LangChain 与 Mem0 集成长期记忆
LangChain 的长期记忆可以在创建 Agent 时指定 store 参数,如 create_agent(store=InMemoryStore()), 但它只是把 Agent 与
store 关联了起来,仅此而已,要让长期记忆生效的话必须选择适当的时机,用 Middleware 或 Tool 手动的对 store 进行 get(), put,
search() 等操作。而短期记忆则不同,只要 create_agent(checkpointer=InMemorySaver()) 就让 Agent 具有了短期记忆能力。
在使用 store 的时候,无论是使用 InMemoryStore 还是 PostgreSQLStore 等,历史会话的保存与召回还有很多讲究的地方,例如哪些消息需要保存,
消息如何保存(是否要向量化),新旧消息如何处理等。
Mem0 是一个为 AI Agent 提供长期记忆能力的开源框架,它的核心思路是利用大语言模型(LLM)把对话内容转化为结构化的 事实
存入向量数据库,并通过 LLM 动态维护这些事实的增删改。Mem0 在存入时会不存入原文,而是用 LLM 抽取事实,更新时能与旧记忆合并,删除矛盾记忆,
记忆查询也是把文本转换成向量后进行相似度匹配。向量检索擅长语义模糊匹配,关系推理时 Mem0 1.1 之后引入了图记忆(如用 Neo4j 图数据库)作为补充。
提供 MCP 协议支持不同 AI 应用间的记忆共享与互通。
记忆的重要操作方法有
- add(messages, user_id, agent_id, run_id, ..., infer=True): 添加记忆,返回
memory_id.infer=False不抽取,直接存原文 - update(memory_id, data): 根据
memory_id更新记忆 - delete(memory_id): 根据
memory_id删除记忆 - search(query, top_k=20, filters=None, rerank=False, ...): 检索记忆中数据
- get(memory_id): 根据
memory_id获取记忆内容 - get_all(*, filters=None, top_k=20, ...): 获取所有记忆为 JSON 数据格式,这可以用来迁移记忆
从 add() 方法的参数看出 Mem0 支持多级隔离级别: user_id, agent_id, run_id, 其中 user_id, agent_id, run_id
至少必须指定一个,可多个组合。
先从 Mem0 官方首页取到那段简短的代码,但不想用 OpenAI 的 LLM, 也不用在线的嵌入模型,数据也要存储在本地,
也就是改造成一个离线的 Mem0 记忆。 首先安装相应的 Python 依赖
1uv add mem0ai chromadb ollama
完全离线版的 Mem0 Hello World 后代码行有增加两倍了, 存储用本地的 chromadb 实际为 sqlite 数据库,事实抽取用本地一个稍小的模型
llama3.1:8b,嵌入模型也用本地的 ollama:embeddinggemma:latest.
hello_mem0.py
1import os
2import logging
3
4os.environ["MEM0_TELEMETRY"] = "false"
5logging.getLogger("mem0.utils.spacy_models").setLevel(logging.ERROR)
6
7from mem0 import Memory
8
9config = {
10 "vector_store": {
11 "provider": "chroma",
12 "config": {
13 "collection_name": "mem0_memories",
14 "path": "./chroma_mem0",
15 },
16 },
17 "llm": {
18 "provider": "ollama",
19 "config": {
20 "model": "llama3.1:8b",
21 },
22 },
23 "embedder": {
24 "provider": "ollama",
25 "config": {
26 "model": "embeddinggemma:latest",
27 },
28 },
29}
30
31memroy = Memory.from_config(config)
