学习 Airflow 第一篇章
Airflow 起初是由 Airbnb 开发的, 用于调度和监控工作流的平台,后来开源了, 并于 2019 年 1 月成为了 Apache 的顶级项目。它是用 Python 编写的,管理的工作流是有向无环图(DAG - Directed Acyclic Graph), 这能满足绝大多数情况下的需求。
顺带插一句,Airflow 用了与 Google Photos 极其相似的 Logo,不知算不算侵权。
说到工作调度,头脑中很快会掠过 Cron, 计划任务, Quartz, Spring Schedule, 和 Control-M。除了商业的 Control-M 有调度和监控工作流的功能外,其他的基本只用来调度任务,监控全靠自己的日志。
还有一个类似的工具是由易观贡献给 Apache 的 DolphinScheduler, 它处理的也是 DAG 工作流,用 Java 实现的,所以体量大,硬件要求会高些。它的工作流的创建是通过 Web UI 可视化界面完成的,对程序员来说不那么友好。奇怪的是, 作为 Apache 旗下的项目,项目首页面是中文的,启动后控制台默认界面也是中文的。
而 Airflow 功能就厉害了, 它可动态管理工作流,易于扩展,可集群化进行伸缩,更有一个漂亮的 UI 用于实时监控任务。基于以上特性 Airflow 是很适于执行数据的 ETL(Extract, Transform, Load) 操作的。
这么好的开源产品, 免不了又被 AWS 盯上了, 以 Amazon Managed Workflows for Apache Airflow(MWAA) 服务进行出售,费用还真不菲。AWS 创造性的以 vCPU 数量,DAG 数量限制进行分层次进行收费,远比自己启动一两个 EC2 实例部署 Airflow 贵的多。但 MWAA 有个方便的特性就是 DAG 文件可以放到 S3 中自动部署,相信自己部署的 Airflow 也能进行扩展而从 S3 加载 DAG。
暂且不往下深入 Airflow 的概念,需要快速体验,先在本地安装一个 Airflow,启动,并用 Python 编写部署一个简单的工作流。
Airflow 2.3.0 在以下环境中测试过:
这里使用 Python 3.9, 并使用默认的 SQLite 数据库(产品环境中勿用)。
安装好 Airflow 后,就有了强大的
至此我们可以访问 http://localhost:8080 来到 Apache Airflow 的管理界面了。
启动后在主目录中创建了
airflow 目录的位置可通过环境变量 AIRFLOW_HOME 进行修改,比如我们修改 AIRFLOW_HOME 再分步进行启动 Airflow 的各部件服务
注意,第一次执行
分步启动服务也不会自动创建 admin 用户,要能登陆 Airflow 控制台的话还需创建一个 admin 用户
 这里罗列了一大堆的示例 DAG(示例 DAG 是存放在虚拟来环境中 airflow 安装目录下,如 ~/airflow-venv/lib/python3.9/site-packages/airflow/example_dags ),并且时区是 UTC,是否显示例子 DAG 和时区是可以通过
这里罗列了一大堆的示例 DAG(示例 DAG 是存放在虚拟来环境中 airflow 安装目录下,如 ~/airflow-venv/lib/python3.9/site-packages/airflow/example_dags ),并且时区是 UTC,是否显示例子 DAG 和时区是可以通过
http://localhost:8080/dags/example_nested_branch_dag/graph
 每个 DAG 有设定了 Schedule 的,想要立即触执行也没问题,在右端点击三角播放按钮会提示两种方式立即触发该流程。
每个 DAG 有设定了 Schedule 的,想要立即触执行也没问题,在右端点击三角播放按钮会提示两种方式立即触发该流程。
再来欣赏一下该 DAG 的代码,这有助于我们理解, 仿照并编写自己的 DAG
修改 default_timezone 为
Airflow 中所谓的 DAG 就是一个工作流,工作流中基本概念有
我们可以定义自己的 Operator, 或下载第三方的 Operator, 如 apache-airflow-providers-amazon 的 Amazon AWS Operators,安装命令
Airflow 的 Connection types 和 Operators 现在由第三方的 airflow providers 来提供,如
其实我们有 PythonOperator, 再结合 boto3 库就能直接操作 AWS 的资源了,比使用 AWS 相关 Operator 还要方便。当然第三方 Provider 实现避免了不断的重复发明轮子。
扯了上面那么多,开始进入正题,下面创建单个 Python 文件 hello_dag.py,并定义一个简单的工作流
PythonOperator 指定 python_callable 为一个 Callable 对象,所以理论上只要一个 PythonOperator 就能走遍天下
使用 SimpleHttpOperator 指定了 http_conn_id='opsgenie_default', 可在 Airflow Web UI, Admin/Connections 中看到该配置,只指定了 http, 未指定 Host。SimpleHttpOperator 默认使用 http_default, 所有请求均发向 https://www.httpbin.org/,这不符合我们的需求
