LangChain - 关于会话记忆
所谓大语言模型的记忆功能,就是要在说当前这句话的时候让 LLM 知道整个对话的上下文。比如说与人对话
- A: 给我讲个笑话
- B: 有一天,有人问你:“你喜欢什么?”, 你回答:“我喜欢一切……只要不叫‘考试’。” 😄 够快,够短,有没有让你会心一笑?
- A: 再来一个
- B: 问:海里面最怕什么? 答:脱水。
#3 当 A 问 "再来一个" 时候,B 因为有基于前面对话的上下文,所以能理解 "再来一个" 来一个笑话,而不是一个妞什么的,也记得曾经讲过一个笑话,而不 至于重复之前的笑话。如果突然有一天 A 对 B 突兀的说 "再来一个",B 就会有些傻眼了,AI 在没有上下文的情况也是一样。
不过人与人之间对话的上下文是互相的,两方的共同记忆,双方都是建立在你知道我问了什么,你自己回复了什么的基础之上的。而于大语言模型的对话时, 大语言模型是没有记忆的,就好像和一个失忆的人对话一样,记忆责任全在一方,你和 LLM 每一次对话时都要不停的唠叨:
我曾经问了这个,你回复过那个,问过这个,你回复过那个......,我现在问一个问题,请基于我们的会话历史作出回答
和机器对话就是这么傻傻的,当对话历史过大的时候因为上下文大小限制的原因,就必须压缩总结之前的对话内容,压缩后总会失真,这就是为什么大语言模型会 不断降智的一个原因。
当然在我们实现一个 Agent 的记忆功能时,许多事情由框架来自动完成,比如拼接历史会话,更长期的记忆可以用文件保留下来,会话自动压缩,多人使用一个 Agent 时进行用户会话的隔离等等.
Ollama API 调用的记忆
下面是一个使用 Ollama 的 /api/chat API 时实现会话记忆的情形, 使用的模型为 gemma4:e4b
第一次请求
1{
2 "model": "gemma4:e4b",
3 "messages": [
4 {"role": "user", "content": "tell me a joke"}
5 ]
6}
收到 LLM 一个个 {"role": "assistant", "content": "<token>"} 组成的完整回复为
Why don't scientists trust atoms? ⚛\n\nBecause they make up everything! 😂
发第二次请求想要 LLM 知道会话历史的话就必须把 LLM 的回复拼接起,再发起新的问话
1{
2 "model": "gemma4:e4b",
3 "messages": [
4 {"role": "user", "content": "tell me a joke"},
5 {"role": "assistant", "content": "Why don't scientists trust atoms? ⚛\n\nBecause they make up *everything*! 😂"},
6 {"role": "user", "content": "another one?"}
7 ]
8}
用会话历史的话,LLM 在收到 "another one?" 就不会感到蒙圈 "what?",能明白你想要听另一个笑话,并且也不会重复之前的笑话,作出新的回复
Why did they banana put on sunscreen? 🍌 😎\n\nBecause it was going to peel! 😂
简单 LangChain 记忆
在使用 LangChain 实现 Agent 时也可以手工来实现会话历史
1from langchain.agents import create_agent
2
3agent = create_agent(
4 model="ollama:gemma4:e4b", # 使用 ollama 模型,base_url 默认为 http://localhost:11434
5)
6
7message_history = [{"role": "user", "content": "tell me a joke"}] # 第一个问题
8
9results = agent.invoke({
10 "messages": message_history
11})
12
13messages = results["messages"]
14
15reply = results["messages"][-1].content # 最后一个消息是 LLM 的回复
16print(f"LLM says: \n{reply}")
17
18print("-----------------------------\n")
19
20message_history.append({"role": "assistant", "content": reply}) # 把 LLM 回复加到会话历史
21
22message_history.append({"role": "user", "content": "another one"}) # 新的问题
23results = agent.invoke({
24 "messages": message_history # 包含所有会话历史,LLM 会基于历史会话在对最后一个问题作出回复
25})
26print(f"LLM says: \n{results["messages"][-1].content}")
输出如下:
1LLM says:
2Why don't scientists trust atoms? ⚛️
3
4Because they make up *everything*! 😂
5-----------------------------
6
7LLM says:
8What do you call a fake noodle?
9
10An impasta! 🍝😂
如果第二次不带上会话历史,只是简单的
1results = agent.invoke({
2 "messages": [{"role": "user", "content": "another one"}]
3})
那么 LLM 看到这个就不知措了,不得不对你进行追问你到底想干什么
1LLM says:
2Why don't scientists trust atoms?
3
4...Because they make up everything! 🧑🔬😂
5-----------------------------
6
7LLM says:
8You want another one! I'm ready. 🚀
9
10But "another one" of what? 😂
11
12Tell me what kind of "one" you're looking for, and I'll deliver:
13
141. **A joke** (Why did the scarecrow win an award?)
152. **A random fact** (You might not know this one...)
163. **A short story prompt** (Give me a genre!)
