用 llama.cpp 体验 Meta 的 Llama AI 模型
继续体验 Meta 开源的 Llama 模型,前篇 试用 Llama-3.1-8B-Instruct AI 模型 直接用 Python 的 Tranformers 和 PyTorch 库加载 Llama 模型进行推理。模型训练出来的精度是 float32, 加载时采用的精度是 torch.bfloat16。
注:数据类型 torch.float32, torch.bfloat16, 与 torch.float16 有不同的指数(Exponent),尾数(Fraction)宽度, 它们都有一位是符号位,所以剩下的分别为指数位和尾数位宽度, torch.float32(8, 23), torch.bfloat16(8, 7), torch.float16(5, 10)。
模型依赖于 GPU 的显存,根据经验, 采用 16 位浮点数加载模型的话,推理所需显存大小(以 GB 为单) 是模型参数量(以 10 亿计) 的两倍,如 3B 模型需要约 6G 显存。如果对模型进一步量化,如精度量化到 4 位整数,则所需显存大小降为原来的 1/4 到 1/3, 意味着 3B 模型只要 2 G 显存就能进行推理。所以我们可以把一个 3B 的模型塞到手机里去运行,如果是 1B 的模型 int4 量化后内存占用不到 1G(0.5 ~ 0.67)。
本文体验 llama.cpp 对模型进行推理,在 Hugging Face 的用户设置页面 Local Apps and Hardware, 可看到一些流行的跑模型的应用程序,分别是
我们将在 Linux 下使用 llama.cpp,以及对模型进行量化缩身。llama.cpp 是用 C/C++ 重新实现了模型的推理过程。上面的的 node-llama-cpp 是对 llama.cpp 的套壳, 即对 llama.cpp 的 Bindings,llama.cpp 的 git 仓库中有这个 Bindings 列表, 几乎流行语都可(将)能找到相应的壳,如 Python, Go, Node.js, Ruby, Rust, C#, Java, Swift, Scala, PHP 等。Ollama 使用了 llama.cpp 代码,它更简化了对 Llama 模型的使用。
如果在 Mac OS X 下用 brew search 搜索可找到 gollama, llama.cpp, ollama, llm, llamachat, notesollama, ollma, ollamac 等运行 Llama 模型的应用程序,因为 Mac 电脑的配置比较单纯。本文不打算介绍在 Mac OS X 下使用 llama.cpp, 因为 M3 Pro 毕竟比家装的 RTX 4090 推理差了许多。
说到机器跑模型的能力,不得不涉及一个度量 -- 浮点计算能力衡量 TFLOPS(Tera Floating Point Operations Per Second),下面是三组硬件的 TFLOPS 对比。
铺垫了一大堆,山还没见到,主角 llama.cpp, 它的效率是毋庸置疑的,不然为何那么多的组件踩在了它的肩膀之上。本文将继续使用 Llama-3-8B-Instruct 模型,并与先前的性进行简单的感性对比。
在 Linux 中需安装 gcc, g++, 这里不细讲它们的安装,已知当前在 Ubuntu 22.04 下安装的版本分别是 gcc 13.2.0, g++ 13.2.0
直接用 apt install nvidia-cuda-toolkit 可能版本太旧, nvcc --version 看到的 cuda 版本 11.5, 还不够 RTX 4090 的 CUDA_DOCKER_ARCH=compute_89 兼容的版本,所以需先到 CUDA Toolkit 选择相应的 Linux 发行版 deb 安装方式 CUDA Toolkit 12.6 Update 2 Downloads
编译之后生成一系列的可执行文件
 上图中绿色的文件名,除 *.py 之外的文件都是编译新生成的,llama.cpp 没有提供 make install 来把相应的执行文件拷贝到像 /usr/local/bin 之类的目录,可以自行做相应的操作,或把该路径配置到 PATH 环境变量中。
上图中绿色的文件名,除 *.py 之外的文件都是编译新生成的,llama.cpp 没有提供 make install 来把相应的执行文件拷贝到像 /usr/local/bin 之类的目录,可以自行做相应的操作,或把该路径配置到 PATH 环境变量中。
