AWS S3 Key 前缀分布优化数据请求的性能
很早就想写下这篇日志的,因为实际使用 AWS S3 来存取文件使用什么样的 Key 对性能的影响是极其大的。当然,如果你对 S3 的并发请求在 50 以内是无所谓的,要是并发要求很高的话,Key 的选择就变得至关重要的,不可不察。S3 Key 从第一个字符算起的任意长度子字符串都被称作前缀(prefix), 而对 S3 文件访问性能影响不在完整的 Key, 恰恰是那个前缀。
背景:我们最初在使用 S3 时,存储的文件的 Key 直接用了数据库的自增 ID,于是保存到 Bucket 中大概下面那样子的
S3 的分区存储就像是硬盘分区,或文件分布在不同硬盘上的效果。试想一下,如果我们多个线程同时从一块硬盘上读取数据,每个线程需共同一个磁头来读取数据,性能就差; 但如果那些线程同时从不同的硬盘上读取各自的数据,那性能就大大提升了,它们互不干扰。在使用机械硬盘时我有过这样的体验,在同一个磁盘上拷贝文件比从一个磁盘拷贝到另一个磁盘要慢很多。
S3 的文件分区也是类似这样的原理,知道有这么一个概念在里头,再回到上面的文件。一开始还为为 S3 在分区时只有一个层次,像 Map 一样即以整个 S3 Key 算出一个 Hash 把文件一次性分布,类似于 Kafka 的分区,假设有 5 个分区,想当然是下面的分区行为
其实不然。如果这样的话我们又何须考虑用什么样的 Key(关键是前缀) 呢?又为什么会明显妨碍到我们的并发呢?
实质上 S3 在分区时是采用的树状层级结构,并且是依据 S3 Key 逐字母(也就是我们说的前缀)进行分布的,因此上面的文件实际分布是下面那样子的(我们暂且忽略掉后缀 .csv)
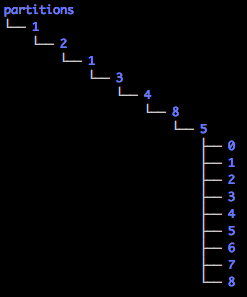 由于自增 ID 的因素,S3 Key 的左边基本没什么变化,它们共享了一个大前缀, 发现直到第 8 层才见分晓,所以用序列命名的文件拼命集中在
由于自增 ID 的因素,S3 Key 的左边基本没什么变化,它们共享了一个大前缀, 发现直到第 8 层才见分晓,所以用序列命名的文件拼命集中在
基于序列的变化只发生在尾部,有一个简单的办法是把序列号翻转过来,即把后缀转变为前缀,变成下面的 Key 命名方式
 上图是翻转过来显示的,看的时候可以头往左平摆,有助于防止颈椎病。由于第一个字符的不同,在第一层上的分区让上图看起来舒展多了,这应该也比较明显的提升并发性能,到 150 不会有问题。
上图是翻转过来显示的,看的时候可以头往左平摆,有助于防止颈椎病。由于第一个字符的不同,在第一层上的分区让上图看起来舒展多了,这应该也比较明显的提升并发性能,到 150 不会有问题。
上面的方案只是作了一个翻转,但作为十进制的数字,第一位的可能性只有 0 - 9 十种。实践证明在 S3 文件分区的表现上第一个字符尤其重要,第一个步子迈得要尽可能的大,不用担心会扯到蛋的。拓宽第一个字符的办法要采用更大的进位制,于是我们希望把字符分布到
上面提供了两个方法
现在我们假设有 20 个 ID (12134850 - 12134870) 对应的文件需要放到 S3 上去, 那么进行编码后放文件名如下
这里也有完整的实现 https://github.com/yabqiu/s3keygen,还有测试用例,在对 0 - 90000 间的数字进行编码后基本上每一位都平均分布到了 0 - 9, A - Z, 和 a - z 的 62 个字符上。
