Ollama - 简化使用本地大语言模型
学习完用 Transformers 和 llama.cpp 使用本地大语言模型后,再继续探索如何使用 Ollama 跑模型。Ollama 让运行和管理大语言模型变得更为简单,它构建在 llama.cpp 之上,并有优化,性能表现同样不俗。下面罗列一下它的特点
其他更多特性我们将在使用当中体验,仍然是在 i9-13900F + 64G 内存 + RTX 4090 + Ubuntu 22.4 台上进行
Ollama 的模型像 Docker 镜像那样的 tag 方式,以上
如果要下载 70b 的模型就用 ollama pull llama3.2-vision:70b
更多 ollama 命令的使用,请参考
从我们用 nvidia-smi 观察到的 ollama run llama3.2-vision:11b 前后 GPU 使用状态都是一样的
如果问问题的话,比如还是老问题: USA 5 biggest cities and population?
看到的 nvidia-smi 的使用情况是有所波动的
说明 GPU 在进行推理操作,即使是输入
ollama ps 列出已加载的模型
从中可知是由 100% GPU 处理的。
ollama run 不仅仅是启动了一个进程,用 ps 命令查看后台
看到的是 ollama run, 其实在后台还是启动了 ollama serve, 然而真正加载模型的进程是 ollama_llama_server, 用
当输入
三个进程的关系是:
ollama run 只是作为 ollama serve 的一个客户端, 可以通过环境变量让 ollama run 连接指定的 ollama_serve 服务,如
继续在 ollama 相关的进程观察会发现 ollama serve 是由 systemd 控制的,所以任由你如何
要关掉 systemd 启动的 ollama-serve 必需用 sudo systemctl stop ollama 命令
特定命令的帮助也是用 --help, 如
那么如果我们在启动
每个 ollama serve 会管理自己的 ollama_llama_server, 一个模型会有一个对应的 ollama_llama_server 服务。
当然通过 export 命令来导出环境变量也行。Ollama REST API Document 罗列了 Ollama API, Ollama 没有提供与 OpenAI API 相兼容的 completion APIs,下面主要尝试一下 /api/generate, 其他的就不详细展开了。
注意:如果你执行过
假说 ollama serve 运行在 http://192.168.86.42:4000, 则启动 Open WebUI 容器的命令用
从 Open WebUI 启动的控制台输出可以获得很多有用的信息,所以本文中不顾篇幅的保留了下来。
现在就可以打开浏览器,输入地址 http://192.168.86.61:3000,进行用户注册,完后登陆
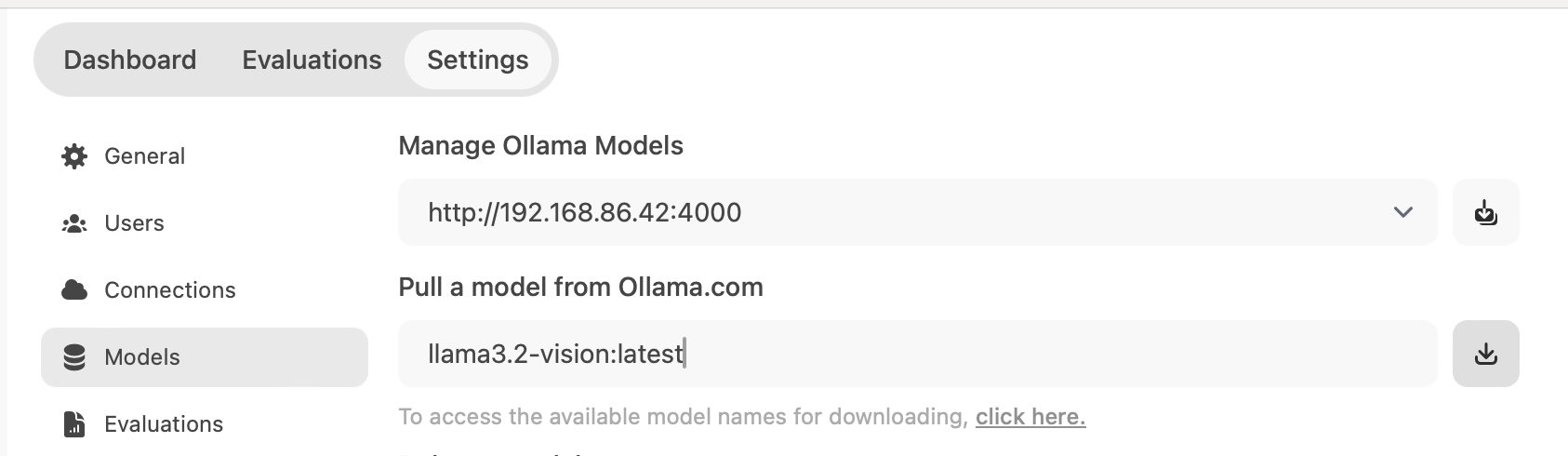
在 Admin Setting/Connections 就看到 Ollama API 是 http://192.168.86.42:4000, 在 Models 中的 Pull a model from Ollama.com 输入框中输入 "llama3.2-vision:latest", 点击下载按钮就会从 Ollama.com pull 指定的模型
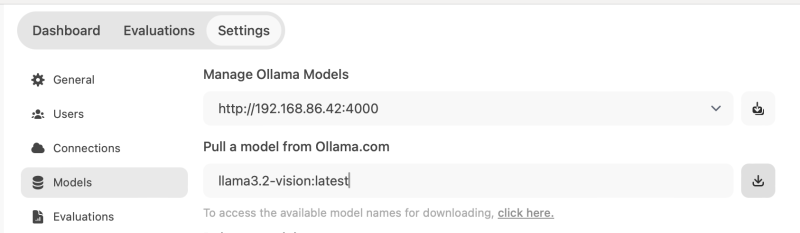 再回到用户 Settings/Interface 中就能选择 llama3.2-vision:latest 为 Default Model, 或者在 New Chat 时选择想要的模型
再回到用户 Settings/Interface 中就能选择 llama3.2-vision:latest 为 Default Model, 或者在 New Chat 时选择想要的模型
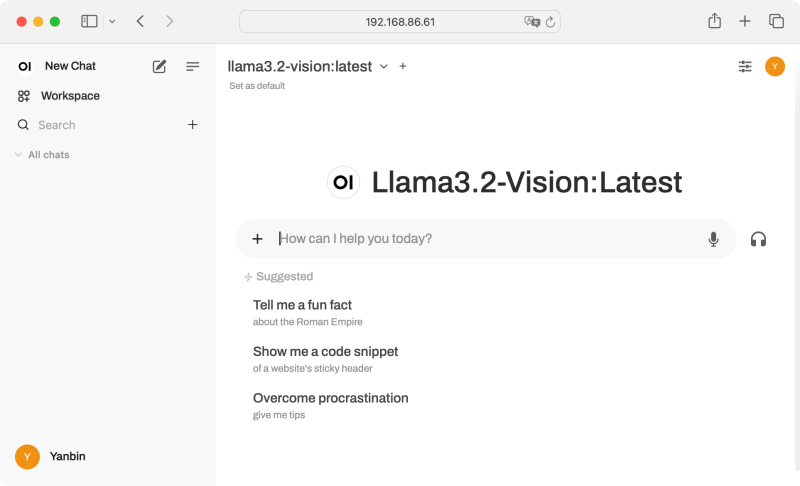 开始聊天, 在
开始聊天, 在
 正可谓 -vision, 那不妨看看它对图片理解能力吧,来一张现下关于美国大选的图片
正可谓 -vision, 那不妨看看它对图片理解能力吧,来一张现下关于美国大选的图片
 llama3.2-vision 这个模型还是理解到了是美国大选的事,并且有红州,蓝州,不过毕竟它是出自 Meta 公司,偏向蓝方就不奇怪了。
llama3.2-vision 这个模型还是理解到了是美国大选的事,并且有红州,蓝州,不过毕竟它是出自 Meta 公司,偏向蓝方就不奇怪了。
ollama run 或者 http client(如 Open WebUI) 都是 ollama serve 的客户端,ollama serve 根据客户端指定的模型动态管理 ollama_llama_server 进程,同一个 ollama serve 管理之下,每个模型会对应一个 ollama_llama_server 进程,某一模型长时间空闲就会被 ollama serve 停掉,需要时再启动。
 这张图应该能说明白 client -> ollama-serve -> ollama_llama_server 之间的关系。客户端可以指定用哪个 ollama-serve, 安装完 ollama 后系统会启动一个在 11434 端口号上监听的 ollama-serve 服务,并且它只能被本地连接,除非修改配置参数才能让系统启动的 ollama-serve 被远程连接。命令 ollama run 默认连接本地的 11434 端口号上的 ollama-serve 服务,可通过环境变量 OLLAMA_HOST 指定 ollama run 连接哪个 ollama-serve 服务。
这张图应该能说明白 client -> ollama-serve -> ollama_llama_server 之间的关系。客户端可以指定用哪个 ollama-serve, 安装完 ollama 后系统会启动一个在 11434 端口号上监听的 ollama-serve 服务,并且它只能被本地连接,除非修改配置参数才能让系统启动的 ollama-serve 被远程连接。命令 ollama run 默认连接本地的 11434 端口号上的 ollama-serve 服务,可通过环境变量 OLLAMA_HOST 指定 ollama run 连接哪个 ollama-serve 服务。
修改 systemd 管理的 ollama-serve 参数的方法是
除 Open WebUI 客户端还有许多,见 Ollama 客户端列表 Web & Desktop 和 Terminal.
链接:
永久链接 https://yanbin.blog/ollama-simple-use-local-llm-model/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
- 从它的 GitHub 项目 ollama/ollama, Go 语言代码 90.8%, C 代码 3.4%
- Ollama 不仅能运行 Llama 模型,还支持 Phi 3, Mistral, Gemma 2 及其他
- Ollama 支持 Linux, Windows, 和 macOS, 安装更简单,不用像 llama.cpp 那样需从源码进行编译,并且直接支持 GPU 的
- Ollama 有自己的模型仓库,无需申请访问权限,可从 Ollama 拉取所需模型,或 push 自己的模型到 Ollama 仓库pull llama3.2-vision
- Ollama 仓库的模型是量化过的,某个模型有大量的 tag 可选择下载,如 llama3.2 的 tags 有 1b, 3b, 3b-instruct-q3_K_M, 1b-instruct-q8_0, 3b-instruct-fp16 等
- 如果在 Ollama 上没有的模型,可以到 HuggingFace 上下载,或量化后再传到 Ollama 仓库
其他更多特性我们将在使用当中体验,仍然是在 i9-13900F + 64G 内存 + RTX 4090 + Ubuntu 22.4 台上进行
Ollama 在 Ubuntu 上的安装
Ollama 的安装方法建议采用官方 https://ollama.com/download/linux 的方式curl -fsSL https://ollama.com/install.sh | sh这样安装的 Ollama 能保证是最新版,避免版本落后造成不必要的麻烦。当前(AsOfDate: 2024-11-11) 看到的 Ollama 版本是 0.4.1
