦相似度用于 NLI 数据集时,必须将标注的标签(0: 蕴含, 1: 中性, 2: 矛盾) 转换为相似度分数(1, 0, 0).
如果要将上面训练嵌入模型代码中的损失函数从 softmax 改为余弦相似度损失函数,关键代码如下
1# 从 GLUE 加载的 MNLI 数据集转换 Label
2# 中性/矛盾 = 0, 蕴含=1
3mapping = {2: 0, 1: 0, 0: 1}
4train_dataset = Dataset.from_dict({
5 "sentence1": train_dataset["premise"],
6 "sentence2": train_dataset["hypothesis"],
7 "label": [float(mapping[label]) for label in train_dataset["label"]]
8})
9
10# 定义损失函数
11train_loss = losses.CosineSimilarityLoss(model=embedding_model)
训练的数据集中的 Label 按照余弦相似度损失函数的要求进行转换,将标签转换为相似度分数,然后选择余弦相似度损失函数进行训练。
改用余弦相似度损失函数后,训练完打印 evaluator(embedding_model) 显示为
{'pearson_cosine': 0.7250524707965853, 'spearman_cosine': 0.7289073126352569}
效果看起来要好一些,训练后生成的目录大小同样为 4.9G, 看来训练数据和基础嵌入模型的规格决定了生成的文件大小。
在我们编写代码时可能注意到在 sentence_transformers.sentence_transformer.losses 中有许多可选的损失函数, 如 TripletLoss, MSELoss, ContrastiveLoss, CoSENTLoss, AnglELoss, DistillKLDivLoss, MarginMSELoss 等等。
多负例排序损失函数(MNR: Multiple Negatives Ranking)
在 sentence_transformers.sentence_transformer.losses 中相关的函数有
- MultipleNegativesRankingLoss
- MultipleNegativesSymmetricRankingLoss
- CachedMultipleNegativesRankingLoss
- CachedMultipleNegativesSymmetricRankingLoss
多负例排序损失函数也常被称为 InfoNCE 或 NTXentLoss 函数。它使用正例句子对, 或包含一对正例句子和一个不相关句子的三元组,其中不相关的句子被称为负例。
有两个关键的代码改动,分别是定义训练数据集和定义损失函数
1# 加载训练数据
2mnli = load_dataset(
3 "nyu-mll/glue", "mnli", split="train"
4).select(range(100_000)).remove_columns("idx")
5
6# 过滤后获得正例的 premise/hypothesis 数据, 过滤出 33803 条记录
7mnli = mnli.filter(lambda x: True if x["label"] == 0 else False)
8
9# 定义训练数据集,三元组
10# anchor(mnli 的 premise), positive(mnli 的 hypothesis), negative(mnli["hypothesis"] 中随机选取)
11train_dataset = {"anchor": [], "positive": [], "negative": []}
12soft_negatives = random.sample(mnli["hypothesis"], len(mnli)) # 打乱 mnli["hypothesis"] 将作为负例
13for row, soft_negative in zip(mnli, soft_negatives):
14 train_dataset["anchor"].append(row["premise"])
15 train_dataset["positive"].append(row["hypothesis"])
16 train_dataset["negative"].append(soft_negative)
17train_dataset = Dataset.from_dict(train_dataset)
18
19# 定义损失函数
20train_loss = losses.MultipleNegativesRankingLoss(model=embedding_model)
其他都一样,训练这 33803 条记录比前面的使用 softmax 和余弦损失函数要慢很多,训练完 evaluator(embedding_model)
{'pearson_cosine': 0.8126082864719841, 'spearman_cosine': 0.8147842455653254}
又好一些了, 目录大小为 3.7G, 可能是数据不足 50,000 条的原因。这里负例是随机选取的,是与问题完全不相关的句子,是简单的负例, 这种情况嵌入模型找到正确答案更容易。还有一种负例叫 hard negative,是与正例有相似含义的句子,但不正确的答案,是更难的负例,需要模型更努力地学习。
训练出的嵌入模型的使用
尝试
1from sentence_transformers import SentenceTransformer
2
3model = SentenceTransformer("cosineloss_embedding_model")
4embeddings = model.encode(sentences)
5print(embeddings)
加载不了模型,出错为
ValueError: Unrecognized model in cosineloss_embedding_model. Should have a
model_typekey in its config.json.
