在 Flask 的官方文档 mod_wsgi(Apache), 说来倒是轻巧,实际操作起来不得不时刻要凝视眼前的无数大坑,或许 Linux, Apache 都用上比较新的版本会好一些。而我所用的环境是 AWS 上的 EC2, AMI 镜像发行版用 cat /proc/version 看到的是 Red Hat 7.2.1-2,内核为 4.14。照着 Flask 的官方文档是没做成功的,yum install mod_wsgi 只能安装到 Python2 的模块,pip install mod_wsgi 也不成功,所以只能使用 mod_wsgi 的源码来编译安装。
在 Flask 的官方文档 mod_wsgi(Apache), 说来倒是轻巧,实际操作起来不得不时刻要凝视眼前的无数大坑,或许 Linux, Apache 都用上比较新的版本会好一些。而我所用的环境是 AWS 上的 EC2, AMI 镜像发行版用 cat /proc/version 看到的是 Red Hat 7.2.1-2,内核为 4.14。照着 Flask 的官方文档是没做成功的,yum install mod_wsgi 只能安装到 Python2 的模块,pip install mod_wsgi 也不成功,所以只能使用 mod_wsgi 的源码来编译安装。
要能顺利编译过 mod_wsgi, 需要安装 Apache 2.2 和 Python 3.6 的 dev 版本。它的仓库里 Python3 最高版本只有 Python 3.6,要 Python 3.7, 3.8 可从源码编译安装。$ yum install gcc
Red Hat 7.2 下的 Apache 真心的难用,不叫 Apache2 也不叫 httpd2,不像 Debian 系统下的 Apache2 做了模块化,基本上 Red Hat 7.2 的 httpd 的配置全在一个文件中 /etc/httpd/conf/httpd.conf。 Read More
$ yum install httpd-devel
$ yum install python36-devel
docker attach可以连接上 Docker 容器的标准输入,输出和错误输出。比如docker attach连接后就能显示容器中用 ENTRYPOINT/CMD 启动进程的输出内容内容。想要断开会话连接怎么做呢?ctrl - c, 控制台是不再显示了,可以容器也被终止了,显然这是一个危险的操作。ctrl - c不仅仅关闭了docker attach本身,因为它的默认参数--sig-proxy是true,所以SIGKILL信号同时传递到了 ENTRYPOINT/CMD 的 PID 1 的进程,所以形成了双杀的效果。我们来试一下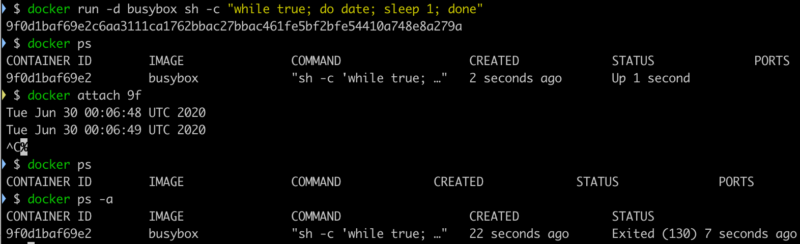 如果是在生产环境下,用
如果是在生产环境下,用 docker attach连接下控制台看下输出,然后不小心像终止tail -f命令一样用ctrl - c退出,结果服务断了。所以更为小心的操作还是用docker logs。docker attach的优势只是在于能查看实时的控制台输出。 Read More 本文主要探讨一下在 Python 各种创建 list, set, tuple 和 dictionary 的方式。首先看
本文主要探讨一下在 Python 各种创建 list, set, tuple 和 dictionary 的方式。首先看最常用的创建方式
1alist = [1, 2] # type(alist) <class 'list'> 2aset = {1, 2} # type(aset) <class 'set'> 3atuple = (1, 2) # type(atuple) <class 'tuple'> 4adict = {'k1': 1, 'k2': 2} # type(adict) <class 'dict'>
以上相当于是针对右边的值调用了相应的构造函数,如 list([1, 2]), set({1, 2}), tupe((1, 2)), dict({'k1': 1, 'k2': 2})
创建 set 和 dictionary 都是用大括号{}, 对于 tuple 如果是单个元素时,要附加一个逗号1atuple = (1,)
如果省略逗号,会怎样呢? Read More Java 多线程编程常用的一个接口是
Java 多线程编程常用的一个接口是ExecutorService, 其实就一个线程池的接口,一般由两种方式创建线程池,一为 Executors 的工厂方法,二则创建 ForkJoinPool 实例,当然也有直接使用 ThreadPoolExecutor 的。
