AWS Lambda 按序处理同一个 Kinesis Shard 中的消息
当 AWS Lambda 由 Kinesis 消息来触发时,一个 Kinesis Shard 会相应启动一个 Lambda 实例,比如说 Kinesis Stream 有 5 个 Shards, 那同时只会启动 5 个 Lambda 实例。那么把多条消息发送到同一个 Kinesis Shard 中去,这些消息会被如何消费呢?答案是按顺消息,不管这些消息是否被不同的 Lambda 实例处理。本文就是关于怎么去理解 https://aws.amazon.com/lambda/faqs/ 的下面那段话的内容:
Lambda 的基础代码如下:
测试环境: Kinesis stream 分配了 2 个 Shards, 每次都运行上面的代码始终向同一个 Shard 发送十条消息
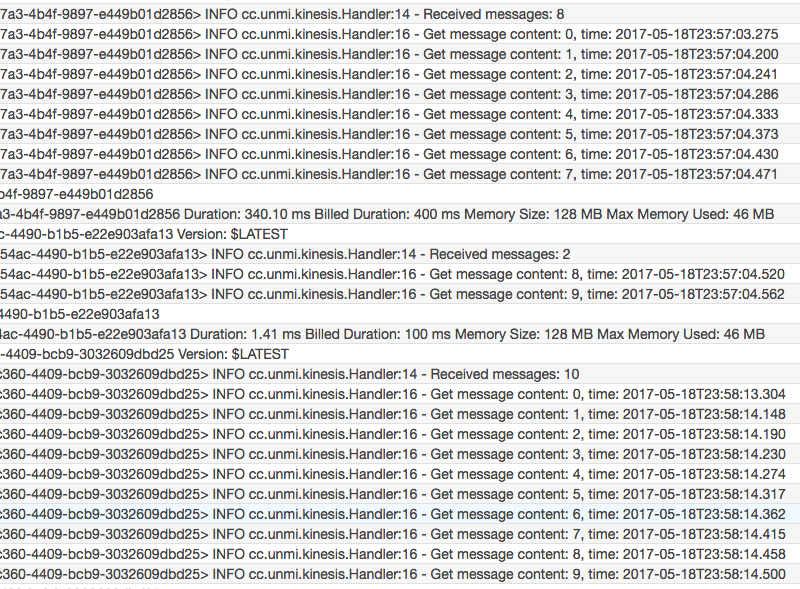
试验一:Lambda 能正常处理每一条 Kinesis 消息,Trigger batchSize: 10, 执行上面代码两次向同一个 Shard 发送了 20 条消息
结果,只启动了一个 Lambda 实例,消息总是按序到达,不管是否在同一个 Batch 中。
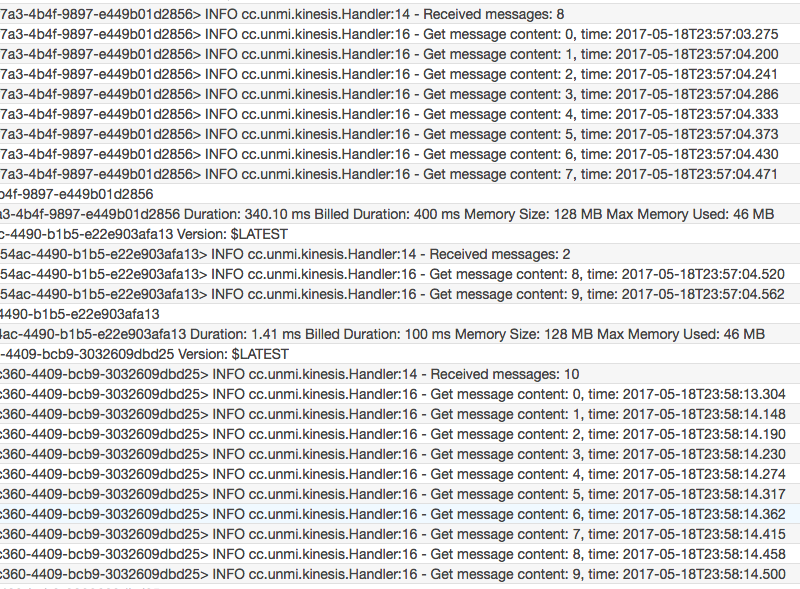
由上图可见,头 10 条消息分两批到达,但顺序总是与发送的顺序一致,永远不可能先收到 8,9,再收到前面的消息
试验二:Lambda 能正常处理每一条 Kinesis 消息,Trigger batchSize: 5, 执行上面代码两次向同一个 Shard 发送了 20 条消息
结果:仍然只启动了一个 Lambda 实例,也是不管消息怎么分批,总是按序到达
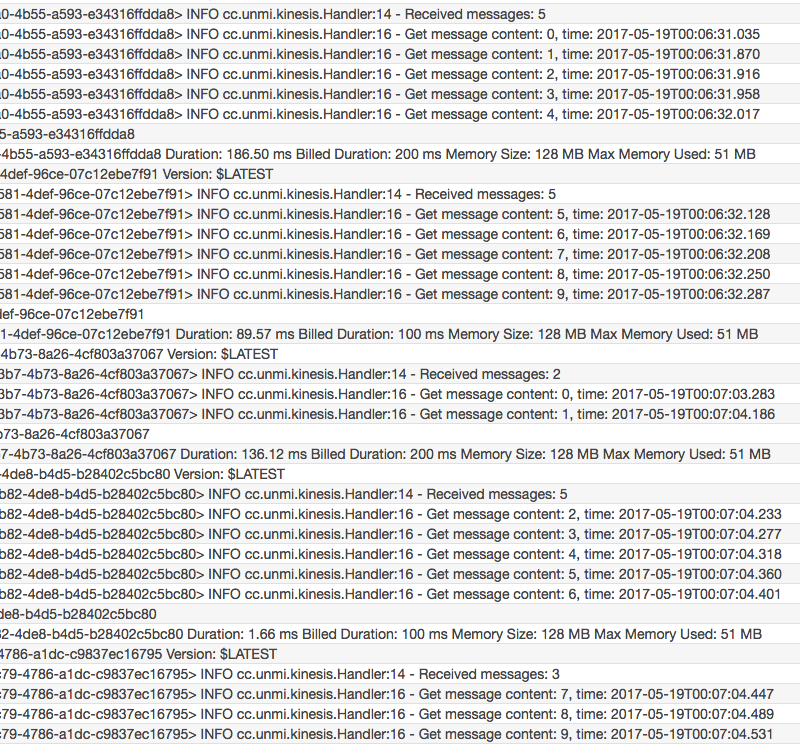
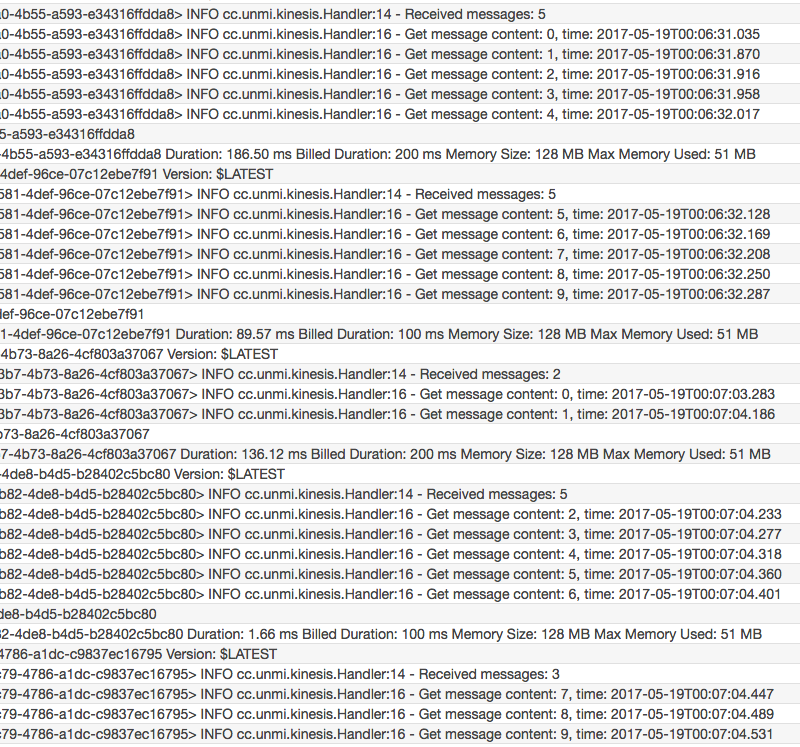
试验三:Lambda 能正常处理每一条 Kinesis 消息,Trigger batchSize: 2, 执行上面代码两次向同一个 Shard 发送了 10 条消息
结果:我的测试中发现启动了两个 Lambda 实例(也可能仍然是一个)来接受消息,两个处理的消息有交错,如下两图
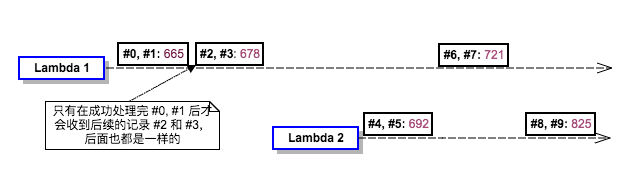
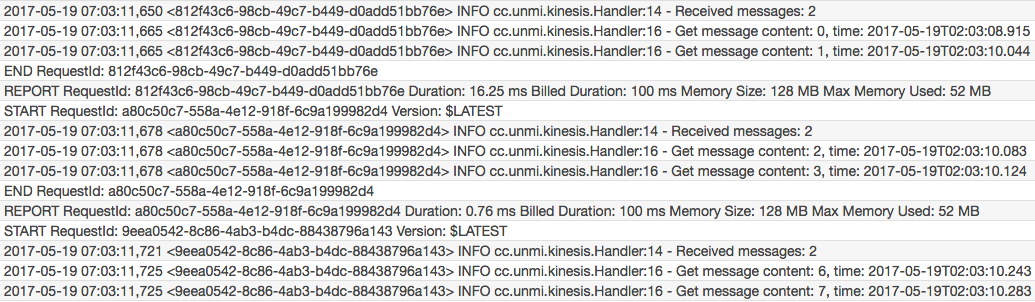
第一个 Lambda 实例收到的消息是 #0, #1, #2, #3, #6, #7; 那么 #4, #5, #8, #9 哪去了呢?被另一个 Lambda 实例处理了

