为 S3 中的 CSV 文件创建带 Partition 的 Athena 表
CSV 文件是纯文本的,对人阅读和编辑来说是最友好的描述表格数据的格式。虽然当前处理大数据时会用到 JSON, avro, parquet 等数据格式,但是在处理平面数据时 CSV 仍然被广泛使用。
S3 Select 能支持 CSV, JSON 和 parquet 格式数据的直接查询。在 AWS s3 控制台选择一个 CSV 文件,从右上的
如 S3 Select 查询语句
S3 Select 只能针对单个 S3 文件查询,如果要对一组 CSV 文件同时进行查询的话就要用到 Athena。把相同 Schema 的一系列 CSV 文件放到 S3 的某一个目录中,我们可为它们创建一个 Athena 表,然后查询该 Athena 表就会从对应 S3 目录中扫描所有的 CSV 文件。
现在我们来创建两个 CSV 文件
1.csv
CSV 文件准备好后,我们进入到 Amazon Athena 的查询控制台 https://us-east-1.console.aws.amazon.com/athena/home?region=us-east-1#/query-editor, 创建 students 表的语句是
创建 Athena 表的语句请参考 Athena CREATE TABLE
执行后会在 default 数据库中创建一个 students 表,完后可以执行查询
得到结果
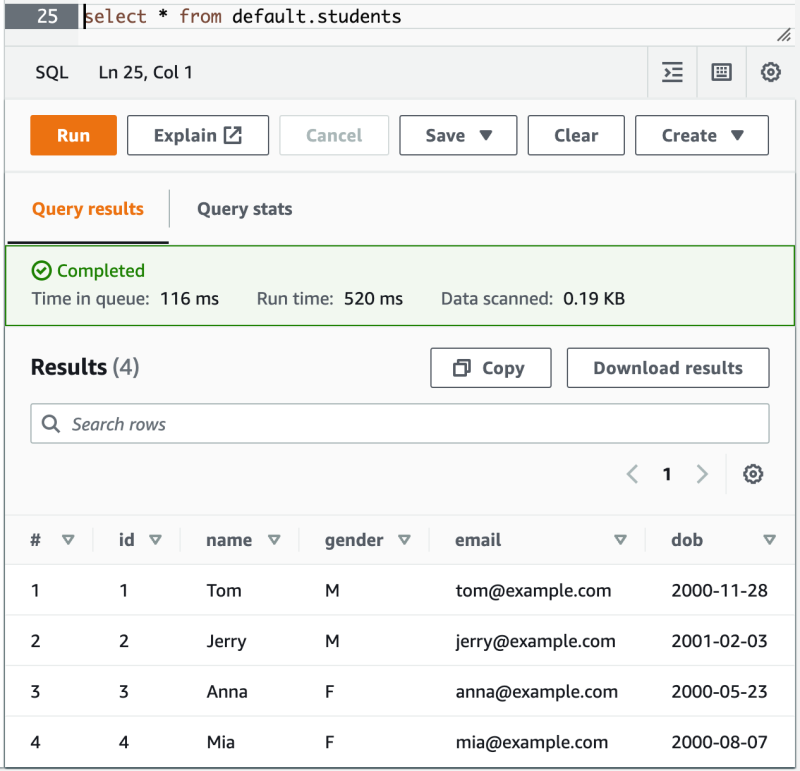 一个基本的为 S3 目录中 CSV 文件创建 Athena 表并查询的功能实现了,现在再往 s3://yanbin-test-csv/students 目录上传一个新的 CSV 文件后,用 select * from default.students 可以查询出新增的记录。
一个基本的为 S3 目录中 CSV 文件创建 Athena 表并查询的功能实现了,现在再往 s3://yanbin-test-csv/students 目录上传一个新的 CSV 文件后,用 select * from default.students 可以查询出新增的记录。
注意当前的 Athena 执行创建表的语句时错误提示信息还比较弱智,可能任意的语法错误都粗暴的提示为如下错误
所以千万不要被它的错误信息误导,并不是
我们尽管在创建 Athena 表时为字段两边加了斜撇号,但无法保留大小写形式,Athena 总是转换为小写字母形式,因此前面创建表的语句中可去掉字段两边的斜撇号,即使字段以数字开头也可不用斜撇号 -- 数字开头的字段名在查询时需用双引号括起来。
以上值是默认的。
还有一个问题,前面创建 Athena 表时只简单认为字段是用逗号分割的,还有稍微复杂一点的 CVS 格式,如字段值含逗号的就需要用双引号括住字段值,再字段值内容中的双引号需要进一步转义
比如我们编辑一个 3.csv 文件,内容如下
 显然这不是我们想要的结果,要能识别字段值中的逗号要用到
显然这不是我们想要的结果,要能识别字段值中的逗号要用到
再来查询含用
 其实
其实
参考 OpenCSVSerde for processing CSV