32
33# Add a memory
34messages = [
35 {"role": "user", "content": "我不是一个素食主义者,但我喜欢吃蔬菜。"},
36 {"role": "assistant", "content": "Got it! I'll remember your dietary preferences."},
37]
38memroy.add(messages, user_id="user123")
39
40# Search memories
41results = memroy.search("What are my dietary restrictions?", filters={"user_id": "user123"}, limit=1)
42print(results)
执行后打印出来的结果
1{'results': [{'id': '413d7459-cf30-4015-89ab-9db2636ae9c6', 'memory': '用户指出自己不是素食主义者,但喜欢吃蔬菜', 'hash': '1cfd6173c20814e47af50c62ab626ac6', 'metadata': None, 'score': 1.0, 'created_at': '2026-05-02T16:17:05.745485+00:00', 'updated_at': '2026-05-02T16:17:05.745485+00:00', 'user_id': 'user123'}]}Mem0 支持的配置请参考 vector_stores/configs.py,
当前列表是 QdrantConfig, ChromaDbConfig, PGVectorConfig, PineconeConfig, MongoDBConfig, MilvusDBConfig,
BaiduDBConfig, CassandraConfig, NeptuneAnalyticsConfig, UpstashVectorConfig, AzureAISearchConfig,
AzureMySQLConfig, RedisDBConfig, ValkeyConfig, DatabricksConfig, ElasticsearchConfig, GoogleMatchingEngineConfig,
OpenSearchConfig, SupabaseConfig, WeaviateConfig, FAISSConfig, LangchainConfig, S3VectorsConfig, TurbopufferConfig
config 除了以上的 vector_store, llm, embedder 属性外,还可配置 history_db_path, reranker, version, 和
custom_instructions. reranker 对检索的内容进行更精细的排序,custom_instructions 是一些自定义的提示词,可以在 LLM 抽取事实时使用。
查看本地存储
前面配置的 vector_store 是本地的 ./chroma_mem0, 查看该目录列表
1tree chroma_mem0
2chroma_mem0
3├── 6227fa08-f436-40e5-b474-bb78ec2012ce
4│ ├── data_level0.bin
5│ ├── header.bin
6│ ├── length.bin
7│ └── link_lists.bin
8└── chroma.sqlite3
.chroma_mem0/chroma.sqlite3 是 sqlite 数据库文件,使用 sqlite3 命令行工具查看其中的表
1sqlite3 chroma_mem0/chroma.sqlite3
2SQLite version 3.51.0 2025-06-12 13:14:41
3Enter ".help" for usage hints.
4sqlite> .table
5acquire_write embedding_metadata_array
6collection_metadata embeddings
7collections embeddings_queue
8databases embeddings_queue_config
9embedding_fulltext_search maintenance_log
10embedding_fulltext_search_config max_seq_id
