流畅的 Python 读书笔记(二)
继续啃这本略微有些旧的书,《Fluent Python》第二版出版在即,预计今年四月份,它将会讲解到更新版本 Python 的特性,书中有提到 Python 3.10。第一版读下来也不会是浪费时间的。
还是数据结构,现在来到字典,dict 是 Python 语言的基石,在它内部也被广泛应用,比如 type(globals()) 是个 dict, globals() 的内容有我们能调用的全局函数。如果在编程中不想创建新对象的话,dict 几乎能表述需要的数据结构。
dict 就是一个 hash 表,它是 collections.abc 下 Mapping 和 MutableMapping 的子类。和其他语言中的字典一样,dict 的 key 必须实现了
基本的字典,HashMap 之类的实现方式都是差不多(稀疏数组),如下图(当然也可以完全用一维数组来实现)
 横向靠 __hash__, hash 相同时靠 __eq__ 来进一步区分,所设计 Map 效率的高下在于散列值要更散(形散而神不散),避免过多相同的 hash 值(散列冲突),不可避免的不同 key 会有相同的 hash/index 值,那么挤在一块的对象如何提高命中效率又是个技巧,比如 Java 8 在超过 8 个同组的 hash 值时用红黑树。
横向靠 __hash__, hash 相同时靠 __eq__ 来进一步区分,所设计 Map 效率的高下在于散列值要更散(形散而神不散),避免过多相同的 hash 值(散列冲突),不可避免的不同 key 会有相同的 hash/index 值,那么挤在一块的对象如何提高命中效率又是个技巧,比如 Java 8 在超过 8 个同组的 hash 值时用红黑树。
Python 要求用不可变的对象(像 tuple, str, bytes, frozenset)作为 key, 如
Java 倒没这个要求,所以也就可能 key 的状态修改了,Map 中的值取不出来的现象,像下面的 Java 代码
Python 对不可变 Key 的要求可以避免这种现象的发生。
创建字典的方式
之前了解过创建各种类型集合的方式 创建 Python 的 list, set, tuple 和 dict,这里再次回顾一下
字典的推导,{} 大括号包围,参考列表的推导,一个例子
Python 除了基本的 dict, 还有 defaultdict 和 OraderedDict。这里有个新知识了,defaultdict, setdefault(), default_factory(), fromkeys(), __missing__() 方法。
update() 方法用来批量更新 dict, 相当于 Java map 的 pullAll() 方法。
setdefault(k, [default]) 方法
dict 在用 d[key] 取值时,key 不存在会报 KeyError, 但可换成用 d.get(key, [defaultvalue]) 的方式安全取值。但用 setdefault(key, defaultvalue) 可以为不存在的 key 用 d[key] 时也能返回默认值,它实质上是往 dict 中加了一个元素,同时返回新的默认值,如果 key 存在时什么也不做。所以 d.setdefault(key, defaultvalue) 相当于(假设 defaultvalue 是 10)
看下 setdefault() 方法的返回值及对字典的影响
这好像要为我们可能想到的每一个 key 设置一个默认值,不过看看下面的用途 - 对相同关键字的值分组
这就不需要我们先判断存不存在,不存在则添加一个空列表(或仅含当前元素的列表)
fromkeys(it, [initial])
它可以为我们预先准备好所有需要的 key
default_factory() 和 __missing__() 是 defaultdict 的方法
用 defaultdict 来实现上面的分组
defaultdict(list) 中的 list 就是 default_factory(), 这是一个 callable 对象,所以在 d[key] 发现 key 不存在时就用调用 list 往 d 中添加一个元素,相当于是
也可以声明 defaultdict 实例后给 default_factory 赋值
注意 default_factory 只对 d[key](即对 __getitem__) 方法起作用,对 d.get(key) 是无效的,d.get(key, [default]) 的总是 key 不存在时返回 None 或 default 值,不会对 dict 的状态产生改变。
defaultdict 的 default_factory 背后默默运作的就是 __missing__ 方法。当 __getitem__ 碰到 Key 不存在时,就询问 __missing__, __missing__ 看到有 default_factory 就给个默认值,并在字典中加上它,否则抛出 KeyError.