OpenCSVSerde 不直接支持字面意义 "YYYY-MM-DD" 格式的 date 类型,所以上面把 DOB 字段类型改成了 string, 它所支持的 date 类型的值是从 1970-01-01 后的天数,如 18276 表示为 2020-01-15,字段值为整数可指定为 date 类型。
S3 目录到 Athena 表的 Partition 映射约定是
映射到 Athena 表的 Partition 名分别为 year=2000, gender=M
当然这不是自动的,我们需要在创建 Athena 表时指定 Partition 参数
现在我们把 s3://yanbin-test-csv/students/ 目录清空,根据 year 和 gender 重新组织 CSV 文件,生成以下三个文件
由于
 我们试着来查询一下
我们试着来查询一下
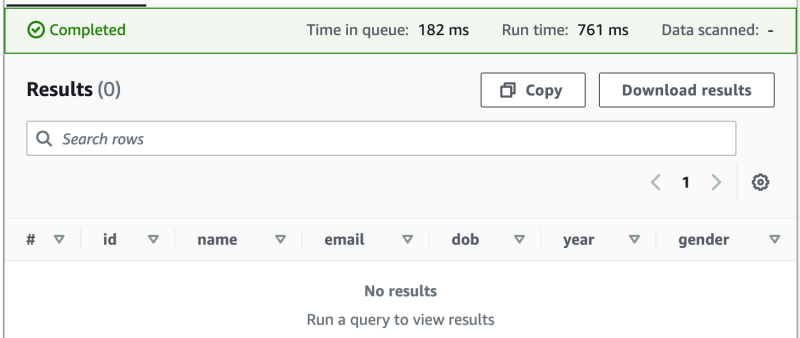 真的没有看错,没有记录,不是明明有一个文件在 s3://yanbin-test-csv/students/year=2000/gender=M/2000-M.csv 吗?
真的没有看错,没有记录,不是明明有一个文件在 s3://yanbin-test-csv/students/year=2000/gender=M/2000-M.csv 吗?
原因是我们需要创建表时指定了分区为 year 和 gender, 但 Athena 尚未从对应的分区目录中(如 year=2000/gender=M) 中加载分区, 还需要后续一步操作。
需要执行
 再用前面的查询语句就能取到数据了
再用前面的查询语句就能取到数据了
关于 MSCK REPAIR TABLES 的用法请参数官方文档 https://docs.aws.amazon.com/athena/latest/ug/msck-repair-table.html. MSCK 是 Hive's MetaStore consistency check,像 FSCK(file system consistency check) 命名一样。
后续我们往已知的分区目录 s3://yanbin-test-csv/students/year=2000/gender=M/ 中添加文件就能立即查询到。但是有新的分区目录的话,每次都需要执行语句
比如再上传一个文件
 这里要留意一个问题,由于创建 Athena 表时字段自动转换为小写,
这里要留意一个问题,由于创建 Athena 表时字段自动转换为小写,
我们来作一个测试
上传文件到
 Athena 能扫描到该新分区,却无法依照 /year=xxxx/ 的规则加载该分区到 metastore 信息库中去,当然也就无法查询到其中的数据内容
Athena 能扫描到该新分区,却无法依照 /year=xxxx/ 的规则加载该分区到 metastore 信息库中去,当然也就无法查询到其中的数据内容
所以记住,在 S3 路径中的分区名称一定要用小写,这样才能被
不过 S3 路径中分区分称有大写字母时还有手工的补救措施,在 AWS Athena 控制台执行语句
结果只显示
实际中请尽量遵循 S3 中分区名部分小写的规则,这样能用
