LangChain 核心组件之 Streaming
一接触 LangChain 就有种停不下来的感觉,在 Deep Agents 与底层的 LangGraph 之间,还是想把 LangChain 的核心组件搞明白一些,
本文是学习 Streaming 的笔记。Streaming 给人的第一印象就是用 ChatGPT 聊天时机器回复时是一个字一个字蹦出来的,因为这就是 LLM
的思维方式,不断的预测下一个 Token.
有个疑问: 这种预测下一个 Token 方式, 中国产的 LLM 放到 Ollama 中运行是怎么实现的过滤敏感词的呢?
前端一个字一个字蹦出来的效果反应到后台 API 响应(以 Ollama 为例)格式是 Content-Type 为 application/x-ndjson,这种格式是 Newline Delimited JSON,即每行是一个 JSON 对象,以 \n 分隔, Transfer-Encoding 为 chunked,表示数据是以分块传输的,所以客户端只要一个个
Chunk 的输出就是那种效果了。
从 LLM 的那种流式(Chunk)输出也能体会出 Markdown 在逐字显示内容时的优势,自上而下,自然而然的清晰结构。
下面是 LangChain 中使用 ChatOllama 模型时,服务端响应数据的片断:
1200 OK
2Content-Type: application/x-ndjson
3Date: Mon, 04 May 2026 15:18:47 GMT
4Transfer-Encoding: chunked
5
6{"model":"gemma4:e4b","created_at":"2026-05-04T15:18:47.383768Z","message":{"role":"assistant","content":"I"},"done":false}
7{"model":"gemma4:e4b","created_at":"2026-05-04T15:18:47.412273Z","message":{"role":"assistant","content":" am"},"done":false}
8{"model":"gemma4:e4b","created_at":"2026-05-04T15:18:47.440783Z","message":{"role":"assistant","content":" functioning"},"done":false}
9{"model":"gemma4:e4b","created_at":"2026-05-04T15:18:47.469007Z","message":{"role":"assistant","content":" well"},"done":false}
10{"model":"gemma4:e4b","created_at":"2026-05-04T15:18:47.497104Z","message":{"role":"assistant","content":"."},"done":false}
11......
12{"model":"gemma4:e4b","created_at":"2026-05-04T15:18:48.54203Z","message":{"role":"assistant","content":"?"},"done":false}
13{"model":"gemma4:e4b","created_at":"2026-05-04T15:18:48.569342Z","message":{"role":"assistant","content":""},"done":true,"done_reason":"stop","total_duration":1446175625,"load_duration":166441709,"prompt_eval_count":13,"prompt_eval_duration":92044166,"eval_count":44,"eval_duration":1170453663}
服务端在向客户输出一个个 Chunk 时一直保持着连接,直到 done 为 true 时才关闭连接。
LangChain 的流式输出不仅能逐字输出 LLM 实际回复的内容(对应 {"role": "assistant", "content": "..."}),还能以同样的方式输出推理的内容
(对应 {"role": "assistant", "thinking": "..."}). 同时通过 Custom Stream 输出定制的信息。
LangChain 支持三种 Stream 模式,分别是
updates: 反应出Agent的步骤变化(一条完整的AIMessage或ToolMessage), 如果一个步骤有多个更新(如多个节点同时运行), 每个更新的stream会分开来, 元素为messagemessages: 反应的是LLM逐Token 生成的过程, 对应于每一个Chunk(Token`)custom: 流式输出在节点中用Stream Writer自定义的输出
这是官方文档中的三种模式,从当前 LangGraph v1.1.6 的源代码看到有更多的 stream_mode, 见 langgraph/types.py.
其中定义了
1StreamMode = Literal[
2 "values", "updates", "checkpoints", "tasks", "debug", "messages", "custom"
3]
4"""How the stream method should emit outputs.
5
6- `"values"`: Emit all values in the state after each step, including interrupts.
7 When used with functional API, values are emitted once at the end of the workflow.
8- `"updates"`: Emit only the node or task names and updates returned by the nodes or tasks after each step.
9 If multiple updates are made in the same step (e.g. multiple nodes are run) then those updates are emitted separately.
10- `"custom"`: Emit custom data using from inside nodes or tasks using `StreamWriter`.
11- `"messages"`: Emit LLM messages token-by-token together with metadata for any LLM invocations inside nodes or tasks.
12- `"checkpoints"`: Emit an event when a checkpoint is created, in the same format as returned by `get_state()`.
13- `"tasks"`: Emit events when tasks start and finish, including their results and errors.
14- `"debug"`: Emit `"checkpoints"` and `"tasks"` events for debugging purposes.