在
完后用 python 命令作初步验证
 从 $AIRFLOW_HOME/dags 目录中删除 DAG 相应的 Python 文件,过一会儿该 DAG 也将从系统中移除。所以,增删改 DAG 是动态的,无需重启任何服务。
从 $AIRFLOW_HOME/dags 目录中删除 DAG 相应的 Python 文件,过一会儿该 DAG 也将从系统中移除。所以,增删改 DAG 是动态的,无需重启任何服务。
查看流程图
 点击右上方的播放键触发该工作流的执行
点击右上方的播放键触发该工作流的执行
执行后,在 Graph 页中,点击某一个 Task 后弹出 Task Instance: get_ip 面板,再点击
 我们也能用
我们也能用
测试一个 DAG
执行 DAG 下的一个任务
链接:
永久链接 https://yanbin.blog/learning-airflow-get-started/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
顺带插一句,Airflow 用了与 Google Photos 极其相似的 Logo,不知算不算侵权。
说到工作调度,头脑中很快会掠过 Cron, 计划任务, Quartz, Spring Schedule, 和 Control-M。除了商业的 Control-M 有调度和监控工作流的功能外,其他的基本只用来调度任务,监控全靠自己的日志。
还有一个类似的工具是由易观贡献给 Apache 的 DolphinScheduler, 它处理的也是 DAG 工作流,用 Java 实现的,所以体量大,硬件要求会高些。它的工作流的创建是通过 Web UI 可视化界面完成的,对程序员来说不那么友好。奇怪的是, 作为 Apache 旗下的项目,项目首页面是中文的,启动后控制台默认界面也是中文的。
而 Airflow 功能就厉害了, 它可动态管理工作流,易于扩展,可集群化进行伸缩,更有一个漂亮的 UI 用于实时监控任务。基于以上特性 Airflow 是很适于执行数据的 ETL(Extract, Transform, Load) 操作的。
这么好的开源产品, 免不了又被 AWS 盯上了, 以 Amazon Managed Workflows for Apache Airflow(MWAA) 服务进行出售,费用还真不菲。AWS 创造性的以 vCPU 数量,DAG 数量限制进行分层次进行收费,远比自己启动一两个 EC2 实例部署 Airflow 贵的多。但 MWAA 有个方便的特性就是 DAG 文件可以放到 S3 中自动部署,相信自己部署的 Airflow 也能进行扩展而从 S3 加载 DAG。
暂且不往下深入 Airflow 的概念,需要快速体验,先在本地安装一个 Airflow,启动,并用 Python 编写部署一个简单的工作流。
Airflow 的安装与启动
当前的 Airflow 版本是 2.3.3。Airflow 提供有官方 Airflow Docker 镜像来启动服务,为体验更原滋原味的 Airflow,我们在一个干净的 Python 虚拟环境中安装使用 Airflow。Airflow 2.3.0 在以下环境中测试过:
- Python 3.7 ~ 3.10
- 数据库:
- PostgreSQL 10 ~ 14
- MySQL 5.7 ~ 8
- SQLite 3.15.0+
- MSSQL(试验性): 2017, 2017
- Kubernetes: 1.20.2, 1.20.1, 1.22.0, 1.23.0, 1.24.0
这里使用 Python 3.9, 并使用默认的 SQLite 数据库(产品环境中勿用)。
创建一个 Python 虚拟环境
$ python3.9 -m venv airflow-venv
$ source airflow-venv/bin/activate
(airflow-venv) $
安装 apache-airflow
$ pip install apache-airflow官方文档中说直接安装 apche-airflow 可能出现莫名的问题,建议是用以下命令来安装
$ pip install apache-airflow==2.3.3 --constraint https://raw.githubusercontent.com/apache/airflow/constraints-2.3.3/constraints-3.9.txt注:以上的 2.3.3 和 3.9 分别是 apache-airflow 版本号和当前 Python 的主次版本号,安装时请根据实际进行调整。
安装好 Airflow 后,就有了强大的
airflow 命令。airflow --help 显示 airflow 的帮助, 可通过 airflow 来启动服务,几乎所有的 Airflow 管理功能都能通过 airflow 命令来完成。子级命令的帮助继续用 --help, 如 airflow scheduler --help。启动 Airflow -- 使用命令 airflow standalone
$ airflow standalone控制台会输出一大堆信息,以上节选了部分信息。从上可知它初始化了 SQLite 数据, 启动了 webserver 和 scheduler,并且告知 admin 和密码是什么,最后说 Airflow Standalone 只为开发为目的。
standalone | Starting Airflow Standalone
standalone | Checking database is initialized