AWS Athena 控制台中的查询语句还能用
最后提示:不要轻信 Athena 对查询语句的错误提示,请确保语法正确。什么时候用 ``, "", '' 都没有明确的规则
[版权声明] 本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。
S3 Select 能支持 CSV, JSON 和 parquet 格式数据的直接查询。在 AWS s3 控制台选择一个 CSV 文件,从右上的
Object actions 下拉选项上选择 Query with S3 Select 就能直接查询该文件的内容,而无须下载后打开文件。如 S3 Select 查询语句
SELECT * from s3object WHERE Name='Tom' LIMIT 5如果 CSV 带 Header 的话,请勾选上
Exclude the first line of CSV data。当然 S3 Select 查看任意的文本文件也行,只是把它当成一个不规则的 CSV 文件来对待。S3 Select 只能针对单个 S3 文件查询,如果要对一组 CSV 文件同时进行查询的话就要用到 Athena。把相同 Schema 的一系列 CSV 文件放到 S3 的某一个目录中,我们可为它们创建一个 Athena 表,然后查询该 Athena 表就会从对应 S3 目录中扫描所有的 CSV 文件。
现在我们来创建两个 CSV 文件
1.csv
Id,Name,Gender,Email,DOB2.csv
1,Tom,M,tom@example.com,2000-11-28
2,Jerry,M,jerry@example.com,2001-02-03
Id,Name,Gender,Email,DOB把它们上传上 s3 的某个目录中
3,Anna,F,anna@example.com,2000-05-23
4,Mia,F,mia@example.com,2000-08-07
aws s3 cp 1.csv s3://yanbin-test-csv/students/在 s3://yanbin-test-csv/students/ 目录中就有了 1.csv 和 2.csv 两个文件
aws s3 cp 2.csv s3://yanbin-test-csv/students/
CSV 文件准备好后,我们进入到 Amazon Athena 的查询控制台 https://us-east-1.console.aws.amazon.com/athena/home?region=us-east-1#/query-editor, 创建 students 表的语句是
1CREATE EXTERNAL TABLE IF NOT EXISTS `default.students` (
2 `Id` integer,
3 `Name` string,
4 `Gender` string,
5 `Email` string,
6 `DOB` date
7)
8ROW FORMAT DELIMITED
9FIELDS TERMINATED BY ','
10LOCATION 's3://yanbin-test-csv/students/'