15"""
下面逐个来看看以上文档中三种模式在实际应用中的效果,对了,还可以组合模式。
Agent 变化
Agent 变化是在一个完整的 AIMessage 或 ToolMessage 产生时才会输出的,对于 LLM 的回复(AIMessage)尽管后台回复的是一个个 Chunk, 当
stream_mode="updates" 时,只有等到收到最后一个 "done": true 时才标记 Agent 的一个步骤的完成,所以它会自动归纳所有 Chunk 中的
content. 即最终的 AI 响应,也包括工具调用的请求。
1from langchain.agents import create_agent
2
3
4def add(a: int, b: int) -> int:
5 """add two integer numbers"""
6 return a + b
7
8agent = create_agent(
9 model="ollama:gemma4:e4b",
10 tools=[add],
11)
12for chunk in agent.stream(
13 {"messages": [{"role": "user", "content": "What's 10+2?"}]},
14 stream_mode="updates",
15 version="v2",
16):
17 print(chunk)
agent.stream() 默认 version="v1", 异步版的 agent.astream() 默认 version="v2", 用 Ollama 测试时,v1, v2 没有明显的区别。
输出为三条 type: updates 的消息
1{'type': 'updates', 'ns': (), 'data': {'model': {'messages': [AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-05-04T16:23:16.993628Z', 'done': True, 'done_reason': 'stop', 'total_duration': 6105232792, 'load_duration': 203561167, 'prompt_eval_count': 76, 'prompt_eval_duration': 70995083, 'eval_count': 181, 'eval_duration': 5767783252, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019df3cc-fd24-74d3-b4b2-b29da4e00825-0', tool_calls=[{'name': 'add', 'args': {'a': 10, 'b': 2}, 'id': '14bbd137-2a09-45f2-83cd-e5921cb2a173', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 76, 'output_tokens': 181, 'total_tokens': 257})]}}}
2{'type': 'updates', 'ns': (), 'data': {'tools': {'messages': [ToolMessage(content='12', name='add', id='02089297-475c-4518-a014-045380cdc456', tool_call_id='14bbd137-2a09-45f2-83cd-e5921cb2a173')]}}}
3{'type': 'updates', 'ns': (), 'data': {'model': {'messages': [AIMessage(content='12', additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-05-04T16:23:17.314667Z', 'done': True, 'done_reason': 'stop', 'total_duration': 292374667, 'load_duration': 142867292, 'prompt_eval_count': 104, 'prompt_eval_duration': 93115000, 'eval_count': 3, 'eval_duration': 53809834, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019df3cd-151a-7272-abd5-3dc557c3c7a0-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 104, 'output_tokens': 3, 'total_tokens': 107})]}}}虽然后台 Ollama 服务的 HTTP 响应是一个个 Chunk, 但用 stream_mode="updates" 的方式,Langchain 将这些 Chunk 组合起来,
形成一个完整的 AIMessage.
没有指定 stream_mode 的话,默认为 updates. agent.stream() 时 stream_mode 的默认值为 updates, 在 CompiledStateGraph()
时设定的 stream_mode="updates.
stream_mode="values" 时
只改 stream_mode 为 values, 测试
1for message in agent.stream(
2 {"messages": [{"role": "user", "content": "What's 10+2?"}]},
3 version="v2",
4 stream_mode="values",
5):
6 print(message)
结果
1{'type': 'values', 'ns': (), 'data': {'messages': [HumanMessage(content="What's 10+2?", additional_kwargs={}, response_metadata={}, id='8cbadc02-b32e-4f4e-aba7-ef5800152af7')]}, 'interrupts': ()}
2{'type': 'values', 'ns': (), 'data': {'messages': [HumanMessage(content="What's 10+2?", additional_kwargs={}, response_metadata={}, id='8cbadc02-b32e-4f4e-aba7-ef5800152af7'), AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-05-04T21:04:25.100463Z', 'done': True, 'done_reason': 'stop', 'total_duration': 11066013042, 'load_duration': 5773339458, 'prompt_eval_count': 76, 'prompt_eval_duration': 204762459, 'eval_count': 180, 'eval_duration': 4934645163, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019df4ce-4cd0-7203-947b-db700107e61b-0', tool_calls=[{'name': 'add', 'args': {'a': 10, 'b': 2}, 'id': 'aa88bc86-f9a9-48d9-8457-d174e2471d7a', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 76, 'output_tokens': 180, 'total_tokens': 256})]}, 'interrupts': ()}
3{'type': 'values', 'ns': (), 'data': {'messages': [HumanMessage(content="What's 10+2?", additional_kwargs={}, response_metadata={}, id='8cbadc02-b32e-4f4e-aba7-ef5800152af7'), AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-05-04T21:04:25.100463Z', 'done': True, 'done_reason': 'stop', 'total_duration': 11066013042, 'load_duration': 5773339458, 'prompt_eval_count': 76, 'prompt_eval_duration': 204762459, 'eval_count': 180, 'eval_duration': 4934645163, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019df4ce-4cd0-7203-947b-db700107e61b-0', tool_calls=[{'name': 'add', 'args': {'a': 10, 'b': 2}, 'id': 'aa88bc86-f9a9-48d9-8457-d174e2471d7a', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 76, 'output_tokens': 180, 'total_tokens': 256}), ToolMessage(content='12', name='add', id='13b31d7d-b61f-4919-9835-ea140ef6fb86', tool_call_id='aa88bc86-f9a9-48d9-8457-d174e2471d7a')]}, 'interrupts': ()}
4{'type': 'values', 'ns': (), 'data': {'messages': [HumanMessage(content="What's 10+2?", additional_kwargs={}, response_metadata={}, id='8cbadc02-b32e-4f4e-aba7-ef5800152af7'), AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-05-04T21:04:25.100463Z', 'done': True, 'done_reason': 'stop', 'total_duration': 11066013042, 'load_duration': 5773339458, 'prompt_eval_count': 76, 'prompt_eval_duration': 204762459, 'eval_count': 180, 'eval_duration': 4934645163, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019df4ce-4cd0-7203-947b-db700107e61b-0', tool_calls=[{'name': 'add', 'args': {'a': 10, 'b': 2}, 'id': 'aa88bc86-f9a9-48d9-8457-d174e2471d7a', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 76, 'output_tokens': 180, 'total_tokens': 256}), ToolMessage(content='12', name='add', id='13b31d7d-b61f-4919-9835-ea140ef6fb86', tool_call_id='aa88bc86-f9a9-48d9-8457-d174e2471d7a'), AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-05-04T21:04:25.352982Z', 'done': True, 'done_reason': 'stop', 'total_duration': 236052458, 'load_duration': 147416417, 'prompt_eval_count': 104, 'prompt_eval_duration': 87037625, 'eval_count': 1, 'eval_duration': None, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019df4ce-781b-7621-9c5e-35959db88d0a-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 104, 'output_tokens': 1, 'total_tokens': 105})]}, 'interrupts': ()}
每一条消息都包含各自所在时刻完整的会话交互,就是 agent.invoke() 的返回值一样。
LLM tokens (节点变化)
当 stream_mode="messages" 时反应的是 LLM 生成的一个个 Token, 即对应于 Chunk. 除了 stream_mode 例子稍微修改了一下, 工具为
add 的话,LLM 可能会自作主张不调用该工具
1from langchain.chat_models import init_chat_model
2from langchain.agents import create_agent
3
4
5def get_weather(city: str) -> str:
6 """Get weather for a given city."""
