真正有些水准的排序算法 - 快速排序
冒泡和选择排序的简单粗暴也许在某些人眼里都不能称作算法,现在要进入一种更优雅的排序算法,快速排序。它使用分而治之(Divide and Conquer, D&G) 的策略,要应用到递归调用。快速排序敢说自己快速,也确实比选择排序快很多很多。冒泡和选择排序,尤其是选择排序是非常自然的排序算法,而快速排序就不是一般人会随意想出来的。
快速排序的演绎需要用递归来思考循环的问题,然而我之前总是在及力用循环来避免递归调用,有趣的是诸如 Haskell 等函数式编译语言根本没有循环,只能用递归来编写循环的效果。来看一个简单的例子,比如要从 1 加到 100,我们很自然会用循环从 1 累加到 100,如果换成递归,看下面的代码
递归有助于我们把大问题分解为小问题,上面代码的思维是数组的和总是很一个元素加上剩下元素列表的和,直到最后元素列表为空(和为 0)。
快速排序的要理如下:
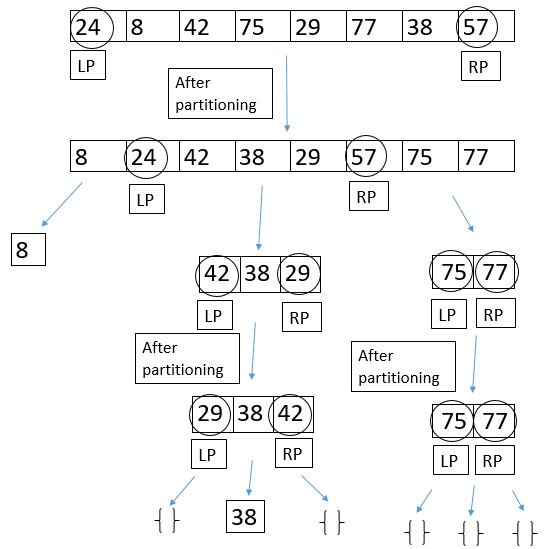
例如,对列表 [3, 5, 2, 1, 4] 总是取第首元素为基准值时的排序过程
上面的代码是取首元素为基准值; 下面有优化后的代码,取中值为基准值,专门应对顺序不够乱的列表
本来也想贴一张动图来展示快速排序的整个过程,但是觉得网上找的几个动图并不那么直观,用文本列出的排序过程也好理解。
我们对比一下快速排序与选择排序看它有多快, 上一篇中的选择排序的代码重新回顾如下:
测试它们对相同含 100000 个数字的列表
结果对比如下(排 10 万个元素):
等排序的元素越多,悬殊越大,再看排 1 万个元素的时间对比:
快速排序的时间复杂度为 O(n log n), 而选择排序的时间复杂度为 O(n2)。
快速排序最喜欢乱序的列表,这样选择一个基准值后,左右子列表大小相当,这样递归处理左右子列表产生的函数调用栈的层次不会太深。如果对一个有序列表进行排序(吃饭撑着,但谁知道有无序),还是像上面那样每次取第一个元素为基准值,子列表为空,剩余元素全在右子列表中,这时候就出现了快速排序的最糟糕时间复杂度 O(n2),而且还会出现栈溢出。
用上面的 quicksort 函数来排序有序的 1 万个元素列表
quicksort(list(range(998)) 没问题,也就是我所用的 Python 的调用栈深度
所以还得对前面快速排序进行优化,选取基准值不能一味的用第一个元素,我们可以取一个中值或随机值。
改进后的快速排序代码,取中值为基准值
看实时执行过程(或点击链接新窗口中查看:快速排序可视过程):
现在再不怕用有序的列来踢场子了,排序 1 千万个有序列表
由此可以看出取基准值也是个小技术活儿,不同的基准值造成调用栈的深度是不一样的。
《算法图解》书上最后说:快速排序的最佳情况也是平均情况。只要你每次都随机的选择一个数组元素作为基准值,快速排序的平均时间就将为 O(n log n)。快速排序是最快的排序算法之一, 也是 D&G 的典范。对于原本有序的列表取随机元素作为基准值还不如直接取中位上的值有效。
进一步优化,以上代码每一次方法调用都会产生额外的数组,浪费了不少内存空间,我们完全可以作 In-place 的快速排序,同时注意基准值的选择,不能简单的选择最低或最高位上的值,否则要排一个有序的大数组就是一个灾难
同样测试一下对有序数组
这里每次都用了
[推荐]In-place 快速排序
排序执行过程(或点击链接新窗口中查看:快速排序可视过程):
再来测试对
再来一种写法
记住,快速排序的一个边际条件就是能否快速排好一个有序的大数组,如果排一个 1 亿个有序组很慢或调用栈溢出,那也不行。
来看看 Java 快速排序的能耐, Arrays.sort()
只需要大约 180 毫秒,比以上任何一种 Python 代码都快多的多,因为它是用的是一种叫做双基准值的快速排序方法,java.util.DualPivotQuickSort,JDK 7 新引入的。原理如下:
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
快速排序的演绎需要用递归来思考循环的问题,然而我之前总是在及力用循环来避免递归调用,有趣的是诸如 Haskell 等函数式编译语言根本没有循环,只能用递归来编写循环的效果。来看一个简单的例子,比如要从 1 加到 100,我们很自然会用循环从 1 累加到 100,如果换成递归,看下面的代码
1def summary(arr):
2 if len(arr) == 0:
3 return 0
4 else:
5 return arr[0] + summary(arr[1:])
6
7
8print(summary(list(range(1, 101)))) # 5050递归有助于我们把大问题分解为小问题,上面代码的思维是数组的和总是很一个元素加上剩下元素列表的和,直到最后元素列表为空(和为 0)。
快速排序的要理如下:
- 从待排序的列表中找一个基准值(随机选择或以第一个元素为基准值)
- 以上列表可分为三部分:小于基准值的子列表,基准值,大于基准值的子列表。这三部分从整体看是有序的
- 对 #2 中小于基准值和大于基准值两个子列表再次应用快速排序进一步分解
- 直到子列表长度为 1 或 0 时返回,因为此时列表是有序的
- 最后把全部分解出来的部分合并就是一个有序的列表
例如,对列表 [3, 5, 2, 1, 4] 总是取第首元素为基准值时的排序过程