ollama --version注:不要用 apt 或 snap 来安装 ollama, 否则可能会安装一个过时的版本,造成 ollama 无法跑模型。本人对此就深有体验,首先尝试了用 apt install ollama, 得到的提示是 apt 没有 ollama, 建议用 snap install ollama 安装,安装是成功了,也能够用 ollama pull llama3.2-vision 拉取远端的相应模型, 但无法运行
ollama version is 0.4.1
ollama run llama3.2-vision找不到任何详细的错误信息,最后意识到从 snap 安装的版本问题,snap 安装了 0.3.13 版的 Ollama. 终究是费了很大一番功夫才卸载掉 snap 安装的 ollama, 并非 snap remove ollama 就能简单了事,其间使用的停掉 snapd 服务,手工删除目录等手段。
Error: llama runner process has terminated: exit status 127
拉取和运行 llama3.2-vision 模型
比 huggingface-cli download 要简单的,更像是 docker pull 操作,命令如下:ollama pull llama3.2-visionllama3.2-vision 有两种参数的模型可选,11b 和 90b, 它们都是被量化过的,规模为 Q4_K_M 大小
Ollama 的模型像 Docker 镜像那样的 tag 方式,以上
ollama pull llama3.2-vision 相当于是 ollama pull llama3.2-vision:latest. tag latest 指向了 11b, 为明确用哪个 tag,最后用ollama pull llama3.2-vision:11b下载后,ollama list 查看本地所有的模型
1ollama list
2NAME ID SIZE MODIFIED
3llama3.2-vision:11b 38107a0cd119 7.9 GB 44 seconds ago
4llama3.2-vision:latest 38107a0cd119 7.9 GB About a minute ago更多 ollama 命令的使用,请参考
ollama --help运行本地模型 - ollama run
我们将介绍两种方式,命令行交互模式与 Service 服务模式。启动 Ollama Service 服务模式的话可用 Open WebUI 连接,从而在 Web 界面中有如 ChatGPT 一般的用户体验。ollama run llama3.2-vision:11bollama run 立即进到命令行交互模式,在 Send a message (/? for help) 的 PlaceHolder 处就可以输入问题
>>> Send a message (/? for help)
从我们用 nvidia-smi 观察到的 ollama run llama3.2-vision:11b 前后 GPU 使用状态都是一样的
1+-----------------------------------------------------------------------------------------+
2| NVIDIA-SMI 560.35.03 Driver Version: 560.35.03 CUDA Version: 12.6 |
3|-----------------------------------------+------------------------+----------------------+
4| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
5| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
6| | | MIG M. |
7|=========================================+========================+======================|
8| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
9| 0% 39C P8 20W / 450W | 11616MiB / 24564MiB | 0% Default |
10| | | N/A |
11+-----------------------------------------+------------------------+----------------------+<br/><br/>
12+-----------------------------------------------------------------------------------------+
13| Processes: |
14| GPU GI CI PID Type Process name GPU Memory |
15| ID ID Usage |
16|=========================================================================================|
17| 0 N/A N/A 2528 G /usr/lib/xorg/Xorg 105MiB |
18| 0 N/A N/A 2675 G /usr/bin/gnome-shell 17MiB |
19| 0 N/A N/A 60336 C ...unners/cuda_v12/ollama_llama_server 0MiB |
20+-----------------------------------------------------------------------------------------+如果问问题的话,比如还是老问题: USA 5 biggest cities and population?
看到的 nvidia-smi 的使用情况是有所波动的
1|-----------------------------------------+------------------------+----------------------+
2| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
3| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
4| | | MIG M. |
5|=========================================+========================+======================|
6| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 Off | Off |
7| 30% 45C P2 116W / 450W | 11618MiB / 24564MiB | 88% Default |
8| | | N/A |
9+-----------------------------------------+------------------------+----------------------+说明 GPU 在进行推理操作,即使是输入
hello 打个招呼,GPU 也会介入。感觉 Ollama 在当前机器总是用 GPU 进行推理,尚未找到什么办法让推理只跑在 CPU 上。ollama ps 列出已加载的模型
1~$ ollama ps
2NAME ID SIZE PROCESSOR UNTIL
3llama3.2-vision:11b 38107a0cd119 12 GB 100% GPU 4 minutes from now
4llama3.2:1b baf6a787fdff 2.7 GB 100% GPU About a minute from now 1~$ ps -ef|grep ollama
2ollama 134689 1 8 20:23 ? 00:00:00 /usr/local/bin/ollama serve
3yanbin 134708 3504 0 20:23 pts/0 00:00:00 ollama run llama3.2-vision:11b