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> e3a246e0dc1, current schema
.......
triggerer | [2022-08-08 23:41:29,886] {triggerer_job.py:100} INFO - Starting the triggerer
.......
scheduler | [2022-08-08 23:41:29,975] {scheduler_job.py:708} INFO - Starting the scheduler
........
scheduler | [2022-08-08 23:41:30 -0500] [7114] [INFO] Starting gunicorn 20.1.0
scheduler | [2022-08-08 23:41:30 -0500] [7114] [INFO] Listening at: http://0.0.0.0:8793 (7114)
scheduler | [2022-08-08 23:41:30 -0500] [7114] [INFO] Using worker: sync
scheduler | [2022-08-08 23:41:30 -0500] [7117] [INFO] Booting worker with pid: 7117
.........
webserver | [2022-08-08 23:41:31 -0500] [7115] [INFO] Listening at: http://0.0.0.0:8080 (7115)
webserver | [2022-08-08 23:41:31 -0500] [7115] [INFO] Using worker: sync
webserver | [2022-08-08 23:41:31 -0500] [7120] [INFO] Booting worker with pid: 7120
webserver | [2022-08-08 23:41:31 -0500] [7121] [INFO] Booting worker with pid: 7121
.........
standalone |
standalone | Airflow is ready
standalone | Login with username: admin password: dFAqpaEf88f7wYvF
standalone | Airflow Standalone is for development purposes only. Do not use this in production!
至此我们可以访问 http://localhost:8080 来到 Apache Airflow 的管理界面了。
启动后在主目录中创建了
airflow 目录,其中有 airflow.db 数据库文件,可用 SQLite 客户端打开查询。还有 airflow.cfg 配置文件, logs 目录,和 standalone_admin_password.txt 存放密码的文件,控制台不见密码了回来这里找。1ls$ ls ~/airflow
2airflow-webserver.pid airflow.db standalone_admin_password.txt
3airflow.cfg logs webserver_config.py逐个启动服务的方法
如果不用airflow standalone 命令启动,也可采用逐个启动 airflow 的 triggerer, scheduler, webserver 这几个服务。airflow 目录的位置可通过环境变量 AIRFLOW_HOME 进行修改,比如我们修改 AIRFLOW_HOME 再分步进行启动 Airflow 的各部件服务
$ export AIRFLOW_HOME=~/opt/airflow参数
$ airflow triggerer --daemon
$ airflow scheduler --daemon
$ airflow webserver --daemon
--daemon 是把对应服务在后台启动,这时会生成 ~/opt/airflow 目录,每个进程会产生相应的 *.err, *.log, *.out, *.pid,想要杀掉以上命令启动的所有进程可用命令$ cat *.pid | xargs killkill -9 的话还需手工清理相应的 *.pid 文件。或者用
pkill "airflow scheduler" 命令杀。注意,第一次执行
airflow triggerer 提示初始化数据库的时候一定要快速回答 yPlease confirm database initialize (or wait 4 seconds to skip it). Are you sure? [y/N]否则会被跳过,启动会失败,除非在启动服务前显式的执行
$ airflow db init来初始化数据库。
分步启动服务也不会自动创建 admin 用户,要能登陆 Airflow 控制台的话还需创建一个 admin 用户
$ airflow users create --role Admin --username admin --email admin@example.com --firstname Yanbin --lastname Qiu --password password另外:airflow 所用数据库可由
airflow db shell 进到数据库的 shell 进行访问$ airflow db shell
......
