使用 Python 的话用不着像 Java 那样是考虑用 Logback 还是 Log4J 的问题,因为它内置提供了完备功能的 logging 库。虽然 JDK 也有 java.util.logging(JUL), 它的特性其实也不差,如日志级别,输出格式,不同的输出目的地的选择,但在 Logback 和 Log4J 的光环之下几乎无人问津。相比而言 Python 的 logging 却极为受宠,非必要时基本不会去考虑引入第三方的日志库,如 Loguru, LogBook, Structlog, Picologging, 尽管它们也很出色,毕竟是庶出。
使用 Python 的话用不着像 Java 那样是考虑用 Logback 还是 Log4J 的问题,因为它内置提供了完备功能的 logging 库。虽然 JDK 也有 java.util.logging(JUL), 它的特性其实也不差,如日志级别,输出格式,不同的输出目的地的选择,但在 Logback 和 Log4J 的光环之下几乎无人问津。相比而言 Python 的 logging 却极为受宠,非必要时基本不会去考虑引入第三方的日志库,如 Loguru, LogBook, Structlog, Picologging, 尽管它们也很出色,毕竟是庶出。logging 的最基本用法
在基本前面加是最字,是因为这一节仅仅是如何让 logging 作为 print() 的替代品,暂不涉及到参数的传递,异常的输出,以及格式定制,日志往哪里输出的问题。1import logging 2 3logging.info("hello")
运行,什么也看不到,因为 Python logging 的默认级别是 warning, 这不符合人的基本认知,一般 logging.info() 起码是用来替代 print() 的,居然直接用无法输出,不知该库的设计者是怎么个想法。 Read More 回看三年前的一篇日志 Mockito 3.4.0 开始可 Mock 静态方法,最后对 Mockito 产生的缺憾是它无法用来 Mock 非测试线程(主线程)中的静态方法调用。其实这也是可以变通的,下面慢慢道来。
回看三年前的一篇日志 Mockito 3.4.0 开始可 Mock 静态方法,最后对 Mockito 产生的缺憾是它无法用来 Mock 非测试线程(主线程)中的静态方法调用。其实这也是可以变通的,下面慢慢道来。
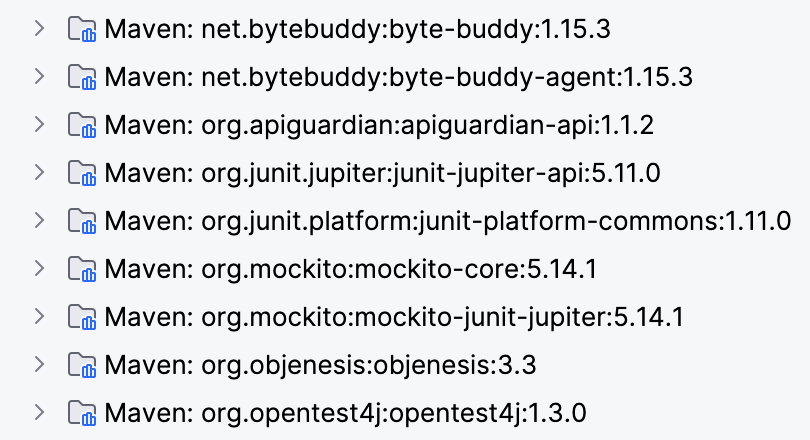
首先回顾一下 Mockito 的静态方法 Mock 的使用方法,随着 Mockito 版本的升级,引入依赖的方式也发生了些许的变化,以 Maven 项目为例,如果在 JUnit 5 下用 Mockito 的 pom.xml 依赖中为1<dependency> 2 <groupId>org.mockito</groupId> 3 <artifactId>mockito-junit-jupiter</artifactId> 4 <version>5.14.1</version> 5 <scope>test</scope> 6</dependency>
由它引入的全部相关依赖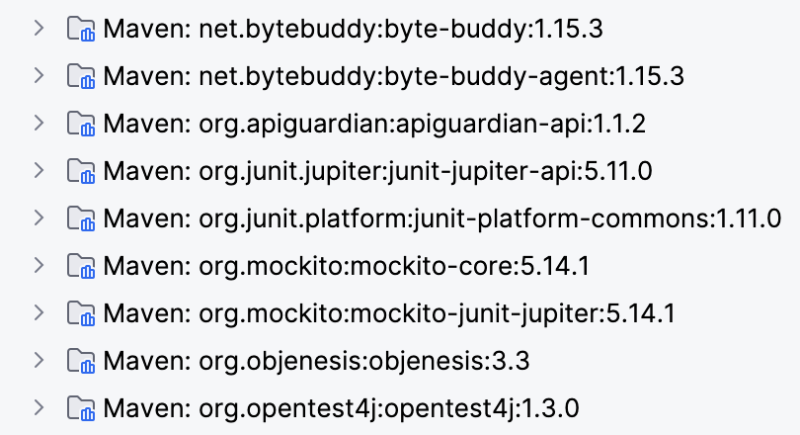 Read More
Read More ThreadLocal 是 Java 编程人员要掌握的一个基本类,似乎没什么太多要说。但因为本文要牵出 TransmittableThreadlLocal, 再顺带说下几乎隐形的 InheritableThreadLocal。
ThreadLocal 是 Java 编程人员要掌握的一个基本类,似乎没什么太多要说。但因为本文要牵出 TransmittableThreadlLocal, 再顺带说下几乎隐形的 InheritableThreadLocal。
ThreadLocal 用于保存与线程绑定的数据,它在框架内部使用的很频繁,但凡见到 XxxContextHolder.currentContext() 之类的十之八九用到了 ThreadLocal, 如 Spring 框架中的
RequestContextHolder1public abstract class RequestContextHolder { 2 private static final ThreadLocal<RequestAttributes> requestAttributesHolder = new NamedThreadLocal("Request attributes"); 3 private static final ThreadLocal<RequestAttributes> inheritableRequestAttributesHolder = new NamedInheritableThreadLocal("Request context");
