AWS Step Function 异步动态调用 Lambda 后汇集结果
分布式计算有这么一个需求,主进程准备好输入数据,然后根据输入中某个 Items 动态调用若干计算进程,待到所有计算完成后再汇集结果。这一需求移植到 AWS 上就像是下面这样子
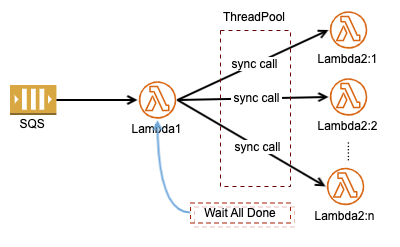 但在一个 Lambda 中同步调用其他 Lambda 时就有个费时费钱的问题,虽然我们采用线程池来调用 Lambda2, 由于每个同步调用的耗时不相同, Lambda1 最终要等待最慢的那个调用结束后才能对所有结果进行聚集处理。这就是著名的“长板效应”, Lambda1 多数时候是在无谓的等待当中消耗着你的钱财。
但在一个 Lambda 中同步调用其他 Lambda 时就有个费时费钱的问题,虽然我们采用线程池来调用 Lambda2, 由于每个同步调用的耗时不相同, Lambda1 最终要等待最慢的那个调用结束后才能对所有结果进行聚集处理。这就是著名的“长板效应”, Lambda1 多数时候是在无谓的等待当中消耗着你的钱财。
如果把同步改成异步调用 Lambda2 的话,就要有一种通知机制,在所有的 Lambda2 完成后再触发一个 Lambda 去收集结果,比如用一致性的协调服务器,像 ZooKeeper, etcd 等,或者是能保持事物的 Redis 都行,只要每一个 Lambda2 完成后能知道自己是最后一个就能通知下一个 Lambda 去处理结果。
基于以上的需求,AWS 的 Step Function 能派上用场了,Step Function 现在支持 Map 方式调用异步动态数量的 Lambda。比如根据输入的 JSON 中某个数组项,或 S3 中的 JSON 文件中的数组项,或 S3 的目录中的对象数进行异步动态调用。
下面是使用了 AWS Step Function 的状态机及如何启动

接下来用 Terraform 和 Python 实际演示上面整个使用 Step Function 的流程,文中贴出所有代码,这将大大增加本文的篇幅。
首先是所用到的 IAM Role, 所有 Lambda 共同一个 Role, Step Function 有自己的 Role
iam_roles.tf
然后是三个 Lambda 的定义
lambdas.tf
三个 Lambda 的代码实现放在同一个 py 文件中,使用了不同的入口函数
aws_lambdas.py
Lambda 实现中根据输入中的
再就是要创建一个 SQS 消息队列以及 Step Function 本身
main.tf
Step Function 的状态机定义放置在了单独的 state_machine.json 文件中
特别注意在 Map-calculation 中会根据
除了定义流程外,还请留意其中的重试与异常捕获处理机制。我们定义了在 Calculation 中无论出现任何异常都会跳到 Aggregation 步骤。
接下来对 Step Function 进行测试,并统计每一步的耗时。测试方法是往 SQS 队列
测试一:所有场景均执行成功,发送消息
测试结果
分析:
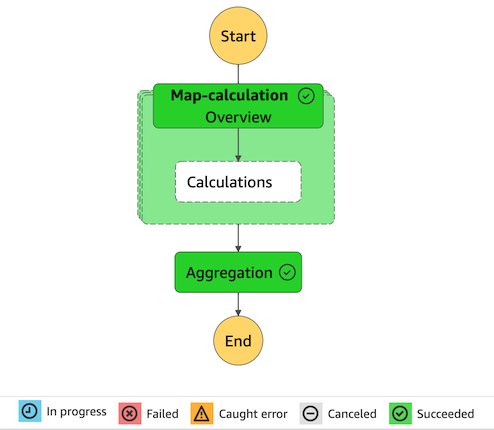
所有步骤成功后在 Step Function 中看到的该执行(Execution) 的图形显示为
 测试二:Calculation 存在失败的情况,发送消息
测试二:Calculation 存在失败的情况,发送消息
有一个 Calculation Lambda 在收到
结果分析:
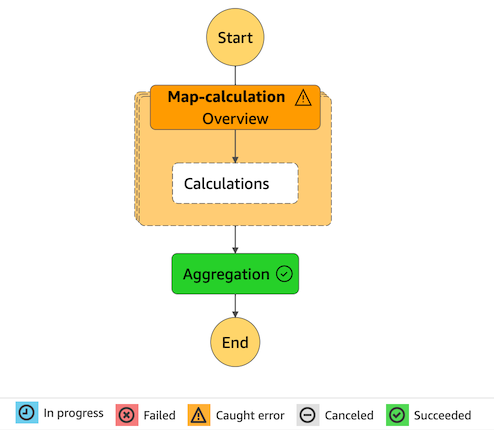
有任务执行失败的话在 Step Function 显示的状态机执行图形是
 本文简单的尝试了 Step Function 动态异步调用 Lambda 函数的用法,实际使用中必定会复杂些。例如大数据的输入输出可能要借助于 S3 来转储,重试与捕获异常的机制需更多的考虑,在某个步骤失败时可以立即发送 SQS/SNS 消息进行通知而不必执行后续的步骤,等等。
本文简单的尝试了 Step Function 动态异步调用 Lambda 函数的用法,实际使用中必定会复杂些。例如大数据的输入输出可能要借助于 S3 来转储,重试与捕获异常的机制需更多的考虑,在某个步骤失败时可以立即发送 SQS/SNS 消息进行通知而不必执行后续的步骤,等等。
另外,除了用 SQS 触发 Lambda 来执行 Step Function 的状态机外,还可以用 Amazon EventBridge Pipe,参考下图的流程
 Source 可以选择 AWS 流服务,如 Kinesis, Kafka, DynamoDB, Amazon MQ, 还不支持 SNS, 选择 SQS 时默认 batch 为 1。
Source 可以选择 AWS 流服务,如 Kinesis, Kafka, DynamoDB, Amazon MQ, 还不支持 SNS, 选择 SQS 时默认 batch 为 1。
然后后面的好理解了 Filtering 过滤收到的 Source 中的消息,Enrichment 对输入进行加工处理,除 Lambda 外还能选择用 API Gateway, API Destination 和 Step Function。