sqlite> .tables
sqlite>. PRAGMA table_info(dag)
浏览 Airflow UI 界面
假设我们前面是直接用airflow standalone 启动的,这时候 admin 用户是已创建好了的。打开 http://localhost:8080, 输入 admin 帐户及控制台下提示的密码登陆,我们看到 这里罗列了一大堆的示例 DAG(示例 DAG 是存放在虚拟来环境中 airflow 安装目录下,如 ~/airflow-venv/lib/python3.9/site-packages/airflow/example_dags ),并且时区是 UTC,是否显示例子 DAG 和时区是可以通过
这里罗列了一大堆的示例 DAG(示例 DAG 是存放在虚拟来环境中 airflow 安装目录下,如 ~/airflow-venv/lib/python3.9/site-packages/airflow/example_dags ),并且时区是 UTC,是否显示例子 DAG 和时区是可以通过 ~/airflow/airflow.cfg 进行修改的。在修改配置之前不妨看下 example_nested_branch_dag 的图形http://localhost:8080/dags/example_nested_branch_dag/graph
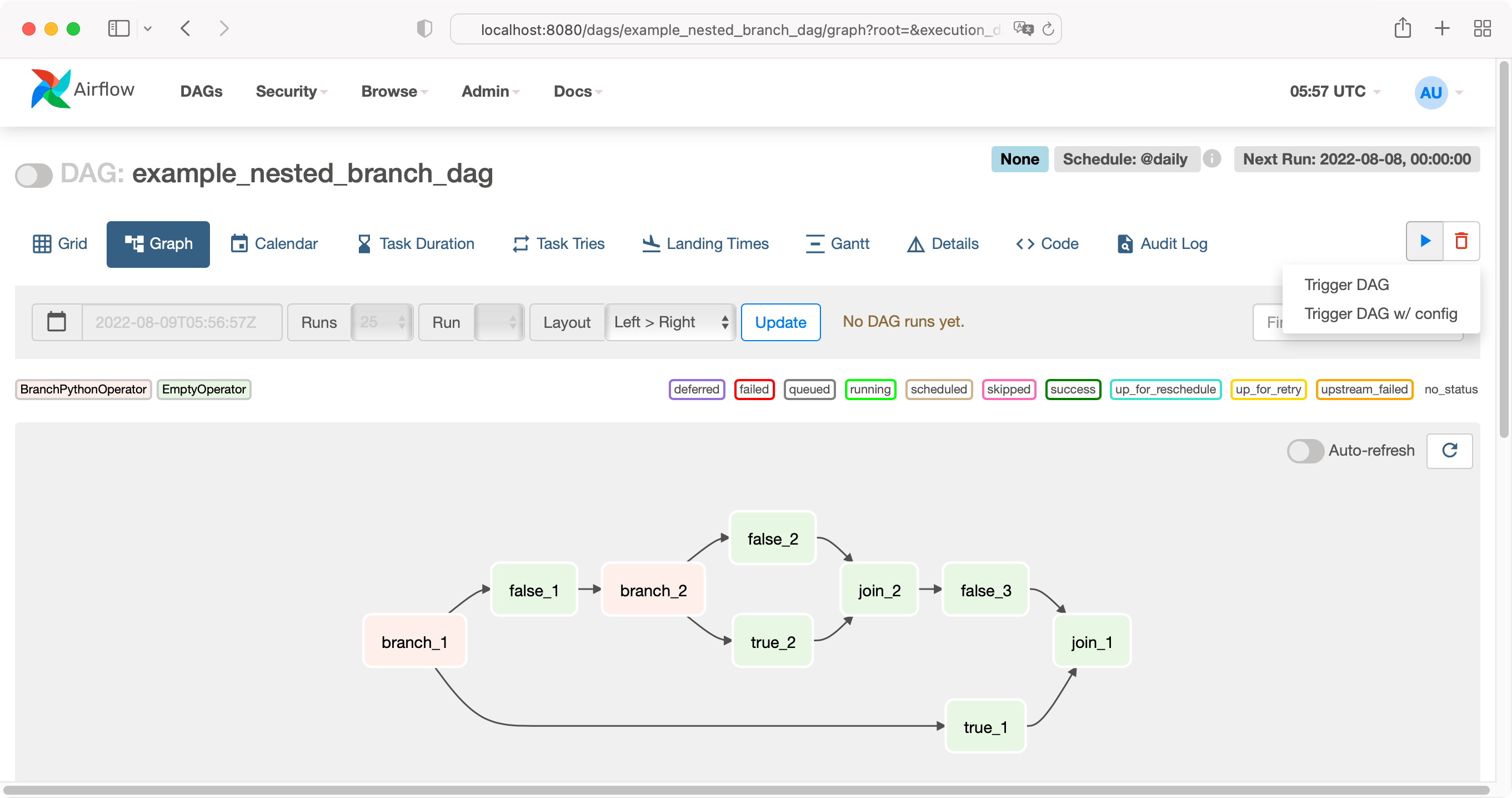 每个 DAG 有设定了 Schedule 的,想要立即触执行也没问题,在右端点击三角播放按钮会提示两种方式立即触发该流程。
每个 DAG 有设定了 Schedule 的,想要立即触执行也没问题,在右端点击三角播放按钮会提示两种方式立即触发该流程。再来欣赏一下该 DAG 的代码,这有助于我们理解, 仿照并编写自己的 DAG
1import pendulum
2
3from airflow.models import DAG
4from airflow.operators.empty import EmptyOperator
5from airflow.operators.python import BranchPythonOperator
6from airflow.utils.trigger_rule import TriggerRule
7
8with DAG(
9 dag_id="example_nested_branch_dag",
10 start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
11 catchup=False,
12 schedule_interval="@daily",
13 tags=["example"],
14) as dag:
15 branch_1 = BranchPythonOperator(task_id="branch_1", python_callable=lambda: "true_1")
16 join_1 = EmptyOperator(task_id="join_1", trigger_rule=TriggerRule.NONE_FAILED_MIN_ONE_SUCCESS)
17 true_1 = EmptyOperator(task_id="true_1")
18 false_1 = EmptyOperator(task_id="false_1")
19 branch_2 = BranchPythonOperator(task_id="branch_2", python_callable=lambda: "true_2")
20 join_2 = EmptyOperator(task_id="join_2", trigger_rule=TriggerRule.NONE_FAILED_MIN_ONE_SUCCESS)