Read More 看国内的一些项目时 Dubbo 这个词经常闪现,一直也不以为然,未作搜索,当然也不知道它是做什么用的。直到最近阅读关于大型网站架构相关的书中反复提到 Dubbo 后,觉得不能再对它视而不见。Google 了一下,它是在阿里巴巴创建贡献给了 Apache 的开源项目,在阿里巴巴的大型应用中久经考验过的。Dubbo 是什么呢?借用官方 Dubbo 介绍
看国内的一些项目时 Dubbo 这个词经常闪现,一直也不以为然,未作搜索,当然也不知道它是做什么用的。直到最近阅读关于大型网站架构相关的书中反复提到 Dubbo 后,觉得不能再对它视而不见。Google 了一下,它是在阿里巴巴创建贡献给了 Apache 的开源项目,在阿里巴巴的大型应用中久经考验过的。Dubbo 是什么呢?借用官方 Dubbo 介绍Apache Dubbo 是一款 RPC 服务开发框架,用于解决微服务架构下的服务治理与通信问题,官方提供了 Java、Golang 等多语言 SDK 实现。使用 Dubbo 开发的微服务原生具备相互之间的远程地址发现与通信能力, 利用 Dubbo 提供的丰富服务治理特性,可以实现诸如服务发现、负载均衡、流量调度等服务治理诉求。Dubbo 被设计为高度可扩展,用户可以方便的实现流量拦截、选址的各种定制逻辑。
Dubbo 是国内企业贡献的,所以官方有原生的中文文档,它某些时候与 Spring Cloud 齐名,又有些像 AWS 的 ECS Service Discovery, Service Connect 加上 ELB 的功能。 Read More 十来天前写过一篇 Redis 之前如何曲线的方式用作消息队列 使用 Redis 作为消息队列 - Pub/Sub, List, SortedSet. 只能说简单的使用方式勉强还行,离真正意义上的消息队列有些距离。而自 Redis 5.0 加入了 Stream 就更进一步,可望朝着作为正规消息队列的 At most once, At least once, 和 Exactly once 方向迈进。
十来天前写过一篇 Redis 之前如何曲线的方式用作消息队列 使用 Redis 作为消息队列 - Pub/Sub, List, SortedSet. 只能说简单的使用方式勉强还行,离真正意义上的消息队列有些距离。而自 Redis 5.0 加入了 Stream 就更进一步,可望朝着作为正规消息队列的 At most once, At least once, 和 Exactly once 方向迈进。
如果以 Serverless 方式使用 AWS 的 Redis, 那么既然用到高级消息队列的功能,还能省去使用 AmazonMQ(ActiveMQ 或 RabbitMQ) 或 MSK(Kafka) 的高成本。
Redis stream 数据结构像是一个 append-only 日志,但又添加了 O(1) 的随机访问和复杂的消费策略,如消息分组。
Redis Stream 的每条消息会有一个唯一 ID, 支持消费组, Redis 用以支持 Stream 的一系列命令是 X 为前缀的, 完整的 Stream 命令列表。 Read More 本文主要验证用 Python 写的 AWS Lambda 与 Java 客户端之间如何双向传递二进制数据,这里不涉及到 Lambda 流输入输出的问题。比如一个 Python AWS Lambda 的处理方法声明是
本文主要验证用 Python 写的 AWS Lambda 与 Java 客户端之间如何双向传递二进制数据,这里不涉及到 Lambda 流输入输出的问题。比如一个 Python AWS Lambda 的处理方法声明是def lambda_handler(event, context):
通过我们用 Lambda 调用时会传给
pass # or do somethingevent一个 JSON 格式的字符串,反应到 AWS Lambda 时event就是一个字典。但当要传递二进制数据如何做呢?直觉的做法就是用 base64 编码二进制字节为普通的字符串,比如要节约网络传输的数据量,需要对文本进行压缩,格式可以是这样{"input": base64Encode(gzipCompress("text content......"))}
