
说起 PGP(Pretty Good Privacy) 的工作原理,类似早期的 TLS/HTTPS 的 RSA 密钥交换,只不过它不依赖于第三方的 CA,而是直接在两端以信任的方式直接交换了公钥和私钥。 它是基于以下几点进行工作的
- 用工具(如 PGPTool 或 GnuPG) 生成公钥和私钥对,公钥发给加密方,私钥保存在解密方
- 公钥加密的数据只能用相应的私钥解密,这是非对称加密
- 由于非对称加密解密的计算量较大,通常用一个较小随机 Key 对数据进行对称加密,而只对 Key 用公钥进行非对称加密,再把对称加密的数据与非对称加密的 Key 发给解密方,在解密方用私钥解密出 Key, 再对数据进行解密。-- 这称之为混合加密,也是目前 HTTPS 的工作方式
- 另外,在只持有公钥的一方可以对使用私钥加密的数据进行签名验证,验证数据是否是由持有私钥的一方签发的,这就是数字签名的工作原理
- PGP 也会对生成的私钥用一个口令对其进行加密,防止私钥被盗时进一步保护
- 只用私钥可以做加解密与签名验证,如加密的数据能用相同的私钥解密,私钥签名再私钥验证。但交换私钥是不安全的,所以才有了可公开的公钥,非对称加密
下面用 GnuPG 和 Java 的 Bouncy Castle 包 进行演示加解密的过程。
Read More
接下来,我们将改进自注意力机制,引入因果机制和多头机制。因果机制是让模型预测只访问前序的 token,多头机制是将注意力机制分成多个 "头", 每个头关注数据的不同特征,以提升模型在复杂任务中的性能.
使用因果注意力(causal attention) 隐藏未来词汇
前一文学过的自注意力,对于当前 token 会计算它与所有 token 的注意力分数(相似度),而因果注意力(又称掩码注意力: masked attention)在预测时只需关注当前和前序 token. 这是符合前因后果自然逻辑的,还是拿读书作类比,想要弄清楚当前在讲什么,我们只用去翻看前面有过什么说明与铺叙.
现在将通过标准自注意力机制来创建因果注意力机制,对于每个处理的 token, 需要遮盖住当前 token 之后的 token,参考以下两个图:
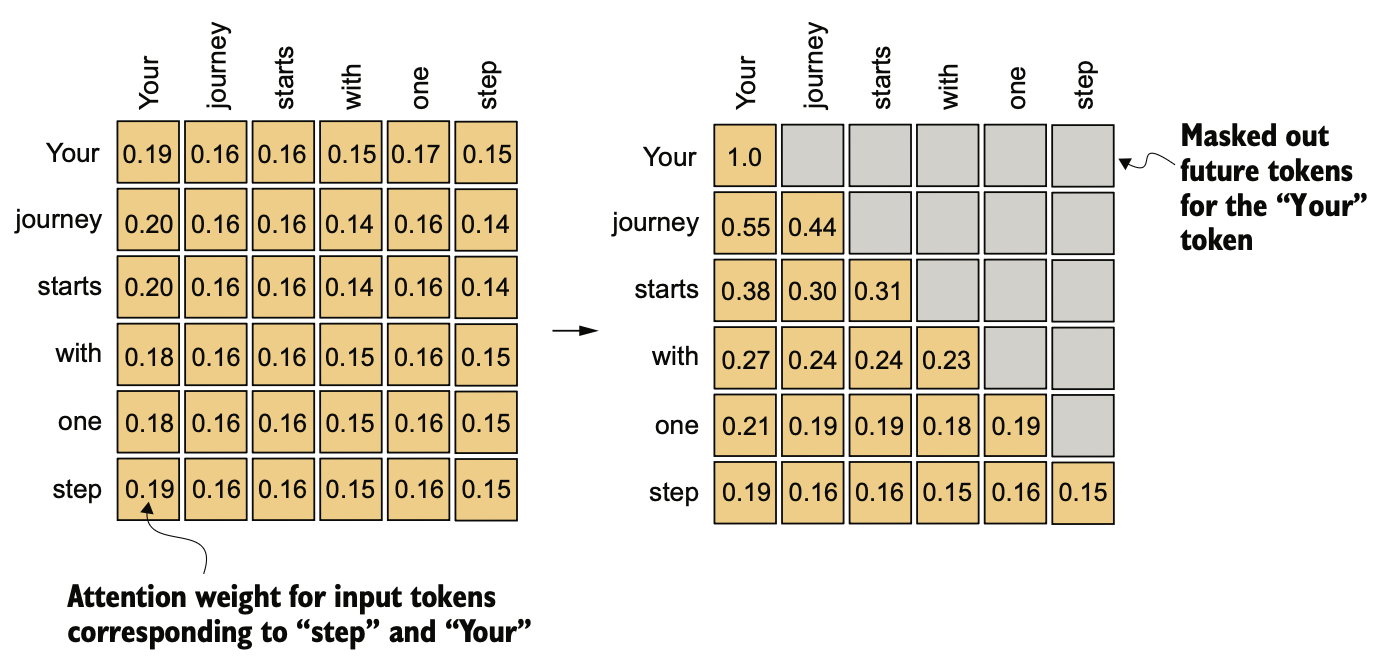
左图是标准注意力机制,在按序处理每一个输入 token 时会计算它与所有 token 的注意力分数,而右图的因果注意力机制,只关注当前 token 之前的 token, 比如处理第一个 token "Your" 时只关注它自己,处理第二个 token "journey" 时只关注 "Your" 和 "journey" 两个 token, 以此类推.