4ollama 134724 134689 24 20:23 ? 00:00:01 /tmp/ollama1091200518/runners/cuda_v12/ollama_llama_server --model /usr/share/ollama/.ollama/models/blobs/sha256-11f274007f093fefeec994a5dbbb33d0733a4feb87f7ab66dcd7c1069fef0068 --ctx-size 2048 --batch-size 512 --n-gpu-layers 41 --mmproj /usr/share/ollama/.ollama/models/blobs/sha256-ece5e659647a20a5c28ab9eea1c12a1ad430bc0f2a27021d00ad103b3bf5206f --threads 8 --parallel 1 --port 41441
5yanbin 134737 57526 0 20:23 pts/1 00:00:00 grep --color=auto ollama
6~$ netstat -na|grep 11434
7tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN
8tcp 0 0 127.0.0.1:38138 127.0.0.1:11434 ESTABLISHED
9tcp 0 0 127.0.0.1:11434 127.0.0.1:38138 ESTABLISHED
10tcp 0 0 127.0.0.1:11434 127.0.0.1:53004 TIME_WAIT
11~$ lsof -i |grep 11434
12ollama 134708 yanbin 3u IPv4 373912 0t0 TCP localhost:38138->localhost:11434 (ESTABLISHED)看到的是 ollama run, 其实在后台还是启动了 ollama serve, 然而真正加载模型的进程是 ollama_llama_server, 用
top -p 134724 看到它占用了 19.4G 的内存。ollama_llama_server 进程是能自动关闭与起动的,当前端有一段时间没有输入问题进行对话, 则 ollama_llama_server 会自动关闭,有对话进来又自动开启。当输入
ollama run <model> 观察后端的进程及端口 1~$ ps -ef|grep ollama
2ollama 135202 1 0 20:49 ? 00:00:00 /usr/local/bin/ollama serve
3yanbin 135222 3504 0 20:49 pts/0 00:00:00 ollama run llama3.2-vision:11b
4ollama 135238 135202 0 20:49 ? 00:00:01 /tmp/ollama2514331115/runners/cuda_v12/ollama_llama_server --model /usr/share/ollama/.ollama/models/blobs/sha256-11f274007f093fefeec994a5dbbb33d0733a4feb87f7ab66dcd7c1069fef0068 --ctx-size 2048 --batch-size 512 --n-gpu-layers 41 --mmproj /usr/share/ollama/.ollama/models/blobs/sha256-ece5e659647a20a5c28ab9eea1c12a1ad430bc0f2a27021d00ad103b3bf5206f --threads 8 --parallel 1 --port 42233
5yanbin 135292 57526 0 20:52 pts/1 00:00:00 grep --color=auto ollama
6~$ sudo netstat -tulnp | grep 135202
7tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN 135202/ollama
8~$ sudo netstat -tulnp | grep 135222
9~$ sudo netstat -tulnp | grep 135238
10tcp 0 0 127.0.0.1:42233 0.0.0.0:* LISTEN 135238/ollama_llama
11~$ netstat -na|grep 11434
12tcp 0 0 127.0.0.1:11434 0.0.0.0:* LISTEN
13tcp 0 0 127.0.0.1:39366 127.0.0.1:11434 ESTABLISHED
14tcp 0 0 127.0.0.1:11434 127.0.0.1:39366 ESTABLISHED
15~$ sudo lsof -i :39366
16COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
17ollama 135202 ollama 7u IPv4 378306 0t0 TCP localhost:11434->localhost:39366 (ESTABLISHED)
18ollama 135222 yanbin 3u IPv4 370135 0t0 TCP localhost:39366->localhost:11434 (ESTABLISHED)
19~$ netstat -na|grep 42233
20tcp 0 0 127.0.0.1:42233 0.0.0.0:* LISTEN
21tcp 0 0 127.0.0.1:39180 127.0.0.1:42233 ESTABLISHED
22tcp 0 0 127.0.0.1:42233 127.0.0.1:39180 ESTABLISHED
23~$ sudo lsof -i :39180
24COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
25ollama 135202 ollama 21u IPv4 379970 0t0 TCP localhost:39180->localhost:42233 (ESTABLISHED)
26ollama_ll 135238 ollama 4u IPv4 357340 0t0 TCP localhost:42233->localhost:39180 (ESTABLISHED)三个进程的关系是:
ollama run -> ollama serve(监听端口 11434) -> ollama_llama_server(监听端口 42233)这时,可能你猜想的没错,这里的 ollama_llama_server 就是 llama.cpp 的 llama-server, 只是它由 Ollama 动态管理的,比如在 启动多个 ollama run 或在 Open WebUI 使用多个模型,每个模型会对应一个 ollama_llama_server 进程,某个模型长时间没使用时就会关掉相应的进程。而这里的
ollama serve 正是下一节要介绍的,默认端口为 114343, 并且不能从远程连接,并且应该留意启动 ollama_llama_server 所使用的参数: --ctx-size 2048 --batch-size 512 --n-gpu-layers 41 --threads 8 --parallel 1 --port 42233ollama run 只是作为 ollama serve 的一个客户端, 可以通过环境变量让 ollama run 连接指定的 ollama_serve 服务,如
OLLAMA_HOST=127.0.0.1:4000 ollama run llama3.2-vision:11b
使用 ollama serve 服务
有了前面的基础到这里就好理解了,ollama serve 将会使用到前面三个进程中的后两个:ollama serve(监听端口 11434) -> ollama_llama_server(监听端口 42233)继续在 ollama 相关的进程观察会发现 ollama serve 是由 systemd 控制的,所以任由你如何
sudo kill -9 <ollama serve 的进程 id> 都会重启新的 ollama serve。1yanbin@Ubuntu-Desktop:~$ ps -ef|grep ollama
