
上篇 AWS ECS 使用 EC2 Capacity Provider (EC2 Auto Scaling) 学习了如何在 ECS 中使用 Capacity Provider + EC2 Auto Scaling 来部署一个简单的 Web 应用,以及了解 ECS 如何管理 EC2 的 Auto Scaling Group.
ECS Capacity Providers 是于 2019 年 12 月发布的,随同的功能支持了 Fargate, Fargate Spot, 和 EC2 AutoScaling. 而 Managed Instances 在 2025-09-30 才加入的新特性,见 Announcing Amazon ECS Managed Instances.
在近六年之间, AWS 大概也理解到了 Capacity Provider + EC2 Auto Scaling 的复杂性,虽说可由 ECS 来管理 EC2 的 ASG, 但毕竟有个 ASG 在那里。 ECS 与 EC2 ASG 之间联接由 CloudWatch Metrics, Alarms, EC2 ASG 的 Dynamic scaling policies 和 Lifecycle hooks 的一整套机制协作。 经常还不得不在 EC2 ASG 与 ECS 两个界面之间来回找问题。而 Managed Instances 的出现则将 EC2 实例的管理完全透明化了,在 EC2 端压根就不存在 一个相应的 ASG, 更不需要 CloudWatch Alarms 之类的关联组件。
Managed Instances 与 EC2 Auto Scaling 之间就好比 Serverless 与 非 Serverless 的区别,用 Managed Instances 之后你只管控制好 ECS Desired Count(ECS AutoScaling), 其余的都由 Managed Instances 来管理,在界面上只需要关注 ECS Infrastructure 中的 Container Instances. 由 Managed Instances 管理的 EC2 实例,你即使用有管理员权限都无法关闭它,只能全权由 Managed Instances 来控制。试图关闭这样的 EC2 实例时报错
Read More在我 X 中 AWS 上不同应用的部署策略 中提到过在 AWS 部署服务(特别是 Web 服务时), 基于采用过以下演进的方式
- EC2(AutoScaling) + 直接 EC2 中部署本地应用, 靠 userdata 完成应用部署 2 EC2(AutoScaling) + ECS(AutoScaling), 运行容器,Replica 模式,有两个层次的 AutoScaling 要单独控制,比较麻烦
- ECS + EC2(AutoScaling), 运行容器,Daemon 模式。由 EC2 来驱动部署 ECS Task
- ECS(AutoScaling) + Fargate, 运行容器。这是最简单的,但硬件资源受限, 想要强大的 CPU, 没门
- ECS(AutoScaling) + Capacity Provider(EC2) + EC2(Managed AutoScaling), 运行容器。由 ECS Task 发起 EC2 实例需求
- ECS(AutoScaling) + Capacity Provider(Fargate),运行容器,Serverless 就是简单,同样硬件资源受限
- EKS,开启 Auto mode,一切变得简单,像是 Capacity Provider(EC2). 但会涉及到复杂的 EKS 配置管理,集群内网络,如 ELB,
基于服务的 WAF, IAM Role. 但基本是一次的工作,建立了健壮的 EKS, 以后部署任何应用都变得很轻松。
对于 #2 和 #3, 如果选择 Network 模式为
Read Morevpc的话,即每个容器都会有自己的 IP 地址,并且 Target Group 中注册的是 IP 地址,这时候 AutoScaling 在缩减实例时就要靠 AutoScaling 的 Lifecycle Hook 来处理对相应 ECS Task 的通知,因为 EC2 的 AutoScaling 只知在开始关闭实例停止向相应实例 转发请求. 如果 Network 模式为默认的Bridge则没问题,因为请求是过通 NAT 方式(如 32768:80) 由 EC2 实例转发到其中的容器。
本文主要专注在 Docker 内的应用进程如何与外部发过来的 Linux 信号进行响应。具体应用在当运行为一个 ECS 的 Docker 容器时,对 ECS 的 AutoScaling 以及部署时如何让应用能正确收到相应的信号。关于 Linux 的 Signal 请参考 Wikipedia 的 Signal(IPC).