7
8 return f"It's always sunny in {city}!"
9
10model = init_chat_model(
11 model="ollama:gemma4:e4b",
12 reasoning=True,
13)
14
15agent = create_agent(
16 model=model,
17 tools=[get_weather],
18)
19
20for chunk in agent.stream(
21 {"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
22 stream_mode="messages",
23 version="v2",
24):
25 print(chunk)
输出
1{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={'reasoning_content': '1'}, response_metadata={}, id='lc_run--019df3df-07aa-7b43-bbe2-c56383b669d2', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
2{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={'reasoning_content': '.'}, response_metadata={}, id='lc_run--019df3df-07aa-7b43-bbe2-c56383b669d2', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
3{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={'reasoning_content': ' **'}, response_metadata={}, id='lc_run--019df3df-07aa-7b43-bbe2-c56383b669d2', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
4{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={'reasoning_content': 'Analyze'}, response_metadata={}, id='lc_run--019df3df-07aa-7b43-bbe2-c56383b669d2', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
5...... 省略了一大段的 reasoning_content
6{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={'reasoning_content': ' call'}, response_metadata={}, id='lc_run--019df3df-07aa-7b43-bbe2-c56383b669d2', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
7{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={'reasoning_content': '.'}, response_metadata={}, id='lc_run--019df3df-07aa-7b43-bbe2-c56383b669d2', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
8{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-07aa-7b43-bbe2-c56383b669d2', tool_calls=[{'name': 'get_weather', 'args': {'city': 'SF'}, 'id': '15114261-04ac-4020-9703-6f8078927a2e', 'type': 'tool_call'}], invalid_tool_calls=[], tool_call_chunks=[{'name': 'get_weather', 'args': '{"city": "SF"}', 'id': '15114261-04ac-4020-9703-6f8078927a2e', 'index': None, 'type': 'tool_call_chunk'}]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
9{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-05-04T16:42:58.127615Z', 'done': True, 'done_reason': 'stop', 'total_duration': 4897810583, 'load_duration': 155401292, 'prompt_eval_count': 67, 'prompt_eval_duration': 35975250, 'eval_count': 165, 'eval_duration': 4659651753, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019df3df-07aa-7b43-bbe2-c56383b669d2', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 67, 'output_tokens': 165, 'total_tokens': 232}, tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
10{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-07aa-7b43-bbe2-c56383b669d2', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[], chunk_position='last'), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
11{'type': 'messages', 'ns': (), 'data': (ToolMessage(content="It's always sunny in SF!", name='get_weather', id='6d7b25bb-7aa0-4172-a16b-3760531067b4', tool_call_id='15114261-04ac-4020-9703-6f8078927a2e'), {'ls_integration': 'langchain_create_agent', 'langgraph_step': 2, 'langgraph_node': 'tools', 'langgraph_triggers': ('__pregel_push',), 'langgraph_path': ('__pregel_push', 0, False), 'langgraph_checkpoint_ns': 'tools:b79a1d4b-6951-edd3-2f0a-153793e30212'})}
12{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='The', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-1adc-7b30-aa5f-170dbe6d1f12', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 3, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
13{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content=' weather', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-1adc-7b30-aa5f-170dbe6d1f12', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 3, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
14{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content=' in', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-1adc-7b30-aa5f-170dbe6d1f12', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 3, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
15{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content=' SF', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-1adc-7b30-aa5f-170dbe6d1f12', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 3, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
16{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content=' is', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-1adc-7b30-aa5f-170dbe6d1f12', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 3, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
17{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content=' always', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-1adc-7b30-aa5f-170dbe6d1f12', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 3, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
18{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content=' sunny', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-1adc-7b30-aa5f-170dbe6d1f12', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 3, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
19{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='!', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-1adc-7b30-aa5f-170dbe6d1f12', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 3, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
20{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-05-04T16:42:58.673167Z', 'done': True, 'done_reason': 'stop', 'total_duration': 530299458, 'load_duration': 130517375, 'prompt_eval_count': 251, 'prompt_eval_duration': 135549875, 'eval_count': 9, 'eval_duration': 259347708, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019df3df-1adc-7b30-aa5f-170dbe6d1f12', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 251, 'output_tokens': 9, 'total_tokens': 260}, tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 3, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
21{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={}, response_metadata={}, id='lc_run--019df3df-1adc-7b30-aa5f-170dbe6d1f12', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[], chunk_position='last'), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 3, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'checkpoint_ns': 'model:46809faa-95fb-8adb-4a97-5115313de43f', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}在 init_chat_model() 时设置了 reasoning=True, 所以这里会有大量的推理的内容, 像
(AIMessageChunk(content='', additional_kwargs={'reasoning_content': 'Analyze'}, ...
如果没有设置 reasoning 参数,Ollama 也会进行推理,但 LangChain 不显示实际的推理内容,上面仍然会有每一个推理对应的 AIMessageChunk
条目,但其中的 additional_kwargs 为空,这时候会产生大量的
(AIMessageChunk(content='', additional_kwargs={}, ...
把 reasonsing 参数设置为 Fasle 的话会关掉 Ollama 的推理功能,当然也就没有对应推理的 AIMessageChunk 了。
模型指示客户端如何调用工具的消息放在同一个 AIMessageChunk 中,上面的第九行,调用工具完回复的是 ToolMessage。从最后几行 AIMessageChunk
中可以拼凑出 LLM 最终的回复
The weather in SF is always sunny!
stream_mode="custom" 时
要在 Stream 中获得 Tool 中状态更新,要用到 custom 模式。仅仅修改上面的 stream_mode 为 stream_mode="custom",再执行发现 for
循环中没有任何输出了,因为它用来输出工具调用中的状态更新。
1from langchain.agents import create_agent
2from langgraph.config import get_stream_writer
3
4
5def get_weather(city: str) -> str:
6 """Get weather for a given city."""
