上一次关注 Scala 新版本特性还是在将近五年前,针对的是 Scala 2.10. 后来也一直在使用 Scala,基本上是 Scala 2.11,但对 Scala 2.11 所带来的新特性基本无知,大约有个 Macro 功能,没什么机会用上,应用 sbt 时稍有接触。还是老句老话,了解新特性最可靠的文档是每个版本的的 Release Notes, 比如 Scala 2.12.0 Release Notes.
其中 Scala 2.12 带来的主要特性在于对 Java 8 的充分支持:
- Scala 可以有方法实现的 trait 直接编译为带默认方法的 Java 接口
- Lambda 表达式无需生成相应的类,而是用到
invokedynamic字节码指令(这个是 Java 7 加进来的新指令) - 最方便的功能莫过于终于支持 Java 8 风格的 Lambda,即功能性接口的 SAM(Single Abstract Method)
Scala 的 Lambda 内部实现
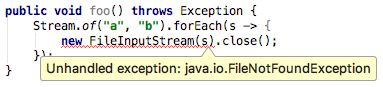
这儿主要是体验 Scala 2.12 如何使用 Java 8 风格的 Lambda. 在 Scala 2.12 之前,Scala 对 Lambda 的支持是为你准备了一大堆的 trait 类,有
- Function0, Function1, ...... Function22 (接收多个参数,返回一个值)
- Product1, Product2, ...... Product22 (函数返回多个值,即 TupleX 时用的)