11TBLPROPERTIES (
12 'skip.header.line.count'='1'
13)创建 Athena 表的语句请参考 Athena CREATE TABLE
skip.header.line.count 跳过第一行的 header执行后会在 default 数据库中创建一个 students 表,完后可以执行查询
select * from default.students
得到结果
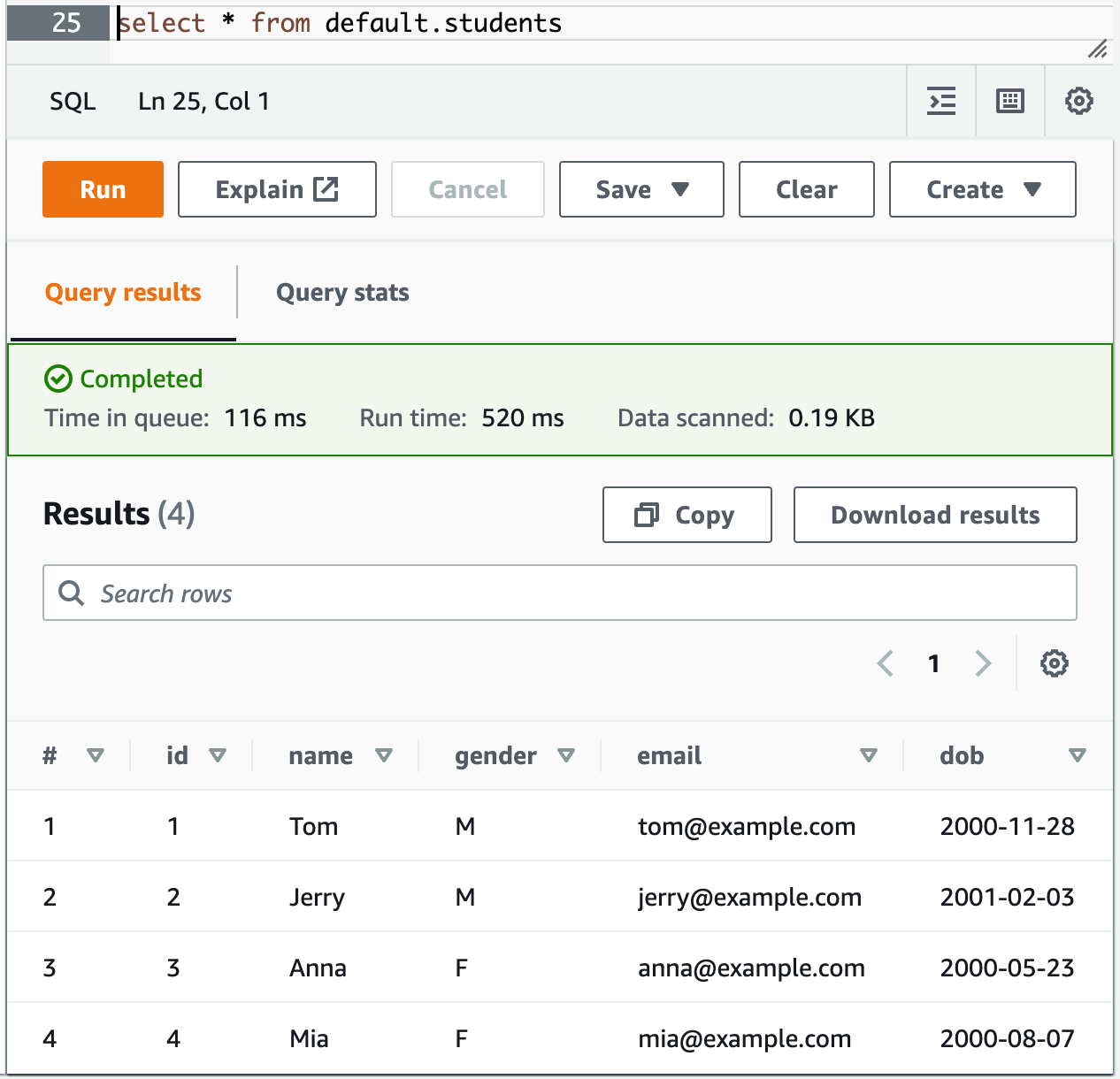 一个基本的为 S3 目录中 CSV 文件创建 Athena 表并查询的功能实现了,现在再往 s3://yanbin-test-csv/students 目录上传一个新的 CSV 文件后,用 select * from default.students 可以查询出新增的记录。
一个基本的为 S3 目录中 CSV 文件创建 Athena 表并查询的功能实现了,现在再往 s3://yanbin-test-csv/students 目录上传一个新的 CSV 文件后,用 select * from default.students 可以查询出新增的记录。注意当前的 Athena 执行创建表的语句时错误提示信息还比较弱智,可能任意的语法错误都粗暴的提示为如下错误
line 1:8: mismatched input 'EXTERNAL'. Expecting: 'OR', 'SCHEMA', 'TABLE', 'VIEW'其实产生上面错误的语句是字段类型后多了一个逗号
1CREATE EXTERNAL TABLE IF NOT EXISTS `default.students` ( `Id` integer,)所以千万不要被它的错误信息误导,并不是
EXTERNAL 的问题,而要认真检查整个语句的语法。我们尽管在创建 Athena 表时为字段两边加了斜撇号,但无法保留大小写形式,Athena 总是转换为小写字母形式,因此前面创建表的语句中可去掉字段两边的斜撇号,即使字段以数字开头也可不用斜撇号 -- 数字开头的字段名在查询时需用双引号括起来。
ROW FORMAT DELIMITED 用于不需要双引号括住值的情况,在 CSV 中值没有逗号用双引号也是合法的,如 "Tom". ROW FORMAT DELIMITED 也能指分隔换行等属性1ROW FORMAT DELIMITED
2FILEDS TERMINATED BY '\t'
3ESACAPED BY '\\'
4LINES TERMINATED By '\n'以上值是默认的。
ROW FORMAT DELIMITED 默认使用的 SERDE 是 org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, 接下来我们要用到另一种 SERDE -- org.apache.hadoop.hive.serde2.OpenCSVSerde。还有一个问题,前面创建 Athena 表时只简单认为字段是用逗号分割的,还有稍微复杂一点的 CVS 格式,如字段值含逗号的就需要用双引号括住字段值,再字段值内容中的双引号需要进一步转义