7 writer = get_stream_writer()
8 # stream any arbitrary data
9 writer(f"Looking up data for city: {city}")
10 writer(f"Acquired data for city: {city}")
11 return f"It's always sunny in {city}!"
12
13agent = create_agent(
14 model="ollama:gemma4:e4b",
15 tools=[get_weather],
16)
17
18for chunk in agent.stream(
19 {"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
20 stream_mode="custom",
21 version="v2",
22):
23 print(type(chunk), ": ", chunk)
输出为
1<class 'dict'> : {'type': 'custom', 'ns': (), 'data': 'Looking up data for city: SF'}
2<class 'dict'> : {'type': 'custom', 'ns': (), 'data': 'Acquired data for city: SF'}
这里和 version="v1" 有区别,如果改成 version="v1", 输出变成了
1<class 'str'> : Looking up data for city: SF
2<class 'str'> : Acquired data for city: SF
输出了在工具函数中用 get_stream_writer 输出的状态更新。这看起来有点眼熟,就是在 MCP 工具函数中用 fastmcp.Context 输出状态更新。
1@mcp.tool()
2async def fetch(ctx: Context, url: str) -> str:
3 """fetch web string content by url"""
4 await ctx.report_progress(30, total=100, message=f"loading {url=}")
5 await asyncio.sleep(1)
6 await ctx.report_progress(65, total=100, message=f"loading {url=}")
7 await asyncio.sleep(1)
8 await ctx.report_progress(100, total=100, message=f"loaded {url=}")
9 return "I'm a cat"
多种 stream_mode 模式
注意到用了 stream_mode="custom" 之后只能输出工具函数中用 get_stream_writer() 输出的状态更新,但是没有别的了,如果同时要输出 LLM
和工具函数中的状态更新,可以用组合的方式
for chunk in agent.stream() 部分改为下面的代码
1for chunk in agent.stream(
2 {"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
3 stream_mode=["custom", "updates"],
4 version="v2",
5):
6 print(type(chunk), ": ", chunk)
这时候输出包含 custom 和 updates 两部分的内容了
1<class 'dict'> : {'type': 'updates', 'ns': (), 'data': {'model': {'messages': [AIMessage(content='', additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-05-04T19:25:02.986174Z', 'done': True, 'done_reason': 'stop', 'total_duration': 1829592334, 'load_duration': 155455959, 'prompt_eval_count': 67, 'prompt_eval_duration': 1273864500, 'eval_count': 15, 'eval_duration': 387603957, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019df473-7761-77c0-9563-9ec70cabbe1d-0', tool_calls=[{'name': 'get_weather', 'args': {'city': 'SF'}, 'id': '6a66ce74-a7b3-4595-84cf-707e2a20f4e7', 'type': 'tool_call'}], invalid_tool_calls=[], usage_metadata={'input_tokens': 67, 'output_tokens': 15, 'total_tokens': 82})]}}}
2<class 'dict'> : {'type': 'custom', 'ns': (), 'data': 'Looking up data for city: SF'}
3<class 'dict'> : {'type': 'custom', 'ns': (), 'data': 'Acquired data for city: SF'}
4<class 'dict'> : {'type': 'updates', 'ns': (), 'data': {'tools': {'messages': [ToolMessage(content="It's always sunny in SF!", name='get_weather', id='68807542-42ca-4d49-9f1a-adc17c5b581c', tool_call_id='6a66ce74-a7b3-4595-84cf-707e2a20f4e7')]}}}
5<class 'dict'> : {'type': 'updates', 'ns': (), 'data': {'model': {'messages': [AIMessage(content="It's always sunny in SF!", additional_kwargs={}, response_metadata={'model': 'gemma4:e4b', 'created_at': '2026-05-04T19:25:06.004734Z', 'done': True, 'done_reason': 'stop', 'total_duration': 3005997250, 'load_duration': 135092125, 'prompt_eval_count': 100, 'prompt_eval_duration': 87342000, 'eval_count': 102, 'eval_duration': 2753467791, 'logprobs': None, 'model_name': 'gemma4:e4b', 'model_provider': 'ollama'}, id='lc_run--019df473-7e95-7803-9f57-902b2fa28b43-0', tool_calls=[], invalid_tool_calls=[], usage_metadata={'input_tokens': 100, 'output_tokens': 102, 'total_tokens': 202})]}}}
stream_mode 中可以包含任意的 updates, messages, custom 组合,把 stream_mode 改成
1stream_mode=["custom", "updates", "messages"]
那么会包含所有的 type 为 custom, updates, messages 的输出了。
常见应用场景
流式输出推理 reasoning/thinking 的 Token
要能让 LangChain 捕获到 LLM 的 reasoning/thinking 的内容,要为 model 指定 reasoning=True, 不同 model 提供者有不同的设置方式,
参考具体的 ChatModel 实现。
使用 stream_mode="messages" 要逐 Token 输出 Thinking 内容也要根据实际的 AIMessageChunk 格式,如上面的
{'type': 'messages', 'ns': (), 'data': (AIMessageChunk(content='', additional_kwargs={'reasoning_content': 'Analyze'}, response_metadata={}, id='lc_run--019df3df-07aa-7b43-bbe2-c56383b669d2', tool_calls=[], invalid_tool_calls=[], tool_call_chunks=[]), {'ls_integration': 'langchain_chat_model', 'langgraph_step': 1, 'langgraph_node': 'model', 'langgraph_triggers': ('branch:to:model',), 'langgraph_path': ('__pregel_pull', 'model'), 'langgraph_checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'checkpoint_ns': 'model:260b4a47-62dc-9039-e13a-1ac8ca1a7807', 'ls_provider': 'ollama', 'ls_model_name': 'gemma4:e4b', 'ls_model_type': 'chat', 'ls_temperature': None})}
就是输出 additional_kwargs={'reasoning_content': 'Analyze'} 中的内容, 这个内容也在 AIMessageChunk.content_blocks 属性中,格式为
content_blocks=[{'type': 'reasoning', 'content': 'Analyze'}]
print(chunk) 看不到 content_blocks 属性。
要输出 Reasoning 内容,用代码
1for message, metadata in agent.stream(
2 {"messages": [{"role": "user", "content": "What is the weather in SF?"}]},
3 stream_mode="messages",
4):
5 if isinstance(message, AIMessageChunk):
6 if any(b["type"]=="reasoning" for b in message.content_blocks):
7 print(message.content_blocks[0]["reasoning"], end="")
version="v2" 时 agent.stream() 的内容/格式可能会不一样,要具体参考 ChatModel 的实现。
Streaming 之于工具调用
再回顾一下 stream_mode 分别为 updates, messages, 和 custom 时的消息格式
- "updates": 获得的一个个完整的
AIMessage或ToolMessage, - "messages": 获得的一个个
AIMessageChunk或ToolMessage(测试中没见到ToolMessageChunk), 一个AIMessageChunk中包含一个Token - "custom": 只获得的由工具函数中用
get_stream_writer()输出的状态更新
这里有几个特例,当 stream_mode="messages" 时,AIMessageChunk 为指示工具调用时不是一个 Token, AIMessageChunk.tool_call_chunks
有完整的方法调用名称与参数列表,并且从 Agent 回给模型的工具调用响应 ToolMessage.content_blocks 也是完整的。
Streaming 中使用 Human-in-the-loop
Human-in-the-loop 不在 Stream 模式下使用时要求多个 agent.invoke() 调用,使用模式为
1result = agent.invoke(...)