当我们要自定义 dict 时可以从 collections.UserDict 继承, UserDict 并不是 dict 的子类,它内部用 data 属性存数据,这能避免落入不必要有递归。除了保持 key 顺序的 OrderedDict 外,Python 还有
ChainMap
给程序由里及外的作用域很有用
Counter
types.MappingProxyType({1:'A'}) 能得到一个只读的 map 视图
集合(set 和 frozenset)
集合中的元素必须是可 hash 的,因为它内部 dict 化便于快速查询
含元素的集合 {1}, 空集合用 set({}), 直接写成 {} 就是一个 dict
集合的操作,| 并集,& 交集,- 差集
多个聚合类型的合集:a.union(b, c, d), a 必须是 set, b, c, d 可为任意可迭代类型
set 的两个移除方法
dict 和 set 都使用稀疏数组来实现,内存上开销较大,键的次序取决于添加顺序,但碰到 dict 要扩容时或散列冲突,键的次序就会被打乱. set 的特性与 dict 是样的,基本上可以认为 set 是存储在 dict 中的 key 的集合,值被忽略。迭代时不能增减元素,因为增减元素时会造成集合的抖动,用索引定位元素将可能失败。 永久链接 https://yanbin.blog/fluent-python-reading-notes-2/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
还是数据结构,现在来到字典,dict 是 Python 语言的基石,在它内部也被广泛应用,比如 type(globals()) 是个 dict, globals() 的内容有我们能调用的全局函数。如果在编程中不想创建新对象的话,dict 几乎能表述需要的数据结构。
dict 就是一个 hash 表,它是 collections.abc 下 Mapping 和 MutableMapping 的子类。和其他语言中的字典一样,dict 的 key 必须实现了
__hash__() 和 __qe__() 方法,否则不能作为 key,比如 list 是不能作 key 的。两个key 的 hash() 相等的话,那么 key1 == key2, 反之不一定。所以当 __eq__ 依赖于可变状态就不要去实现 __hash__ 方法.基本的字典,HashMap 之类的实现方式都是差不多(稀疏数组),如下图(当然也可以完全用一维数组来实现)
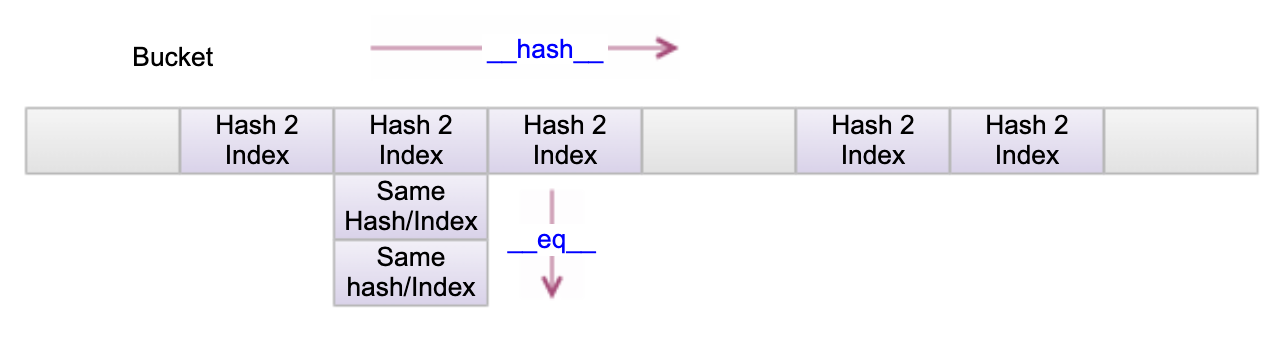 横向靠 __hash__, hash 相同时靠 __eq__ 来进一步区分,所设计 Map 效率的高下在于散列值要更散(形散而神不散),避免过多相同的 hash 值(散列冲突),不可避免的不同 key 会有相同的 hash/index 值,那么挤在一块的对象如何提高命中效率又是个技巧,比如 Java 8 在超过 8 个同组的 hash 值时用红黑树。
横向靠 __hash__, hash 相同时靠 __eq__ 来进一步区分,所设计 Map 效率的高下在于散列值要更散(形散而神不散),避免过多相同的 hash 值(散列冲突),不可避免的不同 key 会有相同的 hash/index 值,那么挤在一块的对象如何提高命中效率又是个技巧,比如 Java 8 在超过 8 个同组的 hash 值时用红黑树。Python 要求用不可变的对象(像 tuple, str, bytes, frozenset)作为 key, 如
1>>> hash('hello')
26333505251547513386
3>>> hash([1,2])
4Traceback (most recent call last):
5 File "<input>", line 1, in <module>
6 hash([1,2])
7TypeError: unhashable type: 'list'
8>>> hash((1,2))
9-3550055125485641917
10>>> hash((1, [2,3]))
11Traceback (most recent call last):
12 File "<input>", line 1, in <module>
13 hash((1, [2,3]))
14TypeError: unhashable type: 'list'Java 倒没这个要求,所以也就可能 key 的状态修改了,Map 中的值取不出来的现象,像下面的 Java 代码
1static class CustomKey {
2 public int state;
3