2ollama 135961 1 0 21:31 ? 00:00:00 /usr/local/bin/ollama serve
3yanbin 135989 3504 0 21:33 pts/0 00:00:00 grep --color=auto ollama
4yanbin@Ubuntu-Desktop:~$ ps -o ppid= -p 135961
5 1
6yanbin@Ubuntu-Desktop:~$ pstree -sp 135961
7systemd(1)───ollama(135961)─┬─{ollama}(135962)
8 ├─{ollama}(135963)要关掉 systemd 启动的 ollama-serve 必需用 sudo systemctl stop ollama 命令
ollama --help 是最友好的助手,我可以看到它可用的命令有 1Available Commands:
2 serve Start ollama
3 create Create a model from a Modelfile
4 show Show information for a model
5 run Run a model
6 stop Stop a running model
7 pull Pull a model from a registry
8 push Push a model to a registry
9 list List models
10 ps List running models
11 cp Copy a model
12 rm Remove a model
13 help Help about any command特定命令的帮助也是用 --help, 如
ollama serve --help, 可查看到环境变量对该命令的影响 1~$ ollama serve --help
2Start ollama
3
4Usage:
5 ollama serve [flags]
6
7Aliases:
8 serve, start
9
10Flags:
11 -h, --help help for serve
12
13Environment Variables:
14 OLLAMA_DEBUG Show additional debug information (e.g. OLLAMA_DEBUG=1)
15 OLLAMA_HOST IP Address for the ollama server (default 127.0.0.1:11434)
16 OLLAMA_KEEP_ALIVE The duration that models stay loaded in memory (default "5m")
17 OLLAMA_MAX_LOADED_MODELS Maximum number of loaded models per GPU
18 OLLAMA_MAX_QUEUE Maximum number of queued requests
19 OLLAMA_MODELS The path to the models directory
20 OLLAMA_NUM_PARALLEL Maximum number of parallel requests
21 OLLAMA_NOPRUNE Do not prune model blobs on startup
22 OLLAMA_ORIGINS A comma separated list of allowed origins
23 OLLAMA_SCHED_SPREAD Always schedule model across all GPUs
24 OLLAMA_TMPDIR Location for temporary files
25 OLLAMA_FLASH_ATTENTION Enabled flash attention
26 OLLAMA_LLM_LIBRARY Set LLM library to bypass autodetection
27 OLLAMA_GPU_OVERHEAD Reserve a portion of VRAM per GPU (bytes)
28 OLLAMA_LOAD_TIMEOUT How long to allow model loads to stall before giving up (default "5m")那么如果我们在启动
ollama serve, 但不想启动在 127.0.0.1:11434(无法通过远程访问), 并且允许并发访问,命令为OLLAMA_HOST=0.0.0.0:4000 OLLAMA_NUM_PARALLEL=5 ollama serve假如没用 sudo systemctl stop ollama 服务,就会看到两个 ollama serve
1~$ ps -ef|grep ollama
2ollama 136061 1 0 21:37 ? 00:00:00 /usr/local/bin/ollama serve
3yanbin 136090 3504 0 21:37 pts/0 00:00:01 ollama serve
4yanbin 136117 136090 5 21:38 pts/0 00:00:05 /tmp/ollama1442856846/runners/cuda_v12/ollama_llama_server --model /home/yanbin/.ollama/models/blobs/sha256-11f274007f093fefeec994a5dbbb33d0733a4feb87f7ab66dcd7c1069fef0068 --ctx-size 2048 --batch-size 512 --n-gpu-layers 41 --mmproj /home/yanbin/.ollama/models/blobs/sha256-ece5e659647a20a5c28ab9eea1c12a1ad430bc0f2a27021d00ad103b3bf5206f --threads 8 --parallel 1 --port 41811
5yanbin 136164 57526 0 21:39 pts/1 00:00:00 ollama run llama3.2-vision:11b
6ollama 136178 136061 10 21:39 ? 00:00:01 /tmp/ollama4120339016/runners/cuda_v12/ollama_llama_server --model /usr/share/ollama/.ollama/models/blobs/sha256-11f274007f093fefeec994a5dbbb33d0733a4feb87f7ab66dcd7c1069fef0068 --ctx-size 2048 --batch-size 512 --n-gpu-layers 41 --mmproj /usr/share/ollama/.ollama/models/blobs/sha256-ece5e659647a20a5c28ab9eea1c12a1ad430bc0f2a27021d00ad103b3bf5206f --threads 8 --parallel 1 --port 36067每个 ollama serve 会管理自己的 ollama_llama_server, 一个模型会有一个对应的 ollama_llama_server 服务。
当然通过 export 命令来导出环境变量也行。Ollama REST API Document 罗列了 Ollama API, Ollama 没有提供与 OpenAI API 相兼容的 completion APIs,下面主要尝试一下 /api/generate, 其他的就不详细展开了。
- POST /api/generate: 这是一个 Streaming API, 可看看它的效果这是一个个返回的 chunked 的数据块,这就是为什么会在聊天客户端看到一个一个字(token)蹦出来的效果,对 "hello" 的回答是 "How are you today? Is there something I can help you with or would you like to chat?