2
3if result.interrupts:
4 command = Command(resume={"decisions":[{"type": "approve"}]})
5
6agent.invoke(command)
每次 interrupt 之后都要回一个 Command, 然后再 agent.invoke(), 如果改成 Stream 模式,能不能代码中只写两次 agent.stream()
调用呢?
相同的话题在 Human-in-the-loop 一文中有学习过,见 Stream 方式使用 Human-in-the-loop
这次要模拟要依次确认两个工具调用的 Human-in-the-loop, 改造成递归调用,最后代码如下
1from langchain.agents import create_agent
2from langchain.agents.middleware import HumanInTheLoopMiddleware
3from langchain.chat_models import init_chat_model
4from langchain_core.messages import AIMessageChunk
5from langchain_core.runnables import RunnableConfig
6from langchain_core.tools import tool
7from langgraph.checkpoint.memory import InMemorySaver
8from langgraph.config import get_stream_writer
9from langgraph.prebuilt import ToolRuntime
10from langgraph.types import Command
11from pydantic import BaseModel
12
13from rich.console import Console
14from rich.markdown import Markdown
15from rich.live import Live
16from rich.prompt import Prompt
17
18console = Console()
19accumulated = ""
20live_markdown = Live(console=console, refresh_per_second=20)
21
22class Context(BaseModel):
23 user_id: str
24
25
26@tool
27def get_location(runtime: ToolRuntime[Context]) -> str:
28 """Get the user's location."""
29 writer = get_stream_writer()
30 user_id = runtime.context.user_id
31 result = {"Yanbin": "Chicago", "Noah": "New York"}.get(user_id, "Unknown")
32 writer(f"Tool: got {user_id}'s location: {result}")