Read More来到第三章,关于注意力机制(attention mechanism), Transformer 可以说是由《Attention Is All You Need》这篇论文起的火,那 Attention 几乎就是 Transformer, 也就是现代 LLM 的核心。在学习 Attention 之前先通过类比的方式理解一下什么是注意力机制,以及为什么取名为 Attention 这个词.
当你读到一句话里某个词时,你的大脑不会孤立地看这个词,而是会"环顾四周"——看看其他词,决定哪些词对理解当前这个词最有帮助,然后把注意力集中在那些词上。 LLM 的 Attention 机制,做的正是同一件事。而且通常看书时,多是翻看前面的部分,帮助当前的理解,找到故事的因果关系, 很少查阅后面的内容, 这就是因果注意力.
本章将由浅入深的介绍以下 Attention 各种变体的原理和实现细节。
- 简化的自注意力(Simplified self-attention)
- 自注意力(Self-attention): 带有可训练权重的自注意力机制
- 因果注意力(Causal attention): 只关注序列中先前和当前的输入,从而保持文本生成的时间顺序
- 多头注意力(Multi-head attention): 自注意力和因果注意力的组合,可同时关注来自不同表示子空间的信息
读完《Hands-On Large Language Models》又回头重新看《Build a Large Language Model from Scratch》一书,阅读时零乱记点什么。
大语言模型构建通常包括两个阶段: 预训练(pre-training)和微调(fine-tuning), 有时也把偏好调优当作一个单独阶段,其实也是一种形式的微调。 预训练使用未标注的大量文本数据理解语言结构,即自监督学习,预训练生成的模型为基础模型(base/foundation model), 这能够完成文本预测任务。 再经过指令微调或分类任务微调后就能回答问题或进行分类了。
Transformer 架构最初由 Google 于 2017 年的论文 "Attention is All You Need" 提出,它已成为了现代大语言模型的基础架构,基本上 LLM 指的就是这种架构。 Transformer 的两个子模块:编码器(encoder)和解码器(decoder), 一大关键组件是自注意力机制(self-attention), 使模型能够捕捉输入序列中不同位置之间的关系和依赖性。 Transformer 的并行处理能力和长距离依赖建模能力使其成为了训练大规模语言模型的理想选择。Transformer 的变体有 BERT(Bidirectional Encoder Representations from Transformers)、GPT(Generative Pre-trained Transformer)等。
