AWS 在 2025-11-14 日发布了 AWS Lambda adds support for Rust, 即 AWS 正式支持用 Rust 写 Lambda 了, 回顾到之前 AWS 为 Rust 提供 SDK 是两年前的 2023-11-27: AWS SDK for Rust is now generally available.
AWS 在 2025-11-14 日发布了 AWS Lambda adds support for Rust, 即 AWS 正式支持用 Rust 写 Lambda 了, 回顾到之前 AWS 为 Rust 提供 SDK 是两年前的 2023-11-27: AWS SDK for Rust is now generally available.
日常中总有几个编程语言是要去掌握的, 像基本的脚本 Bash, 网页用的 JavaScript, 大项目用的 Java, AI 时代的 Python, 再就是仿佛 Rust 也是绕不过的. 之前有学过 Rust, 到现在忘差不多了, 又看到 Tauri, AWS Lambda 对 Rust 的大力支持,有必要放 Rust 提到与 Python, Java 一样的地位来看待。尽管学习起来比 C/C++ 还陡峭,像 解引用, Either(Result, Error), Unwrap, Borrow, Move, Ownership 等概念及规则需慢慢去熟悉。
从 AWS 控制台看看 Lambda 是怎么对 Rust 提供支持的,创建函数时,Runtime 中可以选择
Amazon Linux 2023
OS-only runtime for Go, Rust, C++, customAmazon Linux 2
OS-only runtime for Go, Rust, C++, custom
OS 方面当然是要选择 Amazon Linux 2023 优于 Amazon Linux 2。选择 Amazon Linux 2023 或 Amazon Linux 2 时最后还有一个 custom,也就是说可以自义的定义自己的 Lambda 运行时,可选择任何语言,只要符合 AWS Lambda 调用的接口规范 Using the Lambda runtime API for custom runtimes 即可。不过完全定义吗,还挺罗嗦的,用官方直接支持的语言就容易多了。 Read More 昨天单列了 Java 17 新特性之密封类型, 继续刷 What's New in JDK 17 - New Features and Enhancements.
昨天单列了 Java 17 新特性之密封类型, 继续刷 What's New in JDK 17 - New Features and Enhancements.switch 模式匹配(预览)
在 Java 21 才正式放出,主动就是原来的 switch...case 语句可以写成表达式的方式,有返回值, 无需每个分支的 break, 并增加模式匹配功能,比如匹配类型,带约束子条件,匹配 record 的字段值等,这里不展开说明,待到详细了解 Java 21 新特性时再深入研究。新的 macOS 渲染管道
英文是 New macOS Rendering Pipeline, 主要是 Swing API 如果配置系统属性-Dsun.java2d.meta=true就可以用 Apple Metal 替代 OpenGL 加速渲染界面,很少写 Java Swing 桌面应用的略过。新的 API 可访问大图标
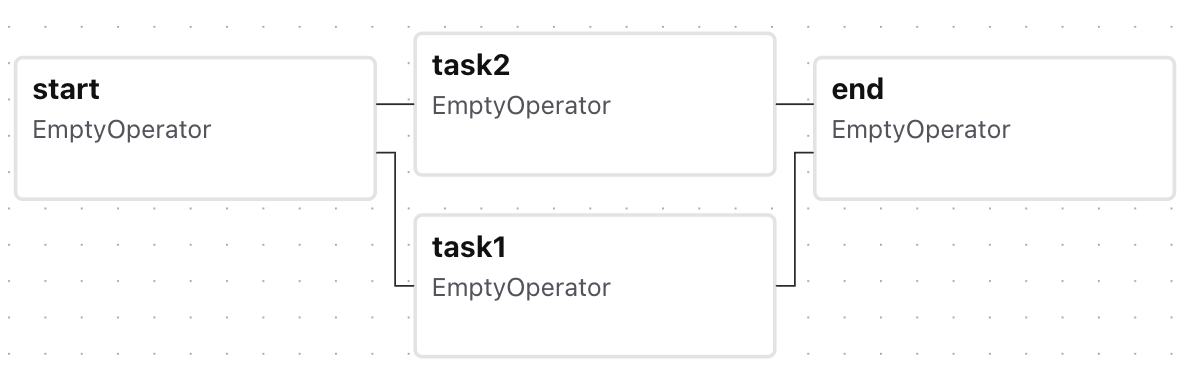
同样是在对 Swing 的改进,可用 FileSystemView 加载解析度的图标 Read More 来到稍微复杂一点的流程,虽说 DAG 不能有循环但分支还是可以有的。比如下面的分支流程
来到稍微复杂一点的流程,虽说 DAG 不能有循环但分支还是可以有的。比如下面的分支流程start >> [task1, task2] >> end
在 Airflow UI 中展示出来就是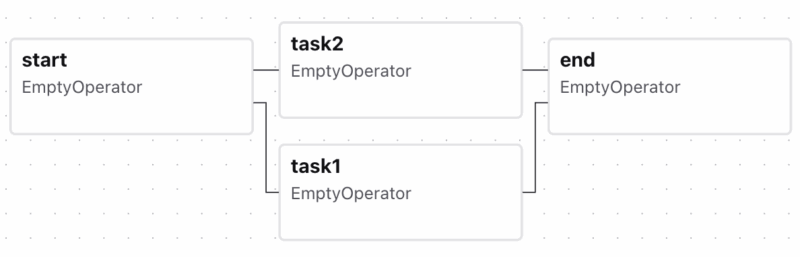 Airflow 默认下游 Task 的
Airflow 默认下游 Task 的 trigger_rule是all_success, 即要求上游的所有 Task 都必须成功才会执行,否则跟随着失败或跳过,这对于并行处理然后汇集结果的应用是合理的。
本文将要使用到的是分支(BranchPythonOperator), 比如共用一个 DAG, 周中与周末执行不同的分支,或根据条件从不同的数据源采集数据,下流的任务则需在任何一个分支成功即可触发。对上面的流程加上辅助任务,使其表达性更强 Read More 使用 Tomcat 时应根据服务器的负载和客户端能接受的等待情可适当的调节 maxThreads, acceptCount, maxConnections 的值。这三个参数只有 maxThreads 是最容易理解,即 Tomcat 当前最大同时处理请求的数目,其他两个参数有些模糊。而搜索网络相关的解释发现一些相互矛盾的地方,本文将通过调整这几个值,实际体验它们对请求连接的影响。