33 return result
34
35
36@tool
37def get_weather(location: str) -> str:
38 """Get the weather in a given location."""
39 result = f"Tool: the temperature in {location} is 26 degrees Celsius, and sunny"
40 writer = get_stream_writer()
41 writer(f"Got weather for {location}: {result}")
42 return result
43
44
45model = init_chat_model(
46 model="ollama:gemma4:e4b",
47 reasoning=False,
48)
49
50agent = create_agent(
51 model=model,
52 tools=[get_location, get_weather],
53 middleware=[HumanInTheLoopMiddleware(
54 interrupt_on={
55 "get_location": True,
56 "get_weather": True,
57 })],
58 checkpointer=InMemorySaver(),
59 context_schema=Context,
60)
61
62config: RunnableConfig = {"configurable": {"thread_id": "1"}}
63
64
65
66def show_message(chunk):
67 if chunk["type"] == "messages" and isinstance((message := chunk["data"][0]), AIMessageChunk):
68 if not message.tool_calls:
69 # print(message.content, end="", flush=True)
70 global accumulated
71 accumulated += message.content
72 live_markdown.update(Markdown(accumulated))
73 if chunk["type"] == "custom":
74 print(chunk['data'], "\n")
75
76
77def resume_agent(interrupt) -> None:
78 command = Command(
79 resume={
80 "decisions": []
81 }
82 )
83
84 for review in interrupt.value["review_configs"]:
85 live_markdown.stop()
86 # option = input(f"{'\033[90m'}Execute '{review['action_name']}?', input 'yes' to approve: {'\033[0m'}")