GPT-3 基础模型预训练数据集为过滤后的 Common Crawl, WebText2, Book1, Books2, 和 Wikipedia, 在共 3000 亿 Token 上进行训练, 文本压缩后大小为 700G 左右。Llama 扩展了它的训练数据范围,包括 Arxiv 论文(92G)和 StackExchange 上的代码问答(78G)。训练基础模型成本极高, GPT-3 的预训练成本高达 460 万美元。
Read More
这应该是阅读本书的最后一篇笔记了,下一本书的目标是《Build a Large Language Model (From Scratch)》。大模型的三步走,预训练、微调、和偏好调优。 本篇的来了解最后一步偏好调优, 对齐(Preference-Tuning / Alignment RLHF), RLHF 是一个像那些 RoPE, LoRA, MoE, SFT 等经常见得着但不知道意义的高级词。 RLHF(Reinforcement Learning from Human Feedback): 用人类的偏好判断来训练一个"打分模型",再用强化学习让语言模型朝高分方向优化。
模型经过指令微调后更听话了,我们还要最后的训练来进一步改进其行为,使用与我们期望它在不同场景中的表现保持一致。做法就是让一个偏好评估者(人或其他方式) 评估模型生成内容的质量
- 如果分数较高,更新模型,以鼓励它产生更多这类生成内容
- 如果分数较低,更新模型,以抑制它产生这类内容
我们可以训练一个叫作奖励模型(reward model) 的模型来实现偏好评估自动化,是要在偏好调优步骤之前增加一个步骤,即训练一个奖励模型
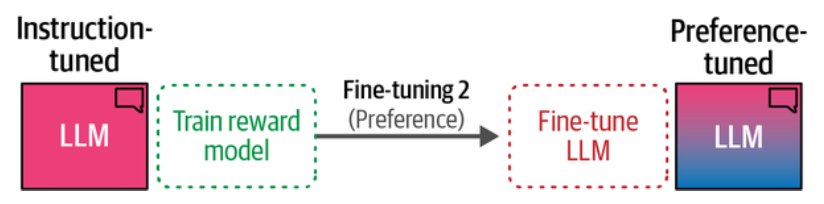
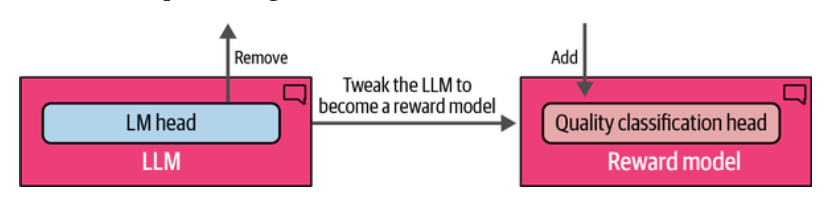
经过指令微调的模型,去掉建模头(LM Head), 加上质量分类头(Quality classification head), 让该分类头只输入单一的分数。如果观察前一篇微调出来的模型
Read MoreTinyLlama-1.1B-sft它最后有一个lm_head层。终于来到最后一章了,要学习是如何微调生成模型,生成模型才是天天所面对的模型,嵌入模型只在需要 RAG 或者模型记忆的时候才会用到,而用表示模型进行分类的场景还是极少。 对于私有数据资料应该用 RAG 还是微调生成模型呢?到目前为止自己也拿不准,因为还只会 RAG, 学完了本章会有一个更感性的认识。 相较于微调表示模型, 微调生成模型后可以进行更直接的交互用以验证微调的效果。在本章会接触到不少炫目的名词,如 SFT, RLHF, PEFT, LoRA, QLoRA, DPO 等。
微调生成模型有两种最常见的方法: 监督微调(Supervised fine-tuning) 和偏好调优(preference tuning)
LLM 训练三阶段: 预训练,监督微调,偏好调优
语言建模(Language Modeling)
或称预训练(Pre-training)阶段,简称 PT, 使用海量无标注文本数据进行预训练,这一阶段是最贵的,一般公司是玩不起的。它的目标是学习语言的统计规律, 预测下一个词是什么,或者给定上下文预测缺失的词是什么。预训练阶段的模型被称为基座(Base)模型,通常也称为预训练(Pretrained)模型或基础(Foundation)模型。
