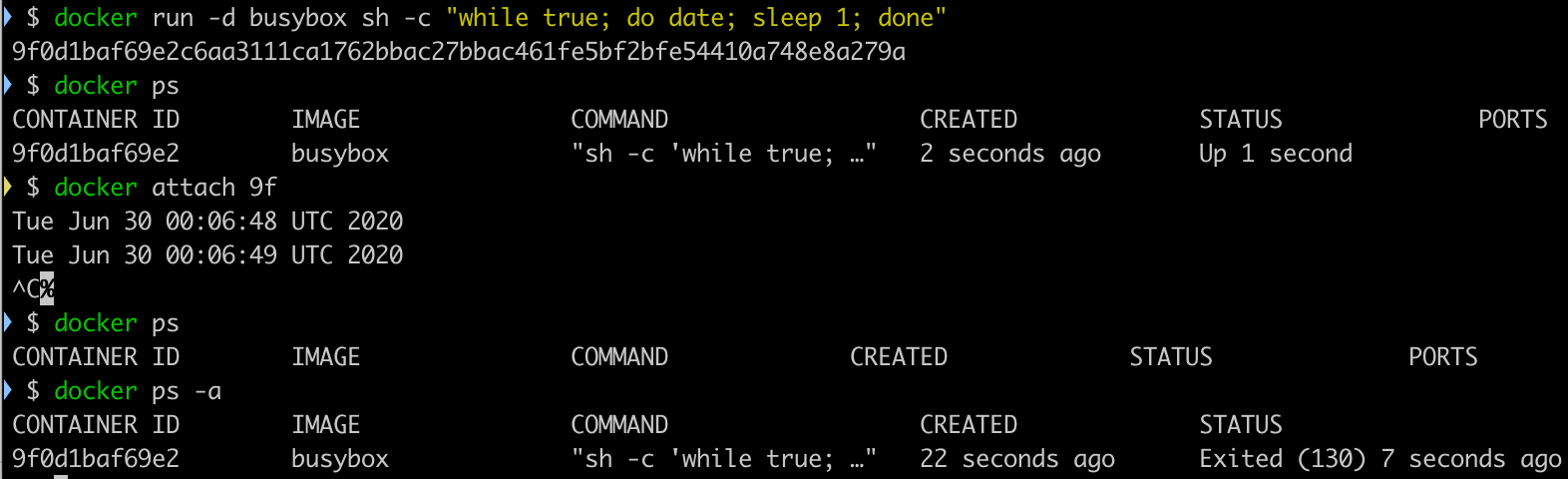
docker attach可以连接上 Docker 容器的标准输入,输出和错误输出。比如docker attach连接后就能显示容器中用 ENTRYPOINT/CMD 启动进程的输出内容内容。想要断开会话连接怎么做呢?ctrl - c, 控制台是不再显示了,可以容器也被终止了,显然这是一个危险的操作。ctrl - c不仅仅关闭了docker attach本身,因为它的默认参数--sig-proxy是true,所以SIGKILL信号同时传递到了 ENTRYPOINT/CMD 的 PID 1 的进程,所以形成了双杀的效果。我们来试一下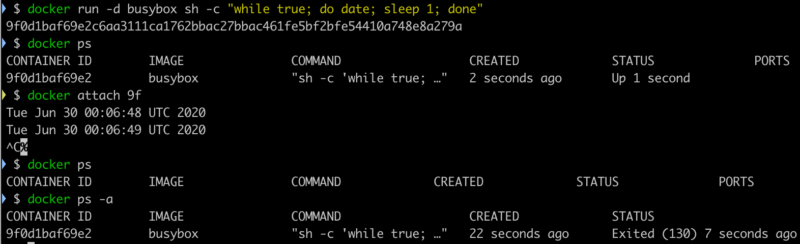 如果是在生产环境下,用
如果是在生产环境下,用 docker attach连接下控制台看下输出,然后不小心像终止tail -f命令一样用ctrl - c退出,结果服务断了。所以更为小心的操作还是用docker logs。docker attach的优势只是在于能查看实时的控制台输出。 Read More 使用 Mockito Mock 方法式,一直以为可以用
使用 Mockito Mock 方法式,一直以为可以用anyString(),any(Foo.class)等匹配null值,其实不行,null值必须显式的用null, 或eq(null)来匹配。anyString(),anyInt()等只能匹配非null值,查看它们的返回值实际是 "" 和 0 等, 而更为特别的是any(Foo.class)看到的是null, 仍然不能匹配null值。进一步用Mockito.mockingDetails(mock).printInvocations()打印出的内容,anyString(),any(Foo.class)都会显示为null值。
说的有点罗嗦,看下面的例子, 被测试类 UserDao,sql 和 sqlArguments 由各自的 setter 方法来控制,默认它们都为nullRead More Python 集合的遍历,推导及 filter/map/reduce 操作 中讲了对集合的 filter, map 和 reduce 操作,那还有 sort 排序呢?像 Java 一样,Python 也提供了 sort() 和 sorted() 方法。
Python 集合的遍历,推导及 filter/map/reduce 操作 中讲了对集合的 filter, map 和 reduce 操作,那还有 sort 排序呢?像 Java 一样,Python 也提供了 sort() 和 sorted() 方法。
sort() 是 list 的实例方法, sorted() 是一个内置函数。Python 中也是只有 list 才有顺序。list.sort() 方法
查看 Python 3 中的list.sort()方法(help(list.sort))Help on method_descriptor:
Python 的 list.sort() 方法和 Java List.sort() 方法一样的,都是
sort(self, /, *, key=None, reverse=False)
Stable sort *IN PLACE*.IN PLACE排序,没有返回值。实际看下各种排序场景 Read More- 本文主要探讨一下在 Python 各种创建 list, set, tuple 和 dictionary 的方式。首先看
