Kafka 生产消费 Avro 序列化数据
本文实践了如何连接 Kafka 生产和消费 Avro 序列化格式的数据, 不能像 NgAgo-gDNA 那样, 为保证实验内容及结果的可重复性, 文中所用的各中间件和组件版本如下:
Apache Kafka 消息系统设计为可以传输字符串, 二进制等数据, 但直接用于传输生产消费两端都能理解的对象数据会更友好. 所以我们这里用 Avro 的 Schema 来定义要传输的数据格式, 通信时采用自定义的序列化和反序列化类进行对象与字节数组间的转换.
以下是整个实验过程
需要用到 avro-tools 或 avro-maven-plugin 把上面的 Schema 编译成 `cc.unmi.data.User.java` 类文件. 该文件留有整个 Schema 的定义, 所以运行时无须 `user.avsc` 文件. 关于 Avro Schema 生成 Java 也可参见 Apache Avro 序列化与反序列化 (Java 实现)
由于 Avro Schema 编译出的类都继承自
这个只是负责把 Java 对象转换成字节数组便于网络传输. 因为
同理, 本实验中
把字节数组转换为一个 Avro 的对象, 虽然这里的泛型是
看看这个
现在才是激动人心的时刻, 输入
完整项目已上传到了 GitHub 上, 见 https://github.com/yabqiu/kafka-avro-demo. 这是一个 Maven 项目, 所以可以通过 Maven 来运行
参考链接:
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
- Apache Kafka: kafka_2.11-0.10.0.1, 这个版本在初始始化生产者消费者的属性与之前版本有所不同.
- kafka-clients: Java API 客户端, 版本为 0.10.0.1
- Apache Avro: 1.8.1. 关于 Avro 序列化的内容可参见 Apache Avro 序列化与反序列化 (Java 实现)
- Java 8
Apache Kafka 消息系统设计为可以传输字符串, 二进制等数据, 但直接用于传输生产消费两端都能理解的对象数据会更友好. 所以我们这里用 Avro 的 Schema 来定义要传输的数据格式, 通信时采用自定义的序列化和反序列化类进行对象与字节数组间的转换.
以下是整个实验过程
本地启动 Apache Kafka 服务
请参考 简单搭建 Apache Kafka 分布式消息系统 启动 ZooKeeper 和 Kafka 即可. 程序运行会自动创建相应的主题. 启动后 Kafka 开启了本地的 9092 端口, 程序中只需要连接这个端口, 不用管 ZooKeeper 的 2181 端口.交换的数据格式定义 user.avsc
1{
2 "namespace": "cc.unmi.data",
3 "type": "record",
4 "name": "User",
5 "fields": [
6 {"name": "name", "type": "string"},
7 {"name": "address", "type": ["string", "null"]}
8 ]
9}需要用到 avro-tools 或 avro-maven-plugin 把上面的 Schema 编译成 `cc.unmi.data.User.java` 类文件. 该文件留有整个 Schema 的定义, 所以运行时无须 `user.avsc` 文件. 关于 Avro Schema 生成 Java 也可参见 Apache Avro 序列化与反序列化 (Java 实现)
创建生产者 Producer
1package cc.unmi;<br/><br/>
2import cc.unmi.serialization.AvroSerializer;
3import org.apache.avro.specific.SpecificRecordBase;
4import org.apache.kafka.clients.producer.KafkaProducer;
5import org.apache.kafka.clients.producer.ProducerConfig;
6import org.apache.kafka.clients.producer.ProducerRecord;
7import org.apache.kafka.common.serialization.StringSerializer;<br/><br/>
8import java.util.Properties;<br/><br/>
9public class Producer<T extends SpecificRecordBase> {<br/><br/>
10 private KafkaProducer<String, T> producer = new KafkaProducer<>(getProperties());<br/><br/>
11 public void sendData(Topic topic, T data) {
12 producer.send(new ProducerRecord<>(topic.topicName, data),
13 (metadata, exception) -> {
14 if (exception == null) {
15 System.out.printf("Sent user: %s \n", data);
16 } else {
17 System.out.println("data sent failed: " + exception.getMessage());
18 }
19 });
20 }<br/><br/>
21 private Properties getProperties() {
22 Properties props = new Properties();
23 props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
24 props.put(ProducerConfig.CLIENT_ID_CONFIG, "DemoProducer");
25 props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
26 StringSerializer.class.getName());
27 props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
28 AvroSerializer.class.getName());
29 return props;
30 }
31}由于 Avro Schema 编译出的类都继承自
SpecificRecordBase, 因此泛型类型是 <T extends SpecificRecordBase>. 在本实验中发送消息时未设置 Key, 所以 KEY_SERIALIZER_CLASS_CONFIG 可不用, 这里用到了自定义的 AvroSerializer 序列化类, 所以Avro 对象的序列化类 AvroSerializer
1package cc.unmi.serialization;
2
3import org.apache.avro.io.BinaryEncoder;
4import org.apache.avro.io.DatumWriter;
5import org.apache.avro.io.EncoderFactory;
6import org.apache.avro.specific.SpecificDatumWriter;