比如模型在输入 "法国的首都是" 后,预测下一个词是 "巴黎"。它还听不懂指令,不回答问题,比如对于输入 "解释黑洞是什么?", 基础模型只会续写,比如
输入:
Read More把'苹果'翻译成英文基础模型续写:把"苹果"翻译成英文:苹果的英文是apple,另外橙子是orange,香蕉是banana……一鼓作气,继续阅读本书,来到了第十一章,本章的标题是 “为分类任务微调表示模型”,而嵌入模型也是表示模型的一种,前一章有学过如何训练和微调嵌入模型。 第 4 章中学习了使用预训练模型进行文本分类,本章将要学习对 BERT 模型的多种微调方法,以适应分类任务。还是文本分类,下一章也就是原书的最后一章才会讲到微调生成模型, 这才是本人更加期待的内容,还是按顺序来消化吧。
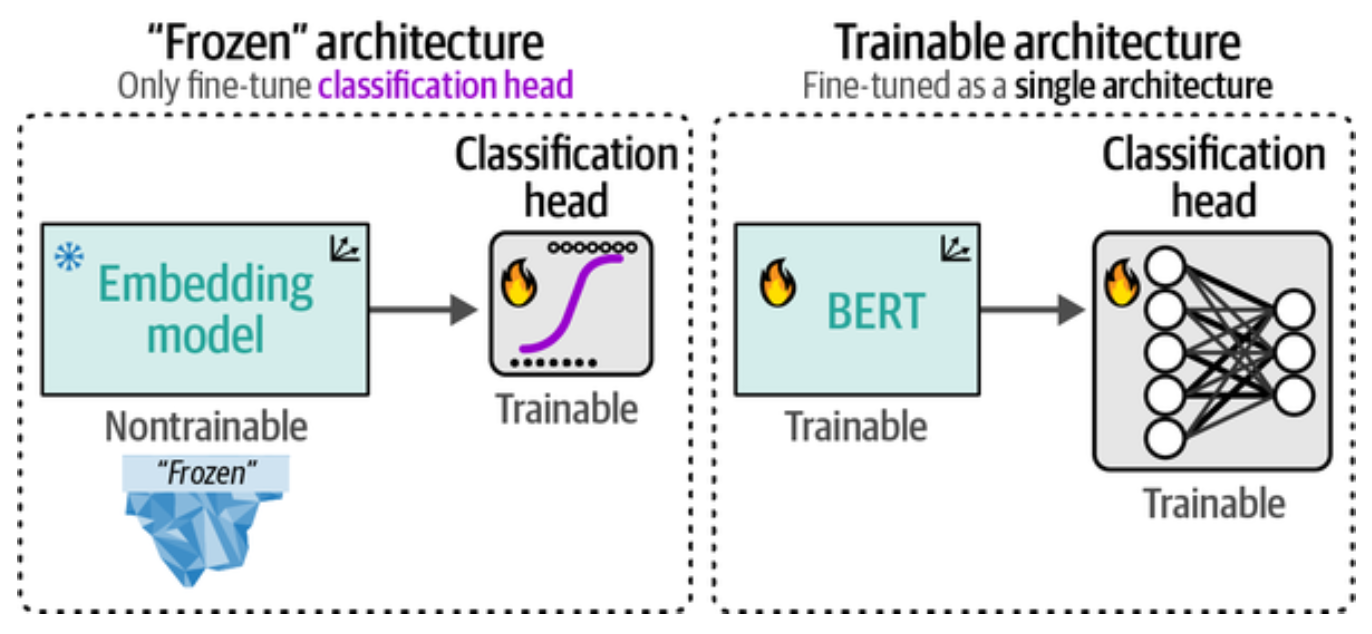
在第 4 章处理监督分类时采用过两类模型:特定任务模型(如情感分析)和用于生成文本嵌入表示的嵌入模型。在微调时是否要冻结一部分参数可分为参数高效微调与全量微调
 Read More
Read More第三部分: 训练和微调语言模型 - 微调嵌入模型
仍然是第 10 章的部分,会学习到微调嵌入模型,监督学习(Supervised Learning)和无监督学习(Unsupervised Learning)的内容。 前面学习的其实也是在一个基础模型的基础上创建一个嵌入模型。
本书把以
bert-base-uncased作为基础模型创建嵌入模型叫做从头开始训练嵌入模型,有点不理解。bert-base-uncased本身就是一个预训练的基础模型, 它的训练语料是 BookCorpus + English Wikipedia, 共约 33 亿词。而所谓的微调嵌入模型就是把bert-base-uncased换为另一个预训练的 sentence-transformers 模型。这与前面的训练过程又有何区别呢?因为
bert-base-uncased就可以直接用来对句子生成嵌入向量,比如下面的代码可得到句子的嵌入向量1from sentence_transformers import SentenceTransformer 2 3model = SentenceTransformer('bert-base-uncased', device="cuda") 4embeddings = model.encode(["The weather is nice today"])所以本章的微调嵌入模型时所谓的监督学习不过是把前面的基本模型换成了另一个专门用对比学习预训练过的
Read Moreall-MiniLM-L6-v2模型,其他代码完全就没变。 选基础模型的时候还得了解它是怎么训练的,训练语料是什么样的,训练目标是什么样的,这样才能知道它适不适合用来微调嵌入模型。第三部分: 训练和微调语言模型 - 构建文本嵌入模型