11embedding_fulltext_search_content migrations
12embedding_fulltext_search_data segment_metadata
13embedding_fulltext_search_docsize segments
14embedding_fulltext_search_idx tenants
15embedding_metadata
16sqlite> .header on
17sqlite> select * from embedding_metadata;
18id|key|string_value|int_value|float_value|bool_value
191|updated_at|2026-05-02T16:17:05.745485+00:00|||
201|created_at|2026-05-02T16:17:05.745485+00:00|||
211|hash|1cfd6173c20814e47af50c62ab626ac6|||
221|user_id|user123|||
231|attributed_to|user|||
241|data|用户指出自己不是素食主义者,但喜欢吃蔬菜|||
251|text_lemmatized|用户指出自己不是素食主义者,但喜欢吃蔬菜|||
存储的内容是通过 LLM 抽取的事实,存储在 embedding_metadata 表中。
网上找了两张图描绘了 Mem0 如何添加与检索记忆
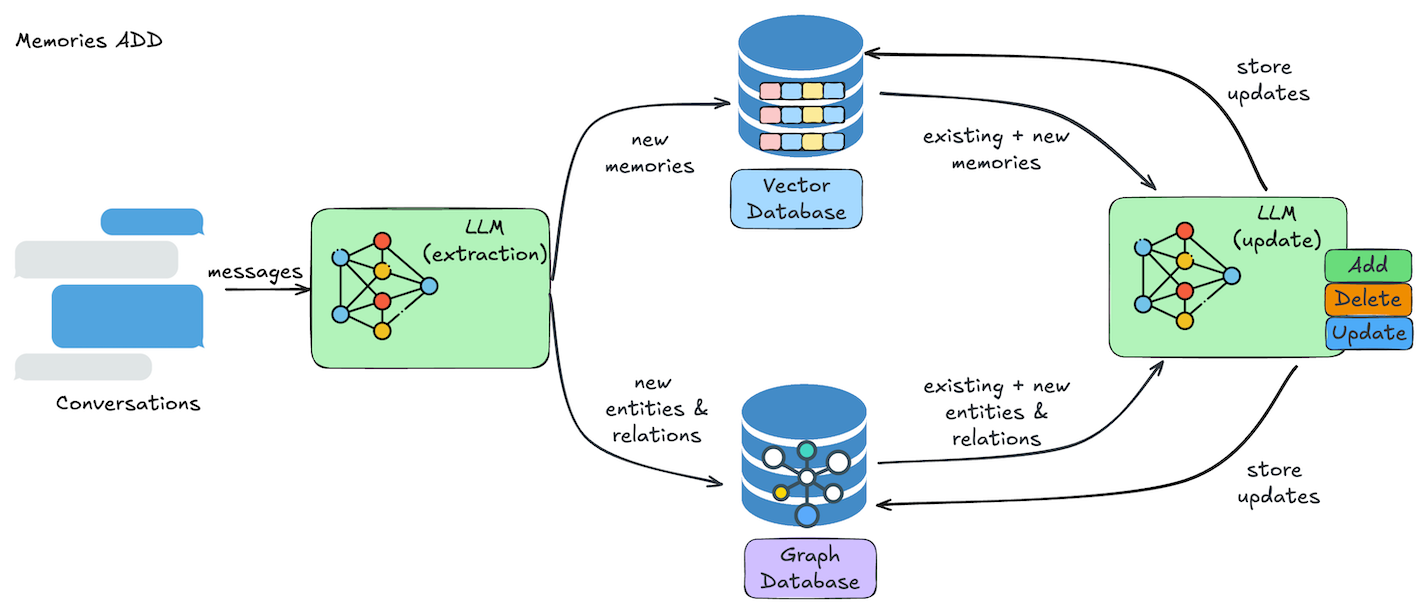
增加和更新记忆时都通过 LLM 对会话内容进行事实提取,识别关键的事实,剔除不必要的噪音信息,达到高效存储与检索。
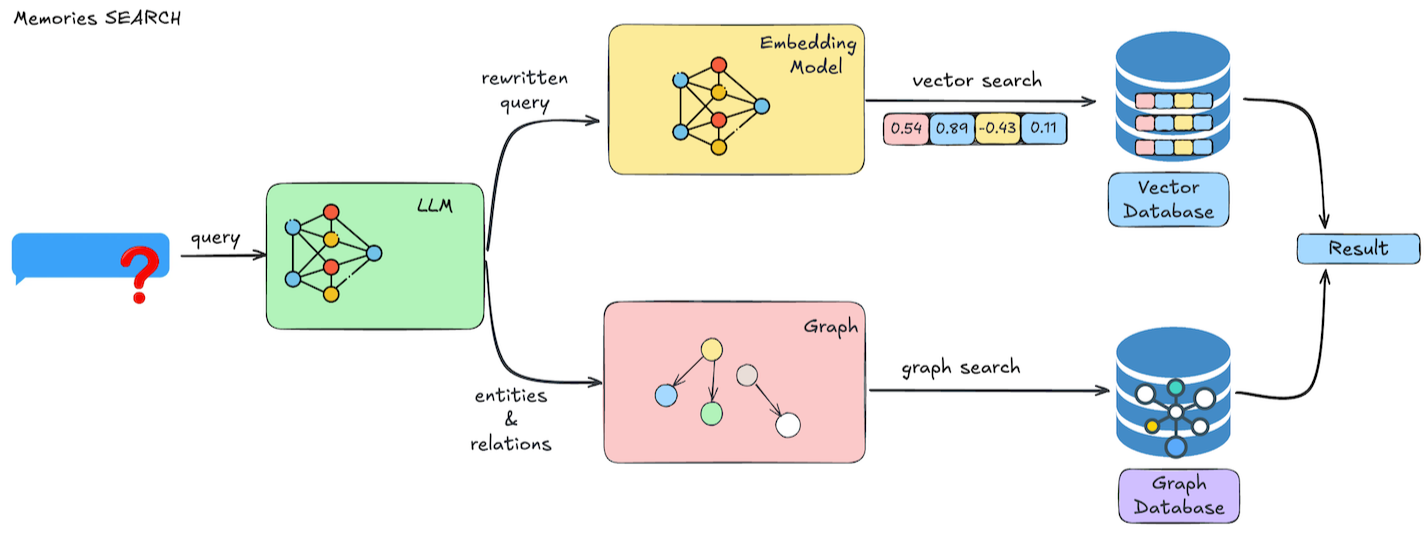
测试 memory.search(...) 时并没有看到 LLM 抽取 query 的步骤。而是直接把 query 向量化后直接检索的。
Mem0 与 LangChain 1.x 的集成
LangChain 可以通过 Middleware 或 tools 与 Mem0 进行集成,生产中更推荐使用 Middleware, 因为 Middleware 不依赖于模型的
tool-calling 能力,减少了与模型之间的一次双向交互。
LangChain 以 Middleware 方式集成 Mem0
config 与上相同,此处省略。
1from typing import Any
2
3from langchain.agents import create_agent
4from langchain.agents.middleware import AgentMiddleware, AgentState
5from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
6from langgraph.runtime import Runtime
7from mem0 import Memory
8from pydantic import BaseModel
9
10config = ... # config 与上相同
11
12class Context(BaseModel):
13 user_id: str
14
15memory = Memory.from_config(config)
16
17class Mem0Middleware(AgentMiddleware):
18
19 def before_model(self, state: AgentState, runtime: Runtime[Context]) -> dict[str, Any] | None:
20 user_id = runtime.context.user_id
21 last_message = state["messages"][-1]
22 last_user_msg = last_message.content if isinstance(last_message, HumanMessage) else ""
23 if not last_user_msg:
24 return None
25
26 results = memory.search(query=last_user_msg, filters={"user_id": user_id}, limit=5)
27 if not results["results"]:
28 return None
29
30 mem_str = "\n".join([f"- {m['memory']}" for m in results["results"]])
31 memory_msg = SystemMessage(
32 content=f"[user long-term memory]\n{mem_str}",
33 id="mem0_context",
34 )
35
36 return {"messages": [memory_msg, *state["messages"]]}
37
38 def after_model(self, state: AgentState, runtime: Runtime[Context]) -> dict[str, Any] | None:
39 user_id = runtime.context.user_id
40 msgs = state["messages"]
41 recent = [
42 {"role": "user" if m.type == "human" else "assistant",
43 "content": m.content}
44 for m in msgs[-2:] if isinstance(m, (HumanMessage, AIMessage)) and m.content
45 ]
46 if recent:
47 result = memory.add(recent, user_id=user_id)
48 print(result)
49
50 return None
51
52
53agent = create_agent(
54 model="ollama:gemma4:e4b",
55 middleware=[Mem0Middleware()],
56 context_schema=Context,
57 # store=memory,
58 system_prompt="You are an assistant with long-term memory, please answer question as concise as you can.",
59)
60
61result = agent.invoke(
62 {"messages": [{"role": "user", "content": "I'm not a vegetarian, but allergic to nuts."}]},
63 context=Context(user_id="user123")
64)
65print("-" * 50)
66print(result["messages"][-1].content)
67
68result = agent.invoke(
69 {"messages": [{"role": "user", "content": "What are my dietary restrictions?"}]},
70 context=Context(user_id="user123")
71)
72print("-" * 50)
73print(result["messages"][-1].content)
这里没有启用短期记忆,所以在第二次询问 What are my dietary restrictions? 就只能依赖 Mem0 的长期记忆中搜寻内容了。看下面的执行输出
1{'results': [{'id': '9babda71-147e-403f-baa1-852e684cf48b', 'memory': 'User is not a vegetarian but has a severe, strict allergy to all nuts including peanuts and tree nuts', 'event': 'ADD'}, {'id': '9872ba26-aa55-4326-8cd9-4b3dfbab129c', 'memory': "User's diet does not restrict meat/non-vegetarian items but must be completely free of nuts due to allergy", 'event': 'ADD'}]}
2--------------------------------------------------
3Understood. Non-vegetarian, nut-allergic.