然后在 Lambda 端取出input的值作相应的 base64 解码再解压缩。
对于大文本,即使是压缩后再编码为 base64 也比直接传送原始文本数据要节约网络带宽。
这种方案实际也是可行的,然而我们在实际使用 Java AWS Lambda SDK 时有些动作会自动帮我们实现的,那就是二进制数据自动 base64 编码。 Read More- 我们通常用的 Java 缓存基本可认为是扩展了 HashMap 或 ConcurrentHashMap 的实现,它们各自实现自己的缓存策略,如时间与空间的控制,生命周期管理,是否支持分布式,溢出时能否转储到磁盘。关于 Java 本地缓存的存储分为内存与磁盘,内存多数情况下指的是堆内内存(on-heap), 而介于堆内内存与文件存储之间的就是堆外内存(off-heap)
- 堆内存储(on-heap): 操作最快,无需序列化,但大量数据时会影响到 GC 的效率
- 堆外存储(off-heap): 存储在 Java 进程内存但非 JVM 堆内(不在 -Xmx 指定的内存范围内),使用或保存时需进行序列化/反序列化过程(在堆内与堆外转换),但不受 GC 影响,有助于提它来 GC 的效率
- 文件存储:不仅存在序列化与反序列化过程,还带 IO 操作,所以最慢,唯一优点就是大
我们查看一下当前 Spring 支持的缓存实现, Supported Cache Providers, 列有 Generic, JCache(JSR-107), EhCache 2.x, Hazelcast, Infinispan, Couchbase, Redis, Caffeine, Simple, 这其中无一支持堆外缓存,其中的 EhCache 要付费使用 EhCache 3(Big Memory) 才能支持 off-heap。 Read More - AWS 自 2014 年推出 Lambda 时仅支持 Node.js,而后添加了对 Python, Ruby, Java, C#, F#, PowerShell 的支持,再来到 2018 年可以自定义运行时了,比如用性能较好的 C, C++, Rust, Go 等语言。见 AWS Lambda Now Supports Custom Runtimes and Enables Sharing Common Code Between Functions.
如果使用 Python, Java 写 Lambda 时觉得还不得快,不想要明显的预热过程,也许 1000 毫秒的任务只想要 600 毫秒就能完成,内存还希望再压缩一些,那着实能在每月千百万次 Lambda 调用的情况下节省一笔可观的支出,那么可以试一试 C, C++, Rust, Go 等编译成了机器指令的语言,况且前三者没有 GC, 执行效率会更高。
本日志记录一下如何用 C++ 创建一个 AWS Lambda, 以及可如何应付 Lambda 的复用。本文主要参考自下面两处
自定义运行时可选择 X86_64 或 arm64 的 Amazon Linux 2023 或 Amazon Linux 2。部署时可选择的 runtime 相应有 provided.al2023, provided.al2, 推荐使用 provided.al2023。runtime provided 不被支持了。
C++ 代码可选择用 GCC 或 Clang 来编译,既然 AWS Lambda 实际的运行时会用到 Amazon Linux 2023,那我们就直接选择 Docker 镜像 amazonlinux:2023 作为我们的编译环境。 Read More 
有时候我们在 Mac OS X 或 Windows 平台下需要开发以 Linux 为运行时的应用,IDE 或可直接使用 Docker 容器,或 SSH 远程连接。 本地命令行下操作虽然可以用
docker exec连接正在运行的容器,但 IDE 远程连接的话 SSH 总是一种较为通用的连接方式, 所以我们希望做一个能进行 SSH 连接的 Docker 容器。因为是本地运行的 Docker,我们想直接用 root 连接,以获得在容器中最大的运行权限。 下面以 ubuntu:2004 基础镜像为例,看如何安装启用 ssh 服务以及允许 root 连接.创建允许 root + 密码登陆的镜像
我们创建一个基本的 Dockerfile 文件,内容为
Read More