Java 22 新特性学习
Java 22 是一个过渡版本, 还是到下面两个链接中找相应的更新
IntelliJ IDEA 对 Java 22 Language level 描述是
- 22 - Unnamed variables and patterns
- 22(Preview) - Statements before super(), string templates (2nd preview), etc.
把上面第二个链接中的特性列出来
本文对上面用红点标记的特性重点关注
JEP 423: Region Pinning for G1
自 Java 9 开始默认垃圾收集算法由 ParallelGC 变为 G1(Garbage First) 后, 到目前 Java 25 一直默默的扮演了一个十分重要的角色. G1
采用分代多 Region 的方式, 实现低延迟(100-200 毫米级), 且低 CPU 消耗. 现在发展出的 ZGC, 号称更低延迟(<10ms), 但完全并行式更消耗 CPU,
在超大内存和强 CPU 下可以考虑用 ZGC.
好了, 回到 G1 的 Region pinning for G1 这一改进, JNI 有一类 API(例如 GetPrimitiveArrayCritical / ReleasePrimitiveArrayCritical
允许 native 代码拿到 Java 对象(常见是数组/字符串数据)的“直接指针”,并要求在这段 critical region 里 JVM 不能移动这个对象, 因为该象关联到 Off heap 的数据.
这个被操作的对象被称作 cretical object. 当 G1 运行时发现还有线程处于这个 critical region 中, 就会禁用 GC, 线程退出了该 critical region,
这会造成 GC 等待数分种, 进而可能造成 OutOfMemory 异常.
注意: G1 把新老代分成若干个内存区域 - region, 比如 2048 个 region, 这里的 region 与上面的 critical region 是两个不一样的概念,
critical region 更类似于 try/catch 那样的监视区域.
G1 新的办法是在每个 G1 region 中维护一个 critical object 的引用计数, 进入 critical region 时计数 +1, 离开时计数 -1, 当计数 > 0
则认为 region pinned.
在 Major/Full GC 时不处理该 pinned region; 在 Minor/Young GC 时, 如果 pinned region 是年轻代, 就把该 region 提升为老年代.
这时候 G1 不用等待 critical object 离开 critical region, 只维护引用计数, 同时能处理其他的 region. 对于使用了 JNI 技术的项目值得升级到 Java 22.
JEP 447: Statements before super(...) (Preview)
自我学 Java 开始就明白, 当继承有默认构造函数的父类, 在子类构造函数中不写的 super(), super(values) 的话会隐式调用 super(),
而父类不存在默认构造函数时, 在子类构造函数的第一行就必须显示的调用用 super(values) 形式指定调用相应的父类构造函数.
这是因为在创建子实例之前必须能成功创建出一个类似于不可见的父实例.
1class A {
2 public A(int x) {
3 }
4}
5
6class B extends A {
7 public B() {
8 super(10); // super(10) 必须放在最前面
9 int y = 5;
10 }
11}
如果换一下
1 public B() {
2 int y = 5;
3 super(10);
4 }
就会提示
java: call to super must be first statement in constructor
如果想要计数获得传入 A(int x) 构造函数的 x 值, 则必须调用一个静态方法
1 public B() {
2 super(buildX());
3 }
4
5 public static int buildX() { // buildX() 方法必须为静态
6 return 10;
7 }
因为假如 buildX() 是一个实例方法, 在调用构造函数 B() 时相应的实例都还不存在.
而这一特性是允许下面的语法
1class B extends A {
2 public B() {
3 int y = 5;
4 super(y);
5 }
6}
但想要在构造函数中调用自身的实例方法仍然不可行
1 public B() {
2 super(buildX());
3 }
4
5 public int buildX() {
6 return 10;
7 }
java: cannot reference buildX() before supertype constructor has been called
道理还是一样的, 在调用 B() 时, 它的实例还不存在.
子构造函数在调用父构造时 super(values) 不能放在条件语句, 必须明确是谁.
其实不光调用 super(values) 方法, this(values) 也适用该新规则
1// Java 22 之前
2class B {
3 public B() {
4 int x = 10;
5 this("" + x); // 报错: java: call to this must be first statement in constructor
6 }
7
8 public B(String s) {
9 }
10}
1// Java 22 开始
2class B {
3 public B() {
4 int x = 10;
5 this("" + x); // 这是合法的
6 }
7
8 public B(String s) {
9 }
10}
JEP 456: Unnamed Variables & Patterns
_ 一直以来只是一个普通的变量名, 如
1int _ = 10;
但是 _ 在 Java 22 开始某些时候赋予了新的隐式约定, 当然它依然可以作为普通变量来使用. 比如有时候必须有命名变量, 但无需使用的时候

IntelliJ IDEA 会提示命名为 ignored 来避免该提示
在 Java 8 的 for 循环中还能用 _ 作为变量名

但到了 _ 变成了一定含义的保留字, for(String _: orders) 在 Java 9 中就不合法了, 错误信息是
java: as of release 9, '_' is a keyword, and may not be used as an identifier
在该 JEP 456 特性之下, 也不用写成 ignore 了, 只要改成
1 for (String _ : orders) {
2 total++;
3 //System.out.println(_); // underscore not allowed here
4 }
这里的 _ 不仅仅是有 ignore 的含义, 而且并确禁止对 _ 的访问, 所谓是彻底 Ignore.