因测试要求,把日志时间精度调到了微秒,由于上面两个 Lambda 实例都是从同一个 Kinesis Shard 上获取的消息,所以它们是有依赖顺序的,Lambda 1 在消费完 #0, #1, #2, #3, 然后是 Lambda 2 收到并消费完 #4, #5,接着又 Lambda 1 消费 #6, #7, 最后才是 Lambda 2 收到 #8, #9。
所以对于发往同一个 Shard 的消息,虽然启动了多个 Lambda 实例,但它们执行并不是并行的,而是依消息顺序执行的。我们把 Trigger 的 batchSize 设置为 1 也是类似的情况,只是一条条记录交错的被两个 Lambda 实例处理。
在试验中试图在 Lambda 处理方法中做一个 1 秒延时(Thread.sleep(1000)),但是测试结果是只要用了 Thread.sleep(...) 延时,只发送消息到同一个 Shard 的话只会启动一个 Lambda 实例,无论 batchSize 是 2 还是 1, 这个很让我惊讶,Thread.sleep(...) 具有某种特异功能。
不管是跨 Lambda 实例,只要发往同一个 Kinesis Shard 的消息总是被顺序处理,这里要注意个问题,不仅仅是按顺序接收到,而是只有前面的消息被 Lambda 成功处理完才接受后续的消息。如果前面的消息未被成功处理,将会重试直到成功,而后才能接收处理后续的消息,可以在 Lambda 抛出一个异常来测试
试验四:Lambda 抛出异常,观察是否能接收后面的消息
在 Lambda 处理方法最后的 return 语句替换为抛出异常,如下
 重试多少次呢?没有限制,如果总是不成功的话,这个 Lambda 实例基本是废掉了,一直重试到这条消息过期了才放弃(最少24小时), 重试的间隔时间当然不是每隔几秒钟,目测像是一个斐波那契序列,也就是说越来越疏。我们仍然可以继续往这个 Shard 上发送消息,也能立即触发那个 Lambda, 只是每次触发都是消费最初的老记录,下面的图可以辅助理解 Kinesis Stream Shard 上的消息的处理流程。
重试多少次呢?没有限制,如果总是不成功的话,这个 Lambda 实例基本是废掉了,一直重试到这条消息过期了才放弃(最少24小时), 重试的间隔时间当然不是每隔几秒钟,目测像是一个斐波那契序列,也就是说越来越疏。我们仍然可以继续往这个 Shard 上发送消息,也能立即触发那个 Lambda, 只是每次触发都是消费最初的老记录,下面的图可以辅助理解 Kinesis Stream Shard 上的消息的处理流程。
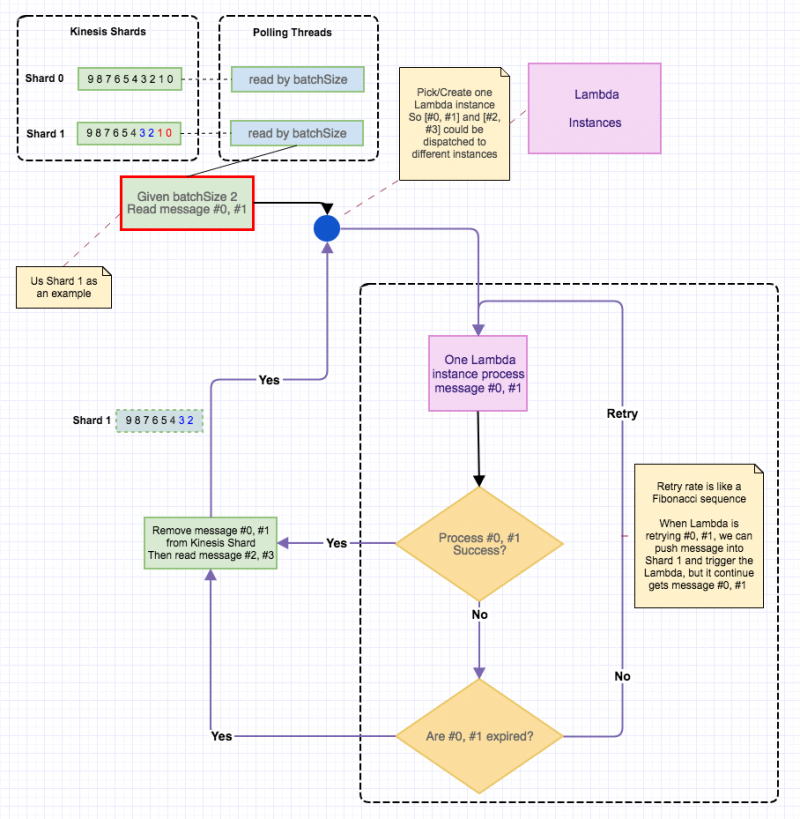 1) 每个 Kinesis Shard 会有一个线程从中轮询数据,如指定 Trigger 的 batchSize 是 10 的话,会每次最多取 10 条记录,只有 2 条的就只会取到 2 条记录,得到记录后选择一个 Lambda 实例来处理它们