使用 Tomcat 时应根据服务器的负载和客户端能接受的等待情可适当的调节 maxThreads, acceptCount, maxConnections 的值。这三个参数只有 maxThreads 是最容易理解,即 Tomcat 当前最大同时处理请求的数目,其他两个参数有些模糊。而搜索网络相关的解释发现一些相互矛盾的地方,本文将通过调整这几个值,实际体验它们对请求连接的影响。
在测试之前,先看看 Tomcat 官网的解释,你可能不信 AI 的胡说八道,官网仍然是最可信的。在关于 The HTTP Connector 一章中,找到它们三者之间的说明原文是Each incoming, non-asynchronous request requires a thread for the duration of that request. If more simultaneous requests are received than can be handled by the currently available request processing threads, additional threads will be created up to the configured maximum (the value of the
用 Google 翻译后 Read MoremaxThreadsattribute). If still more simultaneous requests are received, Tomcat will accept new connections until the current number of connections reachesmaxConnections. Connections are queued inside the server socket created by the Connector until a thread becomes available to process the connection. OncemaxConnectionshas been reached the operating system will queue further connections. The size of the operating system provided connection queue may be controlled by theacceptCountattribute. If the operating system queue fills, further connection requests may be refused or may time out.- 继续玩弄那个小风车,先前买的 《Data Pipelines with Apache Airflow》 一眼没看直接作废,因为是基于 Apache Airflow 2.x 的,3.0 既出立马又买了该书的第二版,倒是基于 Apache Airflow 3.0 的,但写书之时 3.0 尚未正式推出,所以书中内容与实际应用有许多出入。
Apache Airflow 自 2.4 起就支持基于 Asset 事件触发 DAG,那时叫做 Data-aware,从 Apache Airflow 3.0 起更名为 Asset-Aware, 并且在 UI 上也会显示使用到的 Assets。那么 Asset-Aware 解决什么问题呢,它采用了 Producer/Consumer 模式可把依赖的某一共同资源的 DAG 串联起来。比如某一个 Producer DAG 写了文件到 s3://asset-bucket/example.csv, (发布一个事件 ), 然后相当于订阅了该事件所有相关 Consumer DAG 都会得到执行。
Airflow 的 Asset 使用 URI 的格式- s3://asset-bucket/example.csv
- file://tmp/data/export.json
- postgresql://mydb/schema/mytable
- gs://my-bucket/processed/report.parquet
- 本文大概记录一下在 Apache Airflow 的 Task 或 Operator(这两个基本是同一概念) 中如何使用 模板(Template) 和上下文(Context). Airflow 的模板引擎用的 Jinja Template, 它也被 FastAPI 和 Flask 所采纳。首先只有构造 Operator 时的参数或参数指定的文件内容中,或者调用 Operator render_template() 方法才能用模板语法,像