*.py 文件的功能后面会介绍到,它们是几个用来转换模型文件格式为 llama.cpp 能懂的 GGML 或 GGUF 的程序,需用它们的话要创建 Python 虚拟环境并安装 requirements.txt 中的依赖。
下载模型
在
如果加上 -ngl 99 参数,则会用 GPU 进行推理,非常的快(从后面的结果可知从 25 秒降到 2.5 秒),同时看到 GPU 的使用率上到 97%, 功率要往 270W 以上冲。
比如前面用 convert_hf_to_gguf.py 脚本生成的 models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-F16.gguf 文件大小是 15G,它的精度是 F16(16 位的浮点数), 显存大小至少需要 15G。下面我们对它进行量化到 int4(4 位整数表示权重),用 llama.cpp 中的命令
llama-quantize 的参数 Q4-K_M 说明:Q 代表量化,4 为量化过程中使用的位数,K 表示量化中使用 K 均值聚类, M 表示量化后的模型大小,小(S), 中(M), 大(L)
立马使用量化后的模型
用感观的时间消耗来记录回答问题的时间,精确的计时应该要用 x tokens per second. 而且测量是用手机的 StopWatch, 不甚精确,但零点几秒的感受还是很真切的。
区分 llama.cpp 是否用 GPU 的方式是: 1) 编译时是否用了 GGML_CUDA=1 参数, 2) llama-cli 执行时是否用了 -ngl 99 参数。因 GPU, CPU 长得很像,故用红色粗体把 GPU 醒目出来。
这是使用 llama.cpp 的命令:./llama-cli -cnv -m Llama-3.1-8B-Instruct-Q4_K_M.gguf [-ngl 99]
使用 llama.cpp 完全实现的推理比起 Python 的 Transformers Pipeline 无论是 GPU 还是 CPU 推理都要快很多,尤其是大大改进了 CPU 推理的性能,基本可接受的速度,llama.cpp 需要的 GPU 显存和 Transformers Pipeline 差不多,但占用的主内存却大得多(不知为何)。
查看帮助
启动后,浏览器中打开 http://localhost:8080 就能看到聊天界面,我们直接点击
 除了 UI 外,llama-server 还提供了更多的 API Endpoints
除了 UI 外,llama-server 还提供了更多的 API Endpoints
 就可以回到 New Chat 然后选择 llama-server 相对应的模型(Models/Meta-Llama/Llama-3.1-8B-Instruct-Q4_K_M.gguf,或在 Settings/Interface 中选择它为默认模型
就可以回到 New Chat 然后选择 llama-server 相对应的模型(Models/Meta-Llama/Llama-3.1-8B-Instruct-Q4_K_M.gguf,或在 Settings/Interface 中选择它为默认模型
 选择后看到在所选模型下有
选择后看到在所选模型下有
那我们来点实现意义的问答:write python code to read s3 object?, 效果如下
 效果非常不错,甚至可拿来与 ChatGPT 相对比,当然受限于硬件条件,不然跑一个 Llama 70B 的模型更能与之相比拼。llama.cpp 的性能还是很值得称赞的,现实应用中直接用 Transformers Pipeline 的方式是完全没有必要的了。Ollama 简单化 Llama 模型的使用并维护了自己的像 HuggingFace 那样的仓库,以后也值得一试。
效果非常不错,甚至可拿来与 ChatGPT 相对比,当然受限于硬件条件,不然跑一个 Llama 70B 的模型更能与之相比拼。llama.cpp 的性能还是很值得称赞的,现实应用中直接用 Transformers Pipeline 的方式是完全没有必要的了。Ollama 简单化 Llama 模型的使用并维护了自己的像 HuggingFace 那样的仓库,以后也值得一试。
链接:
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
