
突然间研究这个来的缘由是正在从 Jenkins 往 Harness 的过度, 而完全用命令来构建 Docker 镜像变得不一样了。在 Jenkins 中 Agent 本身也是一个 Docker Daemon, 所以 Docker 命令执行无障碍,而 Harness 的所谓的 Agent 就是一个个的运行在 Kubernetes 中的 Docker Container (Pod) 了,这其中没有 Docker Daemon, 又不能连接到 Kubernetes 本身的 Docker Daemon。另外 CloudBees CI/CD 的运行环境与 Harness 类似,也是运行在 Kubernetes 中的 Pod。
因此可能要使用某个 Docker 容器来作为 Docker Daemon, 所以牵连出对此的研究,相应的方案有 Docker in Docker(DinD) 和 Docker outside of Docker(DooD)。
对容器中启动 Docker Daemon 的探索
在知晓 DinD 和 DooD 这两个概念本人还试图构建过一个 Docker 镜像,试图用一个 Docker 容器既作 Docker Daemon 又作为 Docker 客户端。在容器中 Docker 安装成功,但无法在容器中启动 Docker Daemon。比如用下面的 Dockerfile Read More
 Java 项目需要产生单元测试及代码覆盖率的话一直都是走的 JUnit 单元测试,JaCoCo 基于测试产生测试覆盖率,然后送到 SonarQube 去展示这条路子。当然 SonarQube 还可以帮我们进行代码的静态分析。但对其中的具体使用及过程知晓的并不深,基本就是在 pom.xml 中依葫芦画瓢。本文稍加深入的理解每一步的功效与配置,以 Maven 管理的 Java 项目为例,JUnit 采用是众多旧项目仍然无法摆脱的 JUnit 4。
Java 项目需要产生单元测试及代码覆盖率的话一直都是走的 JUnit 单元测试,JaCoCo 基于测试产生测试覆盖率,然后送到 SonarQube 去展示这条路子。当然 SonarQube 还可以帮我们进行代码的静态分析。但对其中的具体使用及过程知晓的并不深,基本就是在 pom.xml 中依葫芦画瓢。本文稍加深入的理解每一步的功效与配置,以 Maven 管理的 Java 项目为例,JUnit 采用是众多旧项目仍然无法摆脱的 JUnit 4。
示例项目名称为 JaCoCoSonar, 创建一个 Calc 类,其中有 int add(int op1, int op2) 方法,为其写一个单元测试 CalcTest1public class CalcTest { 2 3 @Test 4 public void testAdd() { 5 Assert.assertEquals(3, Calc.add(1, 2)); 6 } 7}单元测试实际是被 maven-surefire-plugin 插件执行的
现在开始第一步,执行mvn test看会发生什么,执行过程中控制台显示 Read More 继续阅读本书,编程语言处理数值都有可能出现问题,如溢出,整数的最大最小值不对称,Double.NaN 等。
继续阅读本书,编程语言处理数值都有可能出现问题,如溢出,整数的最大最小值不对称,Double.NaN 等。
由于 Java 学了 C,也用 0 开始的数字来表示 8 进制数,如 037, 010 分别是十进制的 31 和 8,这与现实不相符。因为如果你在纸上写下 037, 010, 几乎所有人(除了某些程序员)都会认为它们就是十进制的 37 和 10。但是 Java 表示 2 进制, 16 进制的方式没有问题的,如 0b10, 0x37。IntelliJ IDEA 看到使用 0 开头的 8 进制数会不建议那么使用. 8 进制数字的范围是 0~8, 所以 09 是错误的, 但是 Java 编译器似乎对此很陌生.
int a = 09;
IntelliJ IDEA 会提示Integer number too large, 编译器提示说java: ';' expected, 有点驴唇不对马嘴.
现在几乎没有必要使用 0 开始的 8 进制数的方式, 或许还有用的就是表示 Unix 下文件权限, 如
int fileMode = 0644
所以任何时候看到 0 开头的数字都必须仔细检视, 基本可以禁止使用这种方式 Read More- 这几日在阅读 Manning 出版社的 《100 Java Mistakes and How to Avoid Them》, 其中列举的确实是一些容易带入到代码中的错误,不少还是通过代码 Review 或单元测试很难发现的问题。也有些看似很弱智,却可能是隐匿许久的定时炸弹,只等某一特定条件出现时即爆。
阅读的同时简单的作了笔记及少许联想,所以内容有些杂乱无条理。最前面介绍了一些静态代码分析工具,也有两个动态分析工具。本书目前还是 Manning 的 MEAP 体验版,未正式发售。一共讲了 100 个常见错误如何避免(例如,怎么用最新 Java(Java 9 -- Java 21) 语法, API 来改进),以及用静态分析工具,单元测试及早发现。
这是读完了 1/4 数量的记录,笔记开始 Read More  由于是第一篇写关于 Lombok 的日志,所以有些不情愿去开门见山直接触及 @With, 而要先提一提本人对 Lombok 的接触过程。
由于是第一篇写关于 Lombok 的日志,所以有些不情愿去开门见山直接触及 @With, 而要先提一提本人对 Lombok 的接触过程。
两三年之前写 Java 代码一直都是全手工打造。一个数据类,所有必须的 setter/getter, toString, hashcode() 等全体现在源代码中,当然是在 IDE 中自动生成的。听说过 Lombok,但觉得它用了会影响到对源代码的阅读,因为造成代码的行为与源代码所展示的不一致,还可能依赖于特定的 IDE 或构建工具插件,所以一直未真正应用。
然而现代语言一直在避免不断书写象 JavaBean 里那一大片样本代码,同时解决试图提高覆盖率写出毫无意义单元测试的烦恼。比如 Scala 发展出了 case class, Kotlin 的 data class, Python 的 @dataclass,还有 JDK 14 引入的及至 JDK 16 转正的 record, 都是为了自动生成 Java 类的 setter/getter/toSring/hashcode/equals 等方法。 所以源代码中看不到实际可调用方法不该再是问题,况且在 JDK 5 加入的 enum 类型本质上也是在源代码的背后生成了一系列的方法和类型声明的。 Read More
刚刚回顾了一下 JDBC 操作 SQL Server 时如何传入列表参数,即如何给 in (?) 条件直接传入一个列表参数,然而本质上是不支持,最终不得不展开为 in (?, ?,...?) 针对每个元素单独设置参数,不定长的参数对于重用已编译 PreparedStatement 语句的帮助不大。
那么 JDBC 操作 PostgreSQL 是何种状态呢?展开为多个参数当然是有效的。继续尝试 Spring 提供的 NamedParameterJdbcTemplate 的操作方式
String query = "select * from users where id in (:ids)";
Map<String, Object> parameters = new HashMap<>();
parameters.put("ids", IntStream.rangeClosed(1, 5).boxed().collect(toList()));
List<Map<String, Object>> maps = namedParameterJdbcTemplate.queryForList(query, parameters);执行后查看到实际执行的语句是
select * from users where id in (?, ?, ?, ?, ?)
