早先都是用的基于 JMS 规范的消息系统, 像 ActiveMQ, IBM MQSeries 等. 随着互联网的发展, 大约是要适应当今大数据, 高可用性, 高效的需求, 于是诞生了 Apache Kafka 这一新时代的分布式消息系统. Apache Kafka 也是发布-订阅式的消息系统, 用 Scala 语言写的, 它最初由 LinedIn 开发并贡献到 Apache 基金会.
Kafka 的集群实质是依赖于 ZooKeeper 的集群来协同管理, 所以这里可以参照之前的 ZooKeeper 快速搭建与体验 来搭建一个 ZooKeeper 集群(其实这是一个伪集群, 实际产品中应该把 ZooKeeper 集群分布在不同的机器上).
本文主要是参考官方的 Kafka Quickstart 来快速体验 Kafka 消息系统, 下载的 Kafka 自带了 ZooKeeper, 默认只启动了一个 ZooKeeper 节点. 如需 ZooKeeper 集群可以不依赖于 Kafka 自带的 ZooKeeper 而单独搭建.
下面开始演示建立一个最简单的 Kafka 系统 Read More
 要用到 Hazelcast 这个东西用作分布式缓存, 网上搜索了下发现这篇文章对我理解 Hazelcast 那种无主从之分, 避免了单点故障很有帮助, Hazelcast 的数据分布方式很有点像磁盘阵列 RAID 1, RAID0+1 的影子. 基本上在一个节点出现故障的情况下是不会影响数据访问的.
要用到 Hazelcast 这个东西用作分布式缓存, 网上搜索了下发现这篇文章对我理解 Hazelcast 那种无主从之分, 避免了单点故障很有帮助, Hazelcast 的数据分布方式很有点像磁盘阵列 RAID 1, RAID0+1 的影子. 基本上在一个节点出现故障的情况下是不会影响数据访问的.
下面这个系列讲的很详细:- Hazelcast集群服务(1)——Hazelcast介绍
- Hazelcast集群服务(2)——Hazelcast基本配置
- Hazelcast集群服务(3)——集群功能详解
- Hazelcast集群服务(4)——分布式Map
Hazelcast 是一个开源的可嵌入式数据网格(社区版免费,企业版收费)。你可以把它看做是内存数据库,不过它与 Redis 等内存数据库又有些不同。项目地址:http://hazelcast.org/
Hazelcast 使得 Java 程序员更容易开发分布式计算系统,提供了很多 Java 接口的分布式实现,如:Map, Queue, Topic, ExecutorService, Lock, 以及 JCache 等。它以一个 JAR 包的形式提供服务,只依赖于 Java,并且提供 Java, C/C++, .NET 以及 REST 客户端,因此十分容易使用。如何存储数据
Hazelcast 服务之间是端对端的,没有主从之分,因此也不存在单点故障。集群中所有的节点都存储等量的数据以及进行等量的计算。
Hazelcast 缺省情况下把数据分为 271 个区。这个值可配置于系统属性hazelcast.partition.count。对于一个给定的键,在经过序列号、哈希并对分区总数取模之后能得到此键对应的分区号。所有的分区等量的分布与集群中所有的节点中,每个分区对应的备份也同样分布在集群中。 Read More Clojure 确实要比 Python 语义上庞大, 所以无法尽量在一篇之中收纳进来, 只得另立新篇, 也许还会有第三篇笔记. 现在开始学习函数定义
Clojure 确实要比 Python 语义上庞大, 所以无法尽量在一篇之中收纳进来, 只得另立新篇, 也许还会有第三篇笔记. 现在开始学习函数定义函数定义
函数用defn宏来定义, 函数名与参数列表之间可选的字符串是函数的注释, 相当于 Python 的函数体中第一个字符串, 这个字符串能被(doc func-name)列出来, Python 中是用dir(fun_name显示函数帮助. 不需要 return 关键字, 和 Groovy/Scala 一样最后一个表达式的值为函数的返回值, 所以函数总是有返回值(或为 nil).