比如我们编辑一个 3.csv 文件,内容如下
Id,Name,Gender,Email,DOB然后上传到 s3://yanbin-test-csv/students 目录中,再查询
5,"Tiger,Scott",M,scott@example.com,2001-03-03
select * from default.students where id=5得到结果是
 显然这不是我们想要的结果,要能识别字段值中的逗号要用到
显然这不是我们想要的结果,要能识别字段值中的逗号要用到 ROW FORMAT SERDE ... 来指定 CSV 的序列化类 1CREATE EXTERNAL TABLE IF NOT EXISTS default.students (
2 Id integer,
3 Name string,
4 Gender string,
5 Email string,
6 DOB string
7)
8
9ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
10WITH SERDEPROPERTIES (
11 'escapeChar'='\\',
12 'quoteChar'='\"',
13 'separatorChar' = ',',
14 'skip.header.line.count'='1'
15)
16LOCATION 's3://yanbin-test-csv/students/'再来查询含用
Tiger,Scott 内容的记录,得到的就是 其实
其实 org.apache.hadoop.hive.serde2.OpenCSVSerde 的 escapeChar, quoteChar 和 separatorChar 就是上面的默认值,因此在 WITH SERDEPROPERTIES 中可以省略这三项,简单书写为 1CREATE EXTERNAL TABLE IF NOT EXISTS default.students (
2 Id integer,
3 Name string,
4 Gender string,
5 Email string,
6 DOB string
7)
8
9ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
10WITH SERDEPROPERTIES (
11 'skip.header.line.count'='1'
12)
13LOCATION 's3://yanbin-test-csv/students/'参考 OpenCSVSerde for processing CSV
OpenCSVSerde 不直接支持字面意义 "YYYY-MM-DD" 格式的 date 类型,所以上面把 DOB 字段类型改成了 string, 它所支持的 date 类型的值是从 1970-01-01 后的天数,如 18276 表示为 2020-01-15,字段值为整数可指定为 date 类型。
创建支持 Partition 的 Athena 表