7import org.apache.avro.specific.SpecificRecordBase;
8import org.apache.kafka.common.errors.SerializationException;
9import org.apache.kafka.common.serialization.Serializer;
10
11import java.io.ByteArrayOutputStream;
12import java.io.IOException;
13import java.util.Map;
14
15public class AvroSerializer<T extends SpecificRecordBase> implements Serializer<T>{
16
17 @Override
18 public void configure(Map<String, ?> configs, boolean isKey) {
19
20 }
21
22 @Override
23 public byte[] serialize(String topic, T data) {
24 DatumWriter<T> userDatumWriter = new SpecificDatumWriter<>(data.getSchema());
25 ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
26 BinaryEncoder binaryEncoder = EncoderFactory.get().directBinaryEncoder(outputStream, null);
27 try {
28 userDatumWriter.write(data, binaryEncoder);
29 } catch (IOException e) {
30 throw new SerializationException(e.getMessage());
31 }
32 return outputStream.toByteArray();
33 }
34
35 @Override
36 public void close() {
37
38 }
39}这个只是负责把 Java 对象转换成字节数组便于网络传输. 因为
serilaize 方法处理的数据类型是 <T extends SpecificRecordBase>, 所以构造 SpecificDatumWriter 可直接传入 data.getSchema(). 等会反序列化时可没这么轻松了.创建消费者 Consumer
1package cc.unmi;
2
3import cc.unmi.serialization.AvroDeserializer;
4import org.apache.avro.specific.SpecificRecordBase;
5import org.apache.kafka.clients.consumer.ConsumerConfig;
6import org.apache.kafka.clients.consumer.ConsumerRecord;
7import org.apache.kafka.clients.consumer.ConsumerRecords;
8import org.apache.kafka.clients.consumer.KafkaConsumer;
9import org.apache.kafka.common.serialization.StringDeserializer;
10
11import java.util.Collections;
12import java.util.List;
13import java.util.Properties;
14import java.util.stream.Collectors;
15import java.util.stream.StreamSupport;
16
17public class Consumer<T extends SpecificRecordBase> {
18
19 private KafkaConsumer<String, T> consumer = new KafkaConsumer<>(getProperties());
20
21 public List<T> receive(Topic topic) {
22// TopicPartition partition = new TopicPartition(topic.topicName, 0);
23 consumer.subscribe(Collections.singletonList(topic.topicName));
24// consumer.assign(Collections.singletonList(partition));
25 ConsumerRecords<String, T> records = consumer.poll(10);
26
27 return StreamSupport.stream(records.spliterator(), false)
28 .map(ConsumerRecord::value).collect(Collectors.toList());
29 }
30
31 private Properties getProperties() {
32 Properties props = new Properties();
33 props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
34 props.put(ConsumerConfig.GROUP_ID_CONFIG, "DemoConsumer");
35 props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
36 StringDeserializer.class.getName());
37 props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
38 AvroDeserializer.class.getName());
39 return props;
40 }
41}同理, 本实验中
KEY_DESERIALIZER_CLASS_CONFIG 也可不用. GROUP_ID_CONFIG 的设定是 Kafka 的一条消息, 多个消费者的情况, 如果它们的 group id 不同, 都能获得这条消息, 如果一样的 group id, 都只有组中的一个消费都能获得这条消息. 这里也用到了自定义的反序列化类 AvroDeserializer.Avro 对象的反序列化类 AvroDeserializer
1package cc.unmi.serialization;
2
3import cc.unmi.Topic;
4import com.sun.xml.internal.ws.encoding.soap.DeserializationException;
5import org.apache.avro.io.BinaryDecoder;
6import org.apache.avro.io.DatumReader;
7import org.apache.avro.io.DecoderFactory;
8import org.apache.avro.specific.SpecificDatumReader;
9import org.apache.avro.specific.SpecificRecordBase;
