AWS 提供的 NoSQL 数据库有 DynamoDB, DocumentDB(即 MongoDB), 和 Keyspaces(即 Cassandra)。还有一个神秘的早已消失于 AWS 控制台之外的 SimpleDB,它只能通过 API 才能使用。因为 AWS 有意要把它藏起来,不愿被新用户看到它,希望用 DynamoDB 替代它,关于用 aws cli 如何体验 AWS SimpleDB 可见本文后面部分。
AWS 提供的 NoSQL 数据库有 DynamoDB, DocumentDB(即 MongoDB), 和 Keyspaces(即 Cassandra)。还有一个神秘的早已消失于 AWS 控制台之外的 SimpleDB,它只能通过 API 才能使用。因为 AWS 有意要把它藏起来,不愿被新用户看到它,希望用 DynamoDB 替代它,关于用 aws cli 如何体验 AWS SimpleDB 可见本文后面部分。
DynamoDB 所设计的读写容量参数的概念,AWS 为其标榜是为保证一致性与明确的性能表现,实际上不如说是一个赚钱的计量单位,为了钱反而是把一个简单的事情弄复杂了。当需要全局索引时,必须为全局索引设定读写容量,连索引的钱也不放过。本文只为体验对 DynamoDB 的常用操作,不管吞吐量的问题,所以不用关心读写容量的问题。
DynamoDB 后端用 SSD 存储,不像 Elasticache 是把数据放在内存当,对了 Elasticache 也是 AWS 提供了 NoSQL 服务。DynamoDB 每条记录(Item) 的大小限制为 400K. Read More
DynamoDB Stream 的实质就是一个依附于表的流,对表的增删改像关系型数据的触发器一样,以日志形式按顺记录到该流中。我们可以用 API 去读取其中的记录,或用来触发一个 Lambda。DynamoDB Stream 非常类似于 Kinesis 的 Stream, 它们都是有 Shard 的概念,但是 DynamoDB Stream 的 Shard 数目是不太确定的。而且还能用 KCL(Kinesis Client Library) 来操作 DynamoDB Stream。
DynamoDB Stream 和 Kinesis Stream 有几个通用的 API 操作,像 list_streams(), describe_stream(), get_shard_iterator() 和 get_records() 函数。同时呢,在设置 Lambda 的触发器时,选择 DynamoDB Stream 与 Kinesis Stream 时可配置的参数几乎是一样的,有 Batch size, Batch window, Starting position 以及重试策略。而且也是一个 Shard 只能同时启动一个 Lambda 实例,由于 DynamoDB Stream 的 Shard 数目不太确定,所以它能同时启动几个 Lambda 实例也不确定的。
另外, 一个 DynamoDB Stream 只能最多被两个 Consumer 消费,而可用来消费 Kinesis Stream 的 Consumer 数目是不受限的。DynamoDB Stream 中的记录保存时间为 24 小时, Kinesis Stream 中记录保存时间也是可配置的。我们创建一个 DynamoDB 表时还能启用
Amazon Kinesis data stream details, 即把对 DynamoDB 的操作记录直接发送到 Kinesis Stream 中去,这样就能操作熟悉的 Kinesis Stream,Shard 数目可设定,坏处就是 Kinesis Stream 较费钱。 Read More 前面写的一篇 Go 调用 C 写的动态库完整例子(Linux版),是在告诉编译器用 /* #cgo ...*/ 的方式去加载动态库
前面写的一篇 Go 调用 C 写的动态库完整例子(Linux版),是在告诉编译器用 /* #cgo ...*/ 的方式去加载动态库libadd.so,这让代码丧失了一定的灵活性,比如同样的函数由多个动态库提供了不同的实现。这就需要做到在 Go 程序中可根据不同的输入条件选择不同的动态库实现,大概是if 条件1 {
当然上面那样写是不行的,首先每一个动态库应该在程序运行期间只加载一次,定位的函数应该要缓存起来复用。 Read More
loadLibrary("libadd1.so")
调用其中的实现函数 add
else if 条件 2 {
loadLibrary("libadd2.so")
调用其中的实现函数 add
else {
loadLibrary("libaddx.so")
调用其中的实现函数 add- 前几日系统性差不多读完了一本讲解 Go 语言的书籍,记录下几篇笔记,现在终于能够开始看看专题性的知识了。首先就是关于 Go 如何管理依赖的问题,Java 经历了最早逐个下载 jar 包,到现在用 maven 来描述项目依赖,及进行项目的构建。而 Go 的起点还是要高一些,从一开始就有
go get,go install命令来从中心库下载依赖。但管理多版本依赖是个问题,也没有明确的方式来怎么描述一个项目的依赖。
因此也就产生过一些第三方的 Go 依赖管理- Glide(使用 glide.yaml 文件描述依赖)
- Godep (长时间没维护的项目)
- govendor (不再维护了,在 Go modules 出来后也不被推荐使用)
- 还有其他的 GPM, gb, gom, gvt 等都相继退出了历史的舞台