注:数据类型 torch.float32, torch.bfloat16, 与 torch.float16 有不同的指数(Exponent),尾数(Fraction)宽度, 它们都有一位是符号位,所以剩下的分别为指数位和尾数位宽度, torch.float32(8, 23), torch.bfloat16(8, 7), torch.float16(5, 10)。
模型依赖于 GPU 的显存,根据经验, 采用 16 位浮点数加载模型的话,推理所需显存大小(以 GB 为单) 是模型参数量(以 10 亿计) 的两倍,如 3B 模型需要约 6G 显存。如果对模型进一步量化,如精度量化到 4 位整数,则所需显存大小降为原来的 1/4 到 1/3, 意味着 3B 模型只要 2 G 显存就能进行推理。所以我们可以把一个 3B 的模型塞到手机里去运行,如果是 1B 的模型 int4 量化后内存占用不到 1G(0.5 ~ 0.67)。
本文体验 llama.cpp 对模型进行推理,在 Hugging Face 的用户设置页面 Local Apps and Hardware, 可看到一些流行的跑模型的应用程序,分别是
- 生成文本的: llama.cpp, LM Studio, Jan, Backyard AI, Jellybox, RecurseChat, Msty, Sanctum, LocalAI, vLLM, node-llama-cpp, Ollama, TGI
- 文生图的: Draw Things, DiffusionBee, Invoke, JoyFusion
我们将在 Linux 下使用 llama.cpp,以及对模型进行量化缩身。llama.cpp 是用 C/C++ 重新实现了模型的推理过程。上面的的 node-llama-cpp 是对 llama.cpp 的套壳, 即对 llama.cpp 的 Bindings,llama.cpp 的 git 仓库中有这个 Bindings 列表, 几乎流行语都可(将)能找到相应的壳,如 Python, Go, Node.js, Ruby, Rust, C#, Java, Swift, Scala, PHP 等。Ollama 使用了 llama.cpp 代码,它更简化了对 Llama 模型的使用。
如果在 Mac OS X 下用 brew search 搜索可找到 gollama, llama.cpp, ollama, llm, llamachat, notesollama, ollma, ollamac 等运行 Llama 模型的应用程序,因为 Mac 电脑的配置比较单纯。本文不打算介绍在 Mac OS X 下使用 llama.cpp, 因为 M3 Pro 毕竟比家装的 RTX 4090 推理差了许多。
说到机器跑模型的能力,不得不涉及一个度量 -- 浮点计算能力衡量 TFLOPS(Tera Floating Point Operations Per Second),下面是三组硬件的 TFLOPS 对比。
- RTX 4090: 82.58 TFLOPS
- i9-13900F, 内存 64G: 0.85 TFLOPS
- Apple M3 Pro, 内存 36G: 14.00 TFLOPS
铺垫了一大堆,山还没见到,主角 llama.cpp, 它的效率是毋庸置疑的,不然为何那么多的组件踩在了它的肩膀之上。本文将继续使用 Llama-3-8B-Instruct 模型,并与先前的性进行简单的感性对比。
Linux(Ubuntu 24.04) 下 llama.cpp 的编译安装
在 Ubuntu 24.04 下用 apt search llama 找不到任何相关的组件,没有 Mac OS X 用户幸福,所以只得从源码构建。在 Linux 中需安装 gcc, g++, 这里不细讲它们的安装,已知当前在 Ubuntu 22.04 下安装的版本分别是 gcc 13.2.0, g++ 13.2.0
直接用 apt install nvidia-cuda-toolkit 可能版本太旧, nvcc --version 看到的 cuda 版本 11.5, 还不够 RTX 4090 的 CUDA_DOCKER_ARCH=compute_89 兼容的版本,所以需先到 CUDA Toolkit 选择相应的 Linux 发行版 deb 安装方式 CUDA Toolkit 12.6 Update 2 Downloads
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb最后在 .bashrc(或其他的 shell 配置) 中加上环境变量
