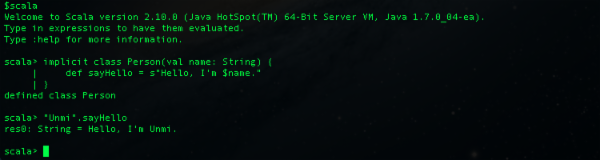
在 Scala 2.10.0 之前类型的隐式转换必须通过隐式方法来完成,现在的 Scala 可以用 implicit class 来声明类, 并且它的主构造器 (Primary Constructor) 只有一个参数时,就可以用来把参数隐式转换成该类型。
能理解上面什么意思,知道怎么用隐式类吗? 就上面那句话,我自己都不知道在说什么。
首先要知道 Scala 先前是怎么依据隐式方法进行类型的隐式转换,其次又何谓主构造器呢? 关于 Scala 2.10.0 的 implicit class, 官方的解释在这里 http://docs.scala-lang.org/sips/pending/implicit-classes.html 再多说只能让大家更摸不到头,实例演示是王道:
 Java 的方法不支持多返回值,或者我们想达到返回多个值的效果时,不得不借用数组、列表或对象等来容纳多个值返回给调用者。这样使用起来不怎么优美,特别是为返回多个值而创造一个类成本有点高,如果 Java 也存在像 C# 那样的匿名类倒好。C# 如何使用匿名类返回多个值可参看本文后面的例子。
Java 的方法不支持多返回值,或者我们想达到返回多个值的效果时,不得不借用数组、列表或对象等来容纳多个值返回给调用者。这样使用起来不怎么优美,特别是为返回多个值而创造一个类成本有点高,如果 Java 也存在像 C# 那样的匿名类倒好。C# 如何使用匿名类返回多个值可参看本文后面的例子。
把 Scala 当作是一种脚本语言,它的灵活性就应该与 Perl 或 Ruby 看齐。Scala 的方法也可以有多个返回值,它实现些种行为,可借助于元组和列表类型,虽然你也可以发掘更多的实现方式,但到目前为止,我还是觉得用元组和列表最简单。
下面给出代码例子,让我们瞧瞧 Scala 如何实现方法多个返回值,并且作为对比我还会贴上 Perl, Ruby 和 C# 可以怎么实现多返回值。我是 Java 的惯用者,不过我一直都未否认,从语言层面 C# 比 Java 要显得优雅的多。用元组实现 Scala 方法多返回值:
1def foo = (100, "Unmi") //定义方法返回元组 2 3val (num, name) = foo //用元组模式去接收方法 foo 的结果 4println(num + ":" + name) //输出为 100:Unmi 5 6val values = foo //调用方法的结果直接给元组变量 7println(values._1 + ":"+ values._2) //输出同样是 100:Unmi
方法返回一个元组,里面可以组合任何多个的不同类型的返回值,调用时可以用元组变量或元组模式去接收方法的返回值,用元组模式的方式更好看些,也才能算作真正的多返回值。 Read More- 在 Java 或者 Scala 的类中,super.foo() 这样的方法调用是静态绑定的,也就是说当你在代码中写下 super.foo() 的时候就能明确是调用它的父类的 foo() 方法。然而,如果是在特质中写下了 super.foo() 时,它的调用是动态绑定的。调用的实现奖在每一次特质被混入到具体类的时候才被决定。
确切的讲,特质的 super 调用与混入的次序很重要,参照下面的例子说话:1val queue = (new BasicIntQueue with Incrementing with Doubling)
直截的讲就是超靠近后面的特质越优先起作用。当你调用带混入的类的方法是,最右侧特质的方法首先被调用。如果那个方法调用了 super,它调用其左侧特质的方法。可以这么认为,Doubling 的 super 指向了 Incrementing,Incrementing 的 super 指向了 BasicIntQueue。
来看个完整的实例实际体验一把,如果要帮助理解,最好应该实际运行一下这个实例 Read More - 我看了《Programming in Scala》一书,仍然对 Scala yield 关键字的理解不甚清楚。起初我以为 Scala yield 的与 Ruby 的 yield 是一样,Ruby 中 yield 是被传入代码块的占位符。Scala 中的 yield 关键字好像总是在 for 循环中用的. 下面一些例子可以帮助你更好的理解 yield 关键字。下面是摘自 《Programming in Scala》关于 yield 的解释:
For each iteration of your for loop, yield generates a value which will be remembered. It's like the for loop has a buffer you can't see, and for each iteration of your for loop, another item is added to that buffer. When your for loop finishes running, it will return this collection of all the yielded values. The type of the collection that is returned is the same type that you were iterating over, so a Map yields a Map, a List yields a List, and so on. Also, note that the initial collection is not changed; the for/yield construct creates a new collection according to the algorithm you specify.
上面那段话的意义就是,for 循环中的 yield 会把当前的元素记下来,保存在集合中,循环结束后将返回该集合。Scala 中 for 循环是有返回值的。如果被循环的是 Map,返回的就是 Map,被循环的是 List,返回的就是 List,以此类推。 Read More