
对列表的去重处理,Java 8 在
Stream接口上提供了类似于 SQL 语句那样的distinct()方法,不过它也只能基于对象整体比较来去重,即通过 equals/hashCode 方法。distinct方法的功效与以往的new ArrayList(new HashSet(books))差不多。用起来是List<Book> unique = book.stream().distinct().collect(Collectors.toList())
并且这种去重方式需要在模型类中同时实现 equals 和 hashCode 方法。
回到实际项目中来,我们很多时候的需求是要根据对象的某个属性来去重。比如接下来的一个实例,一个 books 列表中存在 ID 一样,name 却不同的 book, 我们认为这是重复的,所以需要根据 book 的 id 属性对行去重。在 collect 的时候用到的方法是
collectinAndThen(...), 下面是简单代码: Read More Scala 项目看家的构建工具当然是 SBT, 假如我们已习惯于 Maven, 想要用 Maven 来构建 Scala 项目该如何做呢?那首先要找到一个 Maven Scala 相应的 Archetype, 然后用命令
Scala 项目看家的构建工具当然是 SBT, 假如我们已习惯于 Maven, 想要用 Maven 来构建 Scala 项目该如何做呢?那首先要找到一个 Maven Scala 相应的 Archetype, 然后用命令mvn archetype:generate或是在 IntelliJ IDEA 使用 Maven 项目创建向导来选择一个 Maven Scala Archetype。这里主要介绍 IntelliJ IDEA 中 Maven 向导创建 Scala 项目的方式。
首先确保我们已安装了 IntelliJ IDEA 的 Maven 和 Scala 插件。插件中自带了 org.scala-tools.archetypes:scala-archetype-simple:1.2 的 Maven archetype, 这是一个貌视 Scala 官方的 archetype。我们可以尝试基于它来创建一个 Maven Scala 项目。通过 IntelliJ IDEA 的菜单File/New/Project..., 在弹出的窗口中选择 Maven/Create from archetype, 然后找到 scala-archetype-simple, 自带版本为 1.2, 当前最新版也不过 1.3, 那还是 2010 年建立,别提有多老了。 Read More
Spring 相关代码分析
本文通过对 Spring 的源代码来理解它是如何扫描 Bean 与资源的,因为自己有一个类似的需求,想把一堆的配置文件丢到 resources 下某个目录中,在程序启动的时候能加载它们。因为文件名是不一定的,所以不能直接指定文件名来加载,通过对 Spring 扫描资源的理解后,可以在自己的代码中手工扫描那些配置文件,以后有任何新的配置文件只需要扔到相应的配置目录即可。
下面以一个最简单的 Spring Boot 项目为例,调试并观察源代码1@SpringBootApplication 2@ComponentScan(basePackages = "cc.unmi") 3public class DemoApplication { 4 public static void main(String[] args) { 5 SpringApplication.run(DemoApplication.class, args); 6 } 7}
还是直奔主题吧,不一步一步的去探寻到底是哪个实现类去扫描资源的,用 Google 找到的是ClassPathScanningCandidateComponentProvider, 因此直接在这个类的敏感位置上打上断点,比如它的构造函数 Read More 本文旨在了解 Kafka 发送消息到有多个 Partition 的 Topic 时如何选择 Partition。或许多数人已经知道 Kafka 默认(当 key 为 null) 时采用 Round-robin 策略,也就是雨露均沾,风水轮流转,实现类是 DefaultPartitioner。但我们实际应用中为保持相关消息按序到,就必须送到指定的 Partition,方法可以有
本文旨在了解 Kafka 发送消息到有多个 Partition 的 Topic 时如何选择 Partition。或许多数人已经知道 Kafka 默认(当 key 为 null) 时采用 Round-robin 策略,也就是雨露均沾,风水轮流转,实现类是 DefaultPartitioner。但我们实际应用中为保持相关消息按序到,就必须送到指定的 Partition,方法可以有- 指定 Partition 编号
- 指定 Key
- 自定义 Partitioner - 实现 org.apache.kafka.clients.producer.Partitioner, 并通过属性注册
还应考究当指定了 Key 或 Partition 编号发送消息后,后续消息 key 为 null 会选用哪个 Partition。最后再思考一个问题,Consumer 每次 poll 时是获得的消息列表是否只包含一个 Partition 源还是可以多个 Partiton 源。
为完成本次实验,可以本地搭建一个 Kafka 环境,参考 简单搭建 Apache Kafka 分布式消息系统。待 Zookeeper 和 Kafka 正常启动后,我们用下面的命令创建一个 Partition 数量为 3 的 Topicpartition-testbin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic partition-test