1curl -i 'http://192.168.86.42:4000/api/generate' --data '{ 2 "model":"llama3.2-vision:11b", 3 "prompt":"hello" 4}' 5HTTP/1.1 200 OK 6Content-Type: application/x-ndjson 7Date: Mon, 11 Nov 2024 23:25:27 GMT 8Transfer-Encoding: chunked 9 10{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.813890703Z","response":"Hello","done":false} 11{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.821435957Z","response":"!","done":false} 12{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.829057575Z","response":" How","done":false} 13{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.836642192Z","response":" are","done":false} 14{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.844231003Z","response":" you","done":false} 15{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.851870564Z","response":" today","done":false} 16{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.859237425Z","response":"?","done":false} 17{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.866840884Z","response":" Is","done":false} 18{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.874330135Z","response":" there","done":false} 19{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.881819128Z","response":" something","done":false} 20{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.889275621Z","response":" I","done":false} 21{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.89691295Z","response":" can","done":false} 22{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.904473679Z","response":" help","done":false} 23{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.911987127Z","response":" you","done":false} 24{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.919554847Z","response":" with","done":false} 25{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.927100238Z","response":" or","done":false} 26{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.934637459Z","response":" would","done":false} 27{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.942216118Z","response":" you","done":false} 28{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.949833649Z","response":" like","done":false} 29{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.957408267Z","response":" to","done":false} 30{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.964957677Z","response":" chat","done":false} 31{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.972552891Z","response":"?","done":false} 32{"model":"llama3.2-vision:11b","created_at":"2024-11-11T23:25:27.981265318Z","response":"","done":true,"done_reason":"stop","context":[128006,882,128007,271,15339,128009,128006,78191,128007,271,9906,0,2650,527,499,3432,30,2209,1070,2555,358,649,1520,499,449,477,1053,499,1093,311,6369,30],"total_duration":194396814,"load_duration":16540876,"prompt_eval_count":11,"prompt_eval_duration":2000000,"eval_count":23,"eval_duration":174000000} - POST /api/chat
- POST /api/create
- GET /api/tags
- POST /api/show
- GET /api/copy
- DELETE /api/delete
- POST /api/pull
- POST /api/push
- POST /api/embeddings
注意:如果你执行过
ollama run <model>, 然后结束进程,再次执行 ollama serve 时就极有可能碰到端口被占用的错误,如Error: listen tcp 127.0.0.1:11434: bind: address already in use after running ollama serve因为停止
ollama run <model> 进程时并未停掉后台对应的 ollama serve 进程,可用 lsof -i |grep 11434 找到相应的进程 ID, kill 掉再执行 ollama serve 就行Ollama 与 Open WebUI 的配合
我们在上一篇中使用过 Open WebUI 连接 llama-server, 由于 llama-server 提供了 OpenAI 相兼容的 APIs, 所以能协同工作。而 Open WebUI 本身就完美的支持 Ollama,还能通过 Open WebUI 来从 Ollama 下载所需的模型。这一回我们不用pip install open-webui 的方式使用 Open WebUI, 而是用 Docker假说 ollama serve 运行在 http://192.168.86.42:4000, 则启动 Open WebUI 容器的命令用
docker run -p 3000:8080 -e OLLAMA_BASE_URL=http://192.168.86.42:4000 ghcr.io/open-webui/open-webui:main
1$ docker run -p 3000:8080 -e OLLAMA_BASE_URL=http://192.168.86.42:4000 ghcr.io/open-webui/open-webui:main
2Loading WEBUI_SECRET_KEY from file, not provided as an environment variable.