这里也有完整的实现,还有测试用例,在对 0 - 90000 间的数字进行编码后每一位基本平均分布到了 0 - 9, A - Z, 和 a - z 的 62 个字符上。
这种编码方式可以让每一位都错落有致,如果不翻转,只是每次取余顺序推到 StringBuilder 中的话,
同样对 12134850 - 12134870 进行编码,出来的结果是这样子的
注意:在生成 S3 Key 的时候最好是使用以上那 62 个字符,虽然 S3 Key 对于 S3 来说只是用来计算 Hash 的,可使用任意字符; 但要考虑到 Bucket 中的文件下载到本地后特殊字符会被自动更名的情况,例如像字符
参考:
后注(2018-10-29): Jul 17, 2018, 宣布不需要使用随机 S3 前缀来优化存取性能,S3 会自动处理好对象分布,想用什么 Key 都行。
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
背景:我们最初在使用 S3 时,存储的文件的 Key 直接用了数据库的自增 ID,于是保存到 Bucket 中大概下面那样子的
examplebucket/12134850.csvBucket 中有百万个文件,当初测试时 60 个左右的 Lambda 实例同时访问这个 Bucket 中不同的文件时,加载每个 S3 文件的时间大约在几百毫秒,然后并发上到 70, 80 后加载同样大小的 S3 文件的时间陡然增加到 10 秒以上,并发继续上到 100 以上直接导致众多 S3 的请求超时。后来了解到虽然一个 Bucket 中放多少个文件是没有限制的,而且官方文档说了文件多了并不影响访问的性能,但背后却有一个文件的分区存储机制,这个才是关键。
examplebucket/12134851.csv
examplebucket/12134852.csv
examplebucket/12134853.csv
examplebucket/12134854.csv
examplebucket/12134855.csv
examplebucket/12134856.csv
examplebucket/12134857.csv
examplebucket/12134858.csv
S3 的分区存储就像是硬盘分区,或文件分布在不同硬盘上的效果。试想一下,如果我们多个线程同时从一块硬盘上读取数据,每个线程需共同一个磁头来读取数据,性能就差; 但如果那些线程同时从不同的硬盘上读取各自的数据,那性能就大大提升了,它们互不干扰。在使用机械硬盘时我有过这样的体验,在同一个磁盘上拷贝文件比从一个磁盘拷贝到另一个磁盘要慢很多。
S3 的文件分区也是类似这样的原理,知道有这么一个概念在里头,再回到上面的文件。一开始还为为 S3 在分区时只有一个层次,像 Map 一样即以整个 S3 Key 算出一个 Hash 把文件一次性分布,类似于 Kafka 的分区,假设有 5 个分区,想当然是下面的分区行为
| Partition 1 | Partition 2 | Partition 3 | Partition 4 | Partition 5 |
| 12134850.csv | 12134851.csv | 12134852.csv | 12134853.csv | 12134854.csv |
| 12134855.csv | 12134856.csv | 12134857.csv | 12134858.csv |
其实不然。如果这样的话我们又何须考虑用什么样的 Key(关键是前缀) 呢?又为什么会明显妨碍到我们的并发呢?