最后 Target 的选择就特别的多,如 SQS, SNS, Kinesis, Lambda, EventBridge event bus, ECS Cluster 等,我们这里选择 Step Function 就可以用前一步 Enrichment 的输出直接启动 Step Function 的状态机。
整个流程与前面的 SQS 触发 Lambda 来启动状态机类似,区别就是不需要用 Lambda 手工调用 StepFunction 的 API 的执行状态机。如果 SQS 消息可以直接作为 Step Function 的输入, 跳过中间可选的 Filtering 和 Enrichment 步骤,就可以用 SQS 消息直接启动 Step Function 状态机。
链接:
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
但在一个 Lambda 中同步调用其他 Lambda 时就有个费时费钱的问题,虽然我们采用线程池来调用 Lambda2, 由于每个同步调用的耗时不相同, Lambda1 最终要等待最慢的那个调用结束后才能对所有结果进行聚集处理。这就是著名的“长板效应”, Lambda1 多数时候是在无谓的等待当中消耗着你的钱财。如果把同步改成异步调用 Lambda2 的话,就要有一种通知机制,在所有的 Lambda2 完成后再触发一个 Lambda 去收集结果,比如用一致性的协调服务器,像 ZooKeeper, etcd 等,或者是能保持事物的 Redis 都行,只要每一个 Lambda2 完成后能知道自己是最后一个就能通知下一个 Lambda 去处理结果。
基于以上的需求,AWS 的 Step Function 能派上用场了,Step Function 现在支持 Map 方式调用异步动态数量的 Lambda。比如根据输入的 JSON 中某个数组项,或 S3 中的 JSON 文件中的数组项,或 S3 的目录中的对象数进行异步动态调用。
下面是使用了 AWS Step Function 的状态机及如何启动
- Start:状态机将会由 SQS 触发一个 Lambda来启动
- Calculations: Step Function 根据输入中的 items 项数异步调用动态数量的 Calculation Lambda。Calculations 外的虚线框就表示调用数是动态的
- Aggregation: 所有 Calculations 完成后再处理所有的计算结果
- Starter, Calculation 和 Aggregation 是三个 AWS Lambda
接下来用 Terraform 和 Python 实际演示上面整个使用 Step Function 的流程,文中贴出所有代码,这将大大增加本文的篇幅。
首先是所用到的 IAM Role, 所有 Lambda 共同一个 Role, Step Function 有自己的 Role
iam_roles.tf
1resource "aws_iam_role" "lambda_role" {
2 name = "step_function_lambda_role"
3 assume_role_policy = <<-EOF
4 {
5 "Version": "2012-10-17",
6 "Statement": [
7 {
8 "Effect": "Allow",
9 "Principal": {
10 "Service": "lambda.amazonaws.com"
11 },
12 "Action": "sts:AssumeRole"
13 }
14 ]
15}
16EOF
17 managed_policy_arns = ["arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"]
18 inline_policy {
19 name = "test_inline_policy"
20 policy = <<-EOF
21{
22 "Version": "2012-10-17",
23 "Statement": [
24 {
25 "Effect": "Allow",
26 "Action": [
27 "sqs:ReceiveMessage",
28 "sqs:DeleteMessage",
29 "sqs:GetQueueAttributes"
30 ],
31 "Resource": ["${aws_sqs_queue.step_function_input.arn}"]
32 },
33 {
34 "Effect": "Allow",
35 "Action": [
36 "states:StartExecution"
37 ],
38 "Resource": ["${local.step_function_arn}"]
39 }
40 ]
41}
42EOF
43 }
44}
45
46resource "aws_iam_role" "step_function_role" {
47 name = "step-function-role"
48 assume_role_policy = <<-EOF
49 {
50 "Version": "2012-10-17",
51 "Statement": [
52 {
53 "Effect": "Allow",
54 "Action": "sts:AssumeRole",
55 "Principal": {