3Generating WEBUI_SECRET_KEY
4Loading WEBUI_SECRET_KEY from .webui_secret_key
5/app/backend/open_webui
6/app/backend
7/app
8Running migrations
9INFO [alembic.runtime.migration] Context impl SQLiteImpl.
10INFO [alembic.runtime.migration] Will assume non-transactional DDL.
11INFO [alembic.runtime.migration] Running upgrade -> 7e5b5dc7342b, init
12INFO [alembic.runtime.migration] Running upgrade 7e5b5dc7342b -> ca81bd47c050, Add config table
13INFO [alembic.runtime.migration] Running upgrade ca81bd47c050 -> c0fbf31ca0db, Update file table
14INFO [alembic.runtime.migration] Running upgrade c0fbf31ca0db -> 6a39f3d8e55c, Add knowledge table
15INFO [alembic.runtime.migration] Running upgrade 6a39f3d8e55c -> 242a2047eae0, Update chat table
16INFO [alembic.runtime.migration] Running upgrade 242a2047eae0 -> 1af9b942657b, Migrate tags
17INFO [alembic.runtime.migration] Running upgrade 1af9b942657b -> 3ab32c4b8f59, Update tags
18INFO [alembic.runtime.migration] Running upgrade 3ab32c4b8f59 -> c69f45358db4, Add folder table
19INFO [alembic.runtime.migration] Running upgrade c69f45358db4 -> c29facfe716b, Update file table path
20INFO [alembic.runtime.migration] Running upgrade c29facfe716b -> af906e964978, Add feedback table
21INFO [alembic.runtime.migration] Running upgrade af906e964978 -> 4ace53fd72c8, Update folder table and change DateTime to BigInteger for timestamp fields
22INFO [open_webui.env] 'DEFAULT_LOCALE' loaded from the latest database entry
23INFO [open_webui.env] 'DEFAULT_PROMPT_SUGGESTIONS' loaded from the latest database entry
24WARNI [open_webui.env]
25
26WARNING: CORS_ALLOW_ORIGIN IS SET TO '*' - NOT RECOMMENDED FOR PRODUCTION DEPLOYMENTS.<br/><br/>