4{'results': [{'id': 'ba14e72d-8372-4fd5-ba52-a9389198f98e', 'memory': 'User has a severe, strict allergy to all nuts including peanuts and tree nuts due to dietary restrictions', 'event': 'ADD'}]}
5--------------------------------------------------
6Severe allergy to all nuts (including peanuts and tree nuts).从最后的输出 Severe allergy to all nuts (including peanuts and tree nuts). 说明长期记忆中的内容起了作用
背后主要发生了什么呢?在 after_model 中取最新的两个 HumanMessage 和 AIMessage(非工具调用的)消息,进行添加记忆的操作
1memory.add(recent, user_id=user_id)
它会触发 config.llm 的模型调用进行事件提取(Memory Extract), 用的系统提示词是 ADDITIVE_EXTRACTION_PROMPT.
接下来大概是这样的
1{
2 "model": "llama3.1:8b",
3 "stream": false,
4 "options": {
5 "temperature": 0.1,
6 "num_predict": 2000,
7 "top_p": 0.1
8 },
9 "format": "json",
10 "messages": [
11 {
12 "role": "system",
13 "content": "\n\n# ROLE\n\nYou are a Memory Extractor — a precise, evidence-bound processor responsible for extracting rich, contextual memories from conversations ......<此处省略超过 30k 字符>"
14 },
15 {
16 "role": "user",
17 "content": "## Summary\n\n\n## Last k Messages\nuser: I'm not a vegetarian, but allergic to nuts.\nassistant: Severe and strict allergy to all types of nuts, including peanuts and tree nuts.\nuser: I'm not a vegetarian, but allergic to nuts.\nassistant: Understood. I will remember that your diet does not restrict meat/non-vegetarian items, but it must be completely free of nuts due to allergy.\nassistant: Severe allergy to all nuts (including peanuts and tree nuts).\nuser: I'm not a vegetarian, but allergic to nuts.\nassistant: Acknowledged: Non-vegetarian, nut allergy.\nassistant: Severe allergy to all nuts (including peanuts and tree nuts).\nuser: I'm not a vegetarian, but allergic to nuts.\nassistant: Understood. Non-vegetarian, nut-allergic.\n\n\n## Recently Extracted Memories\n[]\n\n## Existing Memories\n[{\"id\": \"0\", \"text\": \"User is not a vegetarian but has a severe, strict allergy to all nuts including peanuts and tree nuts\"}, {\"id\": \"1\", \"text\": \"User's diet does not restrict meat/non-vegetarian items but must be completely free of nuts due to allergy\"}]\n\n## New Messages\nassistant: Severe allergy to all nuts (including peanuts and tree nuts).\n\n\n## Observation Date\n2026-05-03\n\n## Current Date\n2026-05-03\n\n# Output:\n\nPlease respond with valid JSON only."