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudp apt update
sudo apt install -y cuda-toolkit-12-6
sudo apt install nvidia-open # 或许要更新驱动
export PATH=/usr/local/cuda-12.6/bin:$PATH总之一通操作完最后执行 nvcc --version 能看到的 CUDA 版本是 11.8 或更新的就对了
export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64:$LD_LIBRARY_PATH
nvcc --version环境准备完毕,终于可以开始 llama.cpp 的编译工作了, 参考 Build llama.cpp locally
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Thu_Sep_12_02:18:05_PDT_2024
Cuda compilation tools, release 12.6, V12.6.77
Build cuda_12.6.r12.6/compiler.34841621_0
git clone https://github.com/ggerganov/llama.cpp用 make 编译
cd llama.cpp
make GGML_CUDA=1加了 GGML_CUDA=1 参数才能让 llama.cpp 使用 GPU, 否则只用 CPU 进行推理。经过对比加上 GGML_CUDA=1 参数进行编译比没用该参数时要慢得多。
编译之后生成一系列的可执行文件
 上图中绿色的文件名,除 *.py 之外的文件都是编译新生成的,llama.cpp 没有提供 make install 来把相应的执行文件拷贝到像 /usr/local/bin 之类的目录,可以自行做相应的操作,或把该路径配置到 PATH 环境变量中。
上图中绿色的文件名,除 *.py 之外的文件都是编译新生成的,llama.cpp 没有提供 make install 来把相应的执行文件拷贝到像 /usr/local/bin 之类的目录,可以自行做相应的操作,或把该路径配置到 PATH 环境变量中。*.py 文件的功能后面会介绍到,它们是几个用来转换模型文件格式为 llama.cpp 能懂的 GGML 或 GGUF 的程序,需用它们的话要创建 Python 虚拟环境并安装 requirements.txt 中的依赖。
下载 meta-llama/Llama-3-8B-Instruct 模型
关于 huggingface-cli 的安装及 token 配置,或申请模型的访问权限此处就不再重复,可翻看上一篇。在模型 https://huggingface.co/meta-llama/Llama-3.2-3B-Instruct/tree/main文件列表页面,最外层是有几个 *.safetensors 文件,在 original 目录中有 PyTorch 的原始训练文件 *.pth。并没有提供 llama.cpp 支持的 GGML 或 GGUF 的 *.bin 格式,所以我们要从 HuggingFace 的格式 *.safetensors 文件格式转换成需要的 GGUF 格式文件,GGUF 继承自 GGML 格式,GGML 是旧有格式。下载模型
huggingface-cli download meta-llama/Llama-3.1-8B-Instruct --exclude "original/*" --local-dir models/meta-llama/Llama-3.1-8B-Instruct考虑网速的时刻又来了,看到的四个 *.safetensors 文件加起来有 15G 多, huggingface-cli 在下载时或许会作些优化吧,压缩?恐怕没多大比率能再压缩。
du -sh models/meta-llama/*
15G models/meta-llama/Llama-3.1-8B-Instruct
转换模型为 GGUF 格式
llama.cpp 既提供了 requirements.txt, 也有 Poetry 的 pyproject.toml, 我们将用前者来创建 Python 虚拟环境吧。仍然是在 llama.cpp 目录python -m venv .venv最后看到输出