实质上 S3 在分区时是采用的树状层级结构,并且是依据 S3 Key 逐字母(也就是我们说的前缀)进行分布的,因此上面的文件实际分布是下面那样子的(我们暂且忽略掉后缀 .csv)
由于自增 ID 的因素,S3 Key 的左边基本没什么变化,它们共享了一个大前缀, 发现直到第 8 层才见分晓,所以用序列命名的文件拼命集中在 1/2/1/3/4/8/5 这条路径上的分区中,从而致使并发请求多命中到一个狭窄的分区上,性能的低劣就是这样造成的。基于序列的变化只发生在尾部,有一个简单的办法是把序列号翻转过来,即把后缀转变为前缀,变成下面的 Key 命名方式
examplebucket/05843121.csv那么这时候依照前缀来分区效果又会如何呢?见下图
examplebucket/15843121.csv
examplebucket/25843121.csv
examplebucket/35843121.csv
examplebucket/45843121.csv
examplebucket/55843121.csv
examplebucket/65843121.csv
examplebucket/75843121.csv
examplebucket/85843121.csv
 上图是翻转过来显示的,看的时候可以头往左平摆,有助于防止颈椎病。由于第一个字符的不同,在第一层上的分区让上图看起来舒展多了,这应该也比较明显的提升并发性能,到 150 不会有问题。
上图是翻转过来显示的,看的时候可以头往左平摆,有助于防止颈椎病。由于第一个字符的不同,在第一层上的分区让上图看起来舒展多了,这应该也比较明显的提升并发性能,到 150 不会有问题。上面的方案只是作了一个翻转,但作为十进制的数字,第一位的可能性只有 0 - 9 十种。实践证明在 S3 文件分区的表现上第一个字符尤其重要,第一个步子迈得要尽可能的大,不用担心会扯到蛋的。拓宽第一个字符的办法要采用更大的进位制,于是我们希望把字符分布到
0 - 9上去,也就是需要实现一个 62 进制的数值表示法。而且我们依然需要事先对原始数字进行翻转,否则即使我们采用 128 位进制,由于前面五六位雷打不动,产生的第一个字符也会是一样的。这儿还有一个细节,而于数值的翻转而成为新的数值,会丢失本来是末尾的零,例如
A - Z
a - z
100000这两个数值翻转后为新的数值时都是 1, 所以在编码时必须记录下去掉的零的数目,如此才能保证编码是可逆的。这个翻转的 62 进制的编码实现代码如下
10
1package cc.unmi.aws;
2
3import java.util.ArrayList;
4import java.util.Collections;
5import java.util.List;
6import java.util.stream.IntStream;
7
8import static com.google.common.base.Preconditions.checkArgument;
9import static com.google.common.base.Preconditions.checkState;
10
11public class S3KeyGen {
12
13 private static List<Character> baseChars = new ArrayList<>(62);
14
15 static {
16 IntStream.rangeClosed('0', '9').forEach(value -> baseChars.add((char) value));
17 IntStream.rangeClosed('A', 'Z').forEach(value -> baseChars.add((char) value));
18 IntStream.rangeClosed('a', 'z').forEach(value -> baseChars.add((char) value));
19 }
20
21 public static String encode(long number) {
22 checkArgument(number >= 0, "Should be a positive number");
23
24 long reversed = Long.parseLong(reverse(String.valueOf(number)));
25 int zeros = String.valueOf(number).length() - String.valueOf(reversed).length();
26
27 if(zeros > 1) {
28 reversed *= (long) Math.pow(10, zeros - 1);
29 }
30
31 StringBuilder key = new StringBuilder();
32 encode(key, reversed);
33
34 if (zeros > 1) {
35 key.append("-").append(baseChars.get(zeros - 1));
36 }
37 return key.toString();
38 }
39
40 private static void encode(StringBuilder sb, long number) {
41 char c = baseChars.get((int) (number % baseChars.size()));
42
43 sb.append(c);
44
45 long quotient = number / baseChars.size();
46 if (quotient >= baseChars.size()) {
47 encode(sb, quotient);
48 } else if (quotient != 0) {
49 sb.append((char) baseChars.get((int) quotient));
50 }
51 }
52
53 public static long decode(String encodedS3key) {
54 checkArgument(encodedS3key != null, "Encoded S3 key cannot be null");
55
56 encodedS3key.chars().forEach(value -> {
57 char c = (char) value;
58 checkArgument(c == '-' || baseChars.contains(c), "Not a valid encoded S3 Key");
59 });
60
61 String[] split = encodedS3key.split("-");
62
63 checkState(split.length <= 2, "Could_not contain more than one -");
64
65 long sum = 0;