和 C 语言一样, 函数必须先定义再使用, 否则要用(declare function-names)提前声明, 下面代码是在 Clojure 的 REPL 中执行的1user=> (defn say-hello-to 2 "say hello to some" 3 [name] (str "Hello, " name)) 4#'user/say-hello-to 5user=> (doc say-hello-to) 6------------------------- 7user/say-hello-to 8([name]) 9 say hello to some 10nil 11user=>
提一下 Clojure 的命名规则, 变量和函数名用中划线连接的小写单词.defn-定义的函数是私有, 只对当前名字空间可见, 比如上面的 user 名字空间. 有点像 Python 的下划线变量或函数的可见性约定. Read More- 自己所学过的编程语言基本是 C 风格的, 给自己定下的目标是要学习下 Python, Swift 和 Clojure. 正如之前的 我的 Python 快速入门 那样的几分钟入门, 这里记录下 Clojure 的快速上手过程.
为什么是 Clojure, 因为它是 Lisp 的一个方言, 个人觉得有必要拓展一下不同的语言风格与思维方式, 就像当初接触 Objective-C 的 [person sayHello] 的方法调用有点不好理解一样, 其实把它还原为面向对象的本质是向 person 发送 sayHello 消息就简单了.编程语方不仅仅是一种技术, 它更是一种思维习惯
希望通过 Clojure 这样的语言来感受另样的思维方式. Clojure 是运行在 JVM 之上的函数式 List 方言. Clojure 乍一看, 基本就是一个括号语言, 它的语法更能体现操作/函数为中心. Clojure 的圆括号兼具 C 风格语言的圆括号(参数列表), 分号(分隔语句), 以及大括号(限定作用域) 的功能. (1 + 2 + 3 +4) 只用写成 (+ 1 2 3 4)。
因为 Clojure 是构筑在 JVM 之上, 所以可以从 http://clojure.org/community/downloads 下载 clojure 的 jar 包, 然后java -jar clojure-1.8.0.jar
就能进到 Clojure 的 REPL(read-eval-print-loop) 控制台了, 就可以开始体验 Clojure 的代码user=> (+ 1 2 3),如果要运行一个已经写好的 Clojure 文件, 如 hello.clj, 就要用java -jar clojure-1.8.0.jar hello.clj来执行. 为方便可以建立一个脚本clj, 内容为java -jar /path/clojure.jar $1
Read More - 应对 Java 项目, 我们大概有以下几个自动化构建工具:
- Ant -- XML 化跨平台批处理, 配置文件 build.xml, 执行的是 target
- Maven -- 开始标准化目录布局, 基于项目对象模型, 配置文件 pom.xml, 执行的是 phase/goal
- Gradle -- 使用 Maven 默认布局, Groove 语言铸就, 配置是 groovy 语法的 build.gradle 文件, 执行的是 task
- Buildr -- 默认也是 Maven 目录布局, Java 世界被 Ruby 插手, 配置是 ruby 语法的 buildfile 文件, 也是 task
- Leiningen -- 也采用 Maven 目录布局, Clojure 写的, 可用于构建 Java 和 Clojure 项目, 配置文件是 Clojure 语法的 prject.clj, 基于 task
- sbt -- 默认 Maven 目录布局, Scala(Simple) Build Tool, Scala 写的, 构建 Java 和 Scala 项目, 配置是 Scala 语法的 build.sbt, 基于 task. 交互式控制台.
Ant 让我们摆脱了对系统平台的依赖, 终于不同人构建的工件是一样的了, 曾经它就是昭示着敏捷. 除了 Ant 需要我们定义所有的 target 外, 其他构建都内置了基本足够用的 task, 而且也都采用了业界接受的 Maven 目录布局. 也是从 Maven 开始引入了项目依赖管理, 所以 Maven 才是里程碑式的.
在我们搜索 Java 第三方依赖时常常进到类似这样的页面 http://mvnrepository.com/artifact/com.google.guava/guava/19.0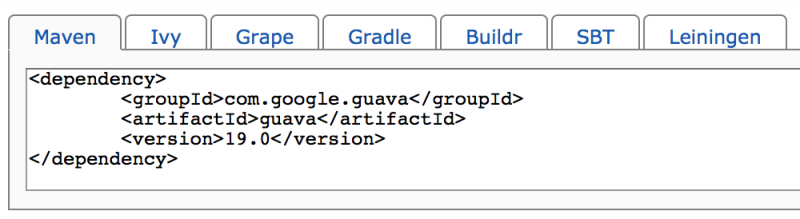 Read More
Read More