1) 每个 Kinesis Shard 会有一个线程从中轮询数据,如指定 Trigger 的 batchSize 是 10 的话,会每次最多取 10 条记录,只有 2 条的就只会取到 2 条记录,得到记录后选择一个 Lambda 实例来处理它们
2)同一个 Shard 中的记录总是按序处理,如上图所示,只有 #0, #1 被成功处理后,才会从 Stream 中删除它们,然后取后续的 #2, #3。#0, #1 失败一直重试,直到成功或记录到期,这时队列阻塞住了
这是 AWS Lambda 关于重试策略 http://docs.aws.amazon.com/lambda/latest/dg/retries-on-errors.html 的一段
关于 Lambda 出错重试,还需要更深入些。
2016-08-24: Kinesis 的的实现就是 Kafka, 所以 Shard 就是 Kafka 的 Partition。一个 Kinesis 能触发的 Lambda 实例就相当于一个 Kafka Topic 的同 GOUPD ID 的 Consumer, 因此最多只需要启动与 Shard 数目一样的 Lambda 实例,多了也没用。每个 Lambda 实例每次只从同一个 Shard 取若干条(Trigger batchSize 决定的) 消息记录, 完全消费成功这些记录才能提交消息的 Offset(Kafka 中的概念, Kinesi 中叫做 MessageId), 否则不断的重试。 永久链接 https://yanbin.blog/aws-lambda-consume-messages-from-one-share-in-series/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
Q: How does AWS Lambda process data from Amazon Kinesis streams and Amazon DynamoDB Streams?可以做几个试验,下面的代码可以保证消息总是被发送到同一个 Kinesis Shard,因为 PartitionKey 参数是一个常量
AWS Lambda 如何处理来自于 Amazon Kinesis 和 DynamoDB 的数据 The Amazon Kinesis and DynamoDB Streams records sent to your AWS Lambda function are strictly serialized, per shard. This means that if you put two records in the same shard, Lambda guarantees that your Lambda