21 true_2 = EmptyOperator(task_id="true_2")
22 false_2 = EmptyOperator(task_id="false_2")
23 false_3 = EmptyOperator(task_id="false_3")
24
25 branch_1 >> true_1 >> join_1
26 branch_1 >> false_1 >> branch_2 >> [true_2, false_2] >> join_2 >> false_3 >> join_1配置 airflow.cfg
打开 $AIRFLOW_HOME/airflow.cfg 文件,其中的所有配置项都值得仔细阅读一番,像1dags_folder = /Users/yanbin/airflow/dags
2default_timezone = utc
3executor = SequentialExecutor
4load_examples = True
5base_log_folder = /Users/yanbin/airflow/logs
6
7# 可以用 s3, cloudwatch 等保存 log
8remote_logging = False
9remote_base_log_folder = 修改 default_timezone 为
America/Chicago, load_examples 改为 False, 重新启动 airflow standalone 试试。创建第一个 DAG
由 airflow.cfg 配置文件中了解到 DAG 的目录为~/airflow/dags, 现在我们来创建自己的第一个 DAG, 只要把 Python 文件丢到 ~/airflow/dags 目录中就能动态加载。选择 Airflow 所用的虚拟环境,然后在 IDE 中编写 DAG,如此可清楚在 Airflow 中有哪些 Operator 可用。Airflow 中所谓的 DAG 就是一个工作流,工作流中基本概念有
- Operator: 描述一个 Task 要做的事情。Airflow 默认为我们提供了 BashOperator, EmailOperator, PythonOperator, SimpleHttpOperator 等
- Task: Task 是 Operator 的一个实例,是构成一个 DAG 工作流的顶点
- Task Relationship: DAG 中 Task 间的依赖关系,构成工作流的边。上下流关系用
>>和<<进行连接。
我们可以定义自己的 Operator, 或下载第三方的 Operator, 如 apache-airflow-providers-amazon 的 Amazon AWS Operators,安装命令
$ pip install 'apache-airflow[amazon]'然后有许多 AWS 资源相关的 Operators 可用,如 S3, SQS, AWS Lambda 等。
Airflow 的 Connection types 和 Operators 现在由第三方的 airflow providers 来提供,如
pip install apache-airflow-providers-mysql 安装后就能使用 MySqlOperator。其实我们有 PythonOperator, 再结合 boto3 库就能直接操作 AWS 的资源了,比使用 AWS 相关 Operator 还要方便。当然第三方 Provider 实现避免了不断的重复发明轮子。
扯了上面那么多,开始进入正题,下面创建单个 Python 文件 hello_dag.py,并定义一个简单的工作流
1import time
2
3from airflow import DAG
