Quartz Job Scheduling Framework[翻译]第十一章. Quartz 集群 (第二部分)
二. Quartz 中集群是如何工作的
一个 Quartz 集群中的每个节点是一个独立的 Quartz 应用,它又管理着其他的节点。意思是你必须对每个节点分别启动或停止。不像许多应用服务器的集群,独立的 Quartz 节点并不与另一其的节点或是管理节点通信。(将来的 Quartz 版本将会设计成让节点能与其他节点直接通信,而不是借助于数据库。) 取而代之的是,Quartz 应用是通过数据库表来感知到另一应用的。
| Quartz 集群仅能使用 JDBC JobStore 工作 因为集群中节点依赖于数据库来传播 Scheduler 实例的状态,你只能在使用 JDBC JobStore 时应用 Quartz 集群。这意味着你必须使用 JobStoreTX 或是 JobStoreCMT 作为 Job 存储;你不能在集群中使用 RAMJobStore 的。在将来的释放版中非常可能移除这个需求,节点也将能直接与另一节点直接通过网络协议,可能使用 JGroup 进行通信。 |
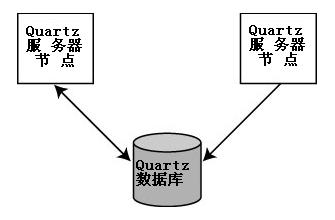
图 11.1 显示了每个节点直接与数据库通信,若离开数据库将对其他节点一无所知
图 11.1. Quartz 集群中的每个节点感知到其他实例只能经由数据库
·Quartz Scheduler 在集群中的启动
Quartz Scheduler 自身是察觉不到被集群的,只有配置给 Scheduler 的 JDBC JobStore 才知道。当 Quartz Scheduler 启动时,它调用 JobStore 的 schedulerStarted() 方法,顾名思义,它告诉 JobStore Scheduler 已经启动了,SchedulerStarted() 方法在 JobStoreSupport 类中被实现了。
JobStoreSupport 类使用 quartz.properties 文件(很快就会讨论到) 中适当的设置确定 Scheduler 实例是否参与到集群中。假如配置了集群,一个新的 ClusterManager 类的实例就被创建、初始化并启动。ClusterManager 是在 JobStoreSupport 类中的一个内嵌类。ClusterManager 继承了 java.lang.Thread,它会定期运行,并对 Scheduler 实例执行检入的功能。Scheduler 也要查看是否有任何一个别的集群节点失败了。检入操作发生的周期是基于一个配置属性的(很快会讲到)。
·侦测失败的 Scheduler 节点
当一个 Scheduler 实例执行检入的例程时,它会查看是否有其他的 Scheduler 实例在到达他们所预期的时间还未检入。这是通过检查 SCHEDULER_STATE 表并寻找 Scheduler 记录在 LAST_CHEDK_TIME 列的值是否早于 org.quartz.jobStore.clusterCheckinInterval(在下节中会讨论) 属性值。如果一个或多个节点还没有检入,那么运行中的 Scheduler 就假定它(们) 失败了。
| 时钟不同步的独立的机器上运行节点 到现在你可以弄清了,如果你在不同的时钟不同步的机器上运行节点的话,你会得到异外的结果。这是因为节点用时间戳来通知其他实例它自己的最后检入时间。假如节点的时钟被设置为将来的时间,那么运行中的 Scheduler 也许再也意识不到那个结点已经宕掉了。另一方面,如果某个节点的时钟被设置为过去了,也许另一节点就会认定那个节点已宕掉并试图接过它的 Job 重运行。这两种情况下,都不是你想要的表现。当你在集群中正使用不同的机器(通常情况下),要确定同步了时钟。具体参考本章后面的 "Quartz 集群 Cookbook" 一节了解如何做。 |
·从故障实例中恢复 Job
当一个 Sheduler 实例在执行某个 Job 时失败了,有可能由另一正常工作的 Scheduler 实例接过这个 Job 重新运行。要实现这种行为,配置给 JobDetail 对象的 Job 可恢复属性必须设置为 true。
如果可恢复属性被设置为 false(默认时),当某个 Scheduler 在运行一个 Job 时失败,它将不会重新运行;而是由另一个 Scheduler 实例在下一次触发时间触发,如果还会被触发的话。Scheduler 实例出现故障后多快能被侦测到决定于每个 Scheduler 的检入间隔。这会在下节中讨论。
永久链接 https://yanbin.blog/quartz-job-scheduling-framework-11-2/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。