其实相关的话题在以前三篇中都有涉及
不同 Dockerfile 的
Read MoreENTRYPOINT或CMD会影响到 Docker 内进程的启动方式,额外参数的接收方式,以及信号的传递。本篇只关注在信号这一议题。 先学习本地的 Docker 容器内与对docker stop或docker kill发出的信号的响应,进而讲述运行在 ECS 的容器与 ASG,部署行为的信号响应。
本文初衷是要专注在 Docker 内的应用进程如何与外部发过来的 Linux 信号进行响应。具体应用在当运行为一个 ECS 的 Docker 容器时,对 ECS 的 AutoScaling 以及部署时如何让应用能正确收到相应的信号。可是一提及这一话题,思维就产生了极大的发散,很想好好捋一捋进程与 Linux 信号之间关系和相关的概念。 关于 Linux 的 Signal 请参考 Wikipedia 的 Signal(IPC).
本文以渐进的方式,从信号的简介,本地 C, Bash, Java 程序与信号,然后将在下一篇学习本地 Docker 容器内进程与信号的处理,ECS 的容器与 ASG,部署行为的信号响应。
Read More
本想用一篇日志记录下在 Docker 容器中使用 Java 调用 C++ 动态库时,当 C++ Crash 时如何自动生成 core dump, 不想分成了至少三篇来完成这一研究。 可以回顾一下前两篇日志
本文是基于第二篇进一步推进,继续探索如何在 Docker 容器中 Java 调用 C++ 动态库时的 core dump 如何生成。首先测试的平台依然是 AWS EC2 实例, OS 为 Amazon Linux 2023, Docker 版本为 25.0.14。为叙事方便,本文所用代码与上篇一样,但还是重复一遍,省却了连接跳转。
Read More在 Java 应用程序通过 JNA 调用 C++ 动态库时,C++ 代码运行在与 Java 同一进程中,当 C++ 代码 Crash 的时候,将会导致整个 Java 应用程序崩溃。 对于一个 Web 应用,这不是我们期望的结果,由于某一个请求输入的数据导致 C++ 代码崩溃了当前 Java 进程,从而造成该 Web 服务已接受到的所有请求全部失败, 这是非常糟糕的用户体验。如果是 Java 代码本身的异常我们可用 try/catch 进行保护,影响只限制在当前请求。如果是 C++ 代码崩溃的话,Java 应用程序无法捕获到这个异常,以致于整个 Java 应用程序崩溃,甚至发生这种情况时连 hs_err.log 文件都来不及生成,更别说生成 HeapDump, 或 CoreDump 了。
如果是用原始 JNI 的方式来调用动态库,我们还能在 JNI 相关的 C++ 代码中捕获到异常,并抛给 Java 去处理。而用 JNA, 我们贪图了它的方便, 比如一个 Java 进程中同时加载同一接口的不同动态库版本(JNI 要同样的实现必须用自定义的 ClassLoader),但在 C++ 代码崩溃时, Java 就显得无能为力了, 只能跟随着立即死亡, 并且在控制台下找不到关于 C++ 因何失败的线索。比如 C++ 中内存被多次释放,或地址越界访问破坏了内存数据等。
Read More
本文初衷是为了解决 Java 应用程序通过 JNA 调用 C++ 动态库时,C++ 代码运行崩溃导致整个 Java 应用程序崩溃而进行的研究。从一个 C++ 调用 C++ 写的动态库起步,记录它在什么情况下产生 core dump 文件,如何分析 core dump 文件等过程。可惜篇幅无法控制,不足以再加入 Java->JNA->C++ 动态库内容了,所以不得不单列此篇,并更名为 'C++ 调用 C++ 动态库时问题诊断'. 关于 Java JNA 到 C++ 的问题诊断只能另立一篇了。
下面我们来用 JNA 的方式来调用 C++ 动态库,演示当 C++ 代码崩溃时会发生什么,并试图找到好的诊断办法。以下演示在 Linux 下进行, 并且 Linux 发行版是 Amazon Linux 2023.