所以还要回过头来看 int _ = 10, 其实它已不是 Java 8 及之前的 _ 了, 因为无法通过 _ 来访问了, 所以有下面的错误
1 int _ = 10;
2 System.out.println(_); // 错误: underscore not allowed here
还有其他很多时候的 unused 都可以使用 _, 比如
1List<String> list = new ArrayList<>();
2boolean _ = list.add("Hello");
3String _ = list.get(0); // _ 已经不是一个普通变量了, 这里没有 _ 重复定义错误
4
5try (var _ = driverManager.getConnection("url")) {
6 System.out.println("database is available");
7} catch (Exception _) {
8}
9
10if(obj instanceof Point(int _, int y)) {
11 System.out.println("It's a point with y = " + y);
12}
13
14switch (obj) {
15 case Point(int x, int _):
16 System.out.println("It's a point with x = " + x);
17 case null:
18 System.out.println("It's null");
19}
JEP 457: Class-File API (Preview)
这一特性让我们更容易解析生成的 class 文件, 给 Java 反编译工具, 和 ASM 相关库创造了便利, 像 ASM, BCEL, 和 Javassist.
由于 Java 每 6 个月的发布周期, 类文件格式可能也变化太快, 第三方的 ASM 工具怕是难以跟上步伐, 所以 Java 自己发布一套 Class-File API. 这也是像 JVM TI(Tool Interface) 一样是给第三方工具用的, 这里不展开研究.
JEP 458: Launch Multi-File Source-Code Programs
在正式的使用了 Maven 或其他构建/依赖管理的项目, 这一特性不会用到. 这也是让 Java 本身进一步脚本化执行更简单. 它的作用是让 Java
在执行源文件时自动找到相关的源文件进行编译, 如下两个文件
1// Prog.java
2class Prog {
3 public static void main(String[] args) {
4 Helper.run();
5 }
6}
1// Helper.java
2class Helper {
3 static void run() {
4 System.out.println("Hello!");
5 }
6}
不需 Prod 和 Helper 写在同一个文件中, 只用
1java Prog.java
Java 就能分析 Prog.java 中的引用, 找到文件 Helper.java, 在内存中编译 Prog.java 和 Helper.java 并执行.
还有一种更聪明的 ---class-path 写法, 假如当前目录下的结构是
1.
2├── Helper.java
3├── Prog.java
4└── libs
5 ├── library1.jar
6 └── library2.jar
执行命令
1java --class-path 'libs/*' Prog.java
不仅能在当前目录中找到 Helper.java, --class-path 'libs/*' 会把 libs/ 中所有的 JAR 文件加入到 classpath 下.
搜索源文件也遵循相同的 package 规则, 假如 Helper.java 的代码是
1package pkg;
2class Helper {
3 static void run() {
4 System.out.println("Hello!");
5 }
6}
则应把 Helper.java 源文件放到 pkg 目录下.
JEP 461: Stream Gatherers (Preview)
最后初步学习一下 Stream Gatherers, 它将在 JDK 24 中转正.
Java 觉得目前 Stream 存在的那些中间操作方法(Intermediate Operations) 还不足以满足某些需求, 也不够灵活. 例如 Stream 提供了基于 Object
整体的去重 distinct() 方法, 但无法基于某一属性去重, 所以先前研究过曲线解决方式 Java 8 根据属性值对列表去重.
