 当我们在使用 Java 8 的 Lambda 表达式时,表达式内容需要抛出异常,也许还会想当然的让当前方法再往外抛来解决编译问题,如下面的代码
当我们在使用 Java 8 的 Lambda 表达式时,表达式内容需要抛出异常,也许还会想当然的让当前方法再往外抛来解决编译问题,如下面的代码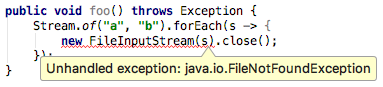 让
让 main()方法抛出Exception还是不解决决编译错误,仍然提示 "Unhandled exception: java.io.FileNotFoundException"。
因为我们可能保持着惯性思维,忽略了 Lambda 本身就是一个功能性接口方法的实现,所以把上面的代码还原为匿名类的方式1public void foo() { 2 Stream.of("a", "b").forEach(new Consumer<String>() { 3 @Override 4 public void accept(String s) { 5 new FileInputStream(s).close(); 6 } 7});
那么对于上面那种情况应该如何处理呢? Read More- 在 Java 中对于下面最简单的泛型类
class A<T> {
设想我们使用时
public void foo() {
//如何在此处获得运行时 T 的具体类型呢?
}
}new A<String>().foo();
是否能在foo()方法中获得当前的类型是 String 呢?答案是否定的,不能。在foo()方法中 this 引用给不出类型信息,this.getClass()就更不可能了,因为 Java 的泛型不等同于 C++ 的模板类,this.getClass()实例例是被所有的不同具体类型的 A 实例(new A<String>(), new A<Integer>() 等) 共享的,所以在字节码中类型会被擦除到上限。
我们可以在 IDE 的调试时看到这个泛型类的签名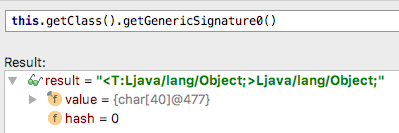 Read More
Read More 
1. Vim 的模式: 通常我们说有三种模式,正常模式(Normal Mode), 插入模式(Inert Mode) 和可视模式(Visual Mode). 其实除此之外还有
4) Operator-Pending Mode: 就是正常模式下按下操作(Operator) 指令(如 c, d 等) 后,等待输入移动(Motion) 指示时的模式。这时 Escape 或 Motion 指令后退回到正常模式
5) Insert Normal Mode: 在插入模式时,按下<Ctrl-o>组合键后进入该模式, 此时可接受一个 Action (Operator + Motion = Action), 比如3dd, 然后自动返回到插入模式。<Esc>也能从 Insert Normal Mode 返回到插入模式。这方便了插入模式只想执行一次指令操作时来回切换, Insert Normal Mode 在 Vim 的状态栏中显示为下图那样 - NORMAL --(insert) --
6) 替换模式(Replace Mode)
-- REPLACE --,R会进到替换模式,随后输入往后覆盖,可尝试<Insert>键;r{char}和gr{char}临时进入单字符的替换模式,替换完当前字符立即退到正常模式,也就是光标不往下走。
7) 可视替换模式(Visual Replace Mode)-- VREPLACE --, 用gR进入该模式,在处理tab字符时会更友好,还有别的好处吧,所以该书建议尽量用可视替换模式。
8) 可视模式(Visual Mode),这就复杂了。它有三个子模式:
character-wise Visual mode---- VISUAL;
line-wise Visual mode---- VISUAL LINE --
block-wise Visual mode---- VISUAL BLOCK --
9) 选择模式(Select Mode),可视模式下选择了内容后用<C-g>可在两种模式下切换,状态栏-- VISUAL --和-- SLECT --的不同,还有选择模式下直接输入就会替换当前的内容,与其他编辑器的行为一样,而可视模式需要按c来替换当前内容。 Read More 在上一篇中尝试了 使用 Javassist 运行时生成泛型子类,这里要用另一个更方便的字节码增加组件 Byte Buddy 来实现类似的功能, 但代码上要直白一些。就是运用 Byte Buddy 在运行时生成一个类的子类,带泛型的,给类加上一个注解,可生成类文件或 Class 实例,不过这里更进一步,实现的方法是带参数的。
在上一篇中尝试了 使用 Javassist 运行时生成泛型子类,这里要用另一个更方便的字节码增加组件 Byte Buddy 来实现类似的功能, 但代码上要直白一些。就是运用 Byte Buddy 在运行时生成一个类的子类,带泛型的,给类加上一个注解,可生成类文件或 Class 实例,不过这里更进一步,实现的方法是带参数的。
用 Byte Buddy 操作起来更简单,根本不需要接触任何字节码相关的,诸如常量池等概念。与 Javassist 相比,Byte Buddy 更为先进的是能生成的类文件都是可加载运行的,不像 Javassist 生成的类文件反编译出来是看起来是正常的,但一加载执行却不那回事。
本例所使用的 Byte Buddy 的版本是当前最新的 1.6.7,在 Maven 项目中用下面的方式引入依赖<dependency>
下面是几个需要在本例中用到的类定义 Read More
<groupId>net.bytebuddy</groupId>
<artifactId>byte-buddy</artifactId>
<version>1.6.7</version>
</dependency>Java 8 之前如何重复使用注解
在 Java 8 之前我们不能在一个类型重复使用同一个注解,例如 Spring 的注解@PropertySource不能下面那样来引入多个属性文件@PropertySource("classpath:config.properties")
上面的代码无法在 Java 7 下通过编译,错误是: Duplicate annotation
@PropertySource("file:application.properties")
public class MainApp {}
于是我们在 Java 8 之前想到了一个方案来规避 Duplicate Annotation 的错误: 即声明一个新的 Annotation 来包裹@PropertySource, 如@PropertySources1@Retention(RetentionPolicy.RUNTIME) 2public @interface PropertySources { 3 PropertySource[] value(); 4}
然后使用时两个注解齐上阵 Read More 最初接触 Mockito 还思考并尝试过如何用它来 mock 返回值为 void 的方法,然而 Google 查找到的一般都会说用
最初接触 Mockito 还思考并尝试过如何用它来 mock 返回值为 void 的方法,然而 Google 查找到的一般都会说用doThrow()的办法doThrow(new RuntimeException()).when(mockObject).methodWithVoidReturn();
因为无法使用常规的when(mockObject.foo()).thenReturn(...)的方法。
当时我就纳闷,为何我想 mock 一个返回值为 void 的方法,却是在模拟抛出一个异常,现在想来如果一个返回值为 void 的方法,为何要去 mock 这个方法呢?
回想一个我们要 mock 一个方法的意图是什么:- 在特定输入参数的情况下期待需要的输出结果(返回值)
- 在方法抛出某种类型异常调用者作出的反应
对于 void 返回值的方法,如果要验证有没有被调用过几次可以在事后用verify()方法去断言。所以基本上对于 void 返回值的方法一般可不用去 mock 它,只需用 verify() 去验证,或者就是像前面一样模拟出现异常时的情况。
所以本文并不像是去直接回答标题所示的问题: Mockito 如何 mock 返回值为 void 的方法,而是如何应对 mock 对象的 void 方法 Read More