简单例子用 Python + PostgreSQL 演示 RAG
RAG(Retrieval-Augmented Generation) 中文名为检索增强生成, 在 LLM 更早期火过的概念,因为那时候上下文较小,所以要检索 LLM 中没有内容(私有数据) 须先在本地用相关性算法找到一些相关的片断,拼接到输入提示词中发送给 LLM。而目前上下文都达到 1M 以上的级别,一次会话甚至可以把私有的内容全部塞 提示词中而喂给 LLM, 就不必用 RAG, 而且内容更完整. 比如你可以把整部小说内容让 LLM 去阅读,然后根据输出总结,或讨论关于该小说的各种问题。 像现在的 Agent Skills 的 Reference 就会把一大段内容丢给 LLM.
所谓的检索(Retrieval) 即在与 LLM 交互之前,从本地(如向量数据库)中找到一些相关的片断,拼接到提示词中,以此达到增强内容生成的效果.
这里不去讨论 RAG 是否已死的问题,只想简单的用 Python, PostgreSQL 加 pgvector 扩展来体验一下什么是 RAG, 以及它的基本流程是什么样子的. 并且对向量数据库中是如何存储和检索的.
本文的内容是参考如下两个来自 马克的技术工作坊 YouTube 频道的视频:
关于 RAG 的流程图,从 Techniques, Challenges, and Future of Augmented Language Models 找到一张清晰又容易理解的
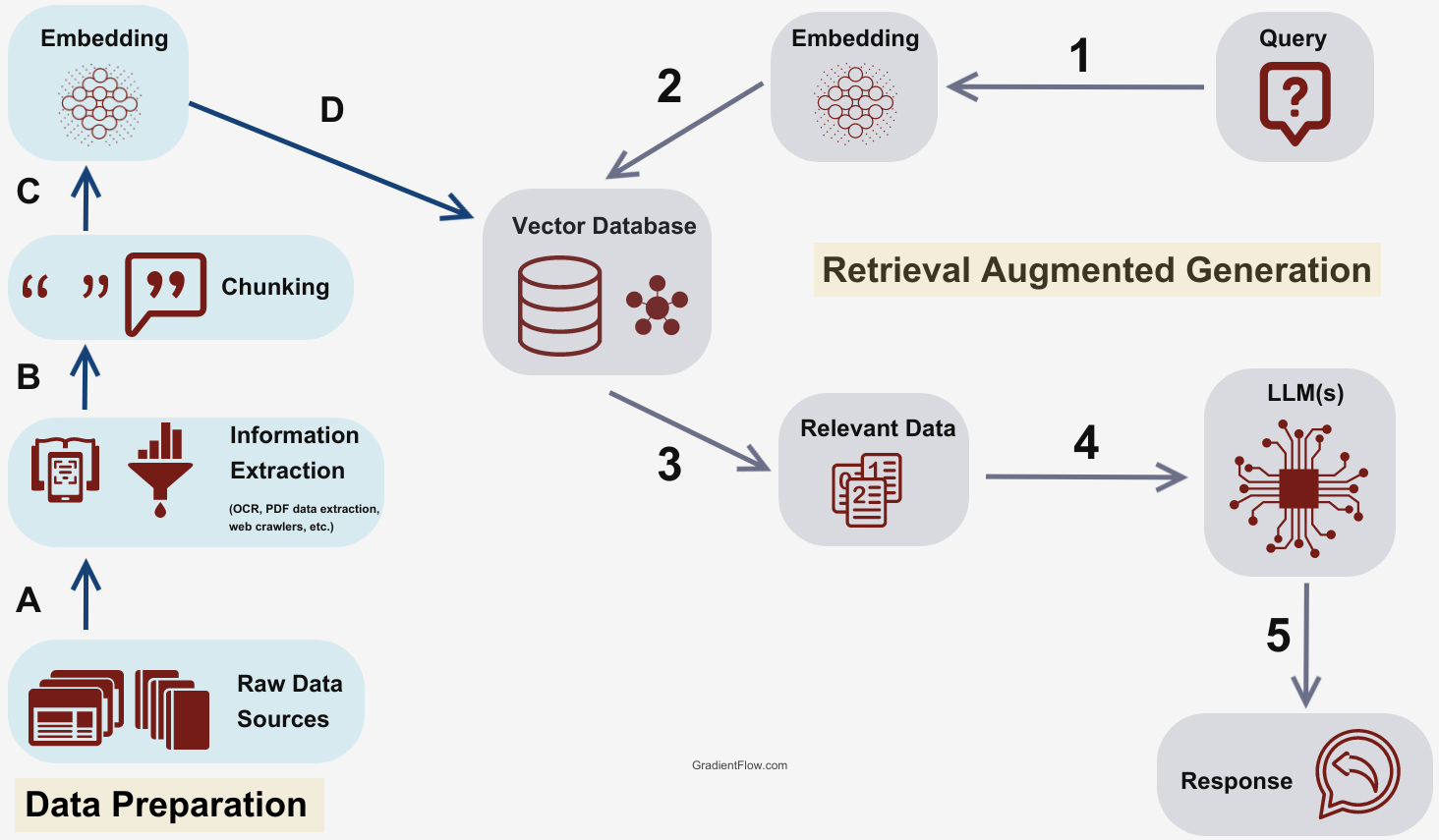
RAG 分两个大的过程:
- 数据向量化(ABCD): 私有数据分片,Embedding(编码), 计算向量值,再把分片内容与向量值存入向量数据库
- 使用向量数据(12345): 当要问询 LLM 时,把输入进行编码,从向量数据库找到若干相似片断内容,并与输入一同组成新的提示词,发送给 LLM, 这样就增强了 LLM 的生成能力. 在获得与输入相关片断的过程时,可能会在进行数据库查询时用粗略的算法快速获得一些候选片断(如 10 条), 再用更精确的算法对这些候选片断进行排序,最终选出更少的(如前 3 条)最相关的片断内容.