source .venv/bin/activate
pip install -r requirements.txt
python convert_hf_to_gguf.py models/meta-llama/Llama-3.1-8B-Instruct
INFO:hf-to-gguf:Model successfully exported to models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-F16.gguf ls -lh models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-F16.gguf也就是 convert_hf_to_gguf.py 生成了 GGUF 格式的 Llama-3.1-8B-Instruct-F16.gguf 单个文件,同样是 15G。它的精度是 F16,我们将在后面对它进行量化来缩小它的体积。
-rw-rw-r-- 1 yanbin yanbin 15G Nov 5 23:50 models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-F16.gguf
正式使用 llama.cpp
从前面构建 llama.cpp 生成的可执行文件有 llama-cli, llama-server, 这两个可堪大用, llama-cli --help 帮助很详尽,最后是两个示例用法text generation: ./llama-cli -m your_model.gguf -p "I believe the meaning of life is" -n 128 chat (conversation): ./llama-cli -m your_model.gguf -p "You are a helpful assistant" -cnv来次 chat 吧
./llama-cli -m models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-F16.gguf -p "chat assistant" -cnv用
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: yes
ggml_cuda_init: GGML_CUDA_FORCE_CUBLAS: yes
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes
build: 4034 (b8deef0e) with cc (Ubuntu 12.3.0-1ubuntu1~22.04) 12.3.0 for x86_64-linux-gnu
main: llama backend init
main: load the model and apply lora adapter, if any
llama_load_model_from_file: using device CUDA0 (NVIDIA GeForce RTX 4090) - 23588 MiB free
llama_model_loader: loaded meta data with 33 key-value pairs and 292 tensors from models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-F16.gguf (version GGUF V3 (latest))
...... 中间显示许多信息,最后是
chat assistant
>
watch -d -n 1 nvidia-smi 观察到显存占用了 17G,同时 llama-cli 进程占用内存也达到 15.8G, 说明同时在主内存和显卡中都加载了该模型,是用 CPU 还是 GPU 来推理会相机而动。在
> 提示符下输入老问题 "USA 5 biggest cities and population?", 这时候的结果输出和 ChatGPT 一样了,是一个字一个字的蹦出来的,很有喜感,同时 GPU 的使用率是 0,说明是用的 CPU 进行的推理。如果加上 -ngl 99 参数,则会用 GPU 进行推理,非常的快(从后面的结果可知从 25 秒降到 2.5 秒),同时看到 GPU 的使用率上到 97%, 功率要往 270W 以上冲。