174. **A philosophical thought experiment** (Let's get deep...)
185. **Just a fun, wild guessing game?**
19
20Let me know what you're in the mood for! 👇
AI 只会对最后一个 role 为 user 的问题作出回答,所以每次把 LLM 的回复添加到消息历史,再问新的问题。其实 LangChain agent.invoke()
的结果中就包含了会话历史。我们断点查看第二次 agent.invoke() 产生的 results
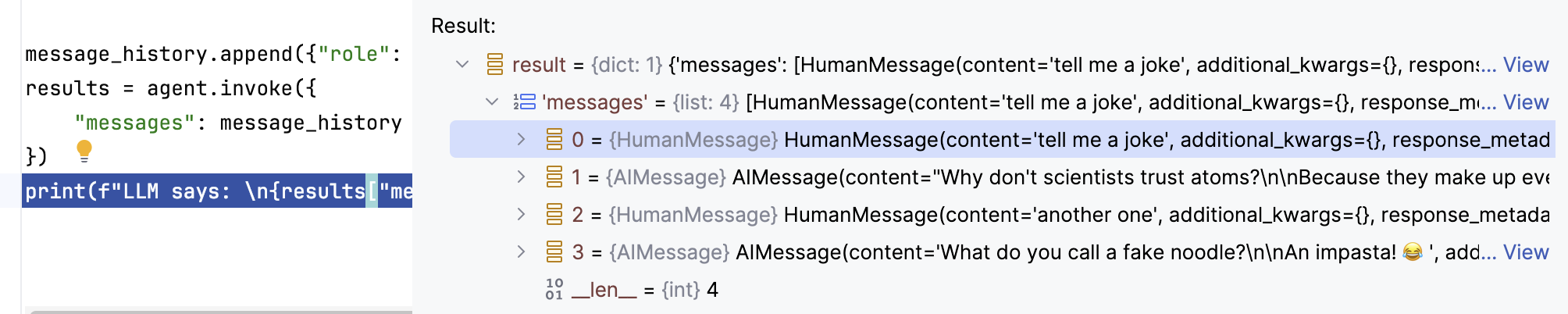
只不过 LangChain 把消息都包装为对应的 HumanMessage(role 为 user), AIMessage(role 为 assistant), 基于 agent.invoke()
会返回会话历史,我们可对前面的代码进一步简化如下
1from langchain.agents import create_agent
2from langchain_core.messages import HumanMessage
3
4agent = create_agent(
5 model="ollama:gemma4:e4b",
6)
7
8message_history = agent.invoke({
9 "messages": [{"role": "user", "content": "tell me a joke"}]
10})
11
12reply = message_history["messages"][-1].content
13print(f"LLM says: \n{reply}")
14
15print("-----------------------------\n")
16
17message_history["messages"].append(HumanMessage("another one")) # 新的问题
18results = agent.invoke(message_history)
19
20print(f"LLM says: \n{results["messages"][-1].content}")
我们同样可通过返回的 results 观察整个会话上下文,不带上下文的问第二个问 another one, 大语言模型便不知如何作答,第二次 results 返回
值当中就只有 HumanMessage 和 AIMessage 两个元素。
agent.invoke() 可接受的参数格式有两种
{"messages": list[{"role":"system|user|assistant", "content":"blah blah"}]}{"messages": list[? extends BaseMessage ]]
用 InMemorySaver 实现记忆管理
使用 LangChain 内置的机制可以实现更简单的记忆功能,其中之一就是 InMemorySaver, 在创建 agent 时指定为 checkpointer. 使用了
checkpointer 的话必须指定会话的 thread_id 同时实现会话隔离,所以 LangChain 的记忆与会话隔离是同时具备的。
现在具有记忆与会话隔离的代码演变为如下
1from langchain.agents import create_agent
2from langchain_core.runnables import RunnableConfig
3from langgraph.checkpoint.memory import InMemorySaver
4
5checkpointer = InMemorySaver()
6
7agent = create_agent(
8 model="ollama:gemma4:e4b",
9 checkpointer=checkpointer,
10)
11
12config1: RunnableConfig = {"configurable": {"thread_id": "1"}}
13
14results = agent.invoke({"messages": [{"role": "user", "content": "tell me a joke"}]}, config=config1)
15
16print(f"LLM says: \n{results['messages'][-1].content}")
17
18print("-----------------------------\n")
19
20results = agent.invoke({"messages": [{"role": "user", "content": "another none"}]}, config=config1)
21
22print(f"LLM says: \n{results["messages"][-1].content}")
关键代码就是上面高亮显示的行
- 创建 agent 时指定
checkpointer,用它来维护记忆 agent.invoke()与大语言模型交互时,指定config来使用哪个会话thread_id指定一个维一的字符串作为会话标识, 实际应用中可以用 uuid 作为 thread_id, 或加入易识别的标识
如果为 agent 指定了 checkpointer, 但 agent.invoke() 时未指定 config 则会报错
Checkpointer requires one or more of the following 'configurable' keys: thread_id, checkpoint_ns, checkpoint_id
观察第二次 agent.invoke() 调用返回的 results, 其中有所有的会话历史。如果再创建一个新的 config2, agent.invoke() 时指定新的 config
1config2: RunnableConfig = {"configurable": {"thread_id": str(uuid4())}}
2results = agent.invoke({"messages": [{"role": "user", "content": "tell me a joke"}]}, config=config2)
这样就实现了使用一个 agent 时多个会话互不相干,各自维护自己的历史。
有点好奇 checkpointer 中的数据是如何保存的,InMemorySaver 保存对象是用 msgpack 序列化,它以下几个属性 blobs, storage,
writes, 记录信息的时候用 thread_id 作为 key,这样就实现了会话的隔离。在 writes 中可以看到完整的会话历史,用代码把它反序列化出来
1from langgraph.checkpoint.serde.encrypted import JsonPlusSerializer
2ser = JsonPlusSerializer()