也就是说 Go Modules 才是王道,在理解 Go Modules 之前也许有必要了解一下传统 GOPATH 管理依赖的方式,其他第三方的管理工具用不着去学习了,早已成了云烟。
Go 语言首次在 1.11 版本中引进了 Go Modules, 在这之前或者没有启用 GO111MODULE 的话,我们用 go get 或 go install 来下载依赖,编译器会从 GOPATH 和 vendor 文件夹中查找包。 Read More  Continue to advance to Kubernetes, the last article Docker Swarm In Action, After understanding Swarm, it is necessary to get familiar with Docker Compose. Docker Swarm forms a cluster of Docker hosts. As long as the Manager node is notified when the service is deployed, it will automatically find the corresponding node to run containers. Compose is another concept entirely. It organizes multiple associated containers into a whole for deployment, such as a load balance container, multiple web containers, and a Redis cache container to make up a whole bundle.
Continue to advance to Kubernetes, the last article Docker Swarm In Action, After understanding Swarm, it is necessary to get familiar with Docker Compose. Docker Swarm forms a cluster of Docker hosts. As long as the Manager node is notified when the service is deployed, it will automatically find the corresponding node to run containers. Compose is another concept entirely. It organizes multiple associated containers into a whole for deployment, such as a load balance container, multiple web containers, and a Redis cache container to make up a whole bundle.
Revealed by its name, Compose, the concept of container orchestration was officially established. Later, Kubernetes, which we will learn, it's a tool for higher-level organization, operation and management of containers. Because Compose organizes the containers, it can start multiple associated containers with one command, instead of starting one container separately.
Regarding the installation of Docker Compose, Docker Desktop under Mac OS X comes with docker-compose; since Docker Compose is written in Python, we can usepip install docker-composeto install it, and use its commands after installationdocker-compose. Read More 在上篇 使用 Java 转换 Apache Avro 为 Parquet 数据格式 实现把 Avro 数据转换为 Parquet 文件或内存字节数组,并支持 LogicalType。其中使用到了 hadoop-core 依赖,注意到它传递的依赖都非常老旧, 到官方 Maven 仓库一看才发现还不是一般的老
在上篇 使用 Java 转换 Apache Avro 为 Parquet 数据格式 实现把 Avro 数据转换为 Parquet 文件或内存字节数组,并支持 LogicalType。其中使用到了 hadoop-core 依赖,注意到它传递的依赖都非常老旧, 到官方 Maven 仓库一看才发现还不是一般的老 长时间无人问津的项目,那一定有它的替代品。对啦,据说 hadoop-core 在 2009 年 7 月份更名为 hadoop-common 了,没找到官方说明,只看到 StackOverflow 的