4from airflow.operators.python import PythonOperator
5from airflow.operators.bash import BashOperator
6from airflow.providers.http.operators.http import SimpleHttpOperator
7from datetime import timedelta, datetime
8import json
9
10
11DAG_DEFAULT_ARGS = {
12 'owner': 'Yanbin',
13 'depends_on_past': False,
14 'retries': 1,
15 'retry_delay': timedelta(minutes=1)
16}
17
18
19def sleep_python(duration: int):
20 print(f"sleep for {duration} seconds")
21 time.sleep(duration)
22
23
24with DAG('hello_dag',
25 start_date=datetime(2020, 8, 9),
26 schedule_interval="0/5 * * * *",
27 description="My first DAG",
28 default_args=DAG_DEFAULT_ARGS, catchup=False) as dag:
29
30 start_task = BashOperator(task_id="Start", bash_command="echo 'start task at {{ds}}'")
31
32 sleep_task = PythonOperator(task_id="sleep", python_callable=sleep_python, op_args=(2,))
33
34 get_ip_task = SimpleHttpOperator(
35 task_id="get_ip",
36 http_conn_id='opsgenie_default',
37 method='GET',
38 endpoint='ip-api.com/json',
39 response_filter=lambda response: json.loads(response.text)['query']
40 )
41
42 end_task = BashOperator(task_id="End",
43 bash_command="echo ip: {{ task_instance.xcom_pull(task_ids='get_ip') }}")
44
45 start_task >> [sleep_task, get_ip_task] >> end_taskPythonOperator 指定 python_callable 为一个 Callable 对象,所以理论上只要一个 PythonOperator 就能走遍天下
使用 SimpleHttpOperator 指定了 http_conn_id='opsgenie_default', 可在 Airflow Web UI, Admin/Connections 中看到该配置,只指定了 http, 未指定 Host。SimpleHttpOperator 默认使用 http_default, 所有请求均发向 https://www.httpbin.org/,这不符合我们的需求
在
end_task 中用 {{ task_instance.xcom_pull(tasks_ids='get_ip') }} 获得 get_id task 的输出,这里涉及到了 Task 之间共享数据的主题 XComs(cross-communications)。{{ abc }} 应用到了 Python 的 Jinja 模板,其中 {{ ds }} 得到当前的 datestamp。完后用 python 命令作初步验证