function will be successfully invoked with the first record before it is invoked with the second record. If the invocation for one record times out, is throttled, or encounters any other error, Lambda will retry until it succeeds (or the record reaches its 24-hour expiration) before moving on to the next record. The ordering of records across different shards is not guaranteed, and processing of each shard happens in parallel. 从 Kinesis 和 DynamoDB 单个 Shard 上的记录会被 Lambda 严格的按序处理。这意味着如果你送两条记录到相同的 Shard, Lambda 将会保证第一条记录成功处理后才会处理第二条记录。假如处理第一条记录时超时,或超过资源使用上限,或碰到任何错误, Lambda 将会不断重试直到成功(或记录在 24 小时后过期), 而后才会去处理下一条记录。跨 Shard 的记录不保证到达顺序,且是并行处理多个 Shard 来的记录。
1AmazonKinesis kinesis = AmazonKinesisClientBuilder.defaultClient();
2for (int i = 0; i < 10; i++) {
3 PutRecordResult result = kinesis.putRecord(kinesisStream, ByteBuffer.wrap(
4 (i + ", time: " + LocalDateTime.now()).getBytes()), "key");
5 System.out.println("ShardId: " + result.getShardId() + ", #Seq: " + result.getSequenceNumber());
6}1@Override
2public String handleRequest(KinesisEvent event, Context context) {
3 LOG.info("Received messages: " + event.getRecords().size());
4 event.getRecords().forEach(record -> {