最常用的创建方式
1alist = [1, 2] # type(alist) <class 'list'> 2aset = {1, 2} # type(aset) <class 'set'> 3atuple = (1, 2) # type(atuple) <class 'tuple'> 4adict = {'k1': 1, 'k2': 2} # type(adict) <class 'dict'>
以上相当于是针对右边的值调用了相应的构造函数,如 list([1, 2]), set({1, 2}), tupe((1, 2)), dict({'k1': 1, 'k2': 2})
创建 set 和 dictionary 都是用大括号{}, 对于 tuple 如果是单个元素时,要附加一个逗号1atuple = (1,)
如果省略逗号,会怎样呢? Read More  对于基本的排序算法,前面介绍了冒泡,选择,插入和希尔(增强版本的插入), 还有快速排序,现在还剩下最后一种基本的排序算法,那就是归并排序。归并排序像快速排序一样采用递归算法对列表进行分而治之,每次平均一分为二,分到只有一个元素为止。如果列表为空或只有一个元素时,那么从定义上来说它就是有序的; 当然归并排序的拆分最终不会有空列表的情况。拆分成一个个元素后再往回归并,归并是指将两个较小的有序列表归并为一个有序列表的过程。比如说两个单元素列表归并为两个元素的有序列表,两个双元素的列表归并为四个元素的有充列表,不断往上进行,最后形成一个有序的完整列表。
对于基本的排序算法,前面介绍了冒泡,选择,插入和希尔(增强版本的插入), 还有快速排序,现在还剩下最后一种基本的排序算法,那就是归并排序。归并排序像快速排序一样采用递归算法对列表进行分而治之,每次平均一分为二,分到只有一个元素为止。如果列表为空或只有一个元素时,那么从定义上来说它就是有序的; 当然归并排序的拆分最终不会有空列表的情况。拆分成一个个元素后再往回归并,归并是指将两个较小的有序列表归并为一个有序列表的过程。比如说两个单元素列表归并为两个元素的有序列表,两个双元素的列表归并为四个元素的有充列表,不断往上进行,最后形成一个有序的完整列表。
从维基百科的词条 Merge sort 找到下图,很深刻的描绘了归并排序的完整过程,红色箭头拆分,绿色箭头归并 Read More前面讲过的几种排序多是以排序逻辑来命名的,例如冒泡,选择和插入排序,以及其他如归并排序,当然还有觉得自己足够牛 X 快速排序命名。而本文要学习的排序算法叫做希尔排序是以其设计者 Donlad Shell 命令的排序算法,该算法在 1959 年公布,能以作者来命名的算法应该是很不错的,令设计者引以为傲的。最初写出冒泡和选择排序的就没以作者来命名,可能不好意说,更可能是公共思维。
那么什么是希尔排序呢?它实际上是插入排序算法的增强版本,又称递减增量排序算法。它对待排序列表进行间隔式分段插入处理,从而总体上减少了元素的移动次数而达到性能的大大提升。那么理解希尔排序之前一定要先了解插入排序。那么为什么说希尔排序既是递减又是增量呢? Read More
- 前面说过最原始的复杂度为 O(n2) 的冒泡和选择排序,也跳跃到了复杂度为 O(n log n) 的快速排序,现在又再看一个复杂度同样为 O(n2) 的插入排序。从排序名称结合代码我们理解了为什么叫做冒泡或是选择,快速排序自认高名,那么何以这又谓之插入排序呢?是怎么插入,从左边往右边插,还是从右边往左边插,这得搞清它的排序原理:
它在列表较低的一端维护一个有序的子列表(从最左端一个元素开始),并逐个将每个新元素(高端的)"插入"这个子列表。插入的时候遍历低端列表,找准位置插入便是,插入点后的元素需后移,当所有高端的元素插入完成了,整个列表就变得有序了。
整个排序操作示意图如下: Read More - 熟悉了传统的 C++/Java 类定义的风格,来感受一下 Python 是如何定义类的。本篇是阅读 《The Quick Python Book》第二版关于类定义的笔记,由原书内容进一步引申,不过是依照本人的思考顺序来组织的。在理解 Python 类定义的同时头脑中应该闪现出 JavaScript/Java 如何定义类的情景。
最简单的类定义
class MyClass:
由于
passclass MyClass后面要有个冒号,而冒号后总得有点东西才能表示该类定义结束了,于是放个pass当占位符。Python 也像 Java 一样,有一个根类,叫做 object,例如上面的定义1>>> MyClass.__bases__ 2(<class 'object'>,) 3>>> import inspect 4>>> inspect.getmro(MyClass) 5(<class '__main__.MyClass'>, <class 'object'>)
我们能看到它隐式的基类是object, 而不用显式的声明为class MyClass(object)。看到__bases__属性是一个 Tuple, 意识到 Python 是支持多重继承的。 Read More - 冒泡和选择排序的简单粗暴也许在某些人眼里都不能称作算法,现在要进入一种更优雅的排序算法,快速排序。它使用分而治之(Divide and Conquer, D&G) 的策略,要应用到递归调用。快速排序敢说自己快速,也确实比选择排序快很多很多。冒泡和选择排序,尤其是选择排序是非常自然的排序算法,而快速排序就不是一般人会随意想出来的。
快速排序的演绎需要用递归来思考循环的问题,然而我之前总是在及力用循环来避免递归调用,有趣的是诸如 Haskell 等函数式编译语言根本没有循环,只能用递归来编写循环的效果。来看一个简单的例子,比如要从 1 加到 100,我们很自然会用循环从 1 累加到 100,如果换成递归,看下面的代码1def summary(arr): 2 if len(arr) == 0: 3 return 0 4 else: 5 return arr[0] + summary(arr[1:]) 6 7 8print(summary(list(range(1, 101)))) # 5050
递归有助于我们把大问题分解为小问题,上面代码的思维是数组的和总是很一个元素加上剩下元素列表的和,直到最后元素列表为空(和为 0)。 Read More - 因 COVID-19 漫延各自居家,也更有闲时,便拣起一本关于算法的书籍来研究。本不是科班出身,算法方面自然是自己的薄弱环节。平时用各种 SDK,只大概听说了些算法,仅能就自己如何选择哪种实现而作为参考。
如今阅读的是一本入门的书籍,名为 《算法图解》,英文版书名是 《Grokking Algorithms》。 该书图文并茂,十分适合初学者,关于排序最基本莫过于冒泡与选择排序。该书并未提及冒泡,而是直接从选择排序切入,在阅读本书之前我就一直对这两咱排序方式傻傻不分。一直以为头脑中的选择排序就是冒泡排序,那就来看下什么是真正的冒泡排序。 Read More