./llama-cli -m models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-F16.gguf -p "chat assistant" -cnv -ngl 99 --color-ngl 参数的意义是
-ngl, --gpu-layers, --n-gpu-layers N number of layers to store in VRAM用 GPU 推理的速度明显要比 CPU 快。
(env: LLAMA_ARG_N_GPU_LAYERS)
模型量化(Model Quantization)
量化一词乍一听有些高大上,很容易就联想到量化交易,量化宽松那些概念。AI 模型的量化是指通过某种方法将浮点模型转化为定点模型,即用浮点数(如 float32) 表示的权重映射到定点数(如 int8, int4 等) 表示的区间中。量化后的效果就是内存占用少,计算量变小,但精度损失,可类比为把位图(BMP) 转换为 JPEG 格式的压缩算法,体积减小,图片质量有所损失,这需要在内存,速度与精度之间找到一个符合自己的平衡。比如前面用 convert_hf_to_gguf.py 脚本生成的 models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-F16.gguf 文件大小是 15G,它的精度是 F16(16 位的浮点数), 显存大小至少需要 15G。下面我们对它进行量化到 int4(4 位整数表示权重),用 llama.cpp 中的命令
./llama-quantize models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-F16.gguf models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-Q4_K_M.gguf Q4_K_M量化后的模型大小是 4.6 G, 差不多就是 F16(16位) 到 int4(4位) 的 1/3 大小,自然是显存空间要求大大降低了。
ls -lh models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-Q4_K_M.gguf
-rw-rw-r-- 1 yanbin yanbin 4.6G Nov 10 16:20 models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-Q4_K_M.gguf
llama-quantize 的参数 Q4-K_M 说明:Q 代表量化,4 为量化过程中使用的位数,K 表示量化中使用 K 均值聚类, M 表示量化后的模型大小,小(S), 中(M), 大(L)
立马使用量化后的模型
./llama-cli -m models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-Q4_K_M.gguf -p "chat assistant" -cnv -ngl 99 --color用
watch -d -n 1 nvidia-smi 观察所使用的显存为 5.6G, 远低于 F16 表示权重的 17G 大小。推理速度也会变得更快,下一节将对不同情景上的速度进行对比内/显存占用及推理速度对比
学习到这里我们把用 Transformers Pipeline, llama.cpp 加载 F16 模型和量化成 int4 模型的内存,显卡,及推理速度进行对比。所用机器硬件配置为 CPU: i9-13900F, 内存:64G,显卡 RTX4090(显存24G)。我们都将问同一个问题:USA 5 biggest cities and population?用感观的时间消耗来记录回答问题的时间,精确的计时应该要用 x tokens per second. 而且测量是用手机的 StopWatch, 不甚精确,但零点几秒的感受还是很真切的。
| 运行方法 | 模型 | 权重表示 | 推理硬件 | 内存占用 | 显存占用 | 模型加载时间(s) | 推理时间(s) |
| Transformer Pipeline | meta-llama/Llama-3.1-8B-Instruct | bfloat16 | GPU | 26G | 15.8G ~ 16G | 2.4 | 2.7 |
| Transformer Pipeline | meta-llama/Llama-3.1-8B-Instruct | bfloat16 | CPU | 19G ~ 23G | 0 | 0.73 | 488 |