下面用 Python 代码和相关的组件,再配合 PostgreSQL 加 pgvector 扩展来演示 RAG 的完整过程,并留意 PostgreSQL 中的向量存储和检索的细节.
我们在 Python 项目中所需用到的依赖列表如下
- BeautifulSoup
- requests
- sentence-transformers
- psycopg2-binary
- pgvector
- google-genai
可用 pip install 安装,如果是 uv 项目,就用 uv add 添加依赖。
数据向量化
先对私有文本数据进行切片,再 Embedding(编码), 将使用 sentence-transformers 并选择合适的模型对片断文本进行编码,得到向量值, 最后存入向量数据库。
向量数据库将使用启用了 pgvector 扩展的 PostgreSQL 数据库.
准备 PostgreSQL 向量数据库
可以安装一个本地的 PostgreSQL 数据库,并启用 pgvector 扩展。如果使用 AWS RDS PostgreSQL 方便的话,操作方式相同,默认未启用 pgvector 扩展.
用 PostgreSQL 客户端连接上数据库后,查看是否启用了 pgvector 扩展
1SELECT extname, extversion FROM pg_extension WHERE extname = 'vector';
2 extname | extversion
3---------+------------
4(0 rows)
如果没有记录,或者 extversion 列为空则说明未启用 pgvector, 启用 pgvector 扩展的方法
1CREATE EXTENSION IF NOT EXISTS vector;
再查询
1SELECT extname, extversion FROM pg_extension WHERE extname = 'vector';
2 extname | extversion
3---------+------------
4 vector | 0.8.0
5(1 row)
现在 PostgreSQL 支持了 pgvector, 不再需要支持 pgvector 的话可执行 DROP EXTENSION vector.