前面我们把所有的 CSV 文件扔到一个 S3 目录中,所以没有 Partition 支持, 为提升查询效率我们有必要对 CSV 文件分目录,然后映射到 Athena 表的分区中去,查询时就能限定分区来查询,大大缩小扫描文件的数目S3 目录到 Athena 表的 Partition 映射约定是
s3://yanbin-test-csv/students/year=2000/gender=M/1.csv
映射到 Athena 表的 Partition 名分别为 year=2000, gender=M
当然这不是自动的,我们需要在创建 Athena 表时指定 Partition 参数
现在我们把 s3://yanbin-test-csv/students/ 目录清空,根据 year 和 gender 重新组织 CSV 文件,生成以下三个文件
$ cat 2000-M.csv首先上传一个文件到 S3 中去
Id,Name,Gender,Email,DOB
1,Tom,M,tom@example.com,2000-11-28
$ cat 2000-F.csv
Id,Name,Gender,Email,DOB
3,Anna,F,anna@example.com,2000-05-23
4,Mia,F,mia@example.com,2000-08-07
$ cat 2001-M.csv
Id,Name,Gender,Email,DOB
2,Jerry,M,jerry@example.com,2001-02-03
5,"Tiger,Scott",M,scott@example.com,2001-03-03
aws s3 cp 2000-M.csv s3://yanbin-test-csv/students/year=2000/gender=M/2000-M.csv然后创建带 Partition 的 students 表
1CREATE EXTERNAL TABLE IF NOT EXISTS default.students (
2 Id integer,
3 Name string,
4 Email string,
5 DOB string
6)
7PARTITIONED BY (year integer, gender string)
8ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
9WITH SERDEPROPERTIES (
10 'skip.header.line.count'='1'
11)
12LOCATION 's3://yanbin-test-csv/students/'PARTITIONED BY 中的字段同时为表的字段,所以必须从表字段中移除 Gender 字段。这时候 Athena 显示 students 为一个 Partitioned 的表
我们试着来查询一下select * from default.students
-- 或者用 select * from default.students where year=2000
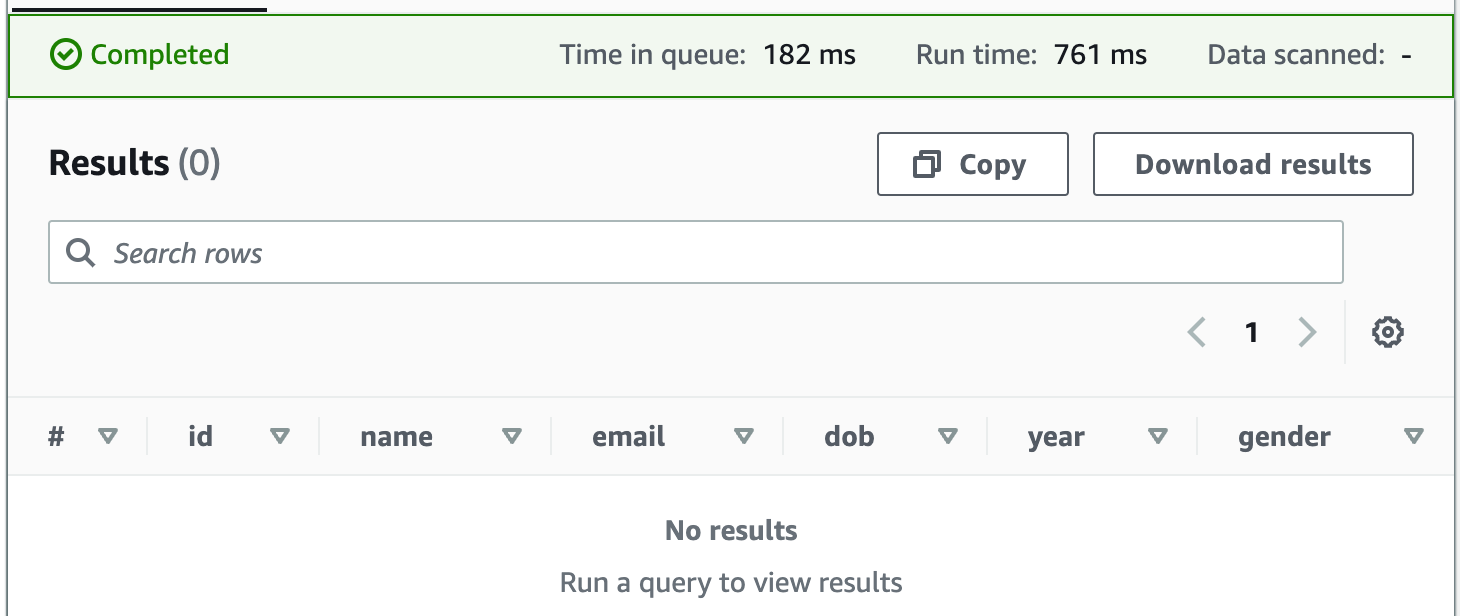 真的没有看错,没有记录,不是明明有一个文件在 s3://yanbin-test-csv/students/year=2000/gender=M/2000-M.csv 吗?