66 char[] chars = reverse(split[0]).toCharArray();
67
68 for (int i = 0; i < chars.length; i++) {
69 int index = Collections.binarySearch(baseChars, chars[i]);
70 sum += index * (long)Math.pow(baseChars.size(), chars.length - 1 - i);
71 }
72
73 checkState(sum >= 0, "No a valid long number in string");
74
75 StringBuilder result = new StringBuilder(reverse(String.valueOf(sum)));
76
77 if (split.length == 2) {
78 IntStream.range(0, Collections.binarySearch(baseChars, (char)(split[1].charAt(0) + 1)))
79 .forEach(value -> result.append("0"));
80 }
81
82 return Long.parseLong(result.toString());
83 }
84
85 private static String reverse(String str) {
86 return str == null?null:(new StringBuilder(str)).reverse().toString();
87 }
88}上面提供了两个方法
String encode(long number)分别是用来把数值编码为 S3 Key 和从 S3 Key 解码为一个数值
long decode(String encodedS3Key)
现在我们假设有 20 个 ID (12134850 - 12134870) 对应的文件需要放到 S3 上去, 那么进行编码后放文件名如下
examplebucket/t3WO.csv因为翻转后进行了 62 进位制,加大采样的话,编码后在第一个字符上可以把文件平均分布到 62 个分区上去,而不只是 10 个,这对并发访问的性能提升是不言而喻的。
examplebucket/DWT41.csv
examplebucket/XyQk1.csv
examplebucket/rQOQ2.csv
examplebucket/BtL63.csv
examplebucket/VLJm3.csv
examplebucket/pnGS4.csv
examplebucket/9GE85.csv
examplebucket/TiBo5.csv
examplebucket/nA9U6.csv
examplebucket/vCiS.csv
examplebucket/Fff81.csv
examplebucket/Z7do1.csv
examplebucket/tZaU2.csv
examplebucket/D2YA3.csv
examplebucket/XUVq3.csv
examplebucket/rwSW4.csv
examplebucket/BPQC5.csv
examplebucket/VrNs5.csv
examplebucket/pJLY6.csv
examplebucket/xLuW.csv
这里也有完整的实现 https://github.com/yabqiu/s3keygen,还有测试用例,在对 0 - 90000 间的数字进行编码后基本上每一位都平均分布到了 0 - 9, A - Z, 和 a - z 的 62 个字符上。
这里也有完整的实现,还有测试用例,在对 0 - 90000 间的数字进行编码后每一位基本平均分布到了 0 - 9, A - Z, 和 a - z 的 62 个字符上。
这种编码方式可以让每一位都错落有致,如果不翻转,只是每次取余顺序推到 StringBuilder 中的话,
1public static String encode(long number) {
2 StringBuilder key = new StringBuilder();
3 encode(key, number);
4 return key.toString();
5}
6private static void encode(StringBuilder sb, long number) {
7 char c = baseChars.get((int) (number % baseChars.size()));
8 sb.append(c);
9 long quotient = number / baseChars.size();
10 if (quotient >= baseChars.size()) {
11 encode(sb, quotient);
12 } else if (quotient != 0) {
13 sb.append((char) baseChars.get((int) quotient));
14 }
15}同样对 12134850 - 12134870 进行编码,出来的结果是这样子的
Opuo虽然第一位能依次排开,但取余之后剩下的数越来越接近。
Ppuo
Qpuo
Rpuo
Spuo
Tpuo
Upuo
Vpuo
Wpuo
Xpuo
Ypuo
Zpuo
apuo
bpuo
cpuo
dpuo
epuo
fpuo
gpuo
hpuo
ipuo
注意:在生成 S3 Key 的时候最好是使用以上那 62 个字符,虽然 S3 Key 对于 S3 来说只是用来计算 Hash 的,可使用任意字符; 但要考虑到 Bucket 中的文件下载到本地后特殊字符会被自动更名的情况,例如像字符
:, * 等在 Windows 文件名中是非法的字符。还有在进行 S3Event 触发 Lambda 时,像 =, + 等虽然可以作为 Windows 下的文件名,但是它会被进行 URL Encode,所以尽量使用不会作任何转换的字符放到 S3 Key 中,如 - 和 _ 任何时候都是很安全的。参考:
- Request Rate and Performance Considerations
- Object Key and Metadata
- Amazon S3 Performance Tips & Tricks + Seattle S3 Hiring Event
后注(2018-10-29): Jul 17, 2018, 宣布不需要使用随机 S3 前缀来优化存取性能,S3 会自动处理好对象分布,想用什么 Key 都行。
- Amazon S3 Announces Increased Request Rate Performance
- Amazon S3 Increases Request Rate Performance and Drops Randomized Prefix Requirement
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。