
前年记录过一篇 创建可直接用 root 用户 ssh 登陆的 Docker 镜像, 采用了基础镜像是 Ubuntu:20.04. 因为在 AWS 使用 AmazonLinux 2023 更为频繁,为贴近生产环境,本地开发也使用基本 AmazonLinux 2023 为基础镜像的容器,与 IDE 连接以 SSH 协议, 容器的操作由自己的控制,而非直接使用 devcontainer 的方式。比如可以在 Windows 或 macOS 进行 Linux 相关的开发。
当今 Linux 主要还是两个发行版,一个是 RedHat 的家族,一个是 Debian 的家族,之前验证过 Debian 族的 Ubuntu, 这次要验证 RedHat 族的 AmazonLinux 2023, 也作为将来不时之需。
创建允许 root + 密码登陆的镜像
Dockerfile 内容为
Read More
各种 AI 编程工具,如 Codex, Claude Code, Gemini 等提供了一些类似的斜线命令,每个斜线命令大约也是对应着一段特定的提示词。由于工作中更方便的使用 Copilot, 所以本文来探讨如何定义自己的 Copilot 斜线命令。比如想要定义一个命令
/c2py-dataclass用于实现把 C/C++ 的类或结构转换成 Python 的 @dataclass 类,并遵循 Python 的命名规则和设置默认字段值, 也就是采用如下提示词Covert following C/C++ class/struct to Python dataclass, following Python naming convention, and set default field values.
<C/C++ source code goes here>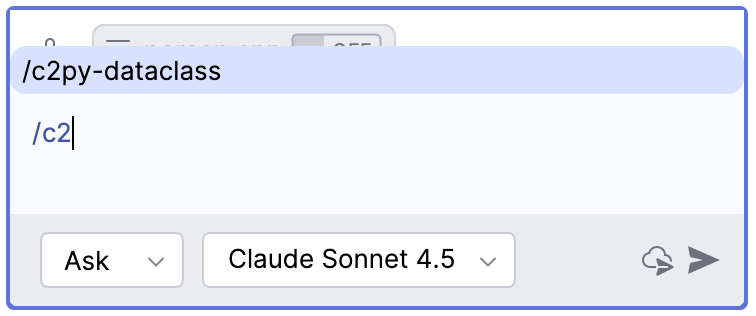
有了自定义的
/c2py-dataclass命令的话,就不需要每次重复上面的描述,而只用输入/c2py-dataclass然后指定某个 C++ 代码文件或粘贴 C/C++ 代码就能实现转换需求。实现方式可以借鉴几天前写的一篇 准备迎接 Vibe Coding - 相关工具与资源 中关于 Spec Kit 一节。
实现方法
开门见山吧,想要添加一个自定义的命令,如
/c2py-dataclass, 仅需在项目目录中添加.github/prompts/c2py-dataclass.prompt.md文件, 立马就会在 Copilot 中出现一个/c2py-dataclass命令,在.github/prompts/c2py-dataclass.prompt.md添加所需的提示词即可。要像
Read MoreSpec Kit那样的话可以使用两个文件.github/agents/c2py-dataclass.agent.md和.github/prompts/c2py-dataclass.prompt.md来配合。
最近在紧锣密鼓的用 Python 写代码,不是 Vibe Coding 那种,因为在真实的敲代码才能碰到一些与 Python 语言相关且容易踏入的坑,记录如下
Python 3.8 引入的 Walrus 操作
即赋值表达式,
:=的使用形式,像海象的两个牙。:=让赋值有了返回值, 该赋值语句的返回值就是右边的值。C/C++ 的=同时具有 Python 的=和:=的功能。我们在 Python 中的
=与:=对比1>>> print(a=1) 2Traceback (most recent call last): 3 File "<python-input-0>", line 1, in <module> 4 print(a=1) 5 ~~~~~^^^^^ 6TypeError: print() got an unexpected keyword argument 'a' 7>>> print(a:=1) 81Python 的这种赋值又有返回值的
Read More:=功能就可以应用到if或while语句中,例如
前篇 MacOS/Linux C++ GDB 远程调试基础 演示了如在 macOS 开发调试远程 Linux 下的 C++ 程序, 本篇将结合 C 语言静态库与动态库的生成和使用 练习如何调试含动态库,静态库的 C++ 程序, 并了解如何指定符号文件。
示例源码
本文将用以下的目录结构, 分别验证主程序与动态库,静态库的源代码断点调试,以及把源文件放在不同目录中是否有特别之处。
Read More1├── dynamic # 动态库 2│ └── add.cpp 3├── static # 静态库 4│ └── sub.cpp 5└── main.cpp # 主程序有那么一个古老的项目,编译用的是 g++, 目标平台的是 Linux x86_64, 构建工具是 make. 本地开发环境是 macOS, 硬件为 Arm64 的苹果芯片 M4, IDE 尝试用 CLion, 如果喜欢的话,也可以选择 VSCode.