4 public CustomKey(int state) {
5 this.state = state;
6 }
7
8 @Override
9 public int hashCode() {
10 return Objects.hash(state);
11 }
12}
13
14public static void main(String[] args) {
15 Map<CustomKey, String> map = new HashMap<>();
16 CustomKey key = new CustomKey(1);
17 map.put(key, "a");
18 System.out.println(map.get(key)); // a
19
20 key.state = 2;
21 System.out.println(map.size()); // 1
22 System.out.println(map.get(key)); // null
23}Python 对不可变 Key 的要求可以避免这种现象的发生。
创建字典的方式
之前了解过创建各种类型集合的方式 创建 Python 的 list, set, tuple 和 dict,这里再次回顾一下
1>>> a = dict(one=1, two=2) # **kwargs 方式,字符串还只能为有效的参数名,如字符串
2>>> b = {1: 1, 2: 2} # 传统的方式
3>>> c = dict(zip(['one', 'two'], [1, 2])) # zip 两个平等列表
4>>> d = dict([('one', 1), ('two', 2)]) # list of tuple字典的推导,{} 大括号包围,参考列表的推导,一个例子
1>>> a = {'one': 1, 'two': 2}
2>>> {k: v+1 for k, v in a.items()}
3{'one': 2, 'two': 3}Python 除了基本的 dict, 还有 defaultdict 和 OraderedDict。这里有个新知识了,defaultdict, setdefault(), default_factory(), fromkeys(), __missing__() 方法。
update() 方法用来批量更新 dict, 相当于 Java map 的 pullAll() 方法。
setdefault(k, [default]) 方法
dict 在用 d[key] 取值时,key 不存在会报 KeyError, 但可换成用 d.get(key, [defaultvalue]) 的方式安全取值。但用 setdefault(key, defaultvalue) 可以为不存在的 key 用 d[key] 时也能返回默认值,它实质上是往 dict 中加了一个元素,同时返回新的默认值,如果 key 存在时什么也不做。所以 d.setdefault(key, defaultvalue) 相当于(假设 defaultvalue 是 10)
1defaultvalue = 2
2if 'two' not in d:
3 d['two'] = defaultvalue看下 setdefault() 方法的返回值及对字典的影响
1>>> d = {'one': 2}
2>>> d.setdefault('two', 3)
33
4>>> len(d)
52
6>>> d.setdefault('one', 4)
72
8>>> len(d)
92这好像要为我们可能想到的每一个 key 设置一个默认值,不过看看下面的用途 - 对相同关键字的值分组
1seq = [('a', 2), ('b', 3), ('a', 5), ('b', 6)]
2
3d = {}
4for k, v in seq:
5 d.setdefault(k, []).append(v) # setdefault 返回当前的默认值
6
7print(d) # {'a': [2, 5], 'b': [3, 6]}这就不需要我们先判断存不存在,不存在则添加一个空列表(或仅含当前元素的列表)
fromkeys(it, [initial])
1d = dict.fromkeys(['one', 'two'])
2print(d) # {'one': None, 'two': None}
3
4d = dict.fromkeys(['one', 'two'], 100)
5print(d) # {'one': 100, 'two': 100}它可以为我们预先准备好所有需要的 key
default_factory() 和 __missing__() 是 defaultdict 的方法