$ python hello_dag.py没有语法错误就把它拷贝到目录 $AIRFLOW_HOME/dags 中, 该目录不存在则创建它。默认最多等 5 分钟(在 airflow.cfg 中的配置 dag_dir_list_interval = 300), 就能在 Airflow 的 Web UI 上看到它
 从 $AIRFLOW_HOME/dags 目录中删除 DAG 相应的 Python 文件,过一会儿该 DAG 也将从系统中移除。所以,增删改 DAG 是动态的,无需重启任何服务。
从 $AIRFLOW_HOME/dags 目录中删除 DAG 相应的 Python 文件,过一会儿该 DAG 也将从系统中移除。所以,增删改 DAG 是动态的,无需重启任何服务。查看流程图
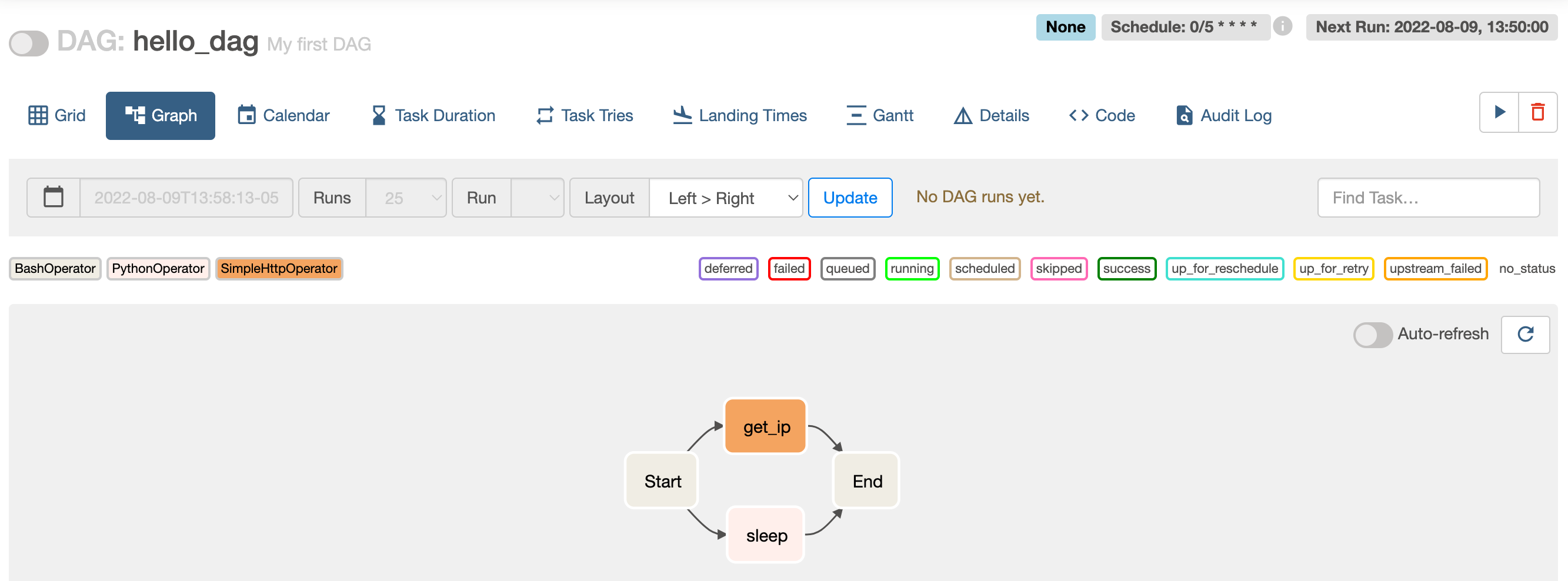 点击右上方的播放键触发该工作流的执行
点击右上方的播放键触发该工作流的执行执行后,在 Graph 页中,点击某一个 Task 后弹出 Task Instance: get_ip 面板,再点击
Log 按钮可查看任务的执行日志 我们也能用
我们也能用 airflow 命令来管理, 触发任务的执行 1$ airflow dags list
2dag_id | filepath | owner | paused
3==========+==============+========+=======
4hello_dag | hello_dag.py | Yanbin | False
5
6$ airflow tasks list hello_dag
7Start
8End
9get_ip
10sleep
11$ airflow tasks list hello_dag --tree
12<Task(BashOperator): Start>
13 <Task(SimpleHttpOperator): get_ip>
14 <Task(BashOperator): End>
15 <Task(PythonOperator): sleep>
16 <Task(BashOperator): End>
17$ airflow dags trigger hello_dag
18[2022-08-09 13:33:54,117] {__init__.py:40} INFO - Loaded API auth backend: airflow.api.auth.backend.session
19Created <DagRun hello_dag @ 2022-08-09T18:33:54+00:00: manual__2022-08-09T18:33:54+00:00, externally triggered: True>
20$ airflow tasks run hello_dag get_ip manual__2022-08-09T19:00:17+00:00
21[2022-08-09 14:08:58,602] {dagbag.py:508} INFO - Filling up the DagBag from /Users/yanbin/airflow/dags
22[2022-08-09 14:08:59,247] {task_command.py:371} INFO - Running <TaskInstance: hello_dag.get_ip manual__2022-08-09T19:00:17+00:00 [success]> on host xyz