Differences between Hadoop-coomon, Hadoop-core and Hadoop-client? 是这么说的。 应该是这么个说法,不然为何 hadoop-core 一直停留在 1.2.1 的版本,
而且原来 hadoop-core 中的类在 hadoop-common 中可以找到,如类 org.apache.hadoop.fs.Path。不过在 hadoop-core-1.2.1 中的
长时间无人问津的项目,那一定有它的替代品。对啦,据说 hadoop-core 在 2009 年 7 月份更名为 hadoop-common 了,没找到官方说明,只看到 StackOverflow 的
Differences between Hadoop-coomon, Hadoop-core and Hadoop-client? 是这么说的。 应该是这么个说法,不然为何 hadoop-core 一直停留在 1.2.1 的版本,
而且原来 hadoop-core 中的类在 hadoop-common 中可以找到,如类 org.apache.hadoop.fs.Path。不过在 hadoop-core-1.2.1 中的 fs/s3包不见, 这么重要的 s3 文件系统没了。 Read More- Avro 和 Parquet 是处理数据时常用的两种编码格式,它们同为 Hadoop 大家庭中的成员。这两种格式都是自我描述的,即在数据文件中带有 Schema。 Avro 广泛的应用于数据的序列化,如 Kafka,它是基于行的格式,可被流式处理,而 Parquet 是列式存储格式的,适合于基于列的查询,不能用于流式处理。
既然是一个系统中可能同时用到了这两种数据存储格式,那么就可能有它们之间相互转换的需求。本文探索如何从 Avro 转换为 Parquet 格式数据,以 Java 语言为例,所涉及到的话题有- 转换 Avro 数据为 Parquet 文件
- 如何支持 Avro 的 LogicalType 类型到 Parquet 的转换, 以 date 类型为例
- 实现转换 Avro 数据为 Parquet 字节数组(内存中完成 Avro 到 Parquet 的转换)
本文例子中所选择 Avro 版本是当前最新的 1.10.1 Read More - 管理一个远程机器最常规的做法是 SSH(Unix/Linux, Mac) 或 PowerShell/RDP(Windows),这就要求远端机器要开通相应的访问端口及打开防火墙,配置好登陆用的用户名密码或 SSH Key。当选择一个 EC2 实例的时候,可以点击 "Connect" 按,它提供有三种连接选择:
- EC2 Instance Connect: 要求 EC2 配置了 SSH Key, 启动了 sshd 并开启了 ssh 的 Security Group,还要在实例上安装了
ec2-instance-connect(如安装命令 sudo yum install ec2-instance-connect) - Session Manager: 这就是我们本文要讲述的,sshd 不用启动,Security Group 只要求能往连接外部的 443 端口,SSH Key 不需要
- SSH client: 客户端 SSH 到 EC2 实例,需要打开 sshd 其 22 号端口接受连接的 Security Group,用 SSH Key 或 AMI 中的用户名和密码,或配置加入了域后使用域帐号验证登陆
AWS 的 Session Manager 提供了通过浏览器或 AWS CLI 来访问 EC2 实例,甚至是本地机房的机器或虚拟机(需 advanced-instances tier 的支持),不再依赖于 SSH。 Read More - EC2 Instance Connect: 要求 EC2 配置了 SSH Key, 启动了 sshd 并开启了 ssh 的 Security Group,还要在实例上安装了
 Python 接触的晚,所以接着 体验一下 Python 3.8 带来的主要新特性 继续往前翻,体验一下 Python 3.7 曾经引入的新特性,爱一门语言就要了解她真正的历史。一步一步慢慢给 Python 来个起底。
Python 接触的晚,所以接着 体验一下 Python 3.8 带来的主要新特性 继续往前翻,体验一下 Python 3.7 曾经引入的新特性,爱一门语言就要了解她真正的历史。一步一步慢慢给 Python 来个起底。
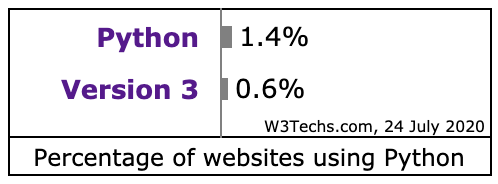
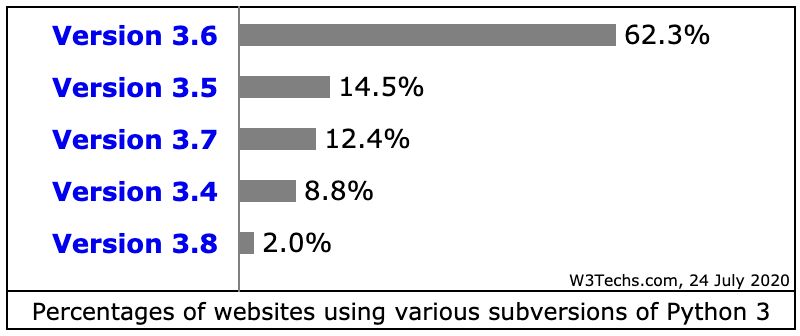
先来看看 Python 网站的各版本使用情况 Usage statistics of Python Version 3 for websites, 这里统计的 Python 开发的网站的数据,应该有 Python 3 大规模的用于其他领域。单网站应用 Python 来说,Python 2 还有大量遗留代码,Python 3 还是 3.6 为主,Python 的升级还任重道远。本人也是谨慎的在从 3.7 迁移到 3.8 的过程中,AWS 的 Lambda 都支持 3.8,直接上 3.8 也没什么历史负担。以下是从网站使用 Python 统计情况中的两个截图
Python 3.7.0 发布于 2018-06-27, 这篇文章 Cool New Features in Python 3.7 详细介绍了 Python 3.7 的新特性,本文也是从其中挑几个来体验体验。 Read More