18 }
19 ],
20 "tools": []
21}提取之后的消息很简洁
1{"model":"llama3.1:8b","created_at":"2026-05-03T04:15:35.535219Z","message":{"role":"assistant","content":"{\n \"memory\": [\n {\"id\": \"0\", \"text\": \"User has a severe, strict allergy to all nuts including peanuts and tree nuts due to dietary restrictions\", \"attributed_to\": \"assistant\"}\n ]\n}"},"done":true,"done_reason":"stop","total_duration":4256318875,"load_duration":72175958,"prompt_eval_count":7982,"prompt_eval_duration":1162492166,"eval_count":49,"eval_duration":2384084584}存入向量数据库就是这个内容,当有新的对话就会把问题转换成向量,然后从历史记忆中找到相似的内容,补充到当前问题当中,这是一个 RAG 应用了。 所以看到第二次实际发送给模型的内容是
1{"model":"gemma4:e4b","stream":true,"options":{},"messages":[{"role":"system","content":"You are an assistant with long-term memory, please answer question as concise as you can."},{"role":"user","content":"What are my dietary restrictions?"},{"role":"system","content":"[user long-term memory]\n- User is not a vegetarian but has a severe, strict allergy to all nuts including peanuts and tree nuts\n- User's diet does not restrict meat/non-vegetarian items but must be completely free of nuts due to allergy"}],"tools":[]}在用户问题之后附加了从长期记忆中提取到的消息
1{
2 "role": "system",
3 "content": "[user long-term memory]\n- User is not a vegetarian but has a severe, strict allergy to all nuts including peanuts and tree nuts\n- User's diet does not restrict meat/non-vegetarian items but must be completely free of nuts due to allergy"在每次 after_model 中都做 memory.add(recent, user_id=user_id) 会很慢,因为它会使用 LLM 来抽取事实,再使用嵌入模型转换成向量再存储,
所以这一步应该作异步操作,以改善客户端体验。实际的 Agent 应该同时启动短期记忆,短期记忆带上最近会话历史,所以长期记忆可以延迟进行异步更新。
LangChain 以 Tools 方式集成 Mem0
另一种 Mem0 与 LangChain 的集成方式是通过 Tools 调用,这时候需把系统提示词写好引导模型去使用相应的工具方法,关键部分的代码改造如下:
1@tool
2def save_memory(content: str, user_id: str) -> str:
3 """Save a long-term fact about the user to the memory store.
4 Call this when the user reveals preferences, attributes, or important events."""
5 result = memory.add(messages=[{"role": "user", "content": content}], user_id=user_id)
6 print(result)
7 return f"Saved: {content}"
8
9@tool
10def search_memory(query: str, user_id: str) -> str:
11 """Search the memory store for user history relevant to the query.
12 Call this before answering personalized questions."""
13 results = memory.search(query=query, filters={"user_id": user_id}, limit=5)
14 if not results["results"]:
15 return "No relevant memories found."
16 return "\n".join([f"- {m['memory']}" for m in results["results"]])
17
18agent = create_agent(
19 model="ollama:gemma4:e4b",
20 tools=[save_memory, search_memory],
21 context_schema=Context,
22 system_prompt=(
23 "You are an assistant with long-term memory. "
24 "Before answering personalized questions, call search_memory first. "
25 "When the user shares important information, call save_memory to persist it. "
26 "Current user ID: {user_id}"
27 ),
28)
执行与 Agent 相同的对话,输出如下
1{'results': [{'id': '8163b6fd-a335-48f3-96a6-0f7bd22b2209', 'memory': 'User is not a vegetarian but has a nut allergy', 'event': 'ADD'}]}
2--------------------------------------------------
3Got it. I've saved that information. Just to confirm, I've noted that you are allergic to nuts, but you are not vegetarian.
4--------------------------------------------------
5The search of your memory reveals that you have a nut allergy, but you are not vegetarian.这里并没有把模型的回复存储到长期记忆当中,如果要存储的话,需要进一步在系统提示词中描述清楚。
其他
前面用的是本地 SDK(mem0ai) 自己管理长期记忆,也可以用托管平台(MemoryClient)管理长期记忆,需要相应的 Api Key 和钱。
注意写入记忆应异步延迟,生产环境建议用 asyncio 或后台队列异步写入,不要阻塞用户响应。
与短期记忆分工,checkpointer 作短期记忆,Mem0 做长期记忆,这样长期记忆的异步延迟写入不会影响到上下文
相关资料:
永久链接 https://yanbin.blog/langchain-mem0-integration/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。