想要单步调试的目的就是想让代码跑起来,然后逐步理解代码执行的逻辑。所以不想对现有项目构建过程进行改造,如换成 CMake, 使用 LLVM 编译之类的。 只想使用远程 Linux 机器, 仍然使用原来的
make命令编译,然后在 Linux 下启动程序,由 Clion 连到的 Linux 上进程, 关联源代码进行调试。因为编译用的 g++, 所以采用 gdbserver 和 gdb 进行远程调用,llvm 相应的解决方案是 lldb-server + lldb. 下面是关键的步骤
. 本地 Clion 中编辑代码 . 代码传到远程 Linux 机器 . 远程 Linux 机器上编译,编译的二进制代码要保留符号信息 . 在 Linux 机器上的符号文件要下载给 Clion . 在远程用 gdbserver 指定端口启动程序 . 本地 Clion 配置用 GDB 连接到远程 Linux 机器上的 gdbserver . 在 Clion 中断点单步调试
上面是基本的操作,当我们用某个客户端工具(比配置运行 Clion 的 Remote GDB Server) 就自动完成以上的某些操作,如自动双向同步源代码与二进制/符号文件, 自动驱动远程端的的编译,启动 gdbserver. 远程 Linux 还能进一步使用 Docker 容器替代。但是在苹果芯片的 macOS 中启动
Read Morex86_64的容器中运行的gdbserver在 macOS 中用 gdb 是连不上的。
前端框架目前基本还是 Vue.js 和 React.js 两大阵营为主流,尽管 Angular.js 版本升的飞快, 事实就是鲜有人问津, 想用 Angular.js 的人何不直接用 Vue.js 呢. 关于 Vue.js 和 React.js 的数据显示, Vue.js 延续了传统模板(如 JSP, Velocity, Freemarker, Thymeleaf)的用法, 通过自定义 Tag, 许多逻辑写到 HTML 里. 而 React.js 则另辟蹊径, 通过 JSX 语法将 HTML 直接写到 JavaScript 里, 页面显示时不夹杂逻辑.
以前算是用 Vue.js 做过一些小项目, 对 React.js 未有多少了解, 现在也算是初学. 刚开始不想从一个
npx create-react-app my-react-app的脚手架开始, 而是想从最原始的 HTML 中引入 React.js 的方式开始学习, 这样可以更清晰地了解 React.js 的工作原理. 也是为使用 React.js 拥抱 Vibe Coding 做准备.基本 React.js Virtual DOM 渲染
用
Read More<script>标签引入 react 和 react-dom 两个核心库的方式已经不推荐了, 官方的 CDN Links 已经变成 Legacy 了, 也找不到引用 react@19 的相关链接了. 但本着要明就里的原则还是希望以这种方式演练一下.
2022 年 11 月 ChatGPT 横空出世, 史称 ChatGPT 时刻, 从那一刻起, 不管你接不接受, 事情正在迅速起变化. 如果写代码从记事本, 一边查文档开始, 到 IDE 的智能提示, 再到 Google 搜索代码, 从 StackOverflow 拷贝代码, 甚至是用 ChatGPT 对话抄写代码这些阶段, 软件工程方面并没有发生太大的变化.