[2, 1] 3 [5, 4]反映成 Python 代码如下:
[1] 2 3 [4] 5
1def quicksort(array):
2 if len(array) < 2:
3 return array
4
5 pivot = array[0]
6 left = []
7 right = []
8 for item in array[1:]:
9 if item <= pivot:
10 left.append(item)
11 else:
12 right.append(item)
13
14 return quicksort(left) + [pivot] + quicksort(right)上面的代码是取首元素为基准值; 下面有优化后的代码,取中值为基准值,专门应对顺序不够乱的列表
本来也想贴一张动图来展示快速排序的整个过程,但是觉得网上找的几个动图并不那么直观,用文本列出的排序过程也好理解。
我们对比一下快速排序与选择排序看它有多快, 上一篇中的选择排序的代码重新回顾如下:
1def selection_sort(array):
2 length = len(array)
3 for i in range(length):
4 for j in range(i+1, length):
5 if array[i] > array[j]:
6 array[i], array[j] = array[j], array[i]测试它们对相同含 100000 个数字的列表
1array1 = random.sample(range(100000+1), 100000)
2array2 = array1.copy()结果对比如下(排 10 万个元素):
- quick_sort(array1): 耗时 0.25448 秒
- selection_sort(array2): 耗时 658.633 秒(10 分多钟), 我居然能等这么久
等排序的元素越多,悬殊越大,再看排 1 万个元素的时间对比:
- quick_sort(array1): 耗时 0.023277 秒,没多大差别
- selection_sort(array2): 耗时 6.18316 秒
快速排序的时间复杂度为 O(n log n), 而选择排序的时间复杂度为 O(n2)。
快速排序最喜欢乱序的列表,这样选择一个基准值后,左右子列表大小相当,这样递归处理左右子列表产生的函数调用栈的层次不会太深。如果对一个有序列表进行排序(吃饭撑着,但谁知道有无序),还是像上面那样每次取第一个元素为基准值,子列表为空,剩余元素全在右子列表中,这时候就出现了快速排序的最糟糕时间复杂度 O(n2),而且还会出现栈溢出。
用上面的 quicksort 函数来排序有序的 1 万个元素列表
quicksort(list(range(999)))Python 中出现错误:RecursionError: maximum recursion depth exceeded while calling a Python object
quicksort(list(range(998)) 没问题,也就是我所用的 Python 的调用栈深度
sys.getrecursionlimit() 不能超过 1000。所以还得对前面快速排序进行优化,选取基准值不能一味的用第一个元素,我们可以取一个中值或随机值。
改进后的快速排序代码,取中值为基准值
1def quicksort(array):
2 if len(array) < 2:
3 return array
4
5 index = len(array) // 2
6 pivot = array[index]
7 left = []
8 right = []
9 for item in (array[:index] + array[index+1:]):
10 if item <= pivot:
11 left.append(item)
12 else:
13 right.append(item)
14
15 return quicksort(left) + [pivot] + quicksort(right)看实时执行过程(或点击链接新窗口中查看:快速排序可视过程):
现在再不怕用有序的列来踢场子了,排序 1 千万个有序列表
quicksort(list(range(10000000))) : 耗时为 25.52097 秒取首位与取中值为基准值时的排序过程对比,中括号外的值是每次分解用的基准值,它的左右就是每次分区后的左右子列表
| 取首位为基准值 [1, 2, 3, 4, 5, 6, 7, 8] [] 1 [2, 3, 4, 5, 6, 7, 8] [] 1 [] 2 [3, 4, 5, 6, 7, 8] [] 1 [] 2 [] 3 [4, 5, 6, 7, 8] [] 1 [] 2 [] 3 [] 4 [5, 6, 7, 8] [] 1 [] 2 [] 3 [] 4 [] 5 [6, 7, 8] [] 1 [] 2 [] 3 [] 4 [] 5 [] 6, [7, 8] [] 1 [] 2 [] 3 [] 4 [] 5 [] 6 [] 7 [8] | 取中位值为基准值 [1, 2, 3, 4, 5, 6, 7, 8] [1, 2, 3, 4] 5 [6, 7, 8] [1, 2], 3, [4] 5 [6] 7 [8] [1] 2 [] 3 [4] 5 [6] 7 [8] |
由此可以看出取基准值也是个小技术活儿,不同的基准值造成调用栈的深度是不一样的。