真的没有看错,没有记录,不是明明有一个文件在 s3://yanbin-test-csv/students/year=2000/gender=M/2000-M.csv 吗? 原因是我们需要创建表时指定了分区为 year 和 gender, 但 Athena 尚未从对应的分区目录中(如 year=2000/gender=M) 中加载分区, 还需要后续一步操作。
需要执行
MSCK REPAIR TABLE default.studentsAWS 控制台显示 再用前面的查询语句就能取到数据了
再用前面的查询语句就能取到数据了关于 MSCK REPAIR TABLES 的用法请参数官方文档 https://docs.aws.amazon.com/athena/latest/ug/msck-repair-table.html. MSCK 是 Hive's MetaStore consistency check,像 FSCK(file system consistency check) 命名一样。
后续我们往已知的分区目录 s3://yanbin-test-csv/students/year=2000/gender=M/ 中添加文件就能立即查询到。但是有新的分区目录的话,每次都需要执行语句
MSCK REPAIR TABLE default.students让 Athena 去 s3://yanbin-test-csv/students/ 目录下扫描新的分区,加入到 metastore 信息库中去。
比如再上传一个文件
$ aws s3 cp 2000-F.csv s3://yanbin-test-csv/students/year=2000/gender=F/2000-F.csvAWS Athena 控制台再执行
MSCK REPAIR TABLE default.students又有
Partition 被添加 这里要留意一个问题,由于创建 Athena 表时字段自动转换为小写,
这里要留意一个问题,由于创建 Athena 表时字段自动转换为小写,PARTITIONED BY (year integer) 和 PARTITIONED by (Year integer 是一样的,分区字段都是 year,然后 S3 的 Key 是区分大小写的,假如在创建表时恰好写成 PARTITIONED by (Year integer), 接着把 CSV 文件传到 s3://yanbin-test-csv/students/Year=2000 目录中的话,怎么用 MSCK REPAIR TABLE default.students 命令也添加不了 Year=2000 这个分区,也就查询不到其中的数据。我们来作一个测试
上传文件到
/Year=20001 目录中$ aws s3 cp 2001-M.csv s3://yanbin-test-csv/students/Year=2001/gender=M/2000-M.csv试图去发现该分区
MSCK REPAIR TABLE default.students
 Athena 能扫描到该新分区,却无法依照 /year=xxxx/ 的规则加载该分区到 metastore 信息库中去,当然也就无法查询到其中的数据内容
Athena 能扫描到该新分区,却无法依照 /year=xxxx/ 的规则加载该分区到 metastore 信息库中去,当然也就无法查询到其中的数据内容所以记住,在 S3 路径中的分区名称一定要用小写,这样才能被
MSCK REPAIR TABLE 自动扫描并加载到 metastore 信息库中去。S3 路径中分区的值是区分大小写的,如 /year=M, /year=m不过 S3 路径中分区分称有大写字母时还有手工的补救措施,在 AWS Athena 控制台执行语句
1ALTER TABLE default.students
2ADD PARTITION (year='2001', gender='M')
3LOCATION 's3://yanbin-test-csv/students/Year=2001/gender=M/'结果只显示
Query successful.如果再执行就会提示错误
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. AlreadyExistsException(message:Partition already exists.)现在就能从新的分区 year=2001, gender=M 中查询到新数据了
select id,name,email from default.students where year=2001当然这种 ADD PARTITION 的操作还能从任意的 S3 目录中加载分区,如
1ALTER TABLE default.students
2ADD PARTITION (year='2002', gender='F')
3LOCATION 's3://other-bucket/students/2001/F/'实际中请尽量遵循 S3 中分区名部分小写的规则,这样能用
MSCK REPAIR TABLE 自动加载到。AWS Athena 控制台中的查询语句还能用
aws cli 来执行,比如$ aws athena start-query-execution --query-string "MSCK REPAIR TABLE default.students"可到 AWS Athena 控制台的
{
"QueryExecutionId": "20b481e3-77f1-4333-90fc-52b3ac9d5635"
}
Recent queries 页面中找执行结果,或用 aws cli 查询执行是否成功$ aws athena get-query-execution --query-execution-id 20b481e3-77f1-4333-90fc-52b3ac9d5635有查询结果的语句,用
get-query-execution 命令能看到 ResultConfiguration:OutputLocation 路径,如 s3://athena-queries/ffa4e9b4-ab92-4e2a-96fb-e8c34881848e.csv$ aws s3 cp s3://athena-queries/ffa4e9b4-ab92-4e2a-96fb-e8c34881848e.csv -即显示查询结果。
最后提示:不要轻信 Athena 对查询语句的错误提示,请确保语法正确。什么时候用 ``, "", '' 都没有明确的规则
create external table `default.fund-similarity` ...链接:
drop table `default.fund-similarity`
select * from "default"."fund-similarity" -- 不能 select * fromdefault.fund-similarity
- How can I create and use partitioned tables in Amazon Athena?
- LazySimpleSerDe for CSV, TSV, and custom-delimted files
[版权声明]
本文采用 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 进行许可。