终于来到了可以真正实战的部分,前面的章节都是关于理解和使用大语言模型的知识,现在可以开始动手实践了。涉及到训练和微调模型, 不过本书只讲了如何训练一个嵌入模型,要学习训练一个生成模型的知识还得看 Build a Large Language Model (From Scratch) 这本书,或者参考 Karpathy 的 nanoGPT 项目。
先从构建一个文本嵌入模型开始吧。嵌入模型是 NLP 的基础,它可应用于多种场景, 如监督分类(supervised classification), 无监督分类(unsupervised classification), 语义搜索等, 甚至为 ChatGPT 赋予记忆功能。
嵌入模型的功能就是把非结构化的文本转换为数值表示的向量,这样才可计算,这一转换过程称为嵌入(embedding)。对输入进行嵌入通常由 LLM 执行, 这样的模型就是嵌入模型。嵌入模型可针对多种目的进行训练,如基于语义,或情感的分类等,比如通过微调使嵌入模型关注情感倾向,通过向模型展示足够多的语义相似文档, 引导模型向语义分析的方向发展,使用情感数据则向情感分析的方向发展。
训练,微调和引导嵌入模型的方法很多,其中最强大的且应用最广泛的技术是对比学习。
对比学习
对比学习是训练和微调文本嵌入模型的一种主要技术。对比学习的目标是训练嵌入模型,使相似文档在向量空间中距离更近,而不相似文档相距更远。 对比学习的基本理念是,向模型输入相似的和不相似的文档对作为示例,这是学习文档之间的相似性或差异性并构建相关模型的最佳方式。
Read More第九章:多模态 LLM
本书第二部分(使用预训练模型)除了 "文本分类","文本聚类和主题建模" 两章外,其他的 "提示词工程", "高级文本生成技术与工具","语义搜索与 RAG" 这三章都只是对原有知识的巩固. 现在学习本部分的最后一章 "多模态 LLM" 应该能了解到一些模型处理图片的相关知识, 这对我来说是新的知识。
多模态就是指模型能够处理多种类型的数据,比如文本、图像、音频等,而不仅仅是文本,如果你的模型只能处理图像和音频也是多模态。视觉 Transformer (Vision Transformer, ViT) 在图像识别任务中超越了传统的卷积神经网络(CNN)。ViT 的核心功能是将非结构化的图像数据转换为可用于分类等任务的数值表示。 像处理自然语言一样来处理图像。
对于文本,Transformer 编码器对文本拆分再编码成数值表示,对文本的切割看成是一维的,ViT 对图像按水平方向和垂直方向进行网格化切割成小块,这和 CNN 用卷积核来提取图像特征的方式类似。
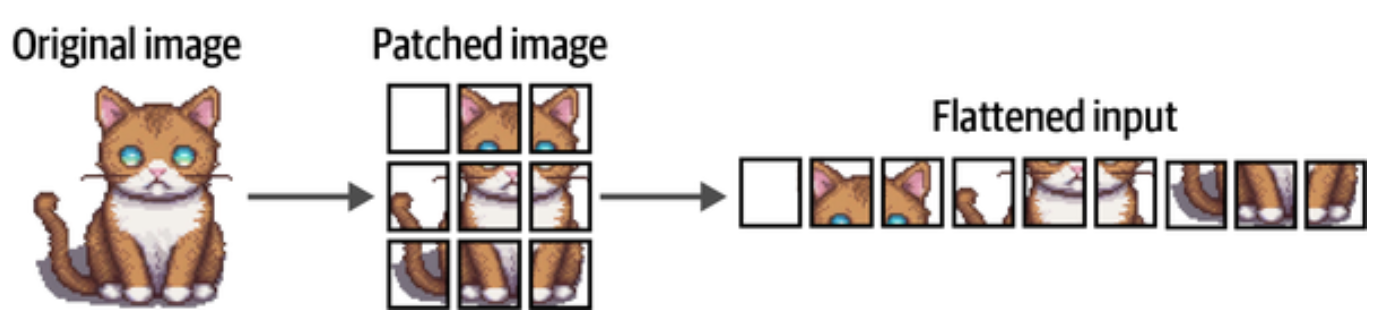
文本的词汇量是有限的,所以可以把文本分割的 Token 映射为一个数值,切成的图片块太过多样性,无法为每一种可能的图片块分配一个 Token. Transformer 的做法是把图片块平铺后对所有图像块实施线性嵌入操作,像文本嵌入一样把一组图片块转换为嵌入向量。这些蕴含语义信息的向量便可作为 Transformer 模型的标准化输入。
Read More