关于什么时候用ForkJoinPool或普通的线程池(如 Executors.newFixedThreadPool(2) 或 new ThreadPoolExecutor(...)) 不过多的述说。如果要运用到 ForkJoinTask 的话就要用 ForkJoinPool, 它是 Java7 新引入的线程池类型。
关于 Java7 的 fork-join 框架可参考很多年前的一篇 Java 的 fork-join 框架实例备忘。ForkJoinPool 的一个典型特征是能够进行 Work stealing。它也是 Akka actor 效率高效的一个有力保证。
本文只能某一种情形下在选择普通线程池与 ForkJoinPool 的区别,直接说吧,普通线程更容易造成死锁,而 ForkJoinPool 却能应对相同的状况。 Read More- 原本是继续阅读《每天5分钟玩转Kubernetes》一书的,发现该书所用的 Kubernetes 版本着实有点老旧( 1.7), 当前版本是 1.18。操作起来有些不同,所以找来了最新的 《Kubernetes in Action》第二版 来看,该书还在写作当中。第二章全是讲 Docker 的内容,本人读书有个不好的习惯,就是不喜欢跳过跳过。看了总会有收获的,这不,就从中稍微理清了 Docker 容器内进程与 Namespace 的关系。
Docker 容器间的进程本质上是宿主主上的一个进程,它能相互隔离靠的是 chroot, namespace 和 cgroup(对 CPU, 内存,磁盘,带宽等的配额)。千万不要认为启动一个 Docker 容器就是启动了一个虚拟机。
其中 namespace 实现了以下几项资源的隔离- Mount: 挂载点(文件系统)
- PID: 进程 ID
- Network: 网络设备,网络栈,端口等
- IPC: 进程间通信,信号量,消息队列和共享等
- UTS: 主机名和域名
- User ID: 用户和组 ID
Read More  继续向 Kubernetes 进发,上一篇 Docker Swarm 集群模式实操 了解完 Swarm 后,有必要对 Docker Compose 了解一番。Docker Swarm 是把 Docker 宿主机组成集群,部署服务时只要告知 Manager 节点,它就会自动找到相应节点去运行相应的容器。Compose 完全是另一个概念,它把相关联的多个容器组织成一个整体来部署,如由负载容器,多个 Web 容器和一个 Redis 缓存容器构成一个整体。
继续向 Kubernetes 进发,上一篇 Docker Swarm 集群模式实操 了解完 Swarm 后,有必要对 Docker Compose 了解一番。Docker Swarm 是把 Docker 宿主机组成集群,部署服务时只要告知 Manager 节点,它就会自动找到相应节点去运行相应的容器。Compose 完全是另一个概念,它把相关联的多个容器组织成一个整体来部署,如由负载容器,多个 Web 容器和一个 Redis 缓存容器构成一个整体。
由其名 Compose 正式有了容器编排这么一个概念,后来将要学的 Kubernetes 是更高级别的组织,运行,管理容器的工具。Compose 由于把容器组织起来了,所以能够一条命令启动多个相关联的容器,而无需单独启动一个一个的容器。
关于 Docker Compose 的安装,在 Mac OS X 下的 Docker Desktop 自带了 docker-compose; 由于 Docker Compose 是用 Python 编写的,我们可以用pip install docker-compose的安装,安装后使用它的命令就是docker-compose。
下方的 Docker Container, Swarm, Compose 三者之间的关系图很形像 Read More 在正式进入 Kubernetes 之前希望能对早先的 Docker Swarm 有所了解,虽然它目前基本上没什么用处。Swarm 提供的是 Docker 宿主机的集群,集群中至少有一个 Manager(或多个), 再加上 0 或多个 Worker。它的大意是有个 Docker 服务(容器)通过 Manager 告诉用所管理的 Swarm 集群来执行,它就会在该集群中找到相应的宿主机来执行。Manager 和 Workder 都可用来运行 Docker 容器,但只有 Manager 才能执行部分管理命令。