87 option = Prompt.ask(f"[bold yellow]Execute '{review['action_name']}'?[/bold yellow] Input 'yes' to approve")
88 if option == "yes":
89 command.resume["decisions"].append({"type": "approve"})
90 else:
91 command.resume["decisions"].append({"type": "reject", "message": "User rejected the request."})
92
93 live_markdown.start()
94 invoke_model(command)
95
96
97def invoke_model(message):
98 for chunk in agent.stream(
99 message,
100 version="v2",
101 stream_mode=["messages", "updates", "custom"],
102 config=config,
103 context=Context(user_id="Yanbin"),
104 ):
105 show_message(chunk)
106
107 if chunk["type"] == "updates" and (interrupts := chunk["data"].get("__interrupt__")):
108 resume_agent(interrupts[0])
109
110
111if __name__ == "__main__":
112 live_markdown.start()
113 invoke_model({"messages": [
114 {
115 "role": "user",
116 "content": "How is the weather like in my location and what kind of outdoor activities are good for me"
117 }
118 ]})
119 live_markdown.stop()
用了 rich 库对模型输出进行实时 Markdown 渲染,需执行 uv add rich 安装该依赖
命令行下执行过程动画
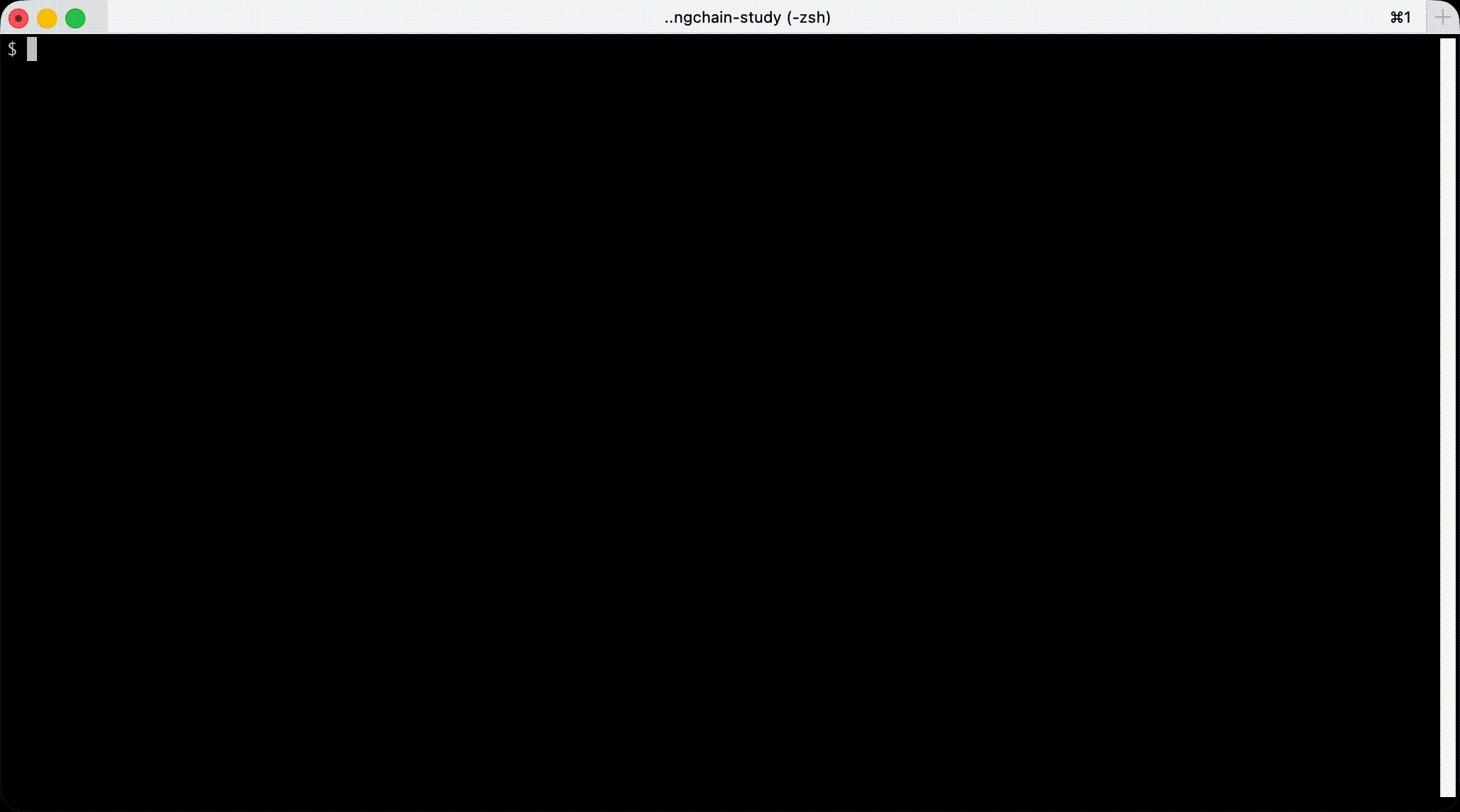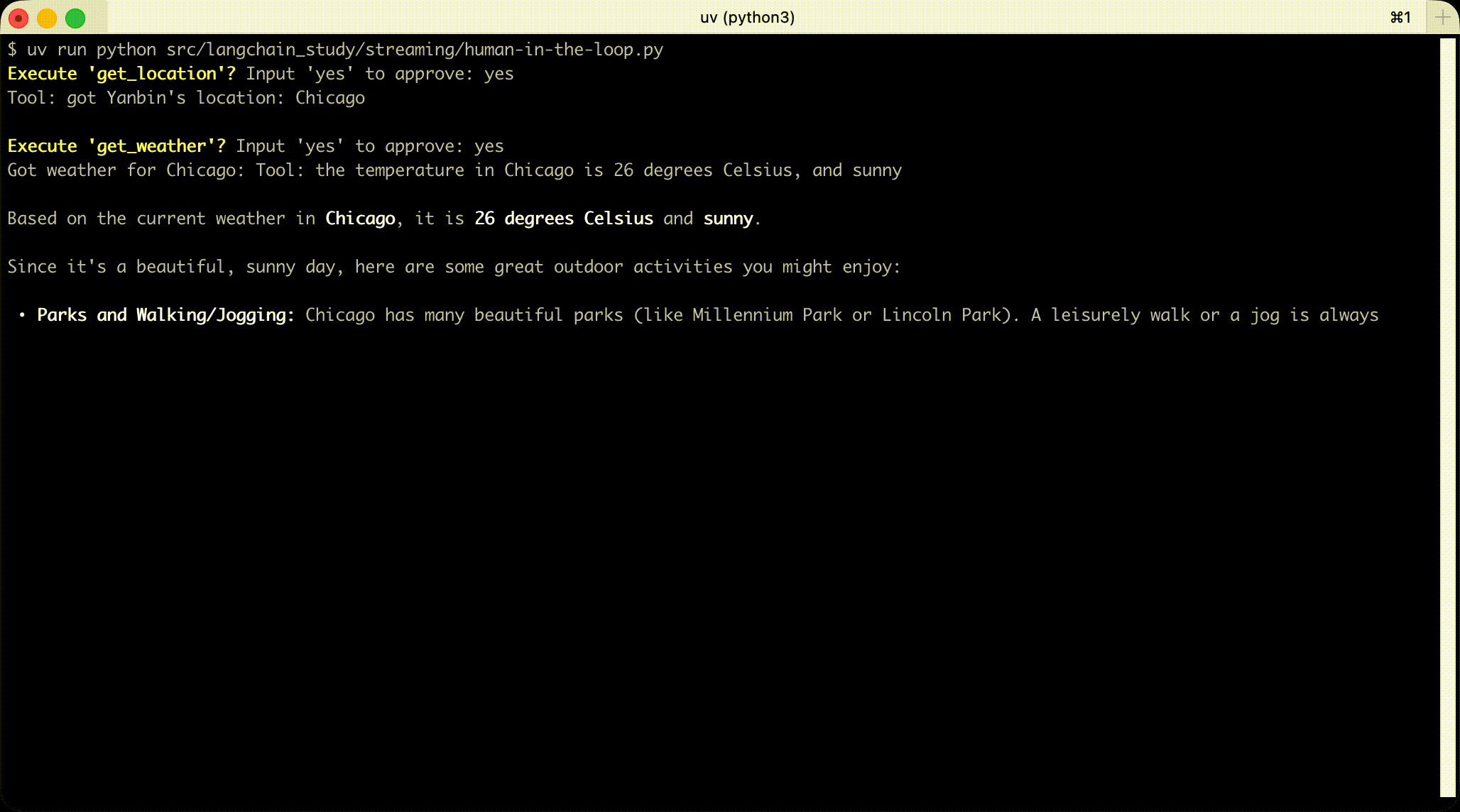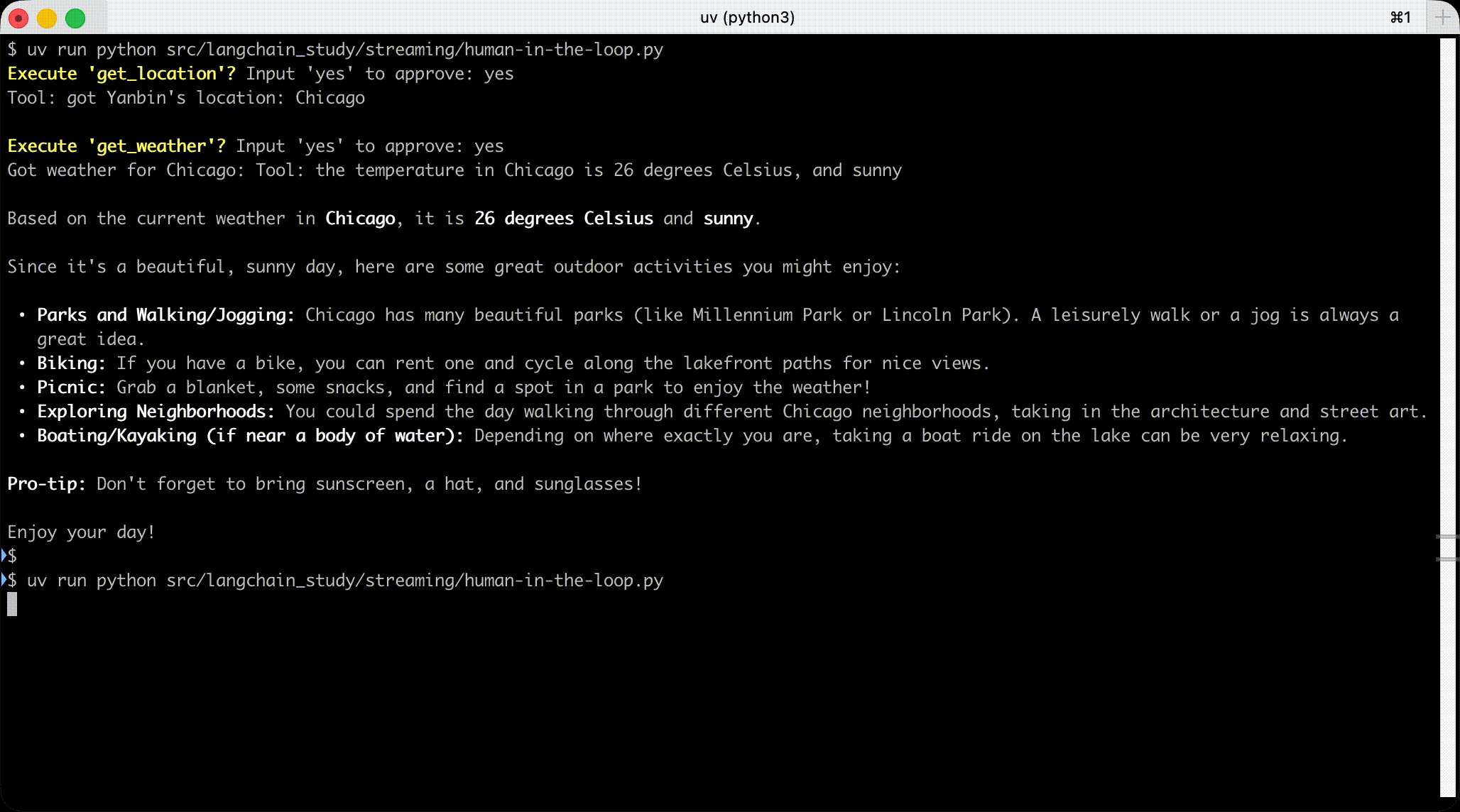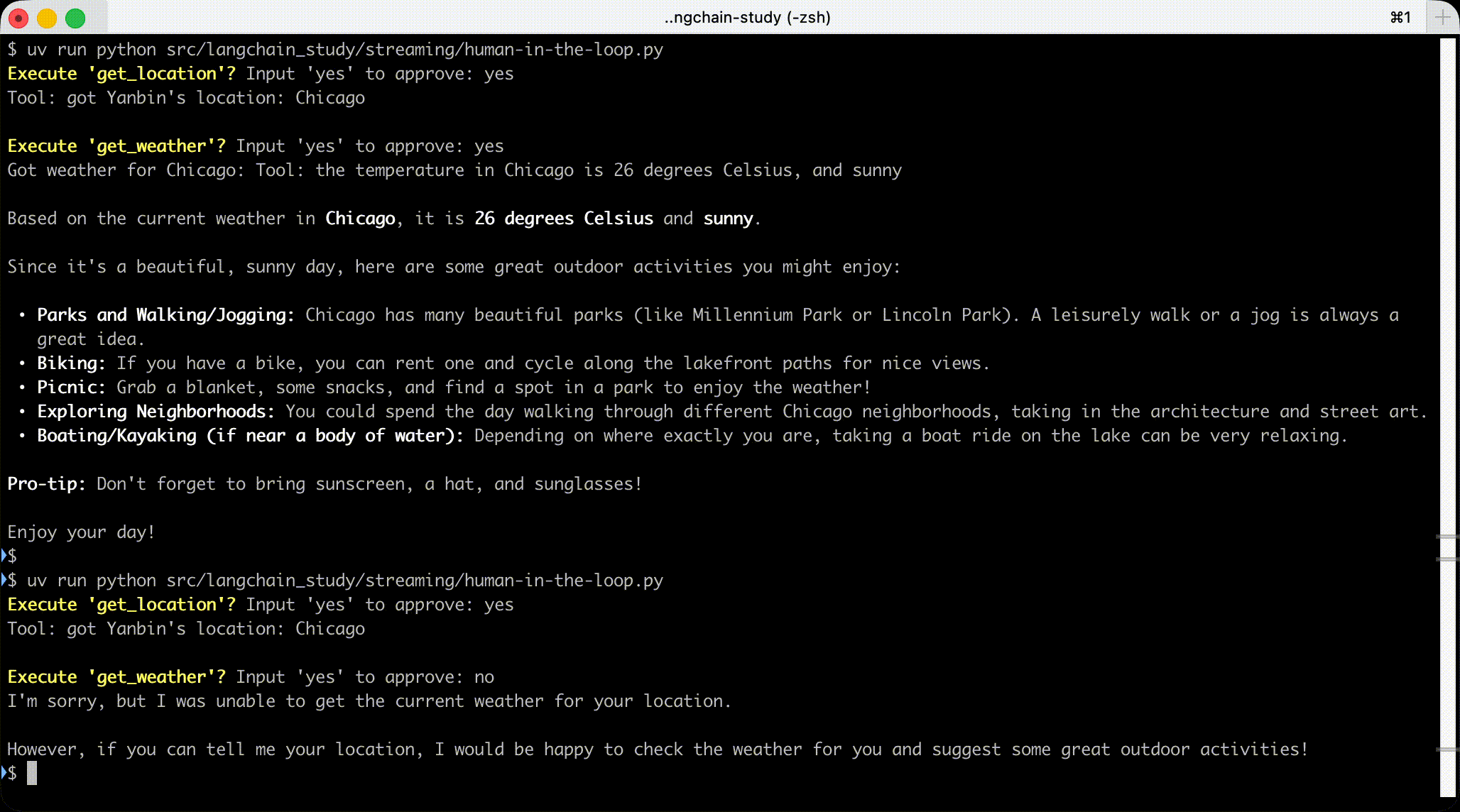
Streaming 子 Agent 中的消息
创建 Agent 时指定的名称,在 stream_mode="messages" 时名称会作为 lc_agent_name 属性出现在 metadata 中
1weather_agent = create_agent(
2 model=weather_model,
3 tools=[get_weather],
4 name="weather_agent",
5)
6
7agent = create_agent(
8 model=supervisor_model,
9 tools=[call_weather_agent],