27INFO [open_webui.env] Embedding model set: sentence-transformers/all-MiniLM-L6-v2
28INFO [open_webui.apps.audio.main] whisper_device_type: cpu
29WARNI [langchain_community.utils.user_agent] USER_AGENT environment variable not set, consider setting it to identify your requests.
30INFO: Started server process [1]
31INFO: Waiting for application startup.
32INFO: Application startup complete.
33INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
34INFO [open_webui.apps.openai.main] get_all_models()
35INFO [open_webui.apps.ollama.main] get_all_models()
36Creating knowledge table
37Migrating data from document table to knowledge table
38Converting 'chat' column to JSON
39Renaming 'chat' column to 'old_chat'
40Adding new 'chat' column of type JSON
41Dropping 'old_chat' column
42Primary Key: {'name': None, 'constrained_columns': []}
43Unique Constraints: [{'name': 'uq_id_user_id', 'column_names': ['id', 'user_id']}]
44Indexes: [{'name': 'tag_id', 'column_names': ['id'], 'unique': 1, 'dialect_options': {}}]
45Creating new primary key with 'id' and 'user_id'.
46Dropping unique constraint: uq_id_user_id
47Dropping unique index: tag_id
48
49 ___ __ __ _ _ _ ___
50 / _ \ _ __ ___ _ __ \ \ / /__| |__ | | | |_ _|
51| | | | '_ \ / _ \ '_ \ \ \ /\ / / _ \ '_ \| | | || |
52| |_| | |_) | __/ | | | \ V V / __/ |_) | |_| || |
53 \___/| .__/ \___|_| |_| \_/\_/ \___|_.__/ \___/|___|
54 |_|
55
56
57v0.3.35 - building the best open-source AI user interface.<br/><br/>
58https://github.com/open-webui/open-webui现在就可以打开浏览器,输入地址 http://192.168.86.61:3000,进行用户注册,完后登陆
在 Admin Setting/Connections 就看到 Ollama API 是 http://192.168.86.42:4000, 在 Models 中的 Pull a model from Ollama.com 输入框中输入 "llama3.2-vision:latest", 点击下载按钮就会从 Ollama.com pull 指定的模型