Read More
本文是作为将要对 PostgreSQL 的 in, any() 操作的一个铺垫,也是对先前用 JDBC 操作 SQL Server 的温习。以此记录一下用 JDBC 查询 SQL Server 时如何传递一个列表参数。比如想像一下查询语句
select * from users where id in (?)
我们是否能给这里的问题参数传递一个 List 或数组呢?
这里所引用的 SQL Server 的 JDBC 驱动是 com.microsoft.sqlserver:mssql-jdbc:11.2.0.jre8
我们尝试调用 PreparedStatement.setArray() 方法来设置这个参数pstmt.setArray(1, conn.createArrayOf("int", new Integer[]{1,2,3}));
这里会受到两个阻碍,首先
SQL Server 的 PreparedStatement 的实现类 SQLServerPreparedStatement 的 setArray() 未实现,反编译出它的 setArray() 方法是 Read More 分布式计算有这么一个需求,主进程准备好输入数据,然后根据输入中某个 Items 动态调用若干计算进程,待到所有计算完成后再汇集结果。这一需求移植到 AWS 上就像是下面这样子
分布式计算有这么一个需求,主进程准备好输入数据,然后根据输入中某个 Items 动态调用若干计算进程,待到所有计算完成后再汇集结果。这一需求移植到 AWS 上就像是下面这样子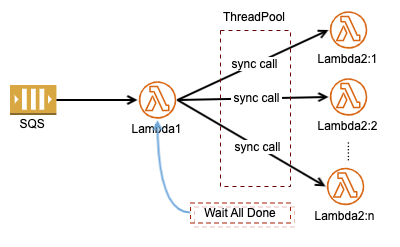 但在一个 Lambda 中同步调用其他 Lambda 时就有个费时费钱的问题,虽然我们采用线程池来调用 Lambda2, 由于每个同步调用的耗时不相同, Lambda1 最终要等待最慢的那个调用结束后才能对所有结果进行聚集处理。这就是著名的“长板效应”, Lambda1 多数时候是在无谓的等待当中消耗着你的钱财。
Read More
但在一个 Lambda 中同步调用其他 Lambda 时就有个费时费钱的问题,虽然我们采用线程池来调用 Lambda2, 由于每个同步调用的耗时不相同, Lambda1 最终要等待最慢的那个调用结束后才能对所有结果进行聚集处理。这就是著名的“长板效应”, Lambda1 多数时候是在无谓的等待当中消耗着你的钱财。
Read More- 无论在何处,有多重任务要处理时,并发编程总是要得到考虑的。比如有 IO 等待时的并发或 CPU 密集型时的并行计算,并发通常是指在同一个 CPU 上按时间片轮换执行,并行是任务在不同的 CPU 上执行。能有效使用 CPU 多核的语言可以让线程运行在不同的核上实现并行,如果是启动的子进程能由操作系统运行在其他 CPU 核上。
回到 AWS Lambda 中的 Python 代码,如果是处理 IO 等待,使用多线程并发就行,大致的代码如下:with ThreadPoolExecutor(10) as executor:
以上代码在 AWS Lambda 中是可以运行的。
result = executor.map(task_function, task_inputs)
如果是 CPU 密集型的任务,用 Python 的多线程就要歇菜了,因为存在著名的 Python's GIL 的约束。 这时候就必须要考虑多进程并行的方式,同时应知晓当前选择的 Lambda 运行环境有多少个 CPU 内核,因为如果是单核的话再多进程也无济于事,没必要启动多于核心数的进程。 底下是本人上篇博客测试收集的不同 AWS Lambda 内存选择对应的 CPU 核心数,以及实际可用内存大小的关系表 Read More - 目前(2023-05-25) AWS Lambda 的内存选择区间是 128MB ~ 10240MB, 最长运行时间为 15 分钟,但没有 vCPU 个数的选择。vCPU 的数量是基于所选内存大小而有不同的,如果我们在 Lambda 中需使用多进程充分发挥 CPU 性能的话,有必要了解当前 Lambda 所在运行环境的 CPU 内核数,甚至是单核的频率。
CPU 个数可用如下 Python 内置的其中一个方法取得multiprocessing.cpu_count()
要获得 CPU 频率或内存的话,将要用到
os.cpu_count()psutil组件的方法,可把 psutil 做成 Lambda 层以引用,或与 Lambda 函数代码一同打成 zip 包。
安装方法psutilpip install --target . psutil
psutil 会安装到当前目录,然后在当前目录下再创建 lambda_function.py 文件,再打包 Read More