56 "Service": "states.amazonaws.com"
57 }
58 }
59 ]
60 }
61 EOF
62 inline_policy {
63 name = "call_lambda_policy"
64 policy = <<-EOF
65 {
66 "Version": "2012-10-17",
67 "Statement": [
68 {
69 "Action": [
70 "lambda:InvokeFunction"
71 ],
72 "Effect": "Allow",
73 "Resource": [
74 "${aws_lambda_function.calculation.arn}",
75 "${aws_lambda_function.aggregation.arn}"
76 ]
77 },
78 {
79 "Effect": "Allow",
80 "Action": [
81 "states:StartExecution"
82 ],
83 "Resource": ["${local.step_function_arn}"]
84 }
85 ]
86 }
87EOF
88 }
89}然后是三个 Lambda 的定义
lambdas.tf
1data "archive_file" "lambda_package" {
2 source_file = "aws_lambdas.py"
3 output_path = "aws_lambdas.zip"
4 type = "zip"
5}
6
7resource "aws_lambda_function" "start" {
8 function_name = "step_function_start"
9 role = aws_iam_role.lambda_role.arn
10 memory_size = 128
11 timeout = 30
12 filename = data.archive_file.lambda_package.output_path
13 source_code_hash = data.archive_file.lambda_package.output_base64sha256
14 runtime = "python3.10"
15 handler = "aws_lambdas.start"
16 environment {
17 variables = {
18 STATE_MACHINE_ARN = aws_sfn_state_machine.demo.arn
19 }
20 }
21}
22
23resource "aws_lambda_event_source_mapping" "event_mapping" {
24 event_source_arn = aws_sqs_queue.step_function_input.arn
25 function_name = aws_lambda_function.start.function_name
26 batch_size = 1
27}
28
29resource "aws_lambda_function" "calculation" {
30 function_name = "step_function_calculation"
31 role = aws_iam_role.lambda_role.arn
32 memory_size = 128
33 timeout = 60
34 filename = data.archive_file.lambda_package.output_path
35 source_code_hash = data.archive_file.lambda_package.output_base64sha256
36 runtime = "python3.10"
37 handler = "aws_lambdas.calculate"
38}
39
40resource "aws_lambda_function" "aggregation" {
41 function_name = "step_function_aggregation"
42 role = aws_iam_role.lambda_role.arn
43 memory_size = 128
44 timeout = 30
45 filename = data.archive_file.lambda_package.output_path
46 source_code_hash = data.archive_file.lambda_package.output_base64sha256
47 runtime = "python3.10"
48 handler = "aws_lambdas.aggregate"
49}三个 Lambda 的代码实现放在同一个 py 文件中,使用了不同的入口函数
aws_lambdas.py
1import json
2import os
3import time
4import boto3
5import logging
6
7logging_format = '%(asctime)s - %(levelname)s - %(funcName)s:%(lineno)d - %(message)s\n'
8logger = logging.getLogger()