10 name="supervisor",
11)
12
13for chunk in agent.stream(
14 {"messages": [{"role": "user", "content": "What is the weather in Boston?"}]},
15 stream_mode=["messages", "updates"],
16 subgraphs=True,
17 version="v2",
18):
19 token, metadata = chunk["data"]
20 agent_name = metadata.get("lc_agent_name")
禁掉 Streaming
禁止 Streaming 的方式也是因各模型提供者而异,对于 Ollama 来说,是用
1model = init_chat_model(
2 "gemma4:e4b",
3 streaming=False,
4)
ChatOpenAI 也是一样的方式。
当设置 streaming=False 后继续用 agent.stream() 来与模型交互可能就得不到预期结果了。
对于 Ollama 来说无论 streaming=True 还是 False, 当用 agent.invoke() 调用时后端的 HTTP 响应总是 Chunk 方式返回。
但以 OpenAI 兼容的方式来使用 Ollama API,agent.invoke() 时就不会以 Chunk 方式返回,而是一次性返回完整的响应了。
1model = init_chat_model(
2 model="openai:gemma4:e4b",
3 streaming=False,
4 base_url="http://localhost:11434/v1",
5 api_key="any",
6)
7
8agent = create_agent(
9 model=model,
10 tools=[get_weather],
11)
12
13result = agent.invoke({"messages": [{"role": "user", "content": "What is the weather in SF?"}]})
v2 streaming 格式
LangChain 当前版本 1.2.15, agent.stream() 默认 version="v1", 但是异步方法 agent.astream() 默认 version="v2",
若要保持 stream() 和 astream() 相同的输出格式,就要显式的指定相同的 version 参数. version="v2" 时 agent.stream()
返回的是 StreamPart 字典,包含 type, ns, data 三个字段, version="v1" 时返回的格式就会不一样了,用时需注意。
在 result = agent.invoke(version="v2") 有中断时,数据的格式也不一样,v2 的格式是 result.interrupts, v1
中要用 result["__interrupt__"] 来获取中断信息, 还有 v2 的 result.value. 一调试就知道了。
[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。