用 defaultdict 来实现上面的分组
1from collections import defaultdict
2
3seq = [('a', 2), ('b', 3), ('a', 5), ('b', 6)]
4d = defaultdict(list)
5
6for k, v in seq:
7 d[k].append(v)
8
9print(d) # defaultdict(<class 'list'>, {'a': [2, 5], 'b': [3, 6]})defaultdict(list) 中的 list 就是 default_factory(), 这是一个 callable 对象,所以在 d[key] 发现 key 不存在时就用调用 list 往 d 中添加一个元素,相当于是
1if k not in d:
2 d[k] = list() # 调用 default_factory() 方法也可以声明 defaultdict 实例后给 default_factory 赋值
1d = defaultdict()
2d.default_factory = list注意 default_factory 只对 d[key](即对 __getitem__) 方法起作用,对 d.get(key) 是无效的,d.get(key, [default]) 的总是 key 不存在时返回 None 或 default 值,不会对 dict 的状态产生改变。
1d = defaultdict(list)
2print(d['one']) # []
3print(d.get('two')) # Nonedefaultdict 的 default_factory 背后默默运作的就是 __missing__ 方法。当 __getitem__ 碰到 Key 不存在时,就询问 __missing__, __missing__ 看到有 default_factory 就给个默认值,并在字典中加上它,否则抛出 KeyError.
当我们要自定义 dict 时可以从 collections.UserDict 继承, UserDict 并不是 dict 的子类,它内部用 data 属性存数据,这能避免落入不必要有递归。除了保持 key 顺序的 OrderedDict 外,Python 还有
ChainMap
给程序由里及外的作用域很有用
1pylookup = ChainMap(locals(), globals(), vars(builtings))
2pylookup('abc') # 依上面的顺序查找,找到立即返回Counter
1>>> from collections import Counter
2>>> ct = Counter('aabcc')
3>>> ct
4Counter({'a': 2, 'c': 2, 'b': 1})types.MappingProxyType({1:'A'}) 能得到一个只读的 map 视图
集合(set 和 frozenset)
集合中的元素必须是可 hash 的,因为它内部 dict 化便于快速查询
1>>> {[1,2]}
2Traceback (most recent call last):
3 File "<input>", line 1, in <module>
4 {[1,2]}
5TypeError: unhashable type: 'list'含元素的集合 {1}, 空集合用 set({}), 直接写成 {} 就是一个 dict
集合的操作,| 并集,& 交集,- 差集
fronzenset(range(10))集合也不能少了推导
{chr(i) for i in {97, 98, 99}}和 dict 推导的区别就是没有冒号(:)
多个聚合类型的合集:a.union(b, c, d), a 必须是 set, b, c, d 可为任意可迭代类型
set 的两个移除方法
- s.discard(e): 如果 s 里有 e 这个元素的话,把它移除
- s.remove(e): 从 s 中移除 e, 若 e 不存在就抛出 KeyError 异常
dict 和 set 都使用稀疏数组来实现,内存上开销较大,键的次序取决于添加顺序,但碰到 dict 要扩容时或散列冲突,键的次序就会被打乱. set 的特性与 dict 是样的,基本上可以认为 set 是存储在 dict 中的 key 的集合,值被忽略。迭代时不能增减元素,因为增减元素时会造成集合的抖动,用索引定位元素将可能失败。 永久链接 https://yanbin.blog/fluent-python-reading-notes-2/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。