在去年面对 AI 还犹豫做什么的时候, 今年毫无疑问就是 AI Agent. 就目前 AI 最大的成就莫过于解决掉了很多程序员的工作问题. 程序员们在面临 AI 应该作出什么变化的话, 那 Vibe Coding 就不得不认真去看待. Vibe Coding 给我们带来某种快感的同时, 也伴随着焦虑. 从 TDD, BDD, DDD, 到现在的 SDD, 大脑就外包给了 LLM.
Vibe Coding 最早由 OpenAI 联合创始人, 前特斯拉 AI 负责人 Andrej Karpathy 于 2025 年 2 月提出的一个新型编码方式. Vibe Coding 给人一种最直白的感觉就是只与大语言模型对话的形式生成软件, 代码完全是个黑盒, 不直接修改代码, 基本都不看代码, 有编译等问题继续与 LLM 对话. 这种软件生产方式还要像传统方式来 Review 代码就很难了, AI 不辞辛苦生成的大量代码, 可能也不适于人类进行审核了.
Vibe Coding 成就了不少一人一公司, 但也不必过于相信有些人在网络上过份吹嘘的那样--零编程经验, 不写一行代码. 小白确实能用 Vibe Coding 做出一个东西来, 但真零编程经验, 技术框架选型就描述不清, 例如用 Vue.js, React.js, Next.js, 或者什么编程语言适合做什么事情等.
有编程经验搭配上了 Vibe Coding 一定能做的更好. 也别信什么 90% 代码是 AI 写的, Vibe Coding 就是一个黑盒. 那 Vibe Coding 试个多人协作的大型项目. 或者 Vibe Coding 做个银行, 政府, 航空航天项目? 这种关键领域的项目我想每一行代码都必须由人工审核. 所以远古的仍然稳定运行着的 COBOL 代码一直无法升级替换, 换成 AI 也别想简单的就能重写它们, 如果不需要重新测试的话, 那没问题.
Read More
Java 24 也是一个过渡版本, 还是到下面两个链接中找相应的更新
IntelliJ IDEA 对 Java 22 Language level 描述是
- 23 - Markdown document comments
- 22(Preview) - Primitive types in patterns, implicitly declared classes, etc.
把上面第二个链接中的特性列出来
本文对上面用红点标记的特性重点关注
Read MoreJava 22 是一个过渡版本, 还是到下面两个链接中找相应的更新
IntelliJ IDEA 对 Java 22 Language level 描述是
- 22 - Unnamed variables and patterns
- 22(Preview) - Statements before super(), string templates (2nd preview), etc.
把上面第二个链接中的特性列出来
本文对上面用红点标记的特性重点关注
Read More迁移完所有的 WordPress 日志到 Hugo 之后, 终于有时间真正继承学习相关的新技术. Java 21 是于 2023 年 9 月份释放出来的 LTS 版本, 目前主要在用该版. Java 25 LTS 版本已发布, 按正常节奏应该要切换到该版本.
随着 AI 在编程界的花式表演, 所宣传的似乎就是要扑灭他人的学习热情, 编程方面越小白越好, 只要能写好小作文就行了. AI 当然还是要用, 但我对以往多少年传统的学习方式并不感到白花了心血. 告诉 AI 的一个课题 AI 确实能写出一篇漂亮, 规整的博客文章, 但其中有没有胡说八道, 只有试了才知道, 即使生成的文章无误, 也必须实践一遍才有更多更深的斩获.
如果没有相关的技术储备, 每次与 AI 互动的时候都要告诉它尽量用 Java 21 新特性, 因为新引入的特性基本能实现得更简洁, 高效, 估计 AI 才不那么在乎这些, 写出适于人阅读的代码恐怕不是 AI 的首要关注.
还是老办法, 关于 Java 某一版本新特性从两个链接出发
Read More