3
4for item1 in checkpointer.writes.values():
5 for item2 in item1.values():
6 x1, x2, x3, x4 = item2
7 if x2 != "messages":
8 print(x2, x3, x4)
9 else:
10 print(x2, ser.loads_typed(("msgpack", x3[1])), x4)
打印出来的信息是
1messages [{'role': 'user', 'content': 'tell me a joke'}] ~__pregel_pull, __start__
2branch:to:model ('null', b'') ~__pregel_pull, __start__
3messages [AIMessage(content="Why don't scientists trust atoms? ⚛️\n\nBecause they make up everything! 😂", additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-04-10T19:59:56.359596Z', 'done': True, 'done_reason': 'stop', 'total_duration': 762359541, 'load_duration': 163254333, 'prompt_eval_count': 19, 'prompt_eval_duration': 35819250, 'eval_count': 20, 'eval_duration': 548230418, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019d78fa-ccca-7a02-b33b-b67a1592952d-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 19, 'output_tokens': 20, 'total_tokens': 39})] ~__pregel_pull, model
4messages [{'role': 'user', 'content': 'another none'}] ~__pregel_pull, __start__
5branch:to:model ('null', b'') ~__pregel_pull, __start__
6messages [AIMessage(content='What do you call a fake noodle?\n\nAn impasta! 😂', additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-04-10T20:00:02.003681Z', 'done': True, 'done_reason': 'stop', 'total_duration': 5633974500, 'load_duration': 133030542, 'prompt_eval_count': 50, 'prompt_eval_duration': 95878417, 'eval_count': 186, 'eval_duration': 5347657499, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019d78fa-cfcf-7072-8cb0-ad38efc58052-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 50, 'output_tokens': 186, 'total_tokens': 236})] ~__pregel_pull, model从探索 InMemorySever 的过程中发现构建 InMemorySever 实例时可指定它的 serd 序列化反序列化器,LangGraph 目前提供了
JsonPlusSerializer, EncryptedSerializer, 和 SerializerCompat, 默认为 JsonPlusSerializer,针对对象优先采用 msgpack
的序列方式,失败都用 pickle 序列化方式, 对于 bytes, byteArray 类型直接存储字节。
再继续学下去发现有更简单的读取 Checkpointer 中的内容,它有 list(config) 和 get(config) 两个方法,可以方便的读取和获取记忆体中的内容。
1for message in checkpointer.get(config1)["channel_values"]["messages"]:
2 print(f"{message.type}: {message.content}")
打印出
1human: tell me a joke
2ai: Why don't scientists trust atoms?
3
4Because they make up *everything*! 🤣
5human: another none
6ai: Why did the teddy bear say no to dessert?
7
8Because she was stuffed! 🧸
其他保存记忆的方式
LangChain 除了内置的 InMemorySever 外,查看它父类 BaseCheckpointSaver 的所有子类只有 InMemorySever 一个,要用其他方式的记忆,
如文件系统,各种数据库,或 Redis 存储还得第三方库支持。像 PostgresSaver 需安装 langgraph-checkpoint-postgres 库。
安装 langgraph-checkpoint-postgres 后,多出了好几个与 Postgres 相关的 CheckpointSaver
1BaseCheckpointSaver
2└── BasePostgresSaver
3 ├── AsyncPostgresSaver
4 ├── AsyncShallowPostgresSaver
5 ├── PostgresSaver
6 └── ShallowPostgresSaver
如果我们在 PyPi 上搜索 langgraph-checkpoint- 能找到许多的 CheckpointSaver 实现,
https://pypi.org/search/?q=langgraph-checkpoint-&o=, 存储方式有
duckdb, dynamodb, s3, mongodb, redis 等,总有一款能符合你的要求。
其他记忆体如何使用就没必要用代码进行演示,只要照着 InMemorySever 的方式和参考不同记忆体的说明文档做就行。
记忆的数据太多的话,需要对记忆进行压缩,这是后面的话题了, 会涉及到 LangGraph 的 StateGraph 的内容。
[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。