23[2022-08-09 14:09:03,500] {dagbag.py:508} INFO - Filling up the DagBag from /Users/yanbin/airflow/dags/hello_dag.py
24[2022-08-09 14:09:04,001] {task_command.py:371} INFO - Running <TaskInstance: hello_dag.get_ip manual__2022-08-09T19:00:17+00:00 [success]> on host xyz测试一个 DAG
$ airflow dags test hello_dag 2022-08-09会同步的执行一个 DAG, 并在控制台下显示全部任务的输出
执行 DAG 下的一个任务
$ airflow tasks test hello_dag get_ip 2022-08-09
其他高级话题
- Sensors 是一个特殊的 Operator, 它可以监控外部的环境来实施任务的触发,例如 FileSensor 当某个文件存在时才触发
- Airflow 2.0 新引入了 TaskFlow 相关的装饰器,如 @dag, @task, 这让定义 DAG 和 Task 变得更简单
- 生产环境中推荐使用 PostgreSQL 或 MySQL 数据库,executor 不应使用默认的 SequentialExecutor, 可尝试 LocalExecutor, DaskExecutor 或 CeleryExecutor, 后两种又要配置一个大的环境
- 触发 DAG 时可传递参数,Task 中获得参数的方式是用 Jinja 模板语法
{{ dag_run.conf['conf1']}}, 通过 Web UI 触发Trigger DAG w/ config, 或命令airflow dags trigger --conf '{"conf1": "value1"}' hello_dag. Task 中{{ params }}参数会被{{ dag_run.conf }}所覆盖。 - Airflow 的 Provider, Plugin, Hook 等扩展方式值得以后需要时深究
- 在 Airflow 中可定义全局变量,可由 Web UI 或代码配置或取得,在模板中使用
{{ var.value.<variable_name> }}, 详情请见 Airflow Variables - 如果在 AWS 开 EC2 来自己安装管理 Airflow, 把 DAG 文件放到 S3 的 Bucket 的也能曲折实现的。比如内置一个 DAG 扫描 S3 Bucket 是否有文件更新,有则拷贝到本地的 $AIRFLOW_HOME/dags 目录中去,或配置 S3 Event -> SQS queue, 内置的 DAG 监听 SQS queue, 有消息则处理相应的事件更新本地目录 $AIRFLOW_HOME/dags
- 如果把 dags, 日志,数据库从 Airflow 服务器分离了开来,那么 Airflow 完全可以 Docker 的方式来运行
- hello_dag 是一个单文件定义的工作流,如果有复杂的工作流需多个文件协同时,考虑打成一个 zip 包来发布 DAG
- 官方的 Best Practices 一定要看,很重要, 命令
airflow cheat-sheet清楚的分类展示出所有常用命令 - airflow webserver 本身提供了 Swagger-UI 文档 http://localhost:8080/api/v1/ui/
链接:
永久链接 https://yanbin.blog/learning-airflow-get-started/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。