5 LOG.info("Get message content: " + new String(record.getKinesis().getData().array()));
6 });
7 return "";
8}试验一:Lambda 能正常处理每一条 Kinesis 消息,Trigger batchSize: 10, 执行上面代码两次向同一个 Shard 发送了 20 条消息
结果,只启动了一个 Lambda 实例,消息总是按序到达,不管是否在同一个 Batch 中。
由上图可见,头 10 条消息分两批到达,但顺序总是与发送的顺序一致,永远不可能先收到 8,9,再收到前面的消息
试验二:Lambda 能正常处理每一条 Kinesis 消息,Trigger batchSize: 5, 执行上面代码两次向同一个 Shard 发送了 20 条消息
结果:仍然只启动了一个 Lambda 实例,也是不管消息怎么分批,总是按序到达
试验三:Lambda 能正常处理每一条 Kinesis 消息,Trigger batchSize: 2, 执行上面代码两次向同一个 Shard 发送了 10 条消息
结果:我的测试中发现启动了两个 Lambda 实例(也可能仍然是一个)来接受消息,两个处理的消息有交错,如下两图
Lambda 1
第一个 Lambda 实例收到的消息是 #0, #1, #2, #3, #6, #7; 那么 #4, #5, #8, #9 哪去了呢?被另一个 Lambda 实例处理了

Lambda 2
因测试要求,把日志时间精度调到了微秒,由于上面两个 Lambda 实例都是从同一个 Kinesis Shard 上获取的消息,所以它们是有依赖顺序的,Lambda 1 在消费完 #0, #1, #2, #3, 然后是 Lambda 2 收到并消费完 #4, #5,接着又 Lambda 1 消费 #6, #7, 最后才是 Lambda 2 收到 #8, #9。
所以对于发往同一个 Shard 的消息,虽然启动了多个 Lambda 实例,但它们执行并不是并行的,而是依消息顺序执行的。我们把 Trigger 的 batchSize 设置为 1 也是类似的情况,只是一条条记录交错的被两个 Lambda 实例处理。
消息被不同的 Lambda 实例按序接受处理,注意标明的微秒数
在试验中试图在 Lambda 处理方法中做一个 1 秒延时(Thread.sleep(1000)),但是测试结果是只要用了 Thread.sleep(...) 延时,只发送消息到同一个 Shard 的话只会启动一个 Lambda 实例,无论 batchSize 是 2 还是 1, 这个很让我惊讶,Thread.sleep(...) 具有某种特异功能。