| llama.cpp | Llama-3.1-8B-Instruct-F16.gguf | F16 | CPU | 16G | 0 | 1 | 25 |
| llama.cpp | Llama-3.1-8B-Instruct-F16.gguf | F16 | GPU | 53.8G | 15.5G | 2 | 2.5 |
| llama.cpp | Llama-3.1-8B-Instruct-Q4_K_M.gguf | int4 | CPU | 58.9G | 0 | 1 | 8.5 |
| llama.cpp | Llama-3.1-8B-Instruct-Q4_K_M.gguf | int4 | GPU | 43.3G | 5.6G ~ 5.7G | 1.3 | 1.2 |
区分 llama.cpp 是否用 GPU 的方式是: 1) 编译时是否用了 GGML_CUDA=1 参数, 2) llama-cli 执行时是否用了 -ngl 99 参数。因 GPU, CPU 长得很像,故用红色粗体把 GPU 醒目出来。
这是使用 llama.cpp 的命令:./llama-cli -cnv -m Llama-3.1-8B-Instruct-Q4_K_M.gguf [-ngl 99]
使用 llama.cpp 完全实现的推理比起 Python 的 Transformers Pipeline 无论是 GPU 还是 CPU 推理都要快很多,尤其是大大改进了 CPU 推理的性能,基本可接受的速度,llama.cpp 需要的 GPU 显存和 Transformers Pipeline 差不多,但占用的主内存却大得多(不知为何)。
llama-server
编译出来的 llama.cpp 中有server 和 llama-server 两个命令,前者已标注为不建议使用,所以我们要用 llama-server 命令。llama-server 会启动一个 Web Server, 它本身提供聊天界面,第三方的 Chat UI 可接入该 llama-server 的 Endpoints。查看帮助
llama-server --help ,它的许多参数与 llama-cli 是一样的,因为毕竟都是加载模型进行推理的,只是接口不一样而已。而且从它的帮助中发现它还能支持 ApiKey, 可配置 SSL,线程数,缓存等,完全可以作为一个产品环境下的 Web 服务./llama-server -ngl 99 --host 0.0.0.0 -c 2048 --matrics -m models/meta-llama/Llama-3.1-8B-Instruct/Llama-3.1-8B-Instruct-Q4_K_M.gguf-ngl 99 可较优先使用 GPU; -c 2048: token 的最大长度为 2048
启动后,浏览器中打开 http://localhost:8080 就能看到聊天界面,我们直接点击
New UI 进入到新式界面 除了 UI 外,llama-server 还提供了更多的 API Endpoints
除了 UI 外,llama-server 还提供了更多的 API Endpoints- GET /health
- POST /completion: 根据指定的提示生成文本
- POST /tokenize: 获得输入文本的 token 值
- POST /detokenize: 把 token 转换回文本
- POST /embedding: 得到输入文本的 embedding
- POST /reranking: 由给定的查询对文档重排序, 启动 llama-server 时需 --reranking 参数,但不能用 --embedding 参数
- POST /infill: 根据前后缀完成中间代码
- GET /props: 获取服务端全局属性配置
- POST /props: 修改服务端全局属性
- POST /v1/chat/completions: 与 OpenAI 兼容的 C0mpletions API
- POST /v1/embeddings: 与 OpenAPI 兼容的 embeddings API
- GET /slots: 返回当前 slot 的处理状态
- GET /metrics: 获得服务端的执行指标数据
- POST /slots/{id_slot}?action=save: 保存相应 slot 上的提示 cache 为文件