《算法图解》书上最后说:快速排序的最佳情况也是平均情况。只要你每次都随机的选择一个数组元素作为基准值,快速排序的平均时间就将为 O(n log n)。快速排序是最快的排序算法之一, 也是 D&G 的典范。对于原本有序的列表取随机元素作为基准值还不如直接取中位上的值有效。
进一步优化,以上代码每一次方法调用都会产生额外的数组,浪费了不少内存空间,我们完全可以作 In-place 的快速排序,同时注意基准值的选择,不能简单的选择最低或最高位上的值,否则要排一个有序的大数组就是一个灾难
1import random
2
3
4def quicksort(array, low, high):
5 if low >= high:
6 return
7
8 i, j = low, high
9 pivot = array[random.randint(low, high)] # 随机选择一个基准值
10
11 while i <= j:
12 while array[i] < pivot:
13 i += 1
14 while array[j] > pivot:
15 j -= 1
16 if i <= j:
17 array[i], array[j] = array[j], array[i]
18 i, j = i + 1, j - 1
19 quicksort(array, low, j)
20 quicksort(array, i, high)同样测试一下对有序数组
list(range(10000000)) 的排序,耗时为 30.71732 秒,为上一段代码略慢,但节约了内存。这里每次都用了
random.randin(low, high) 来找到随机位置,调用多了产生随机数也是个负担,如果换成取中值的方式,并且基线条件也换成了只要子列表为 1 个元素(不能等到长度为零)便返回[推荐]In-place 快速排序
1def quicksort(array, low, high):
2 if high - low < 2:
3 return
4
5 i, j = low, high
6 pivot = array[low + (high - low + 1) // 2]
7
8 while i <= j:
9 while array[i] < pivot:
10 i += 1
11 while array[j] > pivot:
12 j -= 1
13 if i <= j:
14 array[i], array[j] = array[j], array[i]
15 i, j = i + 1, j - 1
16 quicksort(array, low, j)
17 quicksort(array, i, high)排序执行过程(或点击链接新窗口中查看:快速排序可视过程):
再来测试对
list(range(10000000)) 的排序,耗时为 17.94254, 这已经是目前最好成绩了,且内存也不浪费。再来一种写法
1def partition(arr, low, high):
2 i = (low - 1)
3 mid = low + (high - low + 1) // 2
4 pivot = arr[mid] # pivot
5 arr[mid], arr[high] = arr[high], arr[mid]
6
7 for j in range(low, high):
8 if arr[j] <= pivot:
9 i = i + 1
10 arr[i], arr[j] = arr[j], arr[i]
11
12 arr[i + 1], arr[high] = arr[high], arr[i + 1]
13 return (i + 1)
14
15
16def quicksort(arr, low, high):
17 if low < high:
18 pi = partition(arr, low, high)
19
20 quicksort(arr, low, pi - 1)
21 quicksort(arr, pi + 1, high)记住,快速排序的一个边际条件就是能否快速排好一个有序的大数组,如果排一个 1 亿个有序组很慢或调用栈溢出,那也不行。
来看看 Java 快速排序的能耐, Arrays.sort()
1int[] array = IntStream.range(0, 100000000).toArray();
2long start = System.currentTimeMillis();
3Arrays.sort(array);
4System.out.println(System.currentTimeMillis() - start);只需要大约 180 毫秒,比以上任何一种 Python 代码都快多的多,因为它是用的是一种叫做双基准值的快速排序方法,java.util.DualPivotQuickSort,JDK 7 新引入的。原理如下:
- Dual Pivot Quick Sort : Java’s default sorting algorithm for primitive types.
- Dual-Pivot Quicksort algorithm
- Dual pivot Quicksort
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。