在正式进入 Kubernetes 之前希望能对早先的 Docker Swarm 有所了解,虽然它目前基本上没什么用处。Swarm 提供的是 Docker 宿主机的集群,集群中至少有一个 Manager(或多个), 再加上 0 或多个 Worker。它的大意是有个 Docker 服务(容器)通过 Manager 告诉用所管理的 Swarm 集群来执行,它就会在该集群中找到相应的宿主机来执行。Manager 和 Workder 都可用来运行 Docker 容器,但只有 Manager 才能执行部分管理命令。
下面两张图很好的体现了我们平时在一个宿主机上和 Swarm 集群宿主机上运行 Docker 容器的区别 所有容器自己扛
所有容器自己扛=>  容器大家一起扛
容器大家一起扛Docker 在 1.12 之后自带了 Swarm 模式。本文实质上对 使用Docker Swarm模式搭建Swarm集群 的一次实际操作与体验。只是自己方便使用了三个 Vagrant 虚拟机进行实践,其中一个 Swarm Manager 节点,两个 worker 节点 Read More
 通常我们注册 Spring Bean 是通过像 @Named, @Bean, @Component, @Service 这样的注解来注册的,或者用更为古老的 XML 配置文件的方式。难免有时候要根据实际业务需求在 Spring 运行期间动态注册 Spring Bean, 比如基本某种形式的配置文件或系统属性来注册相应的 Bean, 这好像又回到了 XML 文件注册方式,也不尽然。
通常我们注册 Spring Bean 是通过像 @Named, @Bean, @Component, @Service 这样的注解来注册的,或者用更为古老的 XML 配置文件的方式。难免有时候要根据实际业务需求在 Spring 运行期间动态注册 Spring Bean, 比如基本某种形式的配置文件或系统属性来注册相应的 Bean, 这好像又回到了 XML 文件注册方式,也不尽然。
那为什么在运行期还要去注册 Spring Bean 呢,直接 new 对象不行吗?当然行得通,不过这样的话就不能更好的使用到 Spring IOC 的好处了。像待注册的 Bean 构造函数可以直接用到其他的 Spring 对象,或 @Value 引入环境变量,还有 @PostContruct 这样的行为。
最初思考如何注册 Spring Bean 时还是费了不少周折,如今清晰了许多。了当的说,不管是 Spring 初始时还是运行时,注册 Bean 的关键(应是唯一) 入口就是 BeanDefinitionRegistry 接口的方法 Read More- 学习理解一个软件非常好的方法就是跟随每一个版本演进的新特性,好比一个人被别人看着长大的,知子莫若父。因此每个版本的 Changelogs 或 What's New 是非常值得一读的,见 What's New In Python 3.8。因为接触 Python 比较晚,没能即时的重前往后的看过 Python 各版本的新特性,于是采用倒叙的方式来看 Python 的演进也不错。
在正式进入 Python 3.8 新特性前,先来看 Python 3.8 的安装和以及介绍一个非常棒的 Python 命令行解析器 bpython 作为 python 命令,ipython, idle 的替代品。
Python 3.8 各平台的安装包可在 https://www.python.org/downloads/release/python-380/ 找到。比如 Mac OS X 下可下载 https://www.python.org/ftp/python/3.8.0/python-3.8.0-macosx10.9.pkg,然后执行安装。安装完后,我机器上的/usr/local/bin/python3就指向到了 Python 3.8, 要用 Python 3.7 的话命令是 python3.7; pip3 却仍然是老版本的。
bpython 的安装要用相应版本的 pip install bpython, 如/Library/Frameworks/Python.framework/Versions/3.8/bin/pip3 install bpython, 或者创建的虚拟环境中安装, python -m venv .venv; source .venv/bin/activate; pip install bpython。安装后启动 bpython 进入一个更智能的 Python 命令解析器。py
下面正式了解 Python 3.8 的主要新特性 Read More