使用 SQL Server 的 uniqueidentifier 字段类型
SQL Server 自 2008 版起引入了
SQL Server 的
本文所使用的 SQL Server 是 2017 版,通过 Docker 来启动的
默认值也可以指定为
关于
第三条语句在第二条 id 的小写形式,破坏了唯一性约束,因为大小写字符串只是一种外面表现形式,第四条语句把第一个字母改成了
所以往数据库表中插入或更新
查询
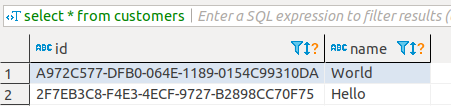 展示为字符串,因为大小写不敏感,所以下面的条件查询
展示为字符串,因为大小写不敏感,所以下面的条件查询
JDBC 操作
也是把它当作字符串来看待,
执行后插入一条新记录,并查询显示出所有的记录
SQL Server JDBC 驱动的 PreparedStatement 实现类是
总之 SQL Server 的
链接:
永久链接 https://yanbin.blog/use-sql-server-uniqueidentifier-data-type/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
uniqueidentifier 字段,它存储的是一个 UUID, 或者叫 GUID,内部存储为 16 个字节。SQL Server 可用两个函数来生成 uniqueidentifier, 分别是 NEWID() 和 NEWSEQUENTIALID(), 后者只能用作字段的默认值。Java 也有一个 UUID 工具类 java.uti.UUID, UUID.randomUUID().toString() 生成一个随机的 UUID 字符串,在 java.util.UUID 也是用两个 long 字段表示内部状态。SQL Server 的
uniqueidentifier 类型字段表明了内部如何存储,在我们操作它时,它的外在表现形式都是一个固定格式 `xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx` 的字符串,不区分大小写的。本文所使用的 SQL Server 是 2017 版,通过 Docker 来启动的
docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=yourStrong(!)Password' -p 1433:1433 -d microsoft/mssql-server-linux:2017-latest然后我们创建一个带有
uniqueidentifier 类型字段的表1CREATE TABLE customers (
2 id UNIQUEIDENTIFIER PRIMARY KEY DEFAULT NEWID(),
3 name VARCHAR(36)
4)默认值也可以指定为
NEWSEQUENTIALID(), uniqueidentifier 字段不指定默认值也没问题。上面把 id 设置为主键,接下为了验证大小写的问题。关于
NEWID() 与 NEWSEQUENTIALID() 的一个显著区别是SELECT NEWID(); --这句是合法的用 SQL 语句插入
SELECT NEWSEQUENTIALID(); -- 这条语句出错,提示该函数只能用作创建表时 uniquidentifier 类型字段的默认值
1insert into customers(id, name) values(newid(), 'Hello');
2insert into customers(id, name) values('A972C577-DFB0-064E-1189-0154C99310DAAC12', 'World');
3
4--以下两条语句均会失败
5insert into customers(id, name) values('a972c577-dfb0-064e-1189-0154c99310daac12', 'loser case');
6insert into customers(id, name) values('X972C577-DFB0-064E-1189-0154C99310DAAC12', 'Not a GUID');第三条语句在第二条 id 的小写形式,破坏了唯一性约束,因为大小写字符串只是一种外面表现形式,第四条语句把第一个字母改成了
X 后,它实际不是一个有效的 GUID。所以往数据库表中插入或更新
uniqueidentifier 字段时,相当于把字符用 java.uti.UUID.fromString("your-input") 转换输入为 UUID 对象- 如果不能转换为 UUID 对象,操作失败
- 转换后的 UUID 对象再看是否违反了唯一性约束,因此输入字符的大小写不敏感
查询
uniqueidentifier 字段
展示为字符串,因为大小写不敏感,所以下面的条件查询select * from customers where id='a972c577-dfb0-064e-1189-0154c99310daac12'也可以查出 name 为 "World" 的记录,由于 SQL Server 是把该字符串转换为 UUID 来比较的,因此与输入的外在形式无关。
JDBC 操作
uniqueidentifier 字段也是把它当作字符串来看待,
rs.getString(..), pstmt.setString(index, "<UUID-STRING>"),只是这个字符串必须是一个符合规格的 UUID。 1DriverManager.registerDriver(new SQLServerDriver());
2Connection conn = DriverManager.getConnection(
3 "jdbc:sqlserver://localhost;databaseName=master", "sa", "yourStrong(!)Password");
4
5PreparedStatement pstmt = conn.prepareStatement("insert into customers(id, name) values(?, ?)");
6
7pstmt.setString(1, UUID.randomUUID().toString());
8
9//下面三行也能用来设置 uniqueidentifier 字段的值
10//pstmt.setString(1, "98F99731-9AB0-4CF7-A861-051771E481F9");
11//pstmt.setObject(1, UUID.randomUUID().toString());
12//pstmt.setObject(1, UUID.randomUUID()); //JDBC 驱动还是会调用 UUID 的 toString() 方法
13
14pstmt.setString(2, "From JDBC");
15
16pstmt.execute();
17
18ResultSet rs = conn.createStatement().executeQuery("select * from customers");
19while (rs.next()) {
20 System.out.println(rs.getString(1) + "=>" + rs.getString(2)); //getObject(1) 也是 String 类型
21}执行后插入一条新记录,并查询显示出所有的记录
A972C577-DFB0-064E-1189-0154C99310DA=>World还有一个小发现就是,查询显示出来的结果与插入的顺序是不一致的。
4A69AA7E-2136-48B2-951C-3EC52942534D=>From JDBC
2F7EB3C8-F4E3-4ECF-9727-B2898CC70F75=>Hello
pstmt.setObject(1, UUID.randomUUID())也没问题,上面最终也是会调用 UUID.randomUUID().toString() 方法,说到底 SQL Server 在插入该字段数据之前收到的还是一个字符串。
SQL Server JDBC 驱动的 PreparedStatement 实现类是
SQLServerPreparedStatement, 它有 setUniqueIdentifier(...) 方法,不过仍然是接收字符串,与 setString(...) 没什么不同。1SQLServerPreparedStatement pstmt = (SQLServerPreparedStatement) conn.prepareStatement("insert into customers(id) values(?)");
2pstmt.setUniqueIdentifier(1, UUID.randomUUID().toString());总之 SQL Server 的
uniqueidentifier 字段是内部存储 16 字节,外部表现为字符串的类型,操作是接受的字符串必须是一个合法的 GUID(UUID) 串就行。链接:
永久链接 https://yanbin.blog/use-sql-server-uniqueidentifier-data-type/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。