{{ ds }}. Apache Airflow 有哪些模板变量可用请参考: Templates references / Variables, 本文将会打印出一个 Task 的 context 变量列出所有可用的上下文变量, 不断的深入,最后在源代码找到相关的定义。
通过使用模板或上下文,我们能能够在任务中使用到 Apache Airflow 一些内置的变量值,如 DAG 或任务当前运行时的状态等 。
当我们手动触发一个 DAG 时, 在Configuration JSON中输入的参数也能在 context 中找到. 所有的 Operator 继承链可追溯到 AbstractOperator -> Templater, 因此所有的 Operator(Task) 都能通过调用 Templater.render_template() 方法对模板进行渲染,该方法的原型是 Read More - 早先对 Java ArrayList 的扩容理解是在 new ArrayList() 时会默认建立一个内部容量为 16(这个数值还是错的,往后看) 大小的数组,然而插入数据容量不足时会扩容为原来的 1.5 倍,并用 System.arraycopy() 移动原来的数组到新的大数组中,所以为了频繁的内部扩容操作,在已知 ArrayList 将来大小的情况下,应该在创建 ArrayList 时指定大小,如 new ArrayList(1000)。那么是否指定初始容量对性能会有多大的影响仍缺乏感性的认识。
本文通过具体的测试主要掌握以下知识- new ArrayList() 默认容量大小(JDK 8 以前是 10, JDK 8 及以后为 0)
- ArrayList 何时进行扩容,以及每次扩容多少
- new ArrayList() 时是否指定初始容量值的性能对比
- 除了 ArrayList 自动扩容外,它会不会自动缩容呢?
new ArrayList() 的默认容量多少及增容策略
就像 JDK 8 的 HashMap 引入了红黑树改善性,随着 JDK 版本的升级 ArrayList 的内部实现也在演进。回到 JDK 7, 当我们不指定容量 new ArrayList() 创建一个对象时的实现是 Read More  IT 从业人员累的一个原因是要紧跟时代步伐,甚至是被拽着赶,更别说福报 996. 从早先 CGI, ASP, PHP, 到 Java, .Net, Java 开发是 Spring, Hibernate, 而后云时代 AWS, Azure, 程序一路奔波在掌握工具的使用。而如今言必提的 AI 模型更是时髦,n B 参数, 量化, 微调, ML, LLM, NLP, AGI, RAG, Token, LoRA 等一众词更让坠入云里雾里。
IT 从业人员累的一个原因是要紧跟时代步伐,甚至是被拽着赶,更别说福报 996. 从早先 CGI, ASP, PHP, 到 Java, .Net, Java 开发是 Spring, Hibernate, 而后云时代 AWS, Azure, 程序一路奔波在掌握工具的使用。而如今言必提的 AI 模型更是时髦,n B 参数, 量化, 微调, ML, LLM, NLP, AGI, RAG, Token, LoRA 等一众词更让坠入云里雾里。
去年以机器学习为名买的(游戏机)一直未被正名,机器配置为 CPU i9-13900F + 内存 64G + 显卡 RTX 4090,从进门之后完全处于游戏状态,花了数百小时对《黑神话》进行了几翻测试。
现在要好好用它的 GPU 来体验一下 Meta 开源的 AI 模型,切换到操作系统 Ubuntu 20.04, 用 transformers 的方式试了下两个模型,分别是- Llama-3.1-8B-Instruct: 显存使用了 16G,它的老版本的模型是 Meta-Llama-3-8B-Instruct(支持中文问话,输出是英文)
- Llama-3.2-11B-Vision-Instruct: 显存锋值到了 22.6G(可以分析图片的内容)
都是使用的 torch_dtype=torch.bfloat16, 对于 24 G 显存的 4090 还用不着主内存来帮忙。如果用 float32 则需更多的显存,对于 Llama-3.2-11B-Vision-Instruct 使用 float32, 则要求助于主内存,将看到Some parameters are on the meta device because they were offloaded to the cpu.
反之,对原始模型降低精度,量化成 8 位或 4 位则更节约显卡,这是后话,这里主要记述使用上面的 Llama-3.1-8B-Instruct 模型的过程以及感受它的强大,可比小瞧了这个 8B 的小家伙。所以在手机上可以离线轻松跑一个 1B 的模型。 Read More