验证一下该 Topic 的信息 Read More- 当我们在使用 Java 8 的 Lambda 表达式时,表达式内容需要抛出异常,也许还会想当然的让当前方法再往外抛来解决编译问题,如下面的代码
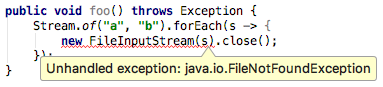 让
让 main()方法抛出Exception还是不解决决编译错误,仍然提示 "Unhandled exception: java.io.FileNotFoundException"。
因为我们可能保持着惯性思维,忽略了 Lambda 本身就是一个功能性接口方法的实现,所以把上面的代码还原为匿名类的方式1public void foo() { 2 Stream.of("a", "b").forEach(new Consumer<String>() { 3 @Override 4 public void accept(String s) { 5 new FileInputStream(s).close(); 6 } 7});
那么对于上面那种情况应该如何处理呢? Read More Java 8 之前如何重复使用注解
在 Java 8 之前我们不能在一个类型重复使用同一个注解,例如 Spring 的注解@PropertySource不能下面那样来引入多个属性文件@PropertySource("classpath:config.properties")
上面的代码无法在 Java 7 下通过编译,错误是: Duplicate annotation
@PropertySource("file:application.properties")
public class MainApp {}
于是我们在 Java 8 之前想到了一个方案来规避 Duplicate Annotation 的错误: 即声明一个新的 Annotation 来包裹@PropertySource, 如@PropertySources1@Retention(RetentionPolicy.RUNTIME) 2public @interface PropertySources { 3 PropertySource[] value(); 4}
然后使用时两个注解齐上阵 Read More- Java 1.5 有了 Future, 可谓是跨了一大步,继而 Java 1.8 新加入一个 Future 的实现 CompletableFuture, 从此线程与线程之间可以愉快的对话了。最初两个线程间的协调我采用过 Object 的
wait()和notify(), Thread 的join()方法,那可算是很低级的 API 了,是否很多 Java 程序都不知道它们的存在,或根本没用过它们。
如果是简单的等待所有线程完成可使用 Java 1.5 的 CountDownLatch, 这里有一篇介绍 CountDownLatch 协调线程, 就是实现的 waitAll(threads) 功能。而 Java 8 的CompletableFuture的功能就多去,可简单使用它实现异步方法。虽说CompletableFuture实现了Future接口,但它多数方法源自于CompletionStage, 所以还里氏代换,用Future来引用CompletableFuture实例就很牵强了; 这也是为什么 PlayFramework 自 2.5 开始直接暴露的类型是CompletionStage而非其他两个。
顾名思义,CompletableFuture 代表着一个 Future 完成后该干点什么,具体大致有:- Future 完成后执行动作,或求取下一个 Future 的值。then...
- 多个 Future 的协调; 同时完成该怎么,其中一个完成该如何。allOf, anyOf
有时候可以把 Future 想像成与线程是一一对应的。 Read More  在数据库中我们一般用整数或字符串来表示枚举值(有些数据库(如 MySQL)本身带有枚举类型), 而在使用 Hibernate 时实体对象中也用 Integer 或 String 来表示枚举就不那么友好了。试想来我们这样定义实体对象的两个属性
在数据库中我们一般用整数或字符串来表示枚举值(有些数据库(如 MySQL)本身带有枚举类型), 而在使用 Hibernate 时实体对象中也用 Integer 或 String 来表示枚举就不那么友好了。试想来我们这样定义实体对象的两个属性@Entity
这样的定义很不严谨,type 和 gender 理论上可取任何值,这会造成表中数据的混乱。其实 Hibernate 在 Java 实体对象中是可以直接用枚举类型与数据库中的整数或字符串映射,需用到
public class User {
.... public Integer type; //0: Individual 类型,1: Company 类型
public String gender; //可取值 Male 和 Female
}@Enumerated注解,用法如下: Read More- 在前一篇 Scala 的参数检查与断言: require, assert, assume 和 ensuring,捉摸 Scala 的断言时提到了 JDK 内置对断言的粗略支持,也就是
assert语句,并且默认该特性是被关掉,需-ea开启。assert object != null;
还进一步接触了 Scala 的
assert object != null : "object can't be null";Predef方法require,assert,assume, 和ensuring是怎么检验参数与断言运算结果的,Scala 的这些方法在校验失败时相应的抛出IllegalArgumentException和AssertionError异常。
JDK 7 引入了 Objects 工具类,它的三个T requireNotNull(T object)方法能对参数进行 null 值检查,null 时抛出NullPointerException Read More
Read More