不管是跨 Lambda 实例,只要发往同一个 Kinesis Shard 的消息总是被顺序处理,这里要注意个问题,不仅仅是按顺序接收到,而是只有前面的消息被 Lambda 成功处理完才接受后续的消息。如果前面的消息未被成功处理,将会重试直到成功,而后才能接收处理后续的消息,可以在 Lambda 抛出一个异常来测试
试验四:Lambda 抛出异常,观察是否能接收后面的消息
在 Lambda 处理方法最后的 return 语句替换为抛出异常,如下
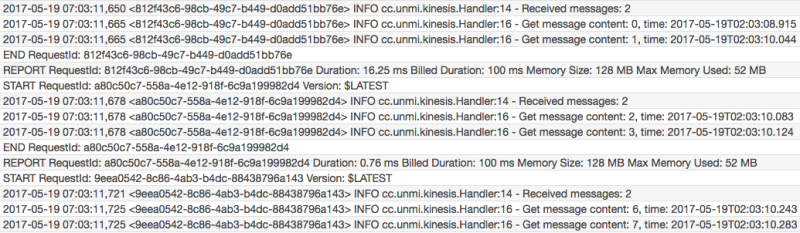
throw new RuntimeException("test");这时候往同一个 Shard 发送 10 条消息后,发现只会有一个 Lambda 实例在运行,因为处理 #0, #1 消息无法成功,所以没有机会接收后续消息如 #2, #3 等。从日志中可以看出 Lambda 不断在重试处理 #0, #1
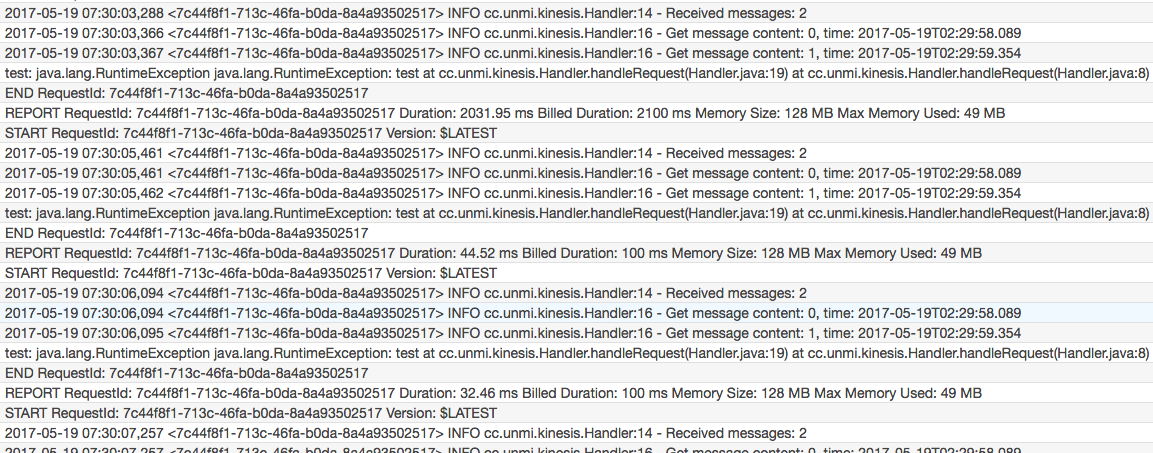 重试多少次呢?没有限制,如果总是不成功的话,这个 Lambda 实例基本是废掉了,一直重试到这条消息过期了才放弃(最少24小时), 重试的间隔时间当然不是每隔几秒钟,目测像是一个斐波那契序列,也就是说越来越疏。我们仍然可以继续往这个 Shard 上发送消息,也能立即触发那个 Lambda, 只是每次触发都是消费最初的老记录,下面的图可以辅助理解 Kinesis Stream Shard 上的消息的处理流程。
重试多少次呢?没有限制,如果总是不成功的话,这个 Lambda 实例基本是废掉了,一直重试到这条消息过期了才放弃(最少24小时), 重试的间隔时间当然不是每隔几秒钟,目测像是一个斐波那契序列,也就是说越来越疏。我们仍然可以继续往这个 Shard 上发送消息,也能立即触发那个 Lambda, 只是每次触发都是消费最初的老记录,下面的图可以辅助理解 Kinesis Stream Shard 上的消息的处理流程。 1) 每个 Kinesis Shard 会有一个线程从中轮询数据,如指定 Trigger 的 batchSize 是 10 的话,会每次最多取 10 条记录,只有 2 条的就只会取到 2 条记录,得到记录后选择一个 Lambda 实例来处理它们
1) 每个 Kinesis Shard 会有一个线程从中轮询数据,如指定 Trigger 的 batchSize 是 10 的话,会每次最多取 10 条记录,只有 2 条的就只会取到 2 条记录,得到记录后选择一个 Lambda 实例来处理它们2)同一个 Shard 中的记录总是按序处理,如上图所示,只有 #0, #1 被成功处理后,才会从 Stream 中删除它们,然后取后续的 #2, #3。#0, #1 失败一直重试,直到成功或记录到期,这时队列阻塞住了
这是 AWS Lambda 关于重试策略 http://docs.aws.amazon.com/lambda/latest/dg/retries-on-errors.html 的一段