9if logger.handlers:
10 logger.handlers[0].setFormatter(logging.Formatter(logging_format))
11 logger.setLevel(logging.INFO)
12
13
14sfn = boto3.client('stepfunctions')
15
16
17def start(event, context):
18 sqs_message = event['Records'][0]['body']
19 logger.info('sqs message: %s', sqs_message)
20
21 response = sfn.start_execution(
22 stateMachineArn=os.getenv("STATE_MACHINE_ARN"),
23 input=sqs_message,
24 )
25 logger.info("start response %s", response)
26
27
28def calculate(event, context):
29 logger.info("received message: %s", event)
30
31 if event['id'] == 104:
32 raise Exception('calculation failed')
33
34 logger.info("sleep %s seconds", event['sleep'])
35 time.sleep(event['sleep'])
36 logger.info("done")
37 return {f"result{event['id']}": f"processed task: {event['id']}"}
38
39
40def aggregate(event, context):
41 logger.info("received aggregated result: %s", event)
42
43 if 'Error' in event:
44 return "one of calculation failed"
45 else:
46 return "processed result " + json.dumps(event, default=str)Lambda 实现中根据输入中的
sleep 模拟耗时,并在 id 为 104 时模拟 Lambda 调用失败。再就是要创建一个 SQS 消息队列以及 Step Function 本身
main.tf
1provider "aws" {}
2
3resource "aws_sqs_queue" "step_function_input" {
4 name = "step_function_input"
5 sqs_managed_sse_enabled = false
6}
7
8locals {
9 step_function_arn = format("arn:aws:states:%s:%s:stateMachine:step-function-demo",
10 data.aws_region.current.id, data.aws_caller_identity.current.account_id)
11}
12
13data "aws_caller_identity" current {}
14data aws_region current {}
15
16resource "aws_sfn_state_machine" "demo" {
17 name = "step-function-demo"
18 role_arn = aws_iam_role.step_function_role.arn
19 definition = templatefile("state_machine.json", {
20 CALCULATION_LAMBDA_ARN = aws_lambda_function.calculation.arn
21 AGGREGATION_LAMBDA_ARN = aws_lambda_function.aggregation.arn
22 })
23}Step Function 的状态机定义放置在了单独的 state_machine.json 文件中
1{
2 "Comment": "A description of my state machine",
3 "StartAt": "Map-calculation",
4 "States": {
5 "Map-calculation": {
6 "Type": "Map",
7 "ItemProcessor": {
8 "ProcessorConfig": {
9 "Mode": "DISTRIBUTED",
10 "ExecutionType": "STANDARD"
11 },
12 "StartAt": "Calculations",
13 "States": {
14 "Calculations": {
15 "Type": "Task",
16 "Resource": "arn:aws:states:::lambda:invoke",
17 "OutputPath": "$.Payload",
18 "Parameters": {