 再回到用户 Settings/Interface 中就能选择 llama3.2-vision:latest 为 Default Model, 或者在 New Chat 时选择想要的模型
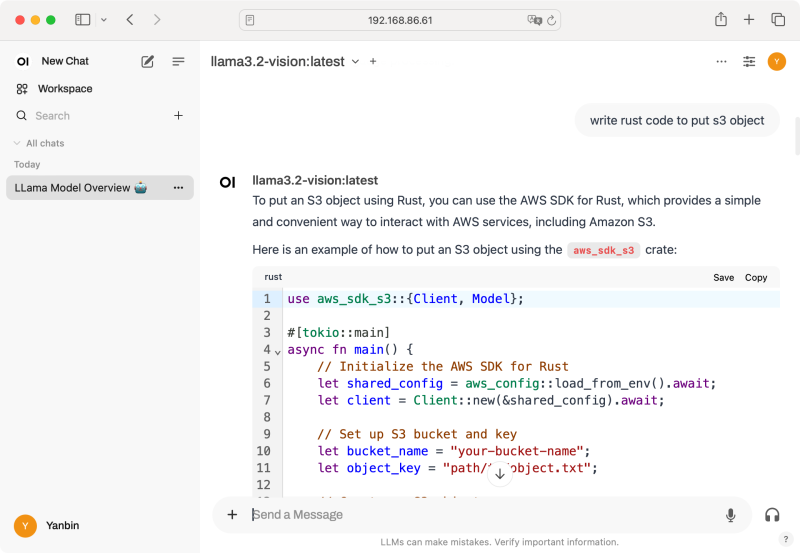
再回到用户 Settings/Interface 中就能选择 llama3.2-vision:latest 为 Default Model, 或者在 New Chat 时选择想要的模型 开始聊天, 在
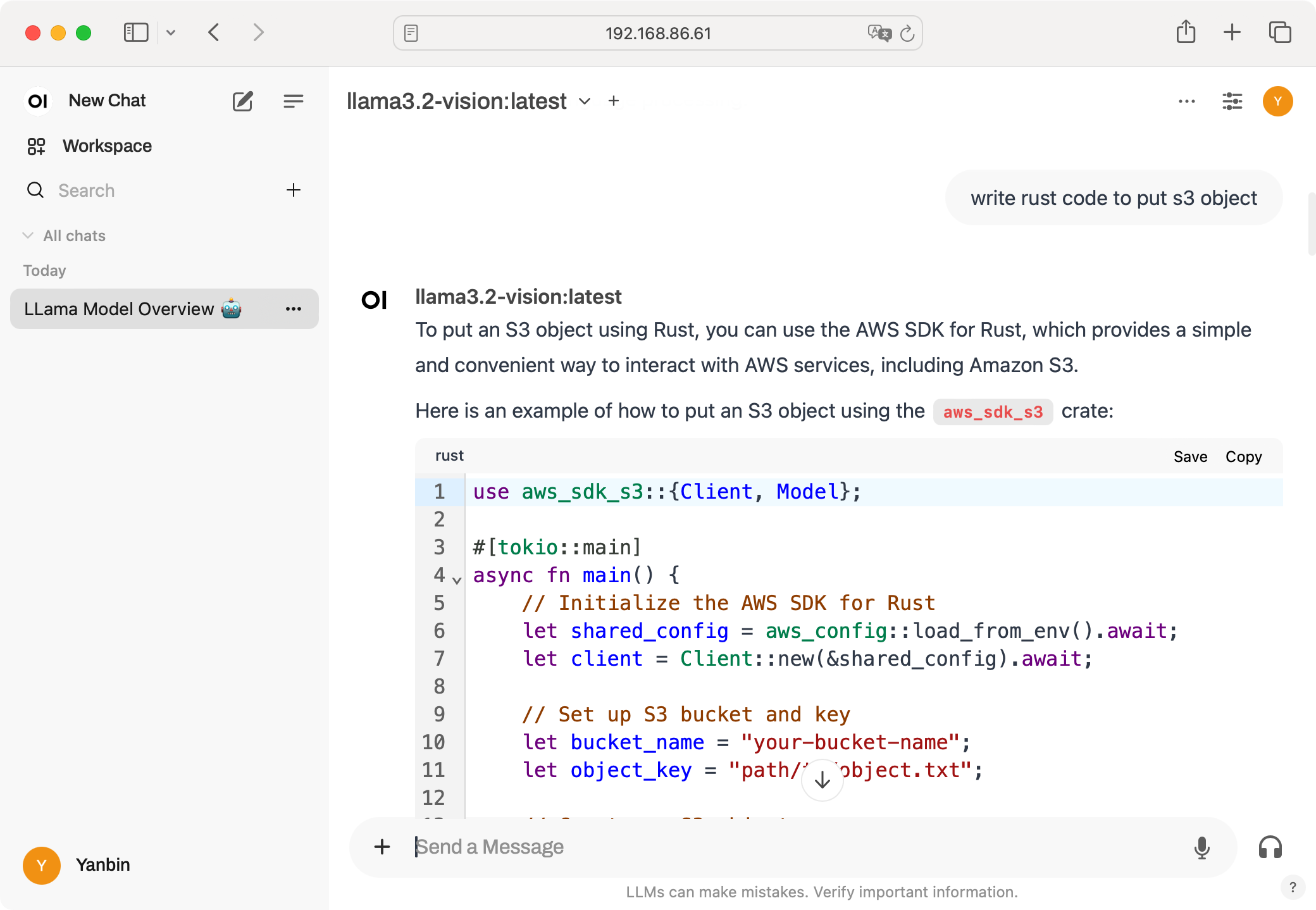
开始聊天, 在 How can I help you today? 框中输入自己的问题即可。还能语音文字互转。我们输入write rust code to put s3 object
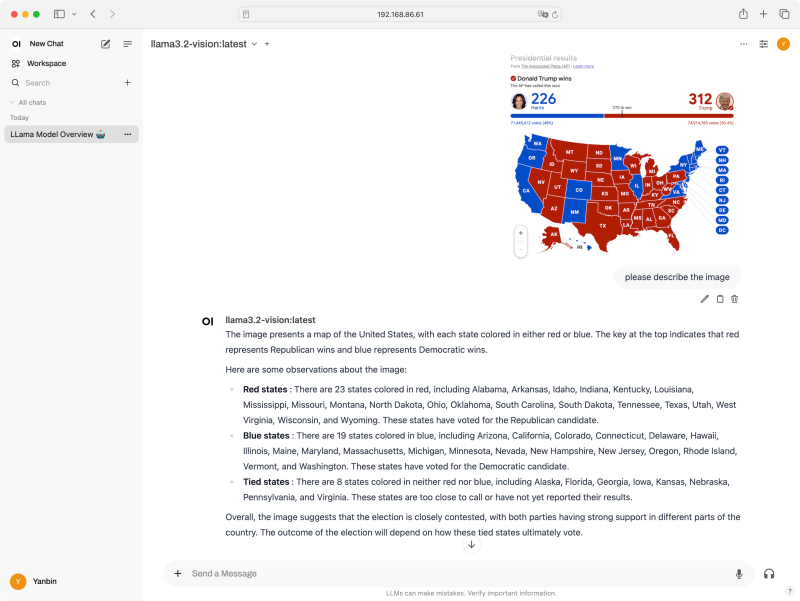
 正可谓 -vision, 那不妨看看它对图片理解能力吧,来一张现下关于美国大选的图片
正可谓 -vision, 那不妨看看它对图片理解能力吧,来一张现下关于美国大选的图片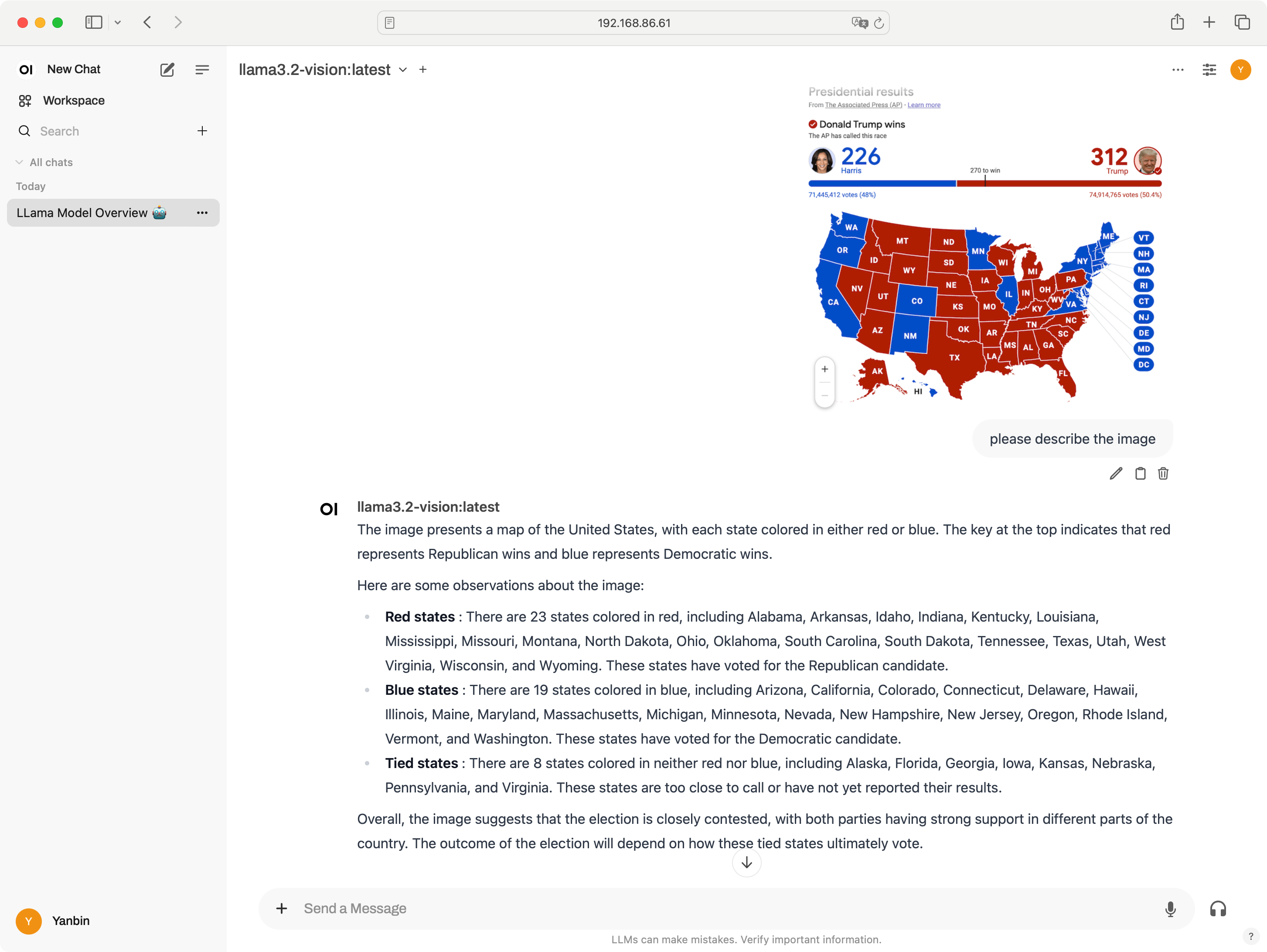 llama3.2-vision 这个模型还是理解到了是美国大选的事,并且有红州,蓝州,不过毕竟它是出自 Meta 公司,偏向蓝方就不奇怪了。
llama3.2-vision 这个模型还是理解到了是美国大选的事,并且有红州,蓝州,不过毕竟它是出自 Meta 公司,偏向蓝方就不奇怪了。总结
主要还是要加强理解 Ollama 的服务架构,由此懂得 Ollama 如何同时使用多个模型,怎么节约资源。ollama run 或者 http client(如 Open WebUI) 都是 ollama serve 的客户端,ollama serve 根据客户端指定的模型动态管理 ollama_llama_server 进程,同一个 ollama serve 管理之下,每个模型会对应一个 ollama_llama_server 进程,某一模型长时间空闲就会被 ollama serve 停掉,需要时再启动。
这张图应该能说明白 client -> ollama-serve -> ollama_llama_server 之间的关系。客户端可以指定用哪个 ollama-serve, 安装完 ollama 后系统会启动一个在 11434 端口号上监听的 ollama-serve 服务,并且它只能被本地连接,除非修改配置参数才能让系统启动的 ollama-serve 被远程连接。命令 ollama run 默认连接本地的 11434 端口号上的 ollama-serve 服务,可通过环境变量 OLLAMA_HOST 指定 ollama run 连接哪个 ollama-serve 服务。修改 systemd 管理的 ollama-serve 参数的方法是
sudo vi /etc/systemd/system/ollama.service在 [Service] 下加上
Environment="OLLAMA_HOST=0.0.0.0"[Service] 下可有多个 Environment, 然后
sudo systemctl daemon-reload这时启动的 ollama-serve 监听在 :::11434, 能从远程访问
sudo systemctl restart ollama
除 Open WebUI 客户端还有许多,见 Ollama 客户端列表 Web & Desktop 和 Terminal.
链接:
永久链接 https://yanbin.blog/ollama-simple-use-local-llm-model/, 来自 隔叶黄莺 Yanbin's Blog
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。