Stream-based event sources – For stream-based event sources (Amazon Kinesis Streams and DynamoDB streams), AWS Lambda polls your stream and invokes your Lambda function. Therefore, if a Lambda function fails, AWS Lambda attempts to process the erring batch of records until the time the data expires, which can be up to seven days for Amazon Kinesis Streams. The exception is treated as blocking, and AWS Lambda will not read any new records from the stream until the failed batch of records either expires or processed successfully. This ensures that AWS Lambda processes the stream events in order.不完整翻译了,大体上说的是为了保证顺序,一旦出错重试的话相当于那个 Stream(确切的讲是 Shard, 像个队列) 就阻塞了,Lambda 无法从那个 Shard 上获取新的数据。所以你继续往那个 Shard 送消息都无法被 Lambda 处理。
关于 Lambda 出错重试,还需要更深入些。
2016-08-24: Kinesis 的的实现就是 Kafka, 所以 Shard 就是 Kafka 的 Partition。一个 Kinesis 能触发的 Lambda 实例就相当于一个 Kafka Topic 的同 GOUPD ID 的 Consumer, 因此最多只需要启动与 Shard 数目一样的 Lambda 实例,多了也没用。每个 Lambda 实例每次只从同一个 Shard 取若干条(Trigger batchSize 决定的) 消息记录, 完全消费成功这些记录才能提交消息的 Offset(Kafka 中的概念, Kinesi 中叫做 MessageId), 否则不断的重试。 永久链接 https://yanbin.blog/aws-lambda-consume-messages-from-one-share-in-series/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。