19 "Payload.$": "$",
20 "FunctionName": "${CALCULATION_LAMBDA_ARN}"
21 },
22 "Retry": [
23 {
24 "ErrorEquals": [
25 "Lambda.ServiceException",
26 "Lambda.AWSLambdaException",
27 "Lambda.SdkClientException",
28 "Lambda.TooManyRequestsException",
29 "Exception"
30 ],
31 "IntervalSeconds": 2,
32 "MaxAttempts": 3,
33 "BackoffRate": 2
34 }
35 ],
36 "End": true
37 }
38 }
39 },
40 "Label": "Map-calculation",
41 "MaxConcurrency": 1000,
42 "InputPath": "$.items",
43 "Next": "Aggregation",
44 "Catch": [
45 {
46 "ErrorEquals": [
47 "States.ALL"
48 ],
49 "Next": "Aggregation"
50 }
51 ]
52 },
53 "Aggregation": {
54 "Type": "Task",
55 "Resource": "arn:aws:states:::lambda:invoke",
56 "OutputPath": "$.Payload",
57 "Parameters": {
58 "Payload.$": "$",
59 "FunctionName": "${AGGREGATION_LAMBDA_ARN}"
60 },
61 "Retry": [
62 {
63 "ErrorEquals": [
64 "Lambda.ServiceException",
65 "Lambda.AWSLambdaException",
66 "Lambda.SdkClientException",
67 "Lambda.TooManyRequestsException"
68 ],
69 "IntervalSeconds": 2,
70 "MaxAttempts": 3,
71 "BackoffRate": 2
72 }
73 ],
74 "End": true
75 }
76 }
77}特别注意在 Map-calculation 中会根据
InputPath: $.items 即输入 JSON 中的 items 数组异步调用相应数目的 Calculation Lambda除了定义流程外,还请留意其中的重试与异常捕获处理机制。我们定义了在 Calculation 中无论出现任何异常都会跳到 Aggregation 步骤。
接下来对 Step Function 进行测试,并统计每一步的耗时。测试方法是往 SQS 队列
step_function_input 中发送 JSON 格式的消息。测试一:所有场景均执行成功,发送消息
1{
2 "items": [
3 {
4 "id": 100,
5 "sleep": 5
6 },
7 {
8 "id": 101,
9 "sleep": 30
10 },
11 {
12 "id": 103,
13 "sleep": 10
14 }
15 ]
16}测试结果
| Lambda Function | 耗时(Duration) | 输入(Event) | 输出(Lambda return) |
| step_function_start | 319.15 ms | { "items": [ { "id": 100, "sleep": 5 }, { "id": 101, "sleep": 30 }, { "id": 103, "sleep": 10 } ] } | 启动状态机 |
| step_function_calculation | 5007.12 ms | {'id': 100, 'sleep': 5} | {'result100': 'processed task: 100'} |
| step_function_calculation | 10013.75 ms | {'id': 103, 'sleep': 10} | {'result103': 'processed task: 103'} |
| step_function_calculation | 30018.05 ms | {'id': 101, 'sleep': 30} | {'result101': 'processed task: 101'} |
| step_function_aggregation | 1.46 ms | [{'result100': 'processed task: 100'}, {'result101': 'processed task: 101'}, {'result103': 'processed task: 103'}] | 处理所有 step_function_calculation 返回结果组成的数组 |
分析:
- SQS 消息触发 step_function_start 启动完 Step Function 状态机立即结束
- 状态机根据输入中的