Read More前年记录过一篇 创建可直接用 root 用户 ssh 登陆的 Docker 镜像, 采用了基础镜像是 Ubuntu:20.04. 因为在 AWS 使用 AmazonLinux 2023 更为频繁,为贴近生产环境,本地开发也使用基本 AmazonLinux 2023 为基础镜像的容器,与 IDE 连接以 SSH 协议, 容器的操作由自己的控制,而非直接使用 devcontainer 的方式。比如可以在 Windows 或 macOS 进行 Linux 相关的开发。
当今 Linux 主要还是两个发行版,一个是 RedHat 的家族,一个是 Debian 的家族,之前验证过 Debian 族的 Ubuntu, 这次要验证 RedHat 族的 AmazonLinux 2023, 也作为将来不时之需。
创建允许 root + 密码登陆的镜像
Dockerfile 内容为
Read More
各种 AI 编程工具,如 Codex, Claude Code, Gemini 等提供了一些类似的斜线命令,每个斜线命令大约也是对应着一段特定的提示词。由于工作中更方便的使用 Copilot, 所以本文来探讨如何定义自己的 Copilot 斜线命令。比如想要定义一个命令
/c2py-dataclass用于实现把 C/C++ 的类或结构转换成 Python 的 @dataclass 类,并遵循 Python 的命名规则和设置默认字段值, 也就是采用如下提示词Covert following C/C++ class/struct to Python dataclass, following Python naming convention, and set default field values.
<C/C++ source code goes here>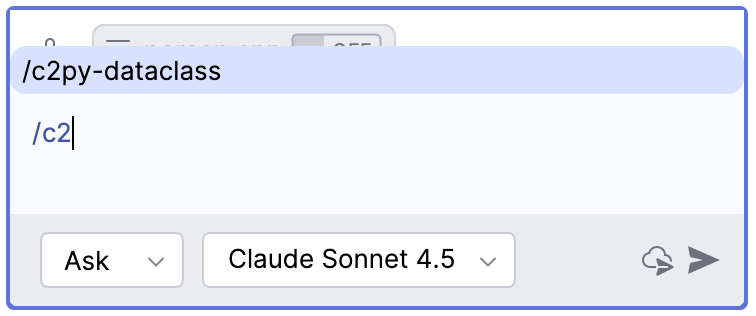
有了自定义的
/c2py-dataclass命令的话,就不需要每次重复上面的描述,而只用输入/c2py-dataclass然后指定某个 C++ 代码文件或粘贴 C/C++ 代码就能实现转换需求。实现方式可以借鉴几天前写的一篇 准备迎接 Vibe Coding - 相关工具与资源 中关于 Spec Kit 一节。
实现方法
开门见山吧,想要添加一个自定义的命令,如
/c2py-dataclass, 仅需在项目目录中添加.github/prompts/c2py-dataclass.prompt.md文件, 立马就会在 Copilot 中出现一个/c2py-dataclass命令,在.github/prompts/c2py-dataclass.prompt.md添加所需的提示词即可。要像
Read MoreSpec Kit那样的话可以使用两个文件.github/agents/c2py-dataclass.agent.md和.github/prompts/c2py-dataclass.prompt.md来配合。
最近在紧锣密鼓的用 Python 写代码,不是 Vibe Coding 那种,因为在真实的敲代码才能碰到一些与 Python 语言相关且容易踏入的坑,记录如下
Python 3.8 引入的 Walrus 操作
即赋值表达式,
:=的使用形式,像海象的两个牙。:=让赋值有了返回值, 该赋值语句的返回值就是右边的值。C/C++ 的=同时具有 Python 的=和:=的功能。我们在 Python 中的
=与:=对比1>>> print(a=1) 2Traceback (most recent call last): 3 File "<python-input-0>", line 1, in <module> 4 print(a=1) 5 ~~~~~^^^^^ 6TypeError: print() got an unexpected keyword argument 'a' 7>>> print(a:=1) 81Python 的这种赋值又有返回值的
Read More:=功能就可以应用到if或while语句中,例如