创建向量表
由后面的步骤我们将了解到每个片断 Embedding 后都会得到一个 1024 大小的向量,所以我们创建如下表
1CREATE TABLE documents (
2 id SERIAL PRIMARY KEY,
3 content TEXT UNIQUE NOT NULL,
4 embedding vector(1024)
5);
需要的话创建索引
1CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops);
数据切片
打算用自己的两篇关于博客搬迁的日志作为私有内容,因为那些大模型肯定没有收录过。分别是
通过 requests 读取并用 BeautifulSoup 解析,同时按照段落进行切片,一段就是一个切片。实际项目中可根据需求进行不同粒度的切片,如按句子,
或按固定长度的文本,或按章节进行切片。
1from bs4 import BeautifulSoup
2import requests
3
4def chunk() -> list[str]:
5 all_paragraphs = []
6
7 for url in ["events-of-this-blog", "migrate-again-again"]:
8 response = requests.get(f"https://yanbin.blog/{url}/")
9 soup = BeautifulSoup(response.content, 'html.parser')
10 post_body = soup.find('div', class_='post_body')
11
12 for p in post_body.find_all('p'):
13 if text := p.get_text(strip=True):
14 all_paragraphs.append(text)
15
16 return all_paragraphs
执行后查看输出大致是
1for index, paragraph in enumerate(chunk()):
2 print(f"{index + 1}: ", paragraph)
11: 写下此篇流水纯粹是为了重拾那些零星的记忆...
22: 1. 开始的开始,2001年工作起,进入一个几乎完全陌生的程序世界...
33: 2. 到后来是网络的盛行,也是信息量的爆炸的时代...
4......
共有 22 个段落。这样的话切片我们就完成了。
切片编码
现在我们要对上面的 22 个切片进行编码,即 Embeddings. 在 LLM 的根基 Transformer 模型中就有 Embedding 的概念,其实 RAG 的 Embedding 是一样的, 可以选择自己偏爱的 Embedding 模型,最后得到每一片断的向量值,这个就是我们要存入向量数据库的内容了。
1from sentence_transformers import SentenceTransformer
2
3def embed_chunk(chunk: str) -> list[float]:
4 model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
5 return model.encode(chunk).tolist()
BAAI/bge-large-zh-v1.5 为选择的 Embedding 模型,第一次运行会比较慢,因为会下载整个模型文件,下载到本地目录为 ~/.cache/huggingface/hub/*
1du -sh ~/.cache/huggingface/hub/*
22.4G /Users/yanbin/.cache/huggingface/hub/models--BAAI--bge-large-zh-v1.5
大小为 2.4G,执行时会产生 Notes 和进度条信息,可以用下面的代码让控制台输出更干净
1import transformers
2
3logging.getLogger("sentence_transformers").setLevel(logging.WARNING)
4logging.getLogger("transformers").setLevel(logging.WARNING)
5transformers.logging.set_verbosity_error()
6
7from tqdm import tqdm
8from functools import partialmethod
9tqdm.__init__ = partialmethod(tqdm.__init__, disable=True)
执行代码看编码后的输出
1for chunk in chunk():
2 embed = embed_chunk(chunk)
3 print(len(embed), embed[:5])
输出片断为
11024 [0.03503158316016197, 0.052978288382291794, 0.02039952017366886, -0.020305214449763298, -0.0029326798394322395]
21024 [-0.006175734102725983, 0.04953287914395332, 0.027097150683403015, -0.030116191133856773, -0.009078013710677624]
31024 [0.013064325787127018, 0.0659080296754837, 0.035774510353803635, -0.0655565932393074, 0.00224252138286829]
4......