10import org.apache.kafka.common.serialization.Deserializer;
11
12import java.io.ByteArrayInputStream;
13import java.io.IOException;
14import java.util.Map;
15
16public class AvroDeserializer<T extends SpecificRecordBase> implements Deserializer<T> {
17
18 @Override
19 public void configure(Map<String, ?> configs, boolean isKey) {
20 }
21
22 @Override
23 public T deserialize(String topic, byte[] data) {
24
25 DatumReader<T> userDatumReader = new SpecificDatumReader<>(Topic.matchFor(topic).topicType.getSchema());
26 BinaryDecoder binaryEncoder = DecoderFactory.get().directBinaryDecoder(new ByteArrayInputStream(data), null);
27 try {
28 return userDatumReader.read(null, binaryEncoder);
29 } catch (IOException e) {
30 throw new DeserializationException(e.getMessage());
31 }
32 }
33
34 @Override
35 public void close() {
36
37 }
38}把字节数组转换为一个 Avro 的对象, 虽然这里的泛型是
<T extends SpecificRecordBase>, 但是代码中是无法从 T 得到 T.class 的. 见 http://www.blogjava.net/calvin/archive/2006/04/28/43830.html. 所以我们专门定义了一个 Topic 枚举, 把每一个 Topic 与具体要传输的数据类型关联起来了, 像上面是通过 Topic.matchFor(topic).topicType.getSchema() 来获得 Schema 的. 这时也必须保证一个主题只为特定类型服务.看看这个
Topic 枚举类型定义 1package cc.unmi;
2
3import cc.unmi.data.User;
4import org.apache.avro.specific.SpecificRecordBase;
5
6import java.util.EnumSet;
7
8public enum Topic {
9 USER("user-info-topic", new User());
10
11 public final String topicName;
12 public final SpecificRecordBase topicType;
13
14 Topic(String topicName, SpecificRecordBase topicType) {
15 this.topicName = topicName;
16 this.topicType = topicType;
17 }
18
19 public static Topic matchFor(String topicName) {
20 return EnumSet.allOf(Topic.class).stream()
21 .filter(topic -> topic.topicName.equals(topicName))
22 .findFirst()
23 .orElse(null);
24 }
25}运行实例 KafkaDemo
1package cc.unmi;
2
3import cc.unmi.data.User;
4
5import java.util.List;
6import java.util.Random;
7import java.util.Scanner;
8
9public class KafkaDemo {
10
11 public static void main(String[] args) {
12
13 Producer<User> producer = new Producer<>();
14 Consumer<User> consumer = new Consumer<>();
15
16 System.out.println("Please input 'send', 'receive', or 'exit'");
17 Scanner scanner = new Scanner(System.in);
18 while (scanner.hasNext()) {
19 String input = scanner.next();
20
21 switch (input) {
22 case "send":
23 producer.sendData(Topic.USER, new User("Yanbin", "Address: " + new Random().nextInt()));
24 break;
25 case "receive":
26 List<User> users = consumer.receive(Topic.USER);
27 if(users.isEmpty()) {
28 System.out.println("Received nothing");
29 } else {
30 users.forEach(user -> System.out.println("Received user: " + user));
31 }
32 break;
33 case "exit":
34 System.exit(0);
35 break;
36 default:
37 System.out.println("Please input 'send', 'receive', or 'exit'");
38 }
39 }
40 }
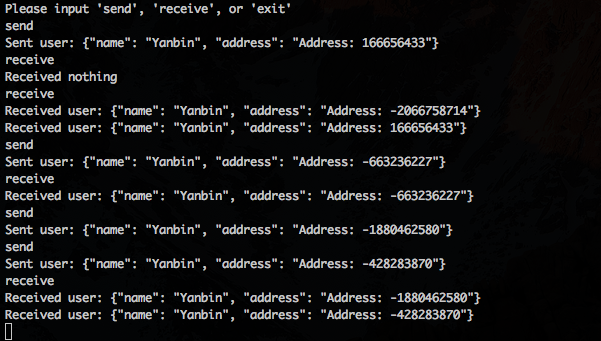
41}现在才是激动人心的时刻, 输入
send 发送消息, receive 接收消息. 实际中消费都应实现为自动监听器模式, 有消息到来时自动提醒, 不过底层还是一个轮询的过程, 和这里一样.完整项目已上传到了 GitHub 上, 见 https://github.com/yabqiu/kafka-avro-demo. 这是一个 Maven 项目, 所以可以通过 Maven 来运行
mvn exec:java -Dexec.mainClass=cc.unmi.KafkaDemo效果如下:
Address: -2066758714 这条消息是启动程序之前就已存在于 Kafka 中的消息. 其他是 send 就能接收到, 有时稍有延迟.参考链接:
- KafkaProducer API
- KafkaConsumer API
- Introducing the Kafka Consumer: Getting Started with the New Apache Kafka 0.9 Consumer Client
- Kafka的Java实例
- Kafka+Avro的demo
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。