在 base_embedding_model 这一层没有 config.json 文件,要在每个 checkpoint-xxxx 目录中才有 config.json 文件,于是写成
1from sentence_transformers import SentenceTransformer
2
3model = SentenceTransformer("cosineloss_embedding_model/checkpoint-1563")
4embeddings = model.encode(sentences)
5print(embeddings)
正常输出生成的嵌入向量,维度为 768, 由下可见每个 checkpoint 目录保存了部分训练阶段的数据
1du -sh cosineloss_embedding_model/*
21.3G cosineloss_embedding_model/checkpoint-1000
31.3G cosineloss_embedding_model/checkpoint-1500
41.3G cosineloss_embedding_model/checkpoint-1563
51.3G cosineloss_embedding_model/checkpoint-500
要一个目录中包含全部预训练结果,在 trainer.train() 训练完成后,调用 embedding_model.save(<目录>), 如用余弦损失函数训练后加上
1embedding_model.save("cosineloss_embedding_model")
这时候目录 cosineloss_embedding_model 中的内容就是
1du -sh cosineloss_embedding_model/*
28.0K cosineloss_embedding_model/1_Pooling
316K cosineloss_embedding_model/README.md
41.3G cosineloss_embedding_model/checkpoint-1000
51.3G cosineloss_embedding_model/checkpoint-1500
61.3G cosineloss_embedding_model/checkpoint-1563
71.3G cosineloss_embedding_model/checkpoint-500
84.0K cosineloss_embedding_model/config.json
94.0K cosineloss_embedding_model/config_sentence_transformers.json
10418M cosineloss_embedding_model/model.safetensors
114.0K cosineloss_embedding_model/modules.json
124.0K cosineloss_embedding_model/sentence_bert_config.json
13696K cosineloss_embedding_model/tokenizer.json
144.0K cosineloss_embedding_model/tokenizer_config.json
rm -rf cosineloss_embedding_model/checkpoint-* 删除 checkpoint 目录后,剩下的就是最终的模型文件了,加载时直接指定 cosineloss_embedding_model 目录即可。
1du -sh cosineloss_embedding_model/*
28.0K cosineloss_embedding_model/1_Pooling
316K cosineloss_embedding_model/README.md
44.0K cosineloss_embedding_model/config.json
54.0K cosineloss_embedding_model/config_sentence_transformers.json
6418M cosineloss_embedding_model/model.safetensors
74.0K cosineloss_embedding_model/modules.json
84.0K cosineloss_embedding_model/sentence_bert_config.json
9696K cosineloss_embedding_model/tokenizer.json
104.0K cosineloss_embedding_model/tokenizer_config.json
实际的模型文件就是那个 cosineloss_embedding_model/model.safetensors, 418M 大小。
现在可以用
1from sentence_transformers import SentenceTransformer
2
3model = SentenceTransformer("cosineloss_embedding_model")
4embeddings = model.encode(["The weather is nice today"])
5embeddings.shape
也可以用该模型进行句子相似度计算,生成嵌入向量后进行余弦相似度计算, 或作语义搜索。
我们可以用刚训练出来的嵌入模型与选择的基础模型 bert-base-uncased 进行对比,它们生成的嵌入向量还是不一样的。
想要训练一个好的嵌入模型首先要选择一个合适的基础模型,其实就是要好的用来训练的数据,还必须由人工构建的或做过良好标注的数据,再就是选择一个恰当的损失函数实现。
本章的前半部分的学习到此为止,后面部分是微调嵌入模型和无监督学习。
永久链接 https://yanbin.blog/hands-on-large-language-models-reading-notes-9/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。