- POST /slots/{id_slot}?action=restore: 从文件恢复提示 cahce 到相应 slot
- POST /slots/{id_slot}/action=earase: 删除相应 slot 上的提示 cache
- GET /lora-adapters: 获取 LoRA 适配器列表
- POST /lora-adapters: 设置 LoRA 适配器列表
尝试 Open WebUI 连接 llama-server
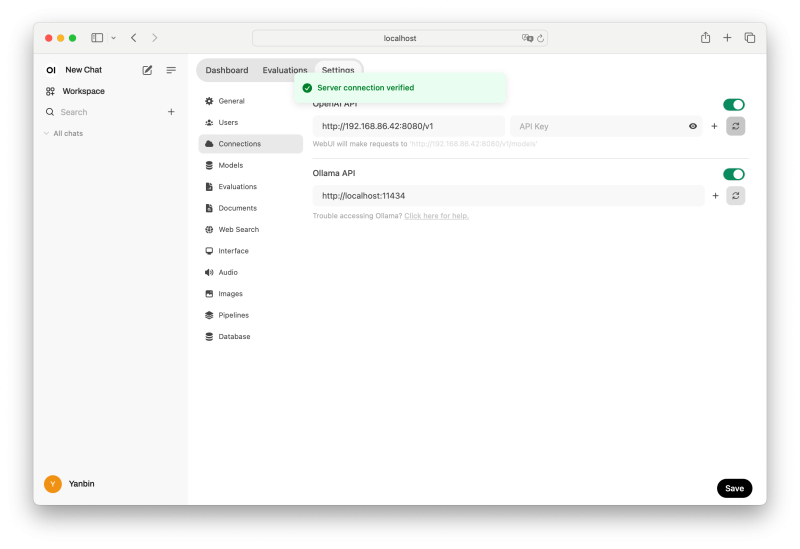
Open WebUI 与 Ollama 较为友好,但 llama-server 实现了与 OpenAI 相兼容的 APIs, 所以也能用 Open WebUI 连接 llama-server 启动的服务python3.11 -m venv venv启动后访问 http://localhost:8080, 然后创建用户,进而用新用户登陆。到到用户的 Settings/Connections 中,把原本 OpenAI API 中的 https://api.openai.com/v1 改成 llama-server 的 endpoint, 如这里假定 llama-server 在 192.168.86.42:8080 上启动的,则填入 http://192.168.86.42:8080/v1, 然后点击它最右端的刷新校验按扭,看到 Server connection verified 提示
source venv/bin/activate
pip install open-webui
open-webui serve
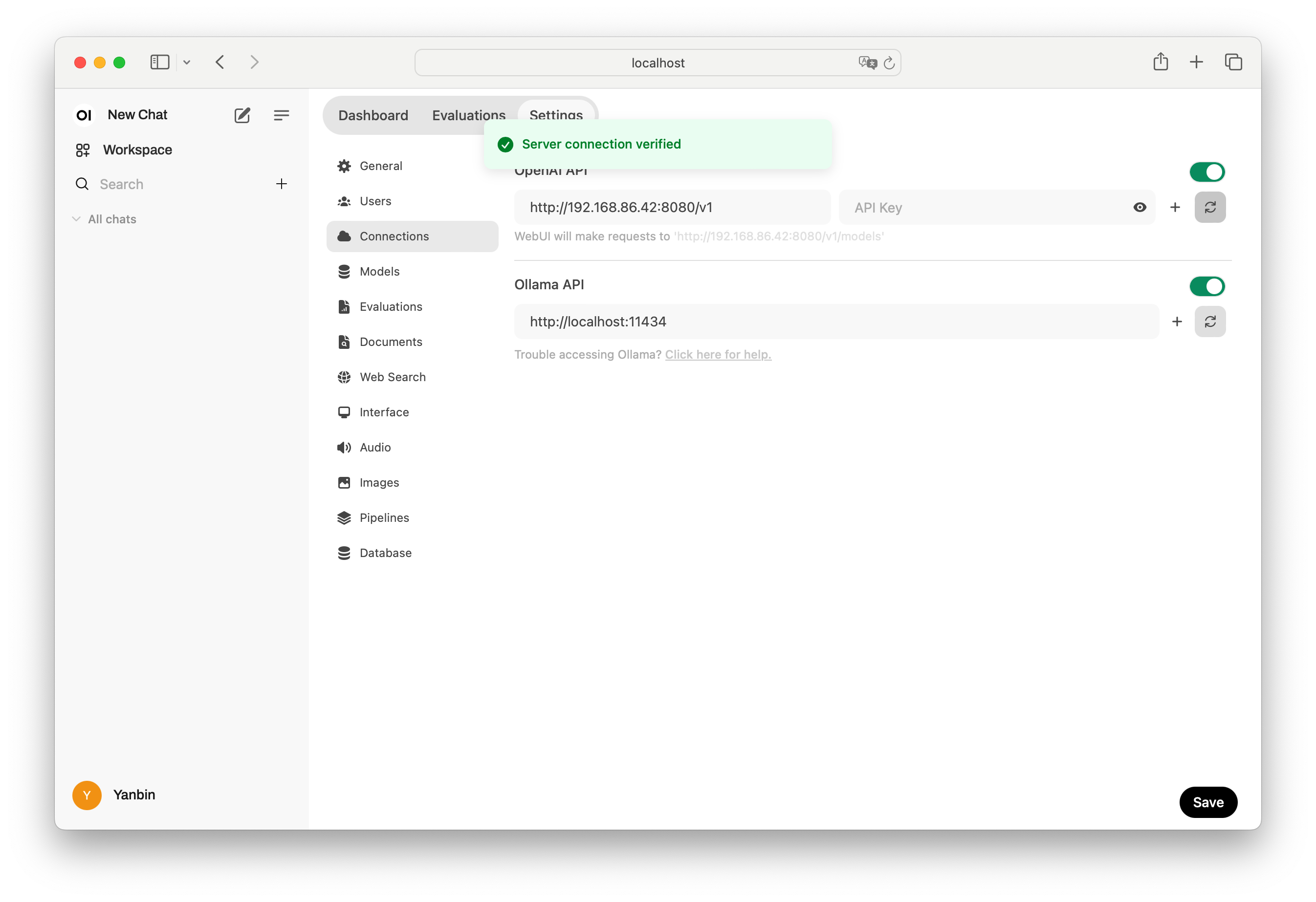 就可以回到 New Chat 然后选择 llama-server 相对应的模型(Models/Meta-Llama/Llama-3.1-8B-Instruct-Q4_K_M.gguf,或在 Settings/Interface 中选择它为默认模型
就可以回到 New Chat 然后选择 llama-server 相对应的模型(Models/Meta-Llama/Llama-3.1-8B-Instruct-Q4_K_M.gguf,或在 Settings/Interface 中选择它为默认模型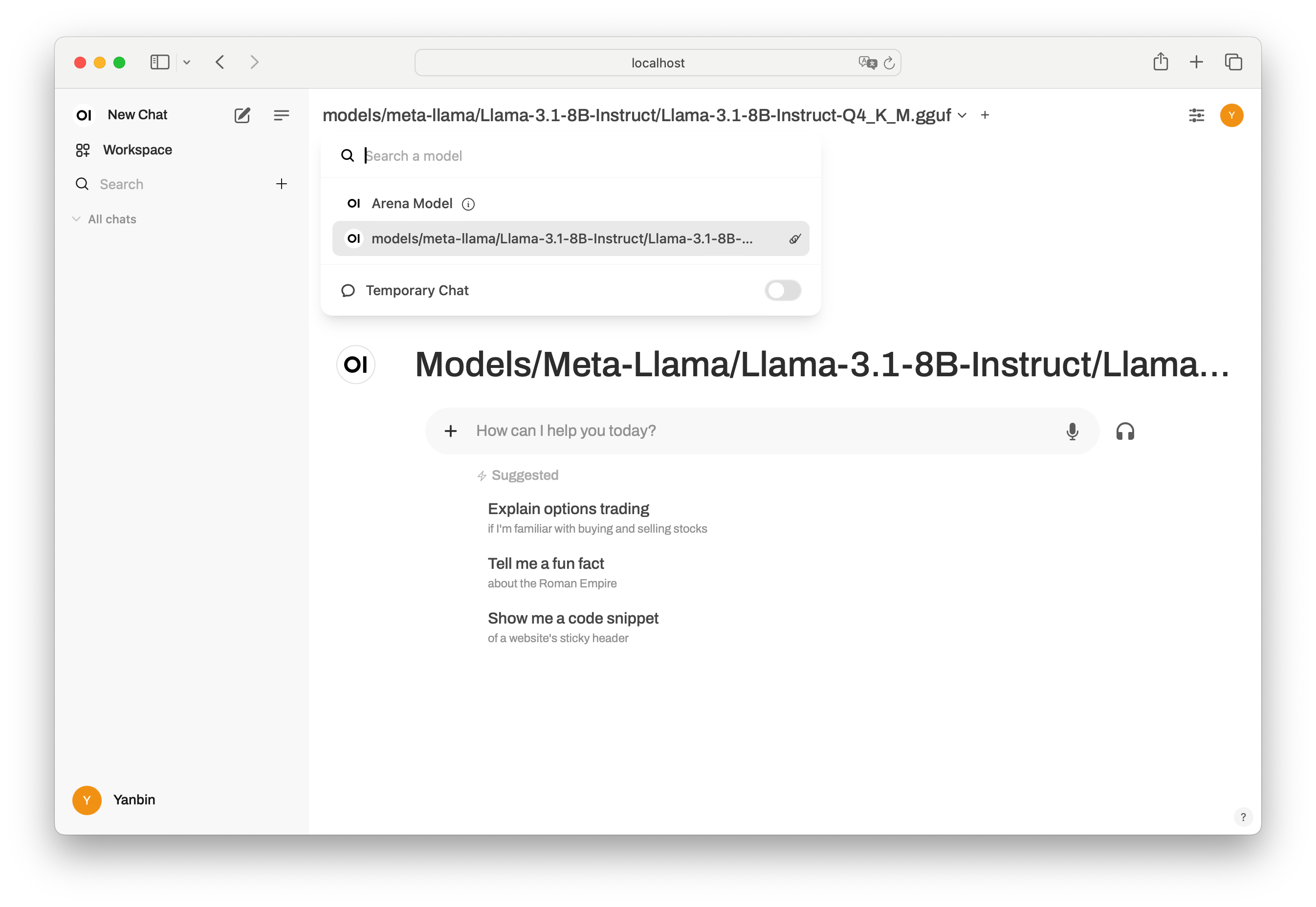 选择后看到在所选模型下有
选择后看到在所选模型下有 How can I help you today? 这个聊天输入框,现在可以和 Llama-3.1-8B 尽情的聊天了, 而且还有语音支持,语音输入能转换成文本,并在得到答案中点击按钮会进行朗读。在进行语音输入后可在 llama-server 后台看到 Lllama 把语音转换成文本的过程信息。那我们来点实现意义的问答:write python code to read s3 object?, 效果如下
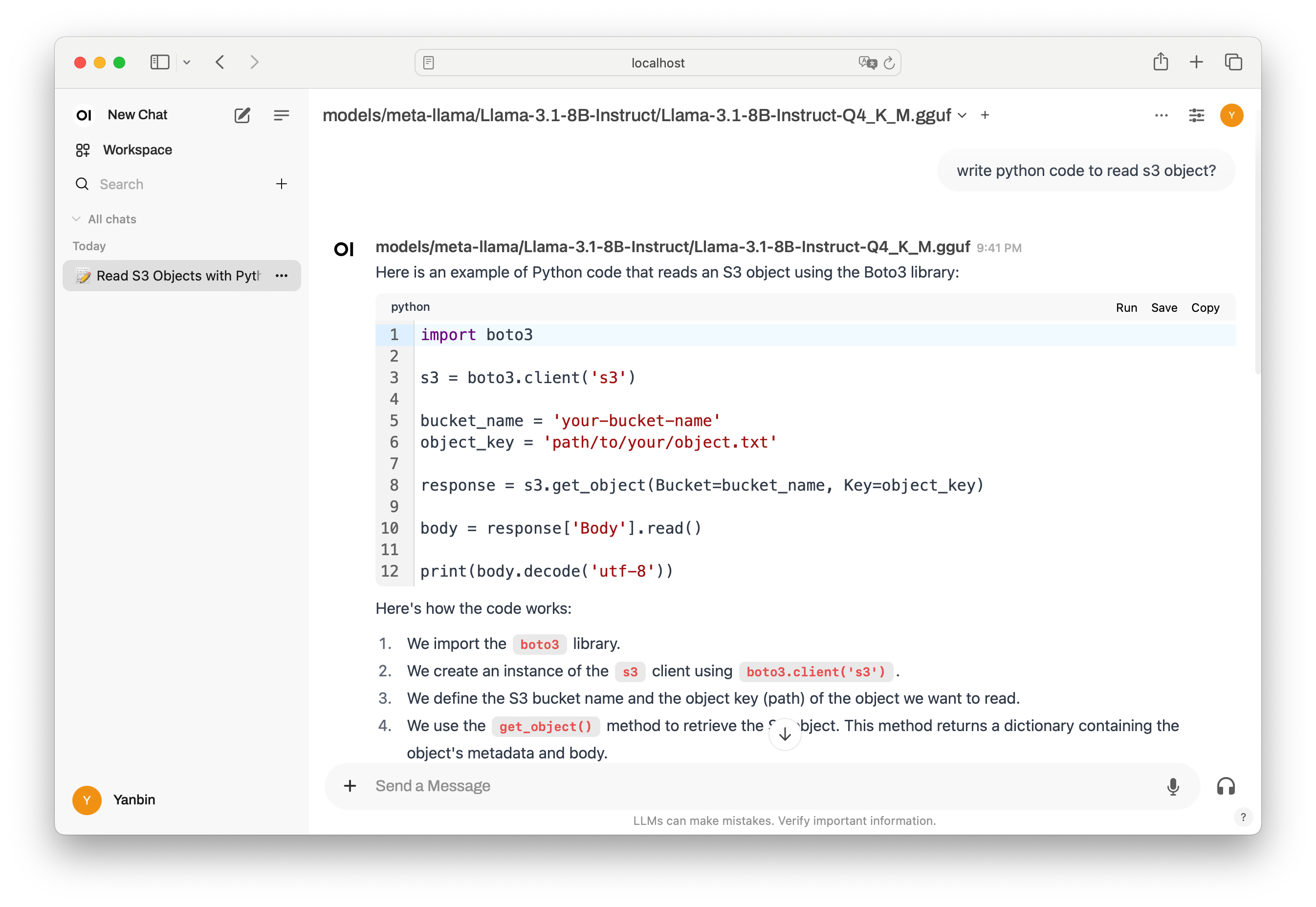 效果非常不错,甚至可拿来与 ChatGPT 相对比,当然受限于硬件条件,不然跑一个 Llama 70B 的模型更能与之相比拼。llama.cpp 的性能还是很值得称赞的,现实应用中直接用 Transformers Pipeline 的方式是完全没有必要的了。Ollama 简单化 Llama 模型的使用并维护了自己的像 HuggingFace 那样的仓库,以后也值得一试。
效果非常不错,甚至可拿来与 ChatGPT 相对比,当然受限于硬件条件,不然跑一个 Llama 70B 的模型更能与之相比拼。llama.cpp 的性能还是很值得称赞的,现实应用中直接用 Transformers Pipeline 的方式是完全没有必要的了。Ollama 简单化 Llama 模型的使用并维护了自己的像 HuggingFace 那样的仓库,以后也值得一试。 链接:
- Achieve State-of-the-Art LLM Inference (Llama 3) with llama.cpp
- Understanding internals of java-llama.cpp
- How to Install Llama.cpp - A Complete Guide
- Comparing Llama.Cpp, Ollama, and vLLM
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。