在该 JEP 中举的例子是
1var result = Stream.of("foo", "bar", "baz", "quux")
2 .distinctBy(String::length) // 现在没有这个方法
3 .toList();
Java 对些的解决办法是, 类似于所有的 Stream 的 terminal operation 都可以用 collect/reduce 操作来实现; 同等的, 对于所有的
intermediate operation, 也应该有一个终极方法, 那就是 Stream::gather(Gatherer).
collect, reduce 在某些编程语言中叫做 fold 方法, 不明白为什么 Java 的 Stream 要同时有 collect 和 reduce, 相比
reduce 比 collect 更抽象一些.
java.util.stream.Gatherer 接口中定义了一些方法, 同时在 java.util.stream.Gatherers 中提供几个实现
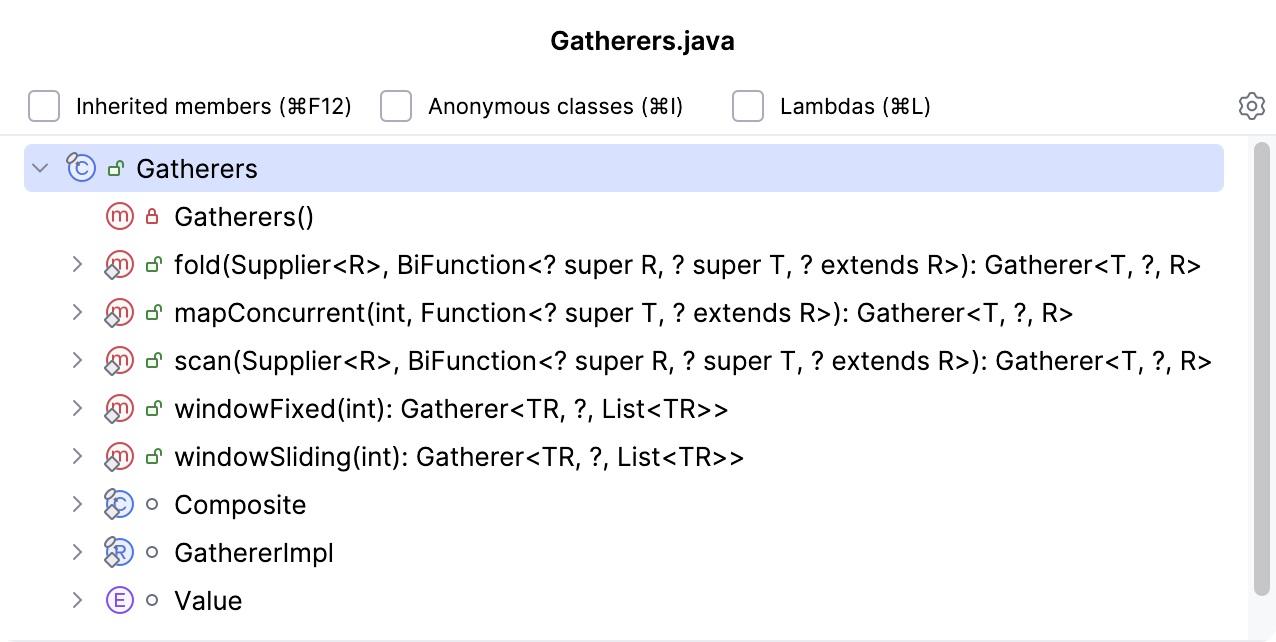
这下可好, 把类似于 Flink 中的固定, 滑动窗口等概念引进来了. 因为 gather 是万能的 intermediate 方法, 而 terminal 方法只能有一个,
所以任何 Stream 操作都可以用
1stream.gather(...).gather(...).gather(...).collect(...);
这里不详细解释 Stream Gatherers, 现在只看下如何用 gather 方法解决老问题 Java 8 根据属性值对列表去重.
1List<Book> uniqueBooks = books.stream()
2 .gather(Gatherers.fold(
3 () -> new HashMap<Integer, Book>(),
4 (map, book) -> {
5 map.putIfAbsent(book.id, book);
6 return map;
7 }
8 ))
9 .flatMap(map -> map.values().stream())
10 .toList();
也没感觉到更优雅, 还不如只用 filter, 借助一个外部 Set
1Set<Integer> uniqueIds = new HashSet<>();
2List<Book> uniqueBooks = books.stream().filter(book -> uniqueIds.add(book.id)).toList();
随着 filter 的操作, uniqueIds 中的内容也是动态, 这比当初 Java 8 根据属性值对列表去重
还要好的多.
这个具体问题, 或者从基础创建自己的 Gather 看起来很复杂, 但 Gather 接口和 Stream.gather() 势将第三方实现功能强大的 Gather 很大的便利,
例如将可能只需
1List<Book> uniqueBooks = book.stream.gather(gathers.distinctBy(Book::id)).toList();
其他的特性如 454: Foreign Function & Memory API 等着象 JNA, JNR-FFI 等第三方组件使用这一特性实现出更高效的 JNI 调用代码.
至于 Vector API, 不知道它将来如何与 Python 的 SciPy, NumPy 比, 灵活性肯定不好, 效果上 Python 的 Vector API 可是 C/C++ 实现的.
[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。