items项调用相应数量的 step_function_calculation Lambda,每个调用的输入为items中的子元素 - Step Function 把所有 step_function_calculation 的输出组成一个数组作为 step_function_aggregation 的输入
- 每一个 Lambda 都在规定的时间内完成自己的任务,不存在任何无谓等待的环节
所有步骤成功后在 Step Function 中看到的该执行(Execution) 的图形显示为
测试二:Calculation 存在失败的情况,发送消息 1{
2 "items": [
3 {
4 "id": 100,
5 "sleep": 5
6 },
7 {
8 "id": 101,
9 "sleep": 50
10 },
11 {
12 "id": 104,
13 "sleep": 1
14 }
15 ]
16}有一个 Calculation Lambda 在收到
id:104 时会抛出异常,执行失败。消息中加大了 101 任务的执行时间,在 104 进行了所有的重试后 101 仍未执行完,以此来考察 aggregation 在什么时机被触发。| Lambda Function | 开始时间 | 结束时间 |
| step_function_start | 16:39:11,310 | 16:39:11,507 |
| step_function_calculation(id:100) | 16:39:12,737 | 16:39:17,742 |
| step_function_calculation(id:101) | 16:39:12,701 | 16:40:02,725 |
| step_function_calculation(id:104) | 16:39:12,733, 16:39:14,924, 16:39:19,103, 16:39:27,303 | 多次重试,每次重试 1 秒后结束 |
| step_function_aggregation | 16:39:29,529 |
结果分析:
- 某一个 step_function_calculation Lambda 处理
id:104的输入时尝试了四次(MaxAttemps:3, 好像有点出入) - 由于某个任务的失败,最络 step_function_aggregation Lambda 执行的输入只是 {'Error': 'States.ExceedToleratedFailureThreshold', 'Cause': 'The specified tolerated failure threshold was exceeded'}, 其余两个能正常执行的结果
- step_function_aggregation 并未等待所有的 calculation 结束后才执行,而是有一个失败就会触发,以此通告整个状态机的执行失败
有任务执行失败的话在 Step Function 显示的状态机执行图形是
本文简单的尝试了 Step Function 动态异步调用 Lambda 函数的用法,实际使用中必定会复杂些。例如大数据的输入输出可能要借助于 S3 来转储,重试与捕获异常的机制需更多的考虑,在某个步骤失败时可以立即发送 SQS/SNS 消息进行通知而不必执行后续的步骤,等等。另外,除了用 SQS 触发 Lambda 来执行 Step Function 的状态机外,还可以用 Amazon EventBridge Pipe,参考下图的流程
 Source 可以选择 AWS 流服务,如 Kinesis, Kafka, DynamoDB, Amazon MQ, 还不支持 SNS, 选择 SQS 时默认 batch 为 1。
Source 可以选择 AWS 流服务,如 Kinesis, Kafka, DynamoDB, Amazon MQ, 还不支持 SNS, 选择 SQS 时默认 batch 为 1。然后后面的好理解了 Filtering 过滤收到的 Source 中的消息,Enrichment 对输入进行加工处理,除 Lambda 外还能选择用 API Gateway, API Destination 和 Step Function。
最后 Target 的选择就特别的多,如 SQS, SNS, Kinesis, Lambda, EventBridge event bus, ECS Cluster 等,我们这里选择 Step Function 就可以用前一步 Enrichment 的输出直接启动 Step Function 的状态机。
整个流程与前面的 SQS 触发 Lambda 来启动状态机类似,区别就是不需要用 Lambda 手工调用 StepFunction 的 API 的执行状态机。如果 SQS 消息可以直接作为 Step Function 的输入, 跳过中间可选的 Filtering 和 Enrichment 步骤,就可以用 SQS 消息直接启动 Step Function 状态机。
链接:
- 以上代码以上传至 GitHub https://github.com/yabqiu/aws-step-function-map
- New – Step Functions Support for Dynamic Parallelism
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。