每个片断 Embedding 后都会得到一个大小为 1024 的向量。这就是我们要存入向量数据库的内容。不理解这些数值串没关系,它们在之后会用来与用户输入 编码后进行相似度的计算。所谓的向量数据库就是适合存储,查询(相似度计算)这些向量值的数据库。
存入向量数据库
存入向量到数据库也没什么特别的,对于 vector(1024) 类型的字段直接写入 list(float) 类型的值就行, 向量长度要一致。Python 代码如下
1import psycopg2
2from pgvector.psycopg2 import register_vector
3
4conn = psycopg2.connect("postgresql://<user>:<pass>@<db_host>/<db_name>")
5register_vector(conn)
6
7
8def save_embeddings(chunks: list[str], embeddings: list[list[float]]):
9 with conn.cursor() as cur:
10 for idx in range(len(chunks)):
11 cur.execute("INSERT INTO documents (content, embedding) VALUES (%s, %s)", (chunks[idx], embeddings[idx]))
12 conn.commit()
综合前面的方法,串起来就是
1chunks = chunk()
2embeddings = [embed_chunk(chunk) for chunk in chunks]
3save_embeddings(chunks, embeddings)
比如字段 vector(1024), 试图插入一个不同长度向量,比如 1021, 将会得到如下错误
psycopg2.errors.DataException: expected 1024 dimensions, not 1021
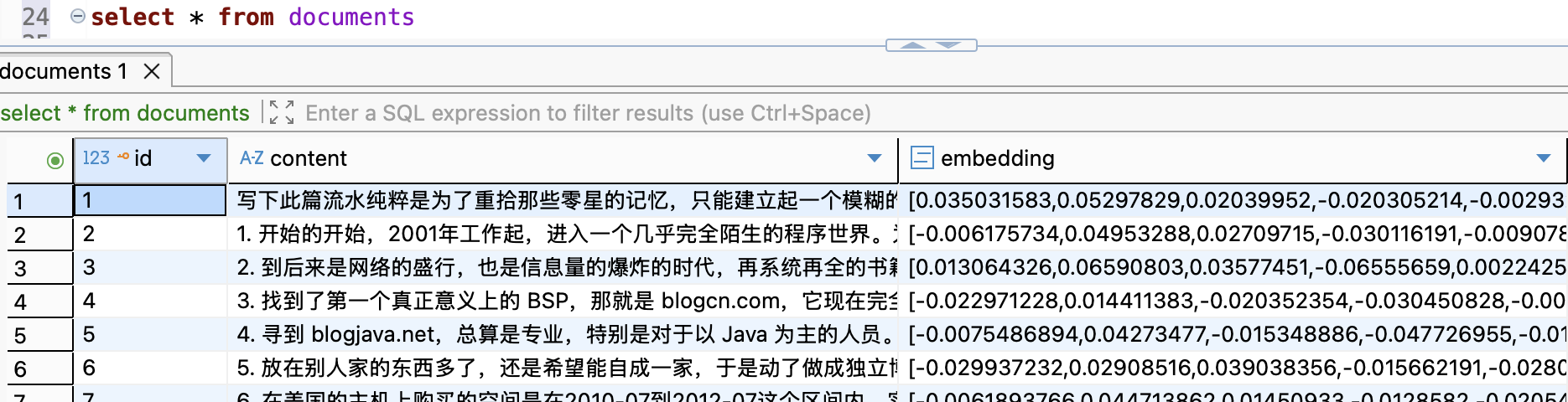
操作成功后,就能在 PostgreSQL 中看到数据了,用 DBeaver 查询看到的内容是这样子的
至此,数据向量化的过程就完成了,下面是在与 LLM 交互前如何使用向量数据库的内容了。
使用向量数据
在正式使用 RAG 之前,我们先来看看向量数据库中存储的向量可如何被查询。可以在任何 PostgreSQL 客户端中直接查询。 PostgreSQL pgvector 支持三种距离(相似度)运算
- <=>: 余弦距离(最常用)
- <->: 欧氏距离
- <#>: 负内积
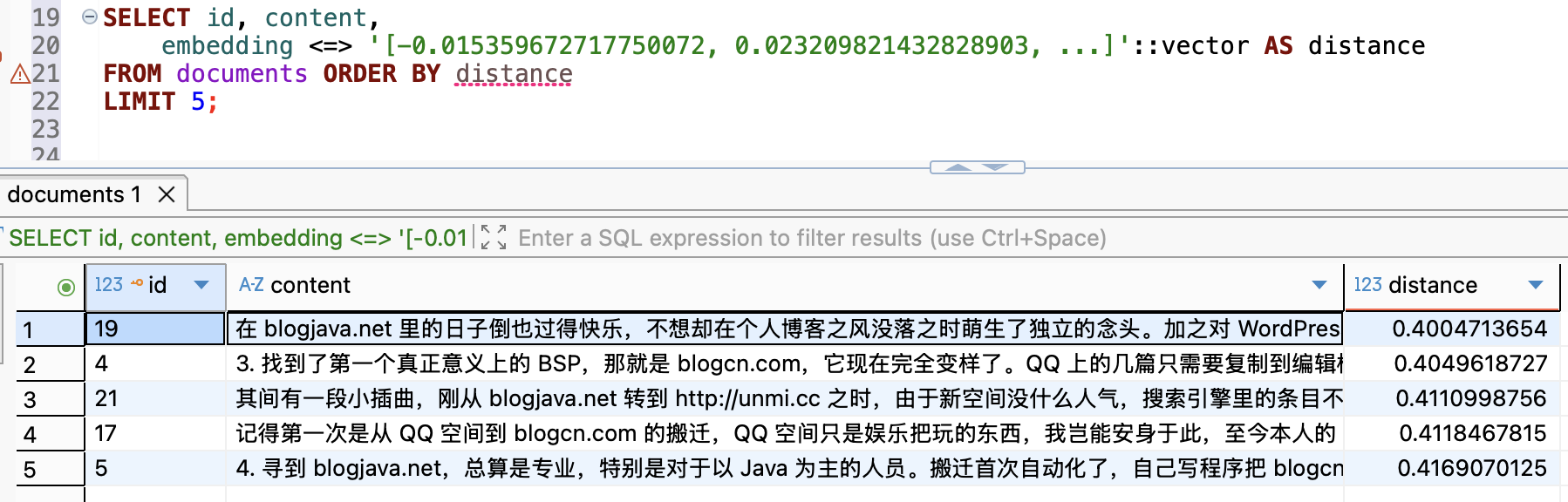
比如我们有一段文字,用前面的 embedding = embed_chunk("本博客使用过哪些域名") 得到一个向量值后就可以在 DBeaver 中查询
1SELECT id, content,
2 embedding <=> '[-0.0045568631030619144, 0.015301012434065342, ...]'::vector AS distance
3FROM documents ORDER BY distance
4LIMIT 5;
[-0.0045568631030619144, 0.015301012434065342, ...] 替换为 "博客使用过哪些域名" Embedding 得到的完整向量值,查询理到最相似的
5 条记录
后面的从数据库查询出最相似的记录基本上就是这样的操作。
输入编码
对于用户输入的问题进行 Embedding 操作,就在前面就提到了。比如我们输入 本博客使用过哪些域名, 这是一个很含混的问题,本 本指代不清,这里就想
测试对于这种含混不清的问题,引入了 RAG 的语料之后, LLM 会给出什么回答。后面还会对比没有 RAG 的话 同样的 LLM 会是什么样的响应。
粗略获取相似片断
前面直接在 PostgreSQL 客户端中查询得到最相似的 5 条记录,这里用 Python 代码也是直接查询向量数据库来粗略获得相似的 10 个片断。
1def retrieve(query: str, top_k: int = 10) -> list[str]:
2 embedding = embed_chunk(query)
3 with conn.cursor() as cur:
4 cur.execute(f"SELECT content FROM documents ORDER BY embedding <=> %s::vector LIMIT {top_k}", (embedding,))
5 return [r[0] for r in cur.fetchall()]
应用到输入的 本博客使用过哪些域名 上,
1retrieved_chunks = retrieve("本博客使用过哪些域名")
2print("\n".join(retrieved_chunks))
得到以下十个相似片断
- 最后的最后,希望不用再往下记录了。或者是有朝一日...
- 在 blogjava.net 里的日子倒也过得快乐,不想却在...
- 其间有一段小插曲,刚从 blogjava.net 转到 http://unmi.cc 之时...
- 最后说此番搬迁,完全是在两个 WordPress 平台间进行...
- 记得第一次是从 QQ 空间到 blogcn.com 的搬迁,QQ 空间只是娱乐把玩的东西...
- 3. 找到了第一个真正意义上的 BSP,那就是 blogcn.com,它现在完全变样...
- 5. 放在别人家的东西多了,还是希望能自成一家,于是动了做成独立博客的念头...
- 4. 寻到 blogjava.net,总算是专业,特别是对于以 Java 为主的人员...
- 主要是国内的主机贵且对备案什么的很反感,所以一直没考虑用国内的主机...
- 8. 香港没法呆了,主机不够隐定,索些弄个 VPS 来玩,在2013-12迁移到...
精确获取相似片断
上一步,如果向量数据库中有大量记录时,在有 vector 列索引时,可以比较快速的获取更冗余数量的相似片断,这一步则要更精细的得到更相关的少量片断, 排序也会与前面的不同。
1from sentence_transformers import CrossEncoder
2
3def rerank(query: str, retrieved_chunks: list[str], top_k: int = 3) -> list[str]:
4 cross_encoder = CrossEncoder('cross-encoder/mmarco-mMiniLMv2-L12-H384-v1')
5 pair = [(query, chunk) for chunk in retrieved_chunks]
6 scores = cross_encoder.predict(pair)
7 chunks_with_score = [(chunk, score) for chunk, score in zip(retrieved_chunks, scores)]
8 chunks_with_score.sort(key=lambda x: x[1], reverse=True)
9 return [chunk for chunk, _ in chunks_with_score[:top_k]]
这里也会下载并用到另一个模型,所以第一次比较慢。
1du -sh ~/.cache/huggingface/hub/*
22.4G /Users/yanbin/.cache/huggingface/hub/models--BAAI--bge-large-zh-v1.5
3470M /Users/yanbin/.cache/huggingface/hub/models--cross-encoder--mmarco-mMiniLMv2-L12-H384-v1
调用它
1query = "本博客使用过哪些域名"
2retrieved_chunks = retrieve(query)
3reranked_chunks = rerank(query, retrieved_chunks)
4print("\n".join(reranked_chunks))
最后输出的最相关的三个片断是
- 5. 放在别人家的东西多了,还是希望能自成一家,于是动了做成独立博客的念头...
- 在 blogjava.net 里的日子倒也过得快乐,不想却在...
- 3. 找到了第一个真正意义上的 BSP,那就是 blogcn.com,它现在完全变样...
看到与最初的 10 条记录顺序也不一样了。
增强 LLM 生成
有了与问题相关的语料片断就可能增加 LLM 的内容生成了,做法是把用户问题与相关片断合并一同发送给 LLM. 大语言模型可以用本地的,或者更便利的方式是使用
Gemini 的免费 API key, 打开 https://aistudio.google.com, 如果登陆了 Google, 在左下角点击 Get API Key 为一个新建项目就能生成免费的
API key 了。
合并提示词
处理输入的最后一步就是把用户问题与相关片段连接起来,组成一个新的提示词
1from google import genai
2
3google_client = genai.Client(api_key="<your-api-key>")
4google_client.models.load("gemini-2.5-flash")
5
6def generate(query: str, chunks: list[str]) -> str:
7 prompt = f'''用户问题: {query}
8
9 相关片段{"\n\n".join(chunks)}'''
10
11 response = google_client.models.generate_content(
12 model="gemini-2.5-flash",
13 contents=prompt
14 )
15 return response.text
实际项目中多用 dotenv 组件来加载 API key, 把 API Key 先写在 .env 文件,内容为
1GEMINI_API_KEY=<your-api-key>
然后用 load_dotenv() 加载,如此则可用不带参数的 google_client = genai.Client() 来创建客户端了。
我们执行完整的对话代码
1if __name__ == "__main__":
2 query = "本博客使用过哪些域名"
3 retrieved_chunks = retrieve(query)
4 reranked_chunks = rerank(query, retrieved_chunks)
5 response = generate(query, reranked_chunks)
6 print(response)
在我的测试中,Genimi 给出的回答是
根据您提供的片段,这个博客使用过的域名包括:
- unmi.cc (这是博主于2010年7月购买的第一个独立域名)
- blogjava.net (这是博主之前使用过的博客平台,博客内容曾在此发布)
- blogcn.com (这是博主找到的第一个真正意义上的BSP,博客内容也曾在此发布)
回答的还像模像样,虽说 blogjava.net 和 blogcn.com 是两个博客平台,也算是我曾用过的域名吧,第一个答案就比较准确,独立域名放最前面。
不使用 RAG 的生成
下面试下没有相关片断的回复是什么, 改用下面的代码
1def generate(query: str) -> str:
2 prompt = f'''用户问题: {query}'''
3
4 response = google_client.models.generate_content(
5 model="gemini-2.5-flash",
6 contents=prompt
7 )
8 return response.text
9
10
11if __name__ == "__main__":
12 query = "本博客使用过哪些域名"
13 response = generate(query)
14 print(response)
输出为
很抱歉,我是一个AI助手,并没有自己的博客。因此,我也没有使用过任何域名,自然也没有域名使用历史。
如果您想了解某个特定博客使用过的域名,通常可以通过以下几种方式来查找:
- 查看博客本身的“关于我们”或“联系方式”页面: 博主可能会在这些页面提及他们曾经使用过的域名,或者当前的域名信息。
- 直接观察博客当前的网址(URL): 这是最直接的方式,会显示该博客当前正在使用的域名。
- 使用WHOIS查询工具: 如果您知道博客当前使用的域名,可以通过WHOIS查询工具查询该域名的注册历史信息。有时,这可能会显示该域名以前的注册者或更早的记录,间接反映出域名的使用历史。不过,隐私保护设置可能会隐藏部分信息。
- 访问互联网档案网站(如Wayback Machine): 输入博客当前的域名,看看它在不同时期被抓取(存档)的页面内容。通过浏览不同时间点的存档,您可能会发现博客在过去使用的不同域名或页面结构。
请告诉我您想了解的是哪个博客,或者您是想问我如何帮助您查找相关信息?
在缺乏相关语料数据的情况下,AI 根据对用户问题的理解也只能回答到这一步了。
这样看来,RAG 还是有其存在的意义,如果拿开源模型微调的话还必须部署到本。如果自己有大量的数据,无法一下放到上下文中,且在安全性可接受的情况下, 还是可以考虑用 RAG 的,同时要思考如何才能从向量数据库中获取到准确足够的片断。
最早是有关于 RAG 还是模型微调的讨论,一般不怎么变的数据可以微调到模型中去,动态的用 RAG. 但 AI 发展不过两三年,模型,更确切的说是 AI Agent 有了快速的发展来应对变化的世界。除了用 RAG 一次性的把相关片断与用户问题合并,还可以使用工具,比如 MCP, Agent Skills 的 Reference, Script 等方式在我们与 LLM 交互过程中动态的把相关数据提供给 LLM, 比 Agent 根据需要从互联网,数据库,或本地文件中搜寻相关数据。
特别是近两三个月的 Agent Skills 这一概念出来没久,风头迅速就盖过了 MCP, 有经验程序员的技术积累被要求写成一个个 Skills, 再提交到公司的 Git, 可能然后就没有然后了。
永久链接 https://yanbin.blog/rag-python-postgresql-pgvector/, 来自 隔